Cara Mengatasi Kesalahan Web Scraping Umum pada 2026

Sora Fujimoto
AI Solutions Architect

TL;Dr:
- Penanganan Kesalahan yang Beragam: Tangani kesalahan klien 4xx (400, 401, 402, 403, 429) dan kesalahan spesifik platform seperti Cloudflare's 1001.
- Strategi Adaptif: Implementasikan backoff eksponensial, rotasi IP dinamis, dan optimasi header lanjutan untuk meniru perilaku manusia.
- Peran CapSolver: Gunakan CapSolver untuk menyelesaikan CAPTCHA dan tantangan interaktif kompleks secara otomatis yang memicu berbagai kode kesalahan web scraper.
- Penggalian Data yang Tahan Terhadap Perubahan: Adopsi analisis perilaku dan manajemen fingerprint browser untuk menghadapi lingkungan keamanan web 2026 yang terus berkembang.
Pendahuluan
Penggalian data sangat penting untuk pasar ekstraksi data sebesar 1,17 miliar dolar di tahun 2026. Namun, meningkatnya kesulitan dalam pengumpulan data menghadapi penghalang yang semakin meningkat. Pengembang sering menghadapi kode status, dengan kesalahan 429 menjadi hambatan yang terus-menerus. Panduan ini menjelajahi cara mengidentifikasi, menyelesaikan, dan memperbaiki jenis kesalahan web scraper yang umum. Pelajari cara mencapai tingkat keberhasilan tinggi dengan strategi profesional. Tujuan kami adalah membangun pipa data yang tangguh untuk lingkungan keamanan yang kompleks di tahun 2026.
Memahami Berbagai Kesalahan Penggalian Web
Selain kesalahan 429 yang sering terjadi, spektrum kode status HTTP dapat mengganggu operasi penggalian. Setiap kode menunjukkan masalah yang berbeda, memerlukan pendekatan yang disesuaikan untuk penyelesaian. Memahami sinyal ini adalah dasar untuk membangun infrastruktur penggalian yang kuat.
400 Bad Request
Kesalahan penggalian web ini menunjukkan bahwa server tidak dapat memproses permintaan karena masalah di sisi klien, seperti sintaks yang tidak valid, kerangka pesan permintaan yang tidak sah, atau rute permintaan yang menipu. Penyebab umum termasuk parameter URL yang salah, payload JSON yang tidak sah, atau metode HTTP yang tidak standar. Untuk memperbaiki kesalahan 400, validasi struktur permintaan Anda secara cermat terhadap format yang diharapkan oleh API atau situs web target. Pastikan semua bidang yang diperlukan ada dan diatur dengan benar. Alat debugging dapat membantu mengidentifikasi kesalahan spesifik.
401 Unauthorized
Kesalahan 401 menunjukkan bahwa permintaan tidak memiliki kredensial otentikasi yang valid untuk sumber daya target. Ini sering terjadi saat menggali konten yang dilindungi yang memerlukan token login, kunci API, atau kuki sesi. Jika scraper Anda menghadapi 401, berarti mekanisme otentikasi Anda mungkin hilang, kedaluwarsa, atau salah. Solusi melibatkan manajemen kuki sesi yang benar, memperbarui token otentikasi, atau mengintegrasikan alur OAuth. Untuk skenario otentikasi yang kompleks, alat yang menangani persistensi sesi bisa sangat berharga.
402 Payment Required
Meskipun kurang umum dalam penggalian web umum, kesalahan 402 dapat muncul dalam konteks tertentu, terutama dengan API atau layanan berbayar. Ini menunjukkan bahwa klien perlu melakukan pembayaran untuk mengakses sumber daya yang diminta. Dalam konteks penggalian, ini mungkin berarti Anda telah melewati batas tier gratis atau mencoba mengakses data premium tanpa langganan yang diperlukan. Kesalahan penggalian web ini biasanya memerlukan tinjauan model harga layanan atau penyesuaian strategi pengumpulan data ke data tier gratis.
403 Forbidden
Kesalahan 403 Forbidden adalah sinyal kuat bahwa server memahami permintaan Anda tetapi menolak memenuhinya. Ini sering disebabkan oleh pemblokiran IP, filtering User-Agent, atau pengukuran keamanan lanjutan. Berbeda dengan 401, otentikasi tidak akan membantu; server hanya menolak akses. Untuk mengatasi kesalahan penggalian web ini, strategi termasuk memutar alamat IP, mengoptimalkan string User-Agent, dan mengelola fingerprint browser.
429 Too Many Requests
Kode status HTTP 429 menandai permintaan berlebihan dalam jangka waktu tertentu. Menurut IETF RFC 6585, ini mencakup header "Retry-After". Kesalahan penggalian web ini sering berarti penggalian yang prediktabil atau agresif. Memahami pembatasan laju adalah kunci untuk ketangguhan. Server menggunakan algoritma seperti Token Bucket untuk mengelola lalu lintas, memblokir scraper yang melebihi batas.
Pada tahun 2026, arti kesalahan 429 melampaui permintaan per menit saja. Sistem modern menggunakan "sliding window" untuk mengelola kepadatan permintaan jangka panjang. Volume tinggi dalam satu jam dapat memicu pemblokiran, bahkan jika batas jangka pendek terpenuhi. Beberapa server menggunakan 429 sebagai persiapan untuk pemblokiran IP permanen. Pengenalan dini memungkinkan penyesuaian strategi sebelum terkena flag permanen. Menganggap 429 sebagai umpan balik memperbaiki scraper Anda untuk stabilitas jangka panjang.
500 Internal Server Error & 502 Bad Gateway
Kesalahan ini terjadi di sisi server, bukan secara langsung dengan permintaan scraper Anda. Kesalahan 500 berarti server mengalami kondisi yang tidak terduga. Kesalahan 502 sering menunjukkan bahwa server proxy menerima respons yang tidak sah dari server upstream. Meskipun Anda tidak dapat memperbaiki ini secara langsung, scraper Anda harus dirancang untuk menanganinya dengan baik melalui pengulangan dan pencatatan. Jika kesalahan ini terus berlanjut, mungkin menunjukkan masalah pada situs web target itu sendiri, atau bahwa permintaan Anda secara tidak sengaja memicu pengecualian sisi server karena data atau perilaku yang tidak terduga.
Kesalahan Khusus Cloudflare (misalnya, 1001 Kesalahan Resolusi DNS)
Pengelola keamanan sering kali memperkenalkan kode kesalahan mereka sendiri. Cloudflare, layanan yang banyak digunakan, dapat menampilkan berbagai tantangan. Kesalahan 1001, misalnya, biasanya menunjukkan masalah resolusi DNS atau koneksi ke jaringan Cloudflare. Tantangan Cloudflare lainnya mungkin melibatkan redirect JavaScript atau halaman CAPTCHA. Mengatasi ini memerlukan teknik khusus, seperti menyesuaikan User-Agent secara dinamis atau menggunakan browser tanpa GUI. CapSolver menawarkan solusi untuk skenario ini; pelajari cara mengganti User-Agent untuk mengatasi Cloudflare tantangan secara efektif. Untuk integrasi Cloudflare yang lebih umum, lihat Cloudflare PHP.
Ringkasan Perbandingan: Kesalahan Penggalian Web Umum
| Kode Kesalahan | Penyebab Utama | Keparahan | Perbaikan yang Direkomendasikan |
|---|---|---|---|
| 400 Bad Request | Sintaks permintaan yang tidak valid | Rendah | Validasi permintaan |
| 401 Unauthorized | Otentikasi yang hilang/invalid | Menengah | Manajemen sesi/token |
| 402 Payment Required | Melebihi tier gratis/kebutuhan langganan | Rendah | Tinjau rencana layanan |
| 403 Forbidden | Pemblokiran IP, filtering User-Agent | Tinggi | Rotasi IP, optimasi header |
| 429 Too Many Requests | Pembatasan laju berdasarkan IP atau sesi | Menengah | Pengurangan laju & rotasi IP |
| 500 Internal Server Error | Masalah di sisi server | Rendah | Pengulangan yang baik, pencatatan |
| 502 Bad Gateway | Masalah server proxy/upstream | Rendah | Pengulangan yang baik, pencatatan |
| 1001 Kesalahan Cloudflare | Masalah DNS/jaringan, tantangan keamanan | Tinggi | User-Agent, browser tanpa GUI, CapSolver |
Mengapa Web Scraper Gagal di Tahun 2026
Lingkungan pengumpulan data telah berubah. Data terbaru dari Laporan Bot Jahat Imperva 2025 menunjukkan bahwa lalu lintas otomatis kini menyumbang 37% dari seluruh aktivitas internet. Akibatnya, situs web telah menerapkan analisis perilaku lanjutan. Jika scraper Anda tidak mampu menangani elemen interaktif atau gagal mempertahankan fingerprint digital yang konsisten, kemungkinan besar akan gagal.
Kesalahan penggalian web yang umum terjadi ketika skrip tidak mempertimbangkan sifat "tidak diverifikasi" dari lalu lintasnya. Laporan WP Engine 2025 menunjukkan bahwa 76% lalu lintas bot tidak diverifikasi, menjadikannya target utama pembatasan laju. Untuk tetap beroperasi, infrastruktur Anda harus membuktikan keabsahannya melalui manajemen header yang tepat dan pola interaksi yang realistis.
Perbaikan Praktis untuk Kesalahan Penggalian Web
Memperbaiki kesalahan penggalian web memerlukan pendekatan berlapis. Anda tidak bisa hanya "menerobos" pembatasan laju; Anda harus menyesuaikan diri dengan mereka.
1. Menerapkan Backoff Eksponensial
Alih-alih pengulangan segera, skrip Anda sebaiknya menunggu durasi yang meningkat setelah kegagalan, menunjukkan penghormatan terhadap sumber daya server. Urutan seperti 1, 2, lalu 4 detik dapat mengurangi frekuensi kesalahan 429. Untuk penggunaan lanjutan, tambahkan "jitter"—randomisasi durasi tunggu—untuk mencegah beberapa scraper dari mengulang secara bersamaan, menghindari DDoS tidak sengaja dan pemblokiran IP.
Pada tahun 2026, "jitter yang tidak terkorelasi" juga digunakan, menghitung durasi tunggu dengan faktor acak untuk pola pengulangan yang tidak terduga. Menggabungkan backoff eksponensial dengan jitter cerdas menciptakan pola permintaan yang mirip manusia, yang penting untuk menghindari pembatasan laju yang sensitif di situs web dengan lalu lintas tinggi.
2. Rotasi IP yang Strategis
IP tunggal mudah dibatasi laju. Sebuah kumpulan proxy residensial atau seluler mendistribusikan beban permintaan, membuat penggalian terkoordinasi lebih sulit dideteksi. Untuk menghindari pemblokiran IP, kumpulan proxy yang beragam sangat penting. Proxy datacenter sering diblokir karena rentang server yang diketahui. Proxy residensial dengan alamat IP pengguna rumah, lebih cocok.
Pada tahun 2026, proxy seluler lebih disukai. Mereka menggunakan alamat IP jaringan seluler, yang dibagikan oleh banyak pengguna sah, membuat server enggan memblokirnya karena potensi dampak pada pelanggan. Memutar alamat IP seluler secara signifikan mengurangi tingkat kesalahan penggalian web. Implementasikan "sesi yang konsisten" di mana satu alamat IP proxy menangani perjalanan pengguna penuh sebelum dirotasi, mempertahankan konsistensi dan mencegah perilaku "teleportasi" pengguna.
3. Optimasi Header dan User-Agent
Header HTTP mengungkap identitas Anda. Header bawaan dari perpustakaan, seperti Axios, menunjukkan bahwa Anda adalah bot. Untuk memperbaiki kesalahan penggalian web ini, gunakan string User-Agent terbaik yang sesuai dengan versi browser saat ini. Header User-Agent, Accept-Language, dan Sec-CH-UA harus sejalan. Situs web modern di tahun 2026 menggunakan "Client Hints" (header Sec-CH) untuk detail perangkat. Perbedaan antara User-Agent dan Client Hints (misalnya, Windows vs. Linux) menyebabkan penandaan segera.
Urutan header juga kritis. Browser nyata mengirim header dalam urutan tertentu. Jika skrip Anda menyimpang, filter keamanan mendeteksinya. Gunakan perpustakaan untuk urutan header tetap atau alat browser. Header "Referer" dan "Origin" meningkatkan keabsahan; misalnya, mengatur Referer ke halaman hasil pencarian untuk permintaan halaman produk meniratikan alur pengguna alami. Detail ini membedakan skrip dasar dari alat ekstraksi data profesional.
4. Menangani CAPTCHA dan Tantangan Interaktif
Situs web mengimplementasikan CAPTCHA atau tantangan interaktif ketika mendeteksi aktivitas mencurigakan, yang merupakan kesalahan penggalian web yang umum. CapSolver mengotomatisasi penyelesaian ini, memastikan penggalian yang tidak terganggu. Untuk reCAPTCHA, hCaptcha, atau tantangan kustom, CapSolver mengintegrasikan solusi ke dalam alur kerja Anda secara efisien. Pelajari lebih lanjut tentang kegagalan otomatisasi web pada tantangan ini di Mengapa Otomatisasi Web Terus Gagal pada CAPTCHA.
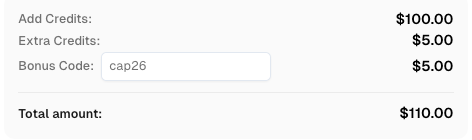
Gunakan kode `CAP26 saat mendaftar di CapSolver untuk mendapatkan kredit tambahan!
Menangani Tantangan Spesifik Platform
Situs web bervariasi dalam toleransi terhadap otomatisasi. Memahami nuansa ini penting bagi pengembang profesional. Di tahun 2026, pendekatan "satu ukuran cocok semua" untuk penggalian sudah usang; sesuaikan logika Anda dengan pertahanan spesifik setiap target.
E-commerce dan Retail
Situs ritel besar secara agresif membatasi laju saat musim puncak. Arti kesalahan 429 di sini biasanya menunjukkan frekuensi permintaan yang terlalu tinggi untuk profil konsumen. Alat untuk mengintegrasikan Playwright dapat meniru perjalanan pengguna nyata (klik, scroll), mengurangi penandaan. Pemilik toko juga mendeteksi "tanda-tanda penggalian" seperti permintaan JSON hanya API. Untuk menghindari kesalahan penggalian web ini, scraper Anda sebaiknya sesekali memuat gambar dan CSS untuk meniru pengalaman browser penuh.
Real Estate dan Data Keuangan
Sektor ini sangat melindungi data berharganya, menggunakan "pembatasan laju berdasarkan niat", memantau jenis halaman yang dikunjungi. Mengunjungi hanya daftar listing berharga tanpa menjelajahi halaman "Tentang Kami" atau "Kontak" menunjukkan perilaku non-manusia. Untuk memperbaiki kesalahan penggalian web ini, sisipkan "permintaan noise" ke halaman berharga rendah, mengurangi jejak Anda dan meniru pengguna yang penasaran. Pastikan penanganan redirect yang benar, karena banyak situs keuangan menggunakan redirect sementara untuk menguji klien yang mencurigakan.
Media Sosial dan Platform Video
Media sosial dan platform video sangat sensitif terhadap penggalian data, sering memeriksa fingerprint browser. Saat menggunakan Axios di Node.js, kelola kuki dan token sesi dengan benar. Untuk tantangan interaktif, CapSolver mengotomatisasi solusi, menghadapi langkah verifikasi kompleks tanpa intervensi manual, mencegah pengumpulan otomatis.
Strategi Lanjut untuk Tahun 2026
Di tahun 2026, "scraper yang sukses" berarti pengambilan data yang efisien dan etis, bukan hanya pengambilan data.
Pembatasan Laju Adaptif
Pantau waktu respons server alih-alih menggunakan penundaan tetap. Perlahan secara proaktif jika latensi meningkat, mencegah kesalahan 429. Pendekatan proaktif lebih baik daripada merespons blokir.
Manajemen Fingerprint Browser
Sistem keamanan modern menganalisis lebih dari IP dan User-Agent. Mereka memeriksa rendering canvas, kemampuan WebGL, dan status baterai. Spoofing atribut ini diperlukan untuk penggalian skala besar.
Kesimpulan
Memperbaiki kesalahan penggalian web memerlukan penyempurnaan terus-menerus. Memahami arti kesalahan 429 dan menerapkan solusi seperti rotasi IP, optimasi header, dan backoff eksponensial memastikan keberhasilan tinggi. Tujuannya adalah menyatu dengan lalu lintas sah. CapSolver, untuk tantangan interaktif kompleks, memberikan keunggulan dalam lingkungan data yang kompetitif di tahun 2026. Tetap adaptif, hormati batas server, dan bangun pipa data yang berkelanjutan.
FAQ
1. Apa penyebab paling umum dari kesalahan 429?
Melebihi batas permintaan server adalah penyebab paling umum, sering disebabkan oleh throttling yang tidak memadai atau jumlah IP yang terlalu sedikit untuk volume data yang tinggi.
2. Bisakah saya memperbaiki kesalahan 403 Forbidden hanya dengan mengganti IP saya?
Mengganti IP Anda mungkin memberikan bantuan sementara, tetapi kesalahan 403 sering kali menunjukkan masalah yang lebih dalam terkait fingerprint browser atau header. Profil permintaan Anda harus terlihat benar-benar manusia.
3. Bagaimana CapSolver membantu mengatasi kesalahan web scraping?
CapSolver mengotomasi penyelesaian tantangan interaktif yang kompleks, mencegah scraper dari terjebak atau terblokir, sehingga mengurangi kesalahan.
4. Apakah ilegal untuk mengambil data dari situs web pada tahun 2026?
Mengambil data publik dari situs web umumnya legal, tetapi patuhi ketentuan layanan, robots.txt, dan hukum privasi data seperti GDPR. Selalu prioritaskan pengumpulan data yang etis.
5. Seberapa sering saya harus mengganti User-Agent saya?
Ganti User-Agent secara teratur, memastikan setiapnya adalah string yang modern dan valid. Kumpulan 50 User-Agent paling umum adalah titik awal yang baik.
Lihat Lebih Banyak
Web ScrapingApr 22, 2026
Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan
Pelajari arsitektur pengambilan data web Rust yang dapat diskalakan dengan reqwest, scraper, pengambilan data asinkron, pengambilan data browser tanpa tampilan, rotasi proxy, dan penanganan CAPTCHA yang sesuai aturan.

Web ScrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.

