如何修复常见网络爬虫错误 2026

Anh Tuan
Data Science Expert

TL;Dr:
- 多样化的错误处理:处理4xx客户端错误(400、401、402、403、429)和特定平台错误,如Cloudflare的1001错误。
- 自适应策略:实施指数退避、动态IP轮换和高级头部优化,以模仿人类行为。
- CapSolver的作用:使用CapSolver自动解决触发各种网络爬虫错误代码的CAPTCHA和复杂交互挑战。
- 未来适应性爬取:采用行为分析和浏览器指纹管理,以应对2026年不断变化的网络安全环境。
简介
2026年,网络爬虫在11.7亿美元的数据提取市场中至关重要。然而,数据收集的复杂性增加,同时面临越来越多的障碍。开发人员经常遇到状态码,其中429错误是持续的障碍。本指南探讨了识别、排查和解决常见网络爬虫错误类型。学习使用专业策略实现高成功率。我们的目标是为2026年复杂的网络安全环境构建稳健的数据管道。
理解多样的网络爬虫错误
除了常见的429错误外,各种HTTP状态码都可能干扰爬取操作。每个代码表示不同的潜在问题,需要定制的解决方案。理解这些信号是构建稳健爬取基础设施的基础。
400 错误请求
此网络爬虫错误表示服务器因客户端问题无法处理请求,如格式错误、无效的请求消息框架或欺骗性请求路由。常见原因包括错误的URL参数、无效的JSON负载或非标准HTTP方法。要解决400错误,需仔细验证请求结构是否符合目标API或网站的预期格式。确保所有必填字段存在且格式正确。调试工具可以帮助定位具体错误。
401 未授权
401错误表示请求缺少目标资源的有效认证凭证。这通常发生在爬取需要登录令牌、API密钥或会话Cookie的受保护内容时。如果爬虫遇到401错误,意味着认证机制缺失、过期或错误。解决方案包括正确管理会话Cookie、刷新认证令牌或集成OAuth流程。对于复杂的认证场景,能够处理会话持久化的工具非常有用。
402 需要付款
虽然在一般网络爬虫中较少见,但402错误可能出现在特定上下文中,尤其是付费API或服务中。它表示客户端需要付款才能访问请求的资源。在爬虫上下文中,这可能意味着您已超出免费套餐限制或试图在没有必要订阅的情况下访问付费数据。此网络爬虫错误通常需要审查服务定价模型或调整数据获取策略以使用公开的免费数据。
403 禁止访问
403禁止访问错误表明服务器理解您的请求但拒绝执行。这通常是由于IP黑名单、User-Agent过滤或其他高级安全措施。与401不同,认证无法解决问题;服务器直接拒绝访问。为应对此网络爬虫错误,策略包括轮换IP地址、优化User-Agent字符串和管理浏览器指纹。
429 请求过多
HTTP 429状态码表示在特定时间内请求过多。根据IETF RFC 6585,它包含"Retry-After"头。此网络爬虫错误通常意味着可预测或激进的爬取。理解速率限制是关键。服务器使用如令牌桶等算法管理流量,阻止超过限制的爬虫。
在2026年,429错误的含义已超越简单的每分钟请求数。现代系统使用"滑动窗口"日志来管理更长期的请求密度。一小时内高流量可能触发封锁,即使短期限制未被突破。一些服务器使用429作为永久IP封锁的前兆。早期识别可让策略调整,避免被永久标记。将429视为反馈,可优化爬虫以实现长期稳定性。
500 内部服务器错误 & 502 错误网关
这些服务器端错误表示网站本身存在问题,而非直接与您的爬虫请求相关。500错误表示服务器遇到意外情况。502错误通常表示代理服务器从上游服务器接收到无效响应。虽然您无法直接修复,但爬虫应设计为通过重试和日志记录来优雅处理这些错误。如果这些错误持续存在,可能表示目标网站本身存在问题,或您的请求无意中触发了服务器端异常,如意外数据或行为。
Cloudflare特定错误(如1001 DNS解析错误)
安全提供商常引入自己的错误代码。Cloudflare作为广泛使用的服务,可能带来各种挑战。例如,1001错误通常指向DNS解析问题或与Cloudflare网络连接问题。其他Cloudflare挑战可能涉及JavaScript重定向或验证码页面。克服这些需要特殊技术,如动态调整用户代理或使用无头浏览器。CapSolver提供这些场景的解决方案;了解如何更改用户代理以解决Cloudflare挑战。有关更通用的Cloudflare集成,参见Cloudflare PHP。
常见网络爬虫错误对比总结
| 错误代码 | 主要原因 | 严重程度 | 推荐解决方案 |
|---|---|---|---|
| 400 错误请求 | 格式错误的请求语法 | 低 | 请求验证 |
| 401 未授权 | 缺失/无效的认证 | 中 | 会话/令牌管理 |
| 402 需要付款 | 超出免费套餐/需要订阅 | 低 | 审查服务计划 |
| 403 禁止访问 | IP黑名单、User-Agent过滤 | 高 | IP轮换、头部优化 |
| 429 请求过多 | 基于IP或会话的速率限制 | 中 | 限流 & IP轮换 |
| 500 内部服务器错误 | 服务器端问题 | 低 | 优雅重试、日志记录 |
| 502 错误网关 | 代理/上游服务器问题 | 低 | 优雅重试、日志记录 |
| 1001 Cloudflare错误 | DNS/网络问题、安全挑战 | 高 | 用户代理、无头浏览器、CapSolver |
2026年网络爬虫为何失败
数据收集的环境已发生变化。根据Imperva 2025 恶意机器人报告,自动化流量现在占所有互联网活动的37%。因此,网站已实施高级行为分析。如果您的爬虫无法处理交互元素或无法保持一致的数字指纹,它将很可能失败。
当脚本未考虑其流量的"未验证"性质时,常见网络爬虫错误就会发生。根据WP Engine 2025 报告,76%的机器人流量是未验证的,成为速率限制的首要目标。为了保持运行,您的基础设施必须通过正确的头部管理和真实交互模式证明其合法性。
网络爬虫错误的实用解决方案
解决网络爬虫错误需要多层方法。您不能简单地"强行突破"速率限制;必须适应它们。
1. 实施指数退避
在失败后,脚本应等待递增的时间段,以尊重服务器资源。如1、2、4秒的序列可减少429错误频率。对于高级用法,添加"随机延迟"——在等待时间中加入随机性,以防止多个爬虫同时重试,避免意外DDoS和IP封锁。
在2026年,"去相关随机延迟"也被使用,通过随机因子计算等待时间,以实现不可预测的重试模式。将指数退避与智能随机延迟结合,可创建类似人类的请求模式,这对绕过高流量网站的敏感速率限制至关重要。
2. 策略性IP轮换
单一IP容易被速率限制。使用住宅或移动代理池可分散请求负载,使协调爬取更难被检测。为避免IP封锁,多样化的代理池至关重要。数据中心代理常因已知服务器范围被封锁。住宅代理使用家庭用户IP,更易融入网络。
到2026年,移动代理更受青睐。它们使用蜂窝网络IP,由许多合法用户共享,使服务器不愿封锁它们,以免影响客户。轮换移动IP可显著降低网络爬虫错误率。实施"粘性会话",一个代理IP处理完整用户流程后再轮换,以保持一致性并防止"瞬移"用户行为。
3. 头部和User-Agent优化
HTTP头部显示您的身份。默认库头部(如Axios)会显示为机器人。为解决此网络爬虫错误,使用与当前浏览器版本匹配的最佳User-Agent字符串。User-Agent、Accept-Language和Sec-CH-UA头部必须一致。2026年的现代网站使用"客户端提示"(Sec-CH头部)获取设备信息。User-Agent和客户端提示不匹配(如Windows vs. Linux)会导致立即被标记。
头部顺序也至关重要。真实浏览器按特定顺序发送头部。如果您的脚本偏离,安全过滤器会检测到。使用固定头部顺序的库或浏览器工具。"Referer"和"Origin"头部可增强合法性;例如,将Referer设置为搜索结果页面,以模拟自然用户行为。这一细节可区分基础脚本和专业数据提取工具。
4. 处理CAPTCHA和交互挑战
网站在检测到可疑活动时会部署CAPTCHA或交互挑战,这是常见的网络爬虫错误。CapSolver可自动解决这些挑战,确保爬取不间断。对于reCAPTCHA、hCaptcha或自定义挑战,CapSolver能高效地将解决方案集成到您的工作流中。了解更多关于这些挑战的网络自动化失败信息,请参见为什么网络自动化在验证码上持续失败。
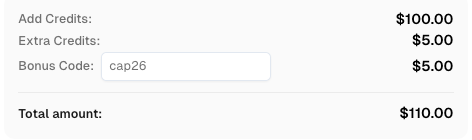
在CapSolver注册时使用代码
CAP26以获得额外积分!
处理平台特定挑战
网站对自动化的容忍度各不相同。理解这些细微差别对专业开发人员至关重要。2026年,"一刀切"的爬取方法已过时;需根据每个目标的特定防御调整逻辑。
电商和零售
大型零售网站在旺季会严格限制请求频率。此处的429错误通常表示请求频率过高。使用集成Playwright的工具可模拟真实用户流程(点击、滚动),降低被标记风险。零售商还会检测"爬取签名",如仅API的JSON请求。为避免此网络爬虫错误,您的爬虫应偶尔加载图片和CSS,以模拟完整浏览器体验。
房地产和金融数据
这些行业对宝贵数据保护严格,使用"按意图的速率限制",监控访问页面类型。仅访问高价值列表而未探索"关于我们"或"联系我们"页面会显示非人类行为。为解决此网络爬虫错误,将数据收集与"低价值页面"的"噪声请求"混合,以稀释足迹并模拟好奇用户。确保正确处理重定向,因为许多金融网站使用临时重定向来挑战可疑客户端。
社交媒体和视频平台
社交媒体和视频平台对数据收集敏感,常检查浏览器指纹。使用Node.js中的Axios时,需正确管理Cookie和会话令牌。对于交互挑战,CapSolver可自动解决,无需人工干预,防止自动化收集。
2026年的高级策略
在2026年,"成功"的爬虫意味着高效且符合伦理的数据获取,而不仅仅是数据提取。
自适应速率限制
监控服务器响应时间而非使用固定延迟。如果延迟增加,主动减慢请求,防止429错误。这种主动方法优于被动响应封锁。
浏览器指纹管理
现代安全系统分析的不仅是IP和User-Agent。它们还会检查画布渲染、WebGL功能和电池状态。伪造这些属性是大规模数据收集的必要条件。
结论
解决网络爬虫错误需要持续优化。理解429错误的含义并实施IP轮换、头部优化和指数退避等解决方案可确保高成功率。目标是与合法流量融合。CapSolver为复杂交互挑战提供优势,在2026年的竞争性数据环境中保持领先。保持适应性,尊重服务器限制,构建可持续的数据管道。
常见问题
1. 429错误最常见的原因是什么?
超过服务器请求限制是常见原因,通常由于限流不足或数据量太大而IP地址不足。
2. 只通过更改IP地址可以解决403禁止访问错误吗?
更改IP地址可能会带来暂时的缓解,但403错误通常指向更深层次的浏览器指纹或请求头问题。您的整个请求配置必须看起来像真正的用户。
3. CapSolver如何帮助解决网络爬虫错误?
CapSolver自动化解决复杂的交互式挑战,防止爬虫程序卡顿或被标记,从而减少错误。
4. 在2026年抓取网站是否违法?
抓取公开数据通常合法,但需遵守服务条款、robots.txt和数据隐私法规,如GDPR。始终优先考虑道德的数据收集。
5. 我应该多久轮换一次User-Agent?
定期轮换您的User-Agent,确保每个都是现代且有效的字符串。前50个常见User-Agent的集合是一个良好的起点。


