如何在RoxyBrowser中通过CapSolver集成解决验证码

Ethan Collins
Pattern Recognition Specialist

RoxyBrowser通过API调用提供浏览器功能,可以与Selenium、Puppeteer和Playwright等自动化框架集成。其API设计用于通过编程方式打开真实的浏览器配置文件并附加您的自动化工具。每个端点的API有记录的速率限制,每分钟最多100次调用。
来源:https://faq.roxybrowser.org/en/guide/10-API
CapSolver提供了一个创建和轮询的API流程,返回您可以注入到页面中的CAPTCHA令牌。CapSolver支持多种CAPTCHA类型:
- reCAPTCHA v2:任务类型
ReCaptchaV2TaskProxyLess,返回gRecaptchaResponse - reCAPTCHA v3:任务类型
ReCaptchaV3TaskProxyLess,返回带有分数的gRecaptchaResponse - Cloudflare Turnstile:任务类型
AntiTurnstileTaskProxyLess,返回token查看文档
本指南展示了一个与框架无关的实际流程:通过API打开Roxy配置文件,附加您的自动化框架,使用CapSolver解决CAPTCHA,并注入令牌以继续。
什么是RoxyBrowser?
RoxyBrowser 是一个用于多账号的反检测浏览器,具有API自动化和多窗口同步器等功能。
对于自动化,API 是最相关的内容:
-
它支持Selenium、Puppeteer和Playwright集成。
-
请求必须包含
token请求头。 -
默认API主机是
http://127.0.0.1:50000(端口更改需要重启)。
什么是CapSolver?
CapSolver通过两次API调用来解决CAPTCHA:
createTask提交CAPTCHA参数getTaskResult轮询直到令牌准备就绪
对于reCAPTCHA v2,CapSolver返回 gRecaptchaResponse。
getTaskResult 每个任务最多允许120次查询,并且必须在任务创建后5分钟内调用。
RoxyBrowser API设置
1) 启用API并获取您的令牌
- 打开RoxyBrowser并进入 API。
- 将API开关设置为 启用。
- 复制API密钥(令牌)并确认主机/端口。
默认情况下,主机是 http://127.0.0.1:50000。如果更改端口,必须重启RoxyBrowser。
2) 获取工作区和配置文件ID
使用 /browser/workspace 获取工作区,然后使用 /browser/list_v3 列出配置文件。
python
import requests
BASE = "http://127.0.0.1:50000"
HEADERS = {"token": "YOUR_ROXY_API_KEY"}
workspaces = requests.get(f"{BASE}/browser/workspace", headers=HEADERS).json()
workspace_id = workspaces["data"]["rows"][0]["id"]
profiles = requests.get(
f"{BASE}/browser/list_v3",
params={"workspaceId": workspace_id},
headers=HEADERS
).json()
dir_id = profiles["data"]["rows"][0]["dirId"]3) 打开配置文件并捕获自动化端点
调用 /browser/open。响应包括:
ws:自动化工具的WebSocket接口http:自动化工具的HTTP接口driver:Selenium集成的WebDriver路径
不支持无头模式。
python
open_resp = requests.post(
f"{BASE}/browser/open",
json={"workspaceId": workspace_id, "dirId": dir_id, "args": []},
headers=HEADERS
).json()
ws_endpoint = open_resp["data"]["ws"]
http_endpoint = open_resp["data"]["http"]
driver_path = open_resp["data"]["driver"]4) 附加您的自动化框架
使用返回的端点来附加您的框架:
- Puppeteer/Playwright可以通过DevTools WebSocket或HTTP端点连接。
- Selenium可以使用
driver路径与调试器连接。
具体的附加步骤取决于您的框架,但 ws、http 和 driver 值会明确提供给自动化工具。
CapSolver助手(Python)
python
import time
import requests
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
CAPSOLVER_BASE = "https://api.capsolver.com"
def create_task(task):
payload = {"clientKey": CAPSOLVER_API_KEY, "task": task}
r = requests.post(f"{CAPSOLVER_BASE}/createTask", json=payload)
data = r.json()
if data.get("errorId", 0) != 0:
raise RuntimeError(data.get("errorDescription", "CapSolver错误"))
return data["taskId"]
def get_task_result(task_id, delay=2):
while True:
time.sleep(delay)
r = requests.post(
f"{CAPSOLVER_BASE}/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
)
data = r.json()
if data.get("status") == "ready":
return data["solution"]
if data.get("status") == "failed":
raise RuntimeError(data.get("errorDescription", "任务失败"))
def solve_recaptcha_v2(website_url, website_key):
task = {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key
}
task_id = create_task(task)
solution = get_task_result(task_id)
return solution.get("gRecaptchaResponse", "")
def solve_recaptcha_v3(website_url, website_key, page_action="verify"):
task = {
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key,
"pageAction": page_action
}
task_id = create_task(task)
solution = get_task_result(task_id)
return solution.get("gRecaptchaResponse", "")
def solve_turnstile(website_url, website_key, action=None, cdata=None):
task = {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key
}
# 如果提供,添加可选的元数据
if action or cdata:
task["metadata"] = {}
if action:
task["metadata"]["action"] = action
if cdata:
task["metadata"]["cdata"] = cdata
task_id = create_task(task)
solution = get_task_result(task_id)
return solution.get("token", "")参考资料:
端到端流程:reCAPTCHA v2
-
通过
/browser/open打开Roxy配置文件 并附加您的自动化框架。 -
导航到目标页面 并提取站点密钥。
示例:javascriptconst siteKey = document.querySelector(".g-recaptcha")?.getAttribute("data-sitekey"); -
使用上面的助手用CapSolver解决。
-
注入令牌并提交表单:
javascriptconst token = "CAPSOLVER_TOKEN"; const el = document.getElementById("g-recaptcha-response"); el.style.display = "block"; el.value = token; el.dispatchEvent(new Event("input", { bubbles: true })); el.dispatchEvent(new Event("change", { bubbles: true }));
端到端流程:reCAPTCHA v3
reCAPTCHA v3的工作方式不同——它在后台运行,并返回一个分数(0.0到1.0),而不是需要用户交互。
-
从页面中提取站点密钥和操作:
javascript// 站点密钥通常在脚本或元标签中 const siteKey = document.querySelector('[data-sitekey]')?.getAttribute('data-sitekey'); // 操作在 grecaptcha.execute 调用中找到 // 在页面源代码中搜索:grecaptcha.execute('KEY', {action: 'ACTION'}) const pageAction = "submit"; // 或 "login", "register" 等 -
用CapSolver解决:
pythontoken = solve_recaptcha_v3( website_url="https://example.com/login", website_key="6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxAA", page_action="login" ) -
注入令牌(与v2相同):
javascriptconst token = "CAPSOLVER_TOKEN"; document.getElementById("g-recaptcha-response").value = token; // 如果有回调,触发它 if (typeof ___grecaptcha_cfg !== 'undefined') { const clients = ___grecaptcha_cfg.clients; Object.keys(clients).forEach(key => { if (clients[key].callback) { clients[key].callback(token); } }); }
端到端流程:Cloudflare Turnstile
Cloudflare Turnstile 是一种现代的CAPTCHA替代方案,解决速度更快(1-20秒)。
-
提取Turnstile站点密钥:
javascriptconst siteKey = document.querySelector('.cf-turnstile')?.getAttribute('data-sitekey'); // 可选:提取操作和cdata(如果存在) const action = document.querySelector('.cf-turnstile')?.getAttribute('data-action'); const cdata = document.querySelector('.cf-turnstile')?.getAttribute('data-cdata'); -
用CapSolver解决:
pythontoken = solve_turnstile( website_url="https://example.com", website_key="0x4AAAAAAAxxxxxxxxxxxxxxx", action=action, // 可选 cdata=cdata // 可选 ) -
注入Turnstile令牌:
javascriptconst token = "CAPSOLVER_TURNSTILE_TOKEN"; // 查找Turnstile响应输入 const input = document.querySelector('input[name="cf-turnstile-response"]'); if (input) { input.value = token; input.dispatchEvent(new Event('input', { bubbles: true })); input.dispatchEvent(new Event('change', { bubbles: true })); } // 可选:某些网站使用不同的输入名称 const altInput = document.querySelector('input[name="turnstile-response"]'); if (altInput) { altInput.value = token; }
最佳实践
- 遵守RoxyBrowser的API速率限制:每个端点每分钟最多100次调用。
- CapSolver 的
getTaskResult在5分钟内最多允许120次轮询。 - 如果令牌被拒绝,请使用重试逻辑和退避机制。
- 当目标网站验证令牌来源时,保持求解器IP和浏览IP一致。
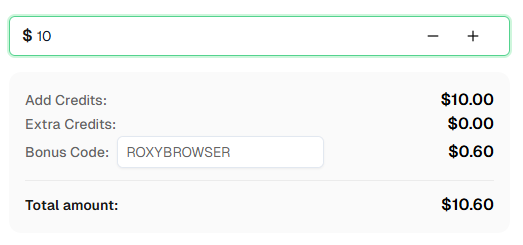
准备好开始了吗? 注册CapSolver 并使用优惠码 ROXYBROWSER 在首次充值时获得额外6%的奖励!
常见问题
-
RoxyBrowser是否支持Selenium、Puppeteer和Playwright?
是的。API专为与这些框架集成而设计。 -
我在哪里获取API令牌和主机?
在RoxyBrowser的 API -> API配置 中。默认主机是http://127.0.0.1:50000。 -
/browser/open返回什么?
它返回自动化工具使用的ws、http和driver字段。 -
支持无头模式吗?
不支持。 -
CapSolver支持哪些CAPTCHA类型?
-
CapSolver如何返回reCAPTCHA v2令牌?
创建一个ReCaptchaV2TaskProxyLess任务,并轮询getTaskResult以获取gRecaptchaResponse。 -
reCAPTCHA v3与v2有何不同?
reCAPTCHA v3在后台运行,无需用户交互,并返回一个分数(0.0-1.0)。它需要pageAction参数,该参数可以通过在页面源代码中搜索grecaptcha.execute找到。 -
如何解决Cloudflare Turnstile?
使用任务类型AntiTurnstileTaskProxyLess,并提供websiteURL和websiteKey。如果小部件上存在,可选地包括metadata.action和metadata.cdata。Turnstile的解决时间在1-20秒之间。
进一步阅读: -
如何找到Turnstile站点密钥?
查找.cf-turnstile元素上的data-sitekey属性。Turnstile站点密钥以0x4开头。 -
我需要为CapSolver使用代理吗?
不需要,*ProxyLess任务类型使用CapSolver内置的代理基础设施。如果您需要使用自己的代理,请使用非-ProxyLess变体。
结论
RoxyBrowser为您提供基于配置文件的浏览器环境和自动化端点,而CapSolver提供程序化的CAPTCHA令牌。通过打开Roxy配置文件,附加您的框架,并注入CapSolver令牌,您可以构建可靠的CAPTCHA感知自动化流程。


