2026年における一般的なウェブスクリーピングエラーの解決方法

Nikolai Smirnov
Software Development Lead

TL;Dr:
- 多様なエラー処理: 4xxクライアントエラー(400、401、402、403、429)とCloudflareの1001などの特定プラットフォームエラーに対処します。
- 適応戦略: 指数バックオフ、動的IPローテーション、高度なヘッダー最適化を実装して、人間の行動を模倣します。
- CapSolverの役割: CapSolver を利用して、さまざまなウェブスクレイピングエラーコードをトリガーするCAPTCHAや複雑なインタラクティブなチャレンジを自動的に解決します。
- 未来に向けたスクリーピング: 行動分析とブラウザフィンガープリント管理を採用して、2026年の進化するウェブセキュリティ環境に対応します。
はじめに
2026年のデータ抽出市場は11億7000万ドルに達し、ウェブスクリーピングはその中で不可欠な存在となっています。しかし、データ収集の複雑さが増す一方で、障壁も増加しています。開発者は頻繁にステータスコードに直面し、429エラーは一般的な障害となっています。このガイドでは、一般的なウェブスクリーパーエラーの特定、トラブルシューティング、解決方法について探ります。プロフェッショナルな戦略で高い成功確率を達成する方法を学び、2026年の複雑なセキュリティ環境に耐えうるデータパイプラインを構築します。
多様なウェブスクリーパーのエラーの理解
429エラーの意味だけでなく、スクリーピング操作を妨げるHTTPステータスコードの幅広い範囲が存在します。各コードは異なる根本的な問題を示しており、解決にはカスタマイズされたアプローチが必要です。これらのシグナルを理解することは、堅牢なスクリーピングインフラを構築するための基本です。
400 Bad Request
このウェブスクリーパーのエラーは、クライアント側の問題によりサーバーがリクエストを処理できないことを示します。例えば、不正な構文、無効なリクエストメッセージのフォーマット、またはだましのリクエストルーティングが原因です。一般的な原因には、誤ったURLパラメータ、無効なJSONペイロード、または非標準的なHTTPメソッドが含まれます。400エラーを解決するには、ターゲットAPIやウェブサイトの期待される形式にリクエスト構造を正確に検証する必要があります。すべての必須フィールドが存在し、正しい形式で記述されていることを確認してください。デバッグツールを使用すると、正確な不正な構造を特定できます。
401 Unauthorized
401エラーは、リソースにアクセスするための有効な認証資格情報がリクエストに含まれていないことを示します。これは、ログイントークン、APIキー、またはセッションクッキーが必要な保護されたコンテンツをスクリーピングする際に頻繁に発生します。スクリーパーが401エラーに遭遇した場合、認証メカニズムが欠如している、期限切れになっている、または誤っていることを意味します。解決策には、セッションクッキーの適切な管理、認証トークンの更新、またはOAuthフローへの統合が含まれます。複雑な認証シナリオの場合、セッションの永続性を扱うツールは非常に役立ちます。
402 Payment Required
一般的なウェブスクリーピングではあまり見られない402エラーは、特定の文脈で現れることがあります。特に、有料APIやサービスで発生します。これは、クライアントがリクエストされたリソースにアクセスするためには支払いが必要であることを示します。スクリーピングの文脈では、無料トライアルの上限に達したか、必要なサブスクリプションなしでプレミアムデータにアクセスしようとしている可能性があります。このウェブスクリーパーのエラーは、通常、サービスの料金モデルを確認するか、無料トライアルデータに合わせたデータ取得戦略を調整する必要があります。
403 Forbidden
403 Forbiddenエラーは、サーバーがリクエストを理解しているが、満たすことを拒否する強力なシグナルです。これは、IPブラックリスト、User-Agentフィルタリング、またはその他の高度なセキュリティ対策が原因であることがよくあります。401とは異なり、認証は役立ちません。サーバーは単にアクセスを拒否します。このウェブスクリーパーのエラーに対処するには、IPアドレスのローテーション、User-Agent文字列の最適化、ブラウザフィンガープリントの管理などの戦略が含まれます。
429 Too Many Requests
HTTP 429ステータスコードは、時間枠内で過剰なリクエストが発生していることを示します。IETF RFC 6585によると、このコードには「Retry-After」ヘッダーが含まれています。この種のウェブスクリーパーのエラーは、予測可能または攻撃的なスクリーピングを示していることがよくあります。レートリミットの理解は、耐性の鍵です。サーバーは、トークンバケットなどのアルゴリズムを使用してトラフィックを管理し、制限を超えるスクリーパーをブロックします。
2026年における429エラーの意味は、単なる1分あたりのリクエスト数を超えています。現代のシステムでは、長期的なリクエスト密度を管理するために「スライディングウィンドウ」ログが使用されます。1時間の高ボリュームは、短期的な制限を満たしていてもブロックを引き起こす可能性があります。一部のサーバーでは、429が永久的なIPブロックの前触れとなることもあります。早期の認識により、永久的なフラグの付与前に戦略を調整できます。429をフィードバックとして扱うことで、スクリーパーを長期的な安定性に最適化できます。
500 Internal Server Error & 502 Bad Gateway
これらのサーバーサイドのエラーは、ウェブサイト側の問題を示しており、スクリーパーのリクエストとは直接関係ありません。500エラーは、サーバーが予期しない状態に遭遇したことを意味します。502エラーは、プロキシサーバーが上流サーバーからの無効な応答を受け取ったことを示します。これらを直接修正することはできませんが、スクリーパーはリトライとロギングでこれらを適切に処理するように設計されるべきです。これらのエラーが続く場合、ターゲットウェブサイト自体に問題があるか、予期しないデータや行動によりサーバーサイドの例外をトリガーしている可能性があります。
Cloudflare固有のエラー(例:1001 DNS解決エラー)
セキュリティプロバイダーはしばしば独自のエラーコードを導入します。Cloudflareは広く使用されているサービスであり、さまざまな課題を提示することがあります。たとえば、1001エラーは通常、DNS解決の問題やCloudflareネットワークへの接続の問題を示します。他のCloudflareの課題には、JavaScriptリダイレクトやCAPTCHAページが含まれます。これらの課題を乗り越えるには、動的にUser-Agentを調整するなどの専門的な技術が必要です。CapSolverはこれらのシナリオに対応するソリューションを提供しています。User-Agentを変更してCloudflareを解決する方法を学んで、効果的に対処してください。より一般的なCloudflareの統合については、Cloudflare PHPを参照してください。
一般的なウェブスクリーピングエラー比較要約
| エラーコード | 主な原因 | 情報レベル | 推奨される修正 |
|---|---|---|---|
| 400 Bad Request | 不正なリクエスト構文 | 低 | リクエスト検証 |
| 401 Unauthorized | 認証情報の欠如/無効 | 中 | セッション/トークン管理 |
| 402 Payment Required | 無料トライアルの上限超過/サブスクリプションが必要 | 低 | サービスプランの確認 |
| 403 Forbidden | IPブラックリスト、User-Agentフィルタリング | 高 | IPローテーション、ヘッダー最適化 |
| 429 Too Many Requests | IPまたはセッションに基づくレートリミット | 中 | スロットリング & IPローテーション |
| 500 Internal Server Error | サーバーサイドの問題 | 低 | フォールバックリトライ、ロギング |
| 502 Bad Gateway | プロキシ/上流サーバーの問題 | 低 | フォールバックリトライ、ロギング |
| 1001 Cloudflareエラー | DNS/ネットワークの問題、セキュリティチャレンジ | 高 | User-Agent、ヘッドレスブラウザ、CapSolver |
2026年のウェブスクリーパーが失敗する理由
データ収集の状況は変化しています。Imperva 2025 Bad Bot Reportによると、自動化されたトラフィックは現在、インターネット活動の37%を占めています。したがって、ウェブサイトは高度な行動分析を導入しています。あなたのスクリーパーがインタラクティブな要素を処理する能力がないか、一貫したデジタルフィンガープリントを維持できない場合、失敗する可能性が高いです。
スクリプトがトラフィックの「未検証」性を考慮しない場合、一般的なウェブスクリーパーのエラーが発生します。WP Engine 2025 Reportは、ボットトラフィックの76%が未検証であることを示しており、これはレートリミットの主な対象です。運用を維持するには、適切なヘッダー管理と現実的なインタラクションパターンを通じて、インフラストラクチャが正当性を証明する必要があります。
ウェブスクリーピングエラーの実践的な修正
ウェブスクリーピングエラーを修正するには、多層的なアプローチが必要です。単にレートリミットを乗り越えるだけではなりません。あなたはそれに適応する必要があります。
1. 指数バックオフの実装
失敗後に即座にリトライする代わりに、スクリプトは失敗後に増加する期間を待つべきです。これは、サーバーのリソースを尊重するものです。1、2、その後4秒のシーケンスは、429エラーの頻度を減らすことができます。高度な使用では、「ジッター(ランダム性)」を追加して、複数のスクリーパーが同時にリトライすることを防ぎ、意図しないDDoSやIPブラックリスト化を回避します。
2026年には、「非相関ジッター」も使用され、ランダムな要因を用いて予測不可能なリトライパターンを計算します。指数バックオフとスマートジッターを組み合わせることで、人間のようなリクエストパターンを作成し、高トラフィックウェブサイトの敏感なレートリミッターを回避するのに不可欠です。
2. 戦略的なIPローテーション
単一のIPアドレスは簡単にレートリミットされます。住宅用またはモバイルプロキシのプールにより、リクエスト負荷を分散させ、連携したクロールを検出するのが難しくなります。IPブロックを回避するために、多様なプロキシプールは必須です。データセンターのプロキシは、既知のサーバー範囲のためによくブロックされます。住宅用プロキシは、ホームユーザーのIPアドレスを使用し、より良いブレンドが可能です。
2026年には、モバイルプロキシが好まれます。これは、セルラーネットワークのIPアドレスを使用し、多くの正当なユーザーが共有しているため、サーバーが顧客への影響を考慮してブロックをためらう傾向があります。モバイルIPのローテーションは、ウェブスクリーパーのエラー率を大幅に減少させます。「スタックセッション」を実装し、1つのプロキシIPが一連のユーザー体験を処理した後、ローテーションを行うことで、一貫性を維持し、「テレポート」ユーザー行動を防ぎます。
3. ヘッダーとUser-Agentの最適化
HTTPヘッダーはあなたのアイデンティティを明らかにします。Axiosなどのデフォルトライブラリのヘッダーはボットを示しています。このウェブスクリーパーのエラーを修正するには、現在のブラウザバージョンに一致する最適なUser-Agent文字列を使用してください。User-Agent、Accept-Language、Sec-CH-UAヘッダーは一致している必要があります。2026年の現代的なウェブサイトは「クライアントヒント(Sec-CHヘッダー)」を使用してデバイスの詳細を取得します。User-AgentとClient Hintsの不一致(例:Windows vs. Linux)はすぐにフラグが付きます。
ヘッダーの順序も重要です。実際のブラウザは特定の順序でヘッダーを送信します。スクリプトが逸脱すると、セキュリティフィルターが検出します。固定ヘッダー順序用のライブラリやブラウザツールを使用してください。「Referer」および「Origin」ヘッダーは正当性を高めます。たとえば、製品ページのリクエストで「Referer」を検索結果ページに設定すると、自然なユーザーの進行を模倣します。この詳細は、基本的なスクリプトとプロフェッショナルなデータ抽出ツールの違いを示します。
4. CAPTCHAとインタラクティブなチャレンジの処理
ウェブサイトは、不審な活動を検出するとCAPTCHAまたはインタラクティブなチャレンジを展開します。これは一般的なウェブスクリーパーのエラーです。CapSolverはこれらを自動的に解決し、スクリーピングを中断することなく行います。reCAPTCHA、hCaptcha、またはカスタムチャレンジに対して、CapSolverはワークフローに効率的に統合されるソリューションを提供します。CAPTCHAでウェブオートメーションがなぜ失敗するのかについての詳細を学んでください。
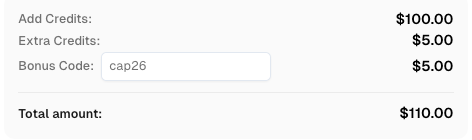
CapSolverで登録する際にコード
CAP26を使用すると、ボーナスクレジットを獲得できます!
プラットフォーム固有のチャレンジの処理
ウェブサイトは自動化の耐性に違いがあります。これらの違いを理解することは、プロフェッショナルな開発者にとって不可欠です。2026年には、「1つのサイズがすべてに合う」スクリーピングアプローチは時代遅れです。各ターゲットの特定の防御に論理をカスタマイズしてください。
エコマースと小売
大規模な小売サイトは、ピークシーズン中に積極的にレートリミットを実施します。ここでの429エラーの意味は、通常、コンシューマープロファイルに対して過剰なリクエスト頻度を示します。Playwrightの統合ツールを使用すると、クリックやスクロールなどのリアルユーザーの旅をシミュレートし、フラグの付与を減らすことができます。小売業者は「スクリーピングシグネチャ」、例えばAPIのみのJSONリクエストを検出します。このウェブスクリーパーのエラーを回避するには、スクリーパーが画像やCSSを時折読み込むことで、完全なブラウザ体験をシミュレートする必要があります。
不動産と金融データ
これらのセクターは、貴重なデータを厳しく保護しており、「意図によるレートリミット」を使用します。訪問されたページタイプを監視し、高価なリストのみを訪問して「About Us」や「Contact」ページを探索しないと、非人間的な行動と見なされます。このウェブスクリーパーのエラーを修正するには、低価値ページへの「ノイズリクエスト」をデータ収集に挟み込み、フットプリントを希釈し、好奇心のあるユーザーを模倣する必要があります。多くの金融サイトが不審なクライアントを挑戦するために一時的なリダイレクトを使用しているため、正しいリダイレクト処理を確保してください。
SNSと動画プラットフォーム
SNSや動画プラットフォームはデータ収集に敏感で、ブラウザフィンガープリントをチェックすることがよくあります。Node.jsのAxiosを使用する場合、クッキーとセッショントークンを適切に管理してください。インタラクティブなチャレンジの場合、CapSolverは手動の介入なしで複雑な検証ステップをナビゲートし、自動収集を妨げます。
2026年の高度な戦略
2026年における「成功した」スクリーパーとは、単にデータを取得するだけでなく、効率的で倫理的なデータ取得を意味します。
顕性レートリミット
サーバーの応答時間をモニタリングし、固定遅延を使用するのではなく、プロアクティブにリクエストを遅らせる。遅延が増加した場合は、429エラーを防ぐためにリクエストを積極的に遅らせる。このプロアクティブなアプローチは、ブロックに反応するよりも優れています。
ブラウザフィンガープリント管理
現代のセキュリティシステムはIPやUser-Agentだけでなく、キャンバスレンダリング、WebGLの機能、バッテリー状態もチェックします。高スケールのデータ収集では、これらの属性をスプーフィングすることが必須です。
結論
ウェブスクリーパーのエラーを解決するには、継続的な改善が必要です。429エラーの意味を理解し、IPローテーション、ヘッダー最適化、指数バックオフなどの解決策を実装することで、高い成功確率を確保できます。目標は、正当なトラフィックに溶け込むことです。CapSolverは、2026年の競争の激しいデータ環境における複雑なインタラクティブなチャレンジに特化したエッジを提供します。柔軟性を持ち、サーバーの制限を尊重し、持続可能なデータパイプラインを構築してください。
FAQ
1. 429エラーの最も一般的な原因は何ですか?
サーバーのリクエスト制限を超えることが最も一般的な原因であり、これは不十分なスローティングやデータ量に適切なIPアドレスが不足しているためです。
2. IPを変更するだけで403エラーを修正できますか?
IPを変更することで一時的な改善が得られるかもしれませんが、403エラーは通常、ブラウザの指紋やヘッダーの問題が原因です。あなたのすべてのリクエストプロフィールが本物のユーザーのように見える必要があります。
3. CapSolverはウェブスクレイピングエラーをどうやって解決しますか?
CapSolverは複雑なインタラクティブなチャレンジの解決を自動化し、スクレイパーが詰まったり、ブロックされたりすることを防ぎ、エラーを減らします。
4. 2026年にウェブサイトをスクレイピングすることは違法ですか?
公開データのスクレイピングは一般的に合法ですが、利用規約、robots.txt、GDPRなどのデータプライバシー法に従う必要があります。常に倫理的なデータ収集を最優先にしましょう。
5. User-Agentをどのくらいの頻度で変更すべきですか?
User-Agentを定期的に変更し、それぞれが現代的で有効な文字列であることを確認してください。上位50の一般的なUser-Agentのプールは良い出発点です。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。

Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
