即時データスカッパーのツール:コードなしでウェブデータを高速に抽出する方法

Nikolai Smirnov
Software Development Lead
TL;Dr: 主なポイント
- インスタントデータスカッパーのツールは、コードを書かずにウェブサイトから構造化されたデータを取得できる。
- ブラウザ拡張機能はシンプルな一回限りのタスクに最適で、APIベースのソリューションはスケーラビリティが向上している。
- 現代のツールはAIを使用してテーブルやリストを自動的に検出するため、データ準備にかかる時間が大幅に短縮される。
- 複雑なウェブサイトやセキュリティ対策がある場合は、CapSolverなどの専門的なソルバーを統合することで、データフローが途切れることなく保証される。
- 適切なツールの選択は、データのボリューム、頻度、ターゲットサイトの技術的な複雑さに依存する。
ウェブスカッピングは、複雑なコード作業からスムーズなプロセスに進化し、誰でも簡単にウェブから価値あるインサイトを収集できるようになりました。今日では、インスタントデータスカッパーのツールがマーケター、研究者、ビジネスオーナーに、ウェブページをブラウズするだけで数クリックで貴重な情報を収集する能力を提供しています。Pythonスクリプトや複雑な設定の必要性はなくなりました。価格をモニタリングするか、リード獲得リストを構築するかにかかわらず、適切なツールは手作業で何百時間もかかっていた作業を節約することができるでしょう。このガイドでは、コードなしでウェブデータを効率的に抽出する方法を紹介し、2026年のデータ戦略に最適なソリューションを選ぶお手伝いをします。
インスタントデータスカッパーの仕組み
インスタントデータスカッパーのツールという用語は、ウェブページから即座にデータを収集するためのソフトウェアのカテゴリを指します。従来のスカッパーが手動でセレクターのマッピングを必要とするのに対し、これらのツールはヒューリスティックアルゴリズムやAIを使用してHTML構造のパターンを認識します。これは、製品リスト、ニュースフィード、または検索結果を自動的に認識できるようにします。世界中のデータ生成と消費量は指数関数的に増加しており、高速な抽出ツールがより重要になっています。
ほとんどのインスタントデータスカッパーのツールはブラウザ拡張機能またはクラウドベースのAPIとして動作します。拡張機能は、現在表示しているページからのデータが必要な場合に最適です。一方、クラウドベースのツールは、同時に何千ものURLをスカッピングする大規模な運用に適しています。これらの違いを理解することが、データ収集ワークフローの最適化の第一歩です。
2026年のインスタントデータスカッパーのトップツール
ノーコード抽出の市場は大幅に成熟し、いくつかの優れたツールがリードを取っています。各ツールは、異なるユーザーのニーズに合わせて特徴がカスタマイズされています。現在利用可能なトップ評価のインスタントデータスカッパーのツールの比較は以下の通りです。
インスタントデータスカッパーの比較概要
| ツール名 | タイプ | 最適な用途 | 使用のしやすさ | スケーラビリティ |
|---|---|---|---|---|
| インスタントデータスカッパー | Chrome拡張機能 | 一括でテーブルを抽出するため | 高 | 低 |
| ScraperAPI | クラウドAPI | 大量の自動パイプライン | 中 | 高 |
| Octoparse | デスクトップアプリ | ページングがある複雑なサイト | 中 | 中 |
| WebScraper.io | 拡張機能 | ダイナミックコンテンツとサイトマップ | 中 | 中 |
| Data Miner | 拡張機能 | 人気のあるサイトの事前作成されたレシピ | 高 | 中 |
1. インスタントデータスカッパー(Chrome拡張機能)
これは初心者にとっておそらく最も人気のある選択肢です。AIを使用してページ上で最も関連性のあるデータを予測する無料のブラウザ拡張機能です。拡張機能のアイコンをクリックすると、検出されたテーブルやリストがすぐにハイライトされ、データのプレビューが表示されます。コードなしでウェブデータを迅速に抽出する最も効果的な方法の一つで、設定は一切必要ありません。
このツールは無限スクロールや「次の場所を検索」ボタンによるページングをサポートしています。これにより、検索結果の複数ページを手動で操作することなくスカッピングできます。ただし、これはブラウザ内でローカルで動作するため、何百万ものページをスカッピングするには適していません。また、強力なスカッピング防止対策を処理するには適していません。より堅牢なオプションを探している場合は、最高のデータ抽出ツールをチェックして、エンタープライズグレードのソリューションの広範な視点を得ることができます。
2. ScraperAPI DataPipeline
ブラウザ拡張機能だけでは物足りないユーザーのために、ScraperAPIは低コードのソリューションであるDataPipelineを提供しています。このツールは、URLのリストをアップロードし、構造化されたJSONまたはCSVデータを返すことで動作します。IPローテーションやヘッダー管理などの技術的なハードルを自動的に処理します。
APIベースのインスタントデータスカッパーのツールを使用する際の重要な利点は、一般的な制限を回避できるという点です。多くのウェブサイトは、自動トラフィックを識別しブロックするための高度な方法を使用しています。IPブロックを回避する方法を知るサービスを使用することで、データ収集が一貫して信頼性を保つことができます。
インスタントスカッピングの課題への対処
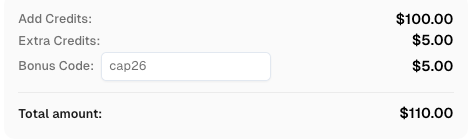
CapSolverに登録する際、コード
CAP26を使用してボーナスクレジットを取得してください!
インスタントデータスカッパーのツールは非常に強力ですが、現代のウェブサイトでは障壁に直面することがあります。CAPTCHAやボット検出システムなどのセキュリティ対策は、自動アクセスを防止するために設計されています。これは、通常のスカッパーが失敗し、データが不完全になったり、IPアドレスがブロックされたりする原因になります。
シームレスな抽出プロセスを維持するため、多くのプロフェッショナルはスカッパーを専門的なサービスと統合しています。たとえば、CapSolverは、複雑な検証課題を処理する重要なサポート層を提供しています。信頼できるソルバーを使用することで、最も保護されたウェブサイトにアクセスし、ボットとしてのフラグを立てることなく、インスタントデータスカッパーのツールを動作させることができます。これは、高頻度スカッピング中に頻繁に表示される私はボットではありませんのプロンプトを扱う際に特に重要です。
注目すべき必須機能
インスタントデータスカッパーのツールを評価する際には、長期的な目標に合った機能を優先する必要があります。今日では機能するツールでも、データニーズが成長するにつれて十分でなくなる可能性があります。以下の基準を考慮してください:
- 自動パターン認識: 手動でセレクターを入力することなく、リストやテーブルを識別する機能。
- ページングサポート: 「もっと読み込む」ボタン、無限スクロール、およびページ番号を処理できる能力。
- エクスポートオプション: 他のソフトウェアとの統合に便利なCSV、Excel、JSON形式のサポート。
- クラウド実行: ローカルマシンではなく、サーバーでスカッピングタスクを実行するオプション。
- アンチ検出統合: プロキシやCAPTCHAソルバーとの互換性により、高い成功率を維持。
インスタントデータスカッパーの使い方:ステップバイステップガイド
インスタントデータスカッパーのツールを使用するのは一般的に簡単です。ほとんどのツールは、スピードとシンプルさを重視した類似したワークフローに従います。以下に、数分でデータを抽出する方法を示します:
- ツールのインストール: Chrome Web Storeから拡張機能をダウンロードするか、クラウドベースのサービスに登録します。
- ターゲットサイトに移動: 抽出したいデータが含まれるウェブページを開きます。例えば、ECサイトのカテゴリページなど。
- スカッパーのアクティブ化: ツールのアイコンをクリックします。AIが検出されたデータ領域をハイライトします。
- 選択の調整: ツールが列を見逃した場合、通常はクリックして手動で追加できます。
- ページングの処理: データが複数ページにまたがる場合、「次の場所を検索」機能を使用してスカッパーをガイドします。
- データのダウンロード: 抽出が完了したら、お気に入りの形式にエクスポートします。
より高度なユーザーは、W3C WebDriver標準に従うことで、これらのツールがブラウザ環境とどのように相互作用するかをより深く理解することができるでしょう。
現代のデータ抽出におけるAIの役割
最新のインスタントデータスカッパーのツールは、人工知能(AI)によって大きく影響を受けています。AIにより、これらのツールはページのコードだけでなく、ページの文脈を理解できるようになります。たとえば、AIを備えたスカッパーは、HTMLタグが似ている場合でも、製品価格と割引価格を区別できます。
このインテリジェントな抽出へのシフトにより、2026年のノーコードウェブスカッピングツールはこれまでで最も信頼性が高くなっています。ウェブサイトがよりダイナミックで複雑になるにつれて、ユーザーの介入なしでレイアウトの変更に適応できるツールの能力は、大きな競争上の優位性となっています。これが、多くの企業が厳密なセレクターに基づくスカッパーから、より柔軟で即時的なソリューションに移行している理由です。
結論
インスタントデータスカッパーのツールの登場により、ウェブデータへのアクセスが民主化され、誰でもデータ駆動型の意思決定者になることが可能になりました。適切なツールを選択することで(シンプルな拡張機能で簡単なタスクを処理するか、大規模なプロジェクト用に堅牢なAPIを使用するか)、研究や運用を大幅に加速させることができます。成功するスカッピング戦略は、コードなしでウェブデータを迅速に抽出する方法と、CapSolverなどの専門的なサービスを組み合わせることで、セキュリティ上の課題を扱うことが多くなります。データパイプラインを構築する際には、スケーラビリティと信頼性に焦点を当て、インサイトが正確でタイムリーであることを確保してください。
FAQ
1. インスタントデータスカッパーのツールは使用することが合法ですか?
はい、公開されているデータのスカッピングは一般的に合法です。ただし、ウェブサイトの robots.txt ファイルや利用規約を尊重する必要があります。詳細については、データ収集の倫理と地域の規制に関する法的リソースを参照してください。
2. ログインが必要なウェブサイトをスカッピングできますか?
一部の最高のChrome用ウェブスカッパー拡張機能は、ブラウザのクッキーを使用してログインセッションを処理できます。ただし、クラウドベースのスカッパーは、認証を処理するためにより複雑な構成が必要です。
3. ブラウザ拡張機能とウェブスカッピングAPIの違いは何ですか?
拡張機能はブラウザで動作し、小規模なタスクに最適です。APIはリモートサーバーで動作し、はるかに高いボリュームと自動化の能力を提供します。
4. スカッピング中にCAPTCHAをどうやって処理しますか?
最も効果的な方法は、CapSolverなどの専門的なサービスを使用することです。これは、任意のウェブサイトワークフローでリアルタイムでチャレンジを解決するためにあなたの自動データ抽出に統合され、スカッパーが詰まることを防ぎます。
5. これらのツールを使用するにはHTMLを知らなければならないのですか?
HTML構造の基本的な知識は役立ちますが、ほとんどのインスタントスカッパーは技術的な知識なしで動作します。関心のあるユーザーは、W3C HTMLテーブル仕様を参照することで、ウェブ上のデータの整理方法について深く掘り下げることができます。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。

Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
