Rust Web Scraping Architecture for Scalable Data Extraction

Sora Fujimoto
AI Solutions Architect
TL;DR
- フェッチ、パース、レンダリング、ストレージを別々のレイヤーに分離することで、Rustウェブスクレイピングは最も効果的になります。
reqwestとscraperは、リソースコストが低くメンテナンスが簡単な多くの静的ターゲットをカバーします。- Tokioを使った非同期スクレイピングは、I/Oバウンドなワークロードのスループットを向上させますが、依然としてレートリミット、リトライ、キュー制御が必要です。
- JavaScriptでレンダリングされたページに対しては、ヘッドレスブラウザスクレイピングを選択的なフォールバックとして使用するべきです。
- ボット保護、プロキシローテーション、CAPTCHAイベントは、明確なポリシーとコンプライアンスに合った自動化設計で処理する必要があります。
- 実際のビジネスニーズに合った正当なオートメーションワークフローの場合、CapSolverは、公式APIフローに従って狭いフォールバックレイヤーに組み込むことができます。
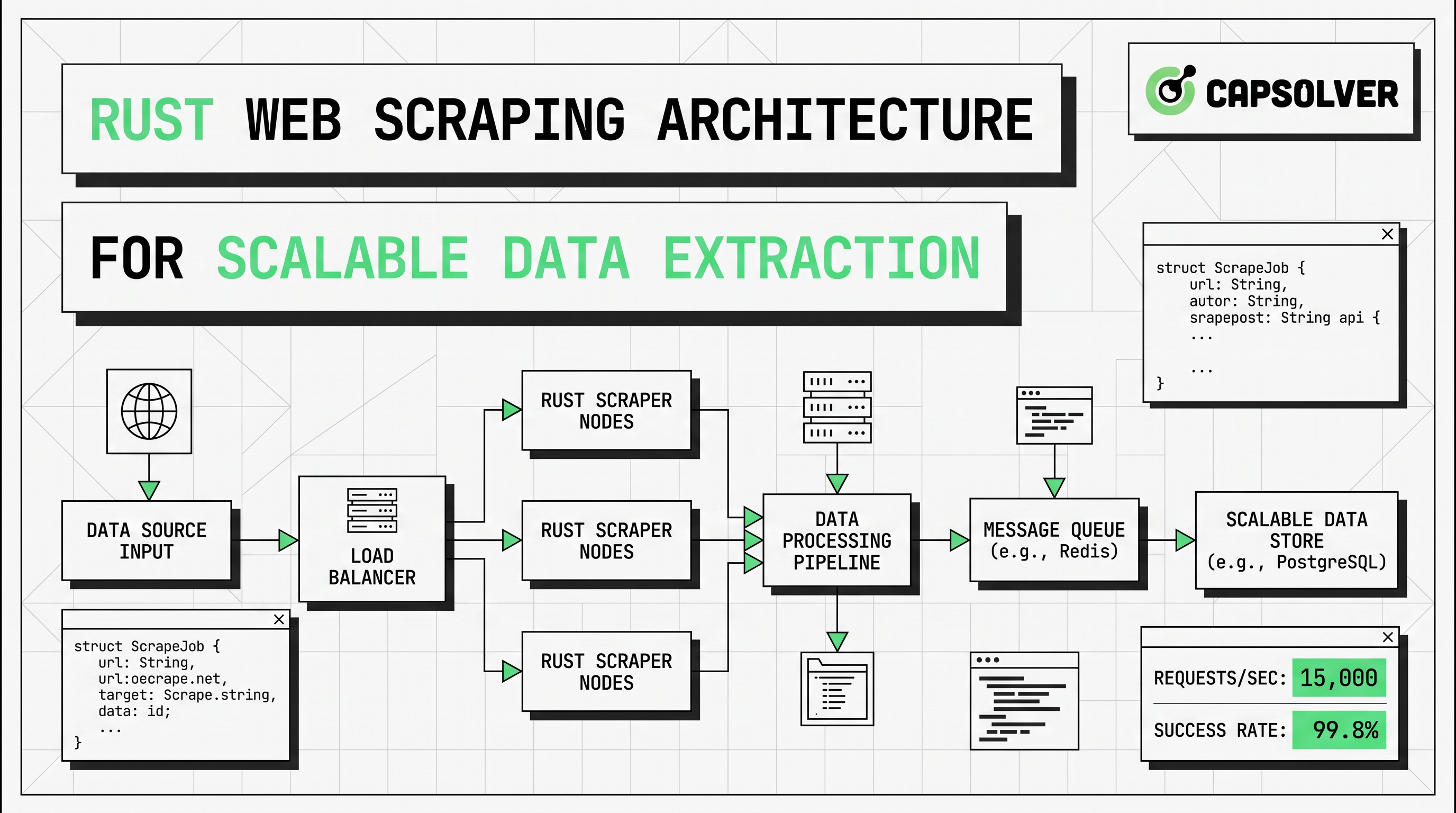
Rustウェブスクレイピングは、アーキテクチャとして設計されている場合に最も効果的です。この記事は、スケールで信頼性のある抽出が必要なエンジニア、データチーム、テクニカルオペレーター向けです。結論は最初に述べます:最適なRustウェブスクレイピングシステムは、reqwestとscraperで高速パスをシンプルに保ち、ターゲットが実際に必要とする場合にのみ非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、チャレンジ処理を追加します。この構造により、コストを削減し、安定性を向上させ、長時間実行されるパイプラインの観測性が向上します。
Rustウェブスクレイピング概要
Rustウェブスクレイピングは、大規模な抽出ジョブにおいて強力な選択肢です。メモリセーフティと予測可能なパフォーマンスを組み合わせるため、作業者が数千ページを処理し、不安定なマークアップをパースし、何時間も正規化されたレコードを書き込む場合に特に重要です。
上位検索結果の多くは、1つのページをフェッチし、セレクターをパースする方法を説明しています。この情報は有用ですが、より難しい質問には答えられません。スケーラビリティ、観測性、拡張の余地を考慮した場合、Rustウェブスクレイピングアーキテクチャはどのように見えるべきでしょうか?
プロダクション設計には、HTTPフェッチレイヤー、パーサーレイヤー、JavaScriptページ用のレンダリングブランチ、ストレージレイヤー、リトライ、メトリクス、リクエストペーシング用の運用レイヤーが必要です。正しい順序も重要です。最初は最も安価なパスから始めます。生のHTMLをフェッチします。必要なフィールドのみをパースします。サーバーHTMLにターゲットデータが含まれていない場合にのみ、ヘッドレスブラウザスクレイピングに進みます。トラフィックの分布や地域アクセスが必要な場合にのみプロキシローテーションを追加します。コンプライアンスに合ったオートメーションフローに正当な理由がある場合にのみCAPTCHA処理を追加します。
これらの境界を計画するチームにとって、ウェブクローリングとウェブスクレイピングは範囲を明確にし、構造化データを抽出する方法はフィールドマッピングが始まる前に役立つ内部リソースです。
Rustスクレイピングのコアライブラリ
Rustウェブスクレイピングは通常、3つの構築ブロックから始まります:reqwest、scraper、およびTokio。公式のreqwestドキュメントは、reqwestを非同期サポート、クッキー、リダイレクト、TLS、プロキシサポートを備えた高レベルHTTPクライアントとして説明しています。これは、Rustウェブスクレイピングの実用的なトランスポートレイヤーとして機能します。
公式のTokio非同期チュートリアルは、未来とエグゼキューターモデルが高コンカレンシーI/Oワークロードに適している理由を説明しています。これは、Rustウェブスクレイピングがリモートサーバーに待機する時間を多く費やすため、ローカルコンピューティングでCPUを消費するよりも重要です。
reqwestでHTTPリクエスト
reqwestはトランスポートレイヤーに配置されるべきです。1つのワーカーまたはワーカーグループごとに1つのクライアントを再利用してください。これにより、接続プーリングが効果的になり、ヘッダー、タイムアウト、クッキー、プロキシポリシーを1か所で定義できます。
rust
use reqwest::Client;
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let client = Client::builder()
.user_agent("Mozilla/5.0")
.build()?;
let html = client
.get("https://example.com")
.send()
.await?
.error_for_status()?
.text()
.await?;
let document = Html::parse_document(&html);
let card = Selector::parse("article")?;
for node in document.select(&card) {
println!("{}", node.text().collect::<Vec<_>>().join(" "));
}
Ok(())
}このパターンは静的ページでのRustウェブスクレイピングを効率的に保ちます。また、エラー処理の標準化も簡単になります。ステータスチェック、リトライ予算、構造化ロギングはすべてリクエストレイヤーの周りに配置され、パーサーコードに混ぜ込まれることはありません。
scraperでHTMLパース
scraperは、小さなテスト可能なパーサーレイヤーに配置されるべきです。テンプレートが変更される予定がある場合は、セレクターをネットワークロジックと混ぜないでください。強力なパーサーは生のHTMLを受け取り、型付きレコード、部分的なレコード、または明確な抽出エラーを返します。
この分離は、セレクターのずれが一般的であるため重要です。クラスが変更されることがあります。テキストが属性に移動するかもしれません。ターゲット要素の間に装飾用のノードが現れるかもしれません。Rustウェブスクレイピングでは、パーサーの隔離により、パイプラインが不完全なデータを書き込む前にテストでこれらの問題が見えるようになります。
非同期スクレイピングアーキテクチャ
非同期スクレイピングは、Rustウェブスクレイピングが中程度のインフラでスケールできる主な理由の1つです。ランタイムはウェブサイトの応答を速くしません。ネットワークやオリジン応答を待っている多くのリクエストの中で、ワーカーをより効率的にします。
スケーラブルなRustウェブスクレイピングパイプラインは、以下の構造をよく見かけます。
| レイヤー | 役割 | Rustデフォルト | 主なリスク |
|---|---|---|---|
| スケジューラー | URLと優先度を選択 | キューまたはチャネル | ピークトラフィック |
| フェッチャー | HTTPリクエストを送信 | reqwest::Client |
403、429、タイムアウト |
| パーサー | フィールドを抽出 | scraperセレクター |
テンプレートのずれ |
| レンダラー | JSページをロード | ヘッドレスブラウザスクレイピング | CPUとメモリコスト |
| チャレンジレイヤー | 許可されたCAPTCHAイベントを処理 | CapSolverフォールバック | 間違ったタスクタイプ |
| ストレージ | 正規化された出力を書き込む | JSON、CSV、DB | スキーマの不一致 |
| 観測性 | ヘルスと品質を追跡 | ログ、トレーシング、メトリクス | サイレントデータロス |
重要な設計ルールは選択的なエスカレーションです。すべてのターゲットを低コストパスで開始してください。返されたHTMLにすでにデータが含まれていれば、reqwestとscraperでそのまま進みます。ターゲットフィールドがハイドレーション、クライアントサイドレンダリング、またはブラウザイベント後にのみ表示される場合、そのページタイプのみをヘッドレスブラウザスクレイピングにルーティングします。承認されたワークフロー内でボット保護やCAPTCHAチェックが表示される場合、そのイベントのみを狭いフォールバックブランチにルーティングします。
これは多くのシステムが無駄になるポイントです。チームはすべてのリクエストに対してブラウザ自動化をデフォルトとしています。これによりコストが増加し、コンカレンシーが低下し、失敗の分類が難しくなります。HTTP Archive State of JavaScriptレポートによると、現代のページはJavaScriptに強く依存しており、選択されたレポートビューでのデスクトップJavaScriptの転送サイズの中央値は803.3KBで、外部スクリプトリクエストは23件です。これは一部のターゲットが必要なレンダリングを説明していますが、すべてのページにブラウザを使用する理由にはなりません。
JavaScriptでレンダリングされたページの処理
初期HTML応答後にデータが作成される場合、ヘッドレスブラウザスクレイピングは必要です。一般的なシグナルには、空のサーバーHTML、ハイドレーション後のコンテンツ挿入、無限スクロールリスト、またはユーザー操作後にフィールドが表示されるページが含まれます。
Rustウェブスクレイピングは、ブラウザレンダリングを普遍的なベースラインではなく、別個のブランチとして扱うべきです。クライアントリクエスト後にポップulatesされる製品グリッド、ブラウザでレンダリングされるダッシュボード、またはキー コンテンツがクリックやスクロールロジックの後ろに隠されているインターフェースに使用してください。ブラウザプールを小さく保ち、メインの非同期HTTPワーカーから隔離してください。
実用的な決定ルールは単純です。データが生のHTMLに含まれていれば、reqwestとscraperでそのまま進みます。フィールドがJavaScriptの実行後にのみ表示される場合、そのルートをヘッドレスブラウザスクレイピングに移動します。同じターゲットがボット保護コントロールを適用している場合、ネットワークポリシー、ブラウザ動作、フォールバック要件を一緒にレビューする必要があります。個別に修正するのではなく、一括で処理してください。
関連する内部リーディングとして、開発者向けブラウザ自動化とヘッドレスブラウザでのCAPTCHA解決の自動化はこの階層モデルに自然に適合します。
CAPTCHAとスクレイピングの制限
Rustウェブスクレイピングには常に制限があります。その一部は技術的なもので、他の一部は法的または運用上のものです。技術的な側面にはIPレピュテーション、セッション処理、ブラウザファINGERプリントチェック、隠しAPI、階層化されたボット保護が含まれます。運用上の側面にはリクエストペーシング、エラーバジェット、ターゲットサイトへのトラフィック影響が含まれます。
そのため、コンプライアンスはアーキテクチャに組み込まれる必要があります。Google Search Central robots.txtガイドは、robots.txtが主にクローラーのトラフィックを管理し、サイトへの過負荷を避けるために使用されることを説明しています。この点はRustウェブスクレイピングにとって重要です。適切に設計されたシステムは、データを抽出することだけでなく、負荷を制御し、不要なリクエストを減らし、収集行動を合理的に保つことを目指しています。
正当なオートメーションフローがCAPTCHAステップに遭遇した場合、CapSolverは焦点を当てたフォールバックサービスとして関連します。最も安全なアプローチは、カスタムリクエストフォーマットを発明するのではなく、公式ドキュメントに従うことです。CapSolver createTaskドキュメントは、標準的なリクエストボディのパターンを以下に示しています。
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey":"YOUR_API_KEY",
"appId": "APP_ID",
"task": {
"type":"ImageToTextTask",
"body":"BASE64 image"
}
}同じ公式フローは非同期タスク用のtaskIdを返し、その後getTaskResultで確認する必要があります。スケーラブルなRustウェブスクレイピングシステムでは、このチャレンジロジックは通常のフェッチおよびパースパスの外に保たれるべきです。これにより、通常のリクエストは高速で監視が容易になります。
CapSolverボーナスコードを取得する
すぐにオートメーション予算を増やそう!
CapSolverアカウントにチャージする際、ボーナスコード CAP26 を使用すると、すべてのチャージで 5%のボーナス を受け取れます — 限度はありません。
今すぐCapSolverダッシュボードで取得してください
大規模なデータ収集のためのRustスクレイパーのスケーリング
Rustウェブスクレイピングのスケーリングは、コードの量よりも制御に重点を置くべきです。アーキテクチャは、ドメインごとの並行性、リトライの上限、タイムアウト予算、出力検証を強制する必要があります。これらの制御がなければ、より速いワーカーはより速い失敗を生み出します。
プロキシローテーションはパーサーレイヤーではなくトランスポートレイヤーに配置されるべきです。リクエストがレートバランス、地域アクセス、またはワークロード隔離のためにIPアドレス間で配布される必要がある場合に使用してください。ポリシーを具体的に保ちます。ドメイン、エンドポイントクラス、またはワークロードタイプごとにローテーションしてください。セッションの連続性を破壊し、デバッグにノイズを追加するランダムなプロキシの変更を避けてください。
これはまた、内部サポートリソースが役立つポイントでもあります。最適なプロキシサービスはネットワーク戦略の評価に役立ち、ウェブスクレイピングの法的問題は収集量を拡大する前の役立つ内部チェックポイントです。
最も強力なRustウェブスクレイピングシステムは、抽出品質を直接測定します。成功率、空のフィールド率、セレクターのずれ、レンダリング比率、中央値フェッチ遅延、成功記録あたりのコストをトラッキングしてください。これらのメトリクスは、単純なHTMLパスがまだ十分であり、ヘッドレスブラウザスクレイピング、プロキシローテーション、チャレンジ処理がコストが高くなるかどうかを示します。
比較要約
| アプローチ | 最適な使用ケース | コストプロファイル | 信頼性プロファイル | ノート |
|---|---|---|---|---|
reqwest + scraper |
静的または軽く動的なページ | 低 | セレクターが安定している場合に高い | Rustウェブスクレイピングの最適なデフォルト |
| Tokioワーカーによる非同期スクレイピング | 複数のI/OバウンドURL | 低〜中 | レートリミットがあると高い | スループットを向上させるが、パーサー品質には影響しない |
| ヘッドレスブラウザスクレイピング | JavaScriptでレンダリングされたページ | 高 | 中 | 小さなプールに隔離する |
| プロキシローテーション | 分散レート制御とジオアクセス | 中 | 中 | トランジットアイデンティティが重要である場合に役立つ |
| CapSolverフォールバック | オートメーションフロー内の許可されたCAPTCHAイベント | イベントベース | 中〜高 | 公式ドキュメントに従って実装を一致させる |
結論
Rustウェブスクレイピングは、アーキテクチャが選択的である限りスケールします。高速パスにはreqwestとscraperを使用してください。ネットワークバウンドジョブでより多くのスループットが必要な場合は非同期スクレイピングを追加してください。本当にレンダリングが必要なページに対してのみヘッドレスブラウザスクレイピングを予約してください。プロキシローテーションとチャレンジ処理を制御されたフォールバックレイヤーとして保ちます。この設計により、コストを低く抑え、観測性を向上させ、パーサーのメンテナンスをはるかに簡単にすることができます。
現在のパイプラインがすべてのページをブラウザ経由でルーティングしている場合、最もクリーンな改善は通常、パスの分割です。静的ターゲットを単純なHTTPに戻します。JavaScriptページを小さなレンダリングブランチに保持します。チャレンジロジックを隔離します。この変更だけで、信頼性とユニット経済性の両方が向上することがよくあります。
FAQ
Rustウェブスクレイピングは、大規模なジョブでPythonよりも優れているのでしょうか?
Rustウェブスクレイピングは、長時間の安定性、コンカレンシー、メモリセーフティが最も重要である場合に強力な選択肢です。Pythonは依然として広範なスクレイピングエコシステムを持っていますが、ワーカーの効率と予測可能なパフォーマンスが主な優先事項である場合、Rustは魅力的です。
reqwestからヘッドレスブラウザスクレイピングに切り替えるのはいつですか?
サーバーHTMLに必要なフィールドが含まれていない場合にのみ切り替えます。ターゲットデータがハイドレーション、クライアントサイドイベント、または遅延したAPIリクエスト後に表示される場合、ヘッドレスブラウザスクレイピングが正当化されます。
Rustで非同期スクレイピングはどのように役立ちますか?
非同期スクレイピングは、Rustウェブスクレイピングで多くの待機中のリクエストをより少ない無駄なリソースで処理するのに役立ちます。I/Oバウンドワークロードのスループットを向上させますが、レートリミット、リトライロジック、パーサーテストが必要です。
常にプロキシローテーションが必要ですか?
いいえ、多くの仕事はそれなしでもうまく機能します。プロキシのローテーションは、地域アクセスが必要な場合、ドメインごとのトラフィック配分、または単一IP範囲からの集中度を下げる必要があるときに重要です。
どのようにしてコンプライアンスに沿ったワークフローでCAPTCHAページを処理すべきですか?
CAPTCHA処理は限定的で、ドキュメント化され、通常のフェッチパスから分離されている必要があります。正当なオートメーションワークフローで必要な場合、公式のCapSolverタスクフローを使用し、実装を公開されたドキュメントと一貫性を保つようにしてください。
もっと見る
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。

Web ScrapingFeb 03, 2026
RoxyBrowserでCAPTCHAを解決する方法(CapSolverの統合)
CapSolverをRoxyBrowserと統合して、ブラウザのタスクを自動化し、reCAPTCHA、Turnstile、その他のCAPTCHAを回避します。