Search API vs Knowledge Supply Chain: AI Data Infrastructure Guide

Anh Tuan
Data Science Expert
TL;DR
- search API tools are useful for fast discovery, but they do not cover the full needs of production AI systems.
- A knowledge supply chain includes discovery, extraction, validation, storage, orchestration, and monitoring.
- A SERP API helps collect ranked search results, while a web scraping API helps collect page-level content.
- Strong web data infrastructure depends on freshness, source quality, auditability, and policy-aware collection.
- An AI data pipeline should connect retrieval with parsing, enrichment, governance, and downstream model usage.
- For approved automation, teams may also need reliability layers when verification steps interrupt collection flows.
Introduction
The short answer is simple. A search API is a retrieval interface, while a knowledge supply chain is an operating model for AI data infrastructure. This article is for AI engineers, technical founders, SEO teams, and data platform builders who need current web data without losing control of quality or compliance. If you are choosing between a search interface, a SERP API, and a broader web data infrastructure stack, the right decision depends on risk, freshness, and downstream usage. The core value is practical clarity. You will see where each option fits, where it breaks, and how to design a more dependable AI data pipeline.
Introduction to Search APIs and Knowledge Supply Chains
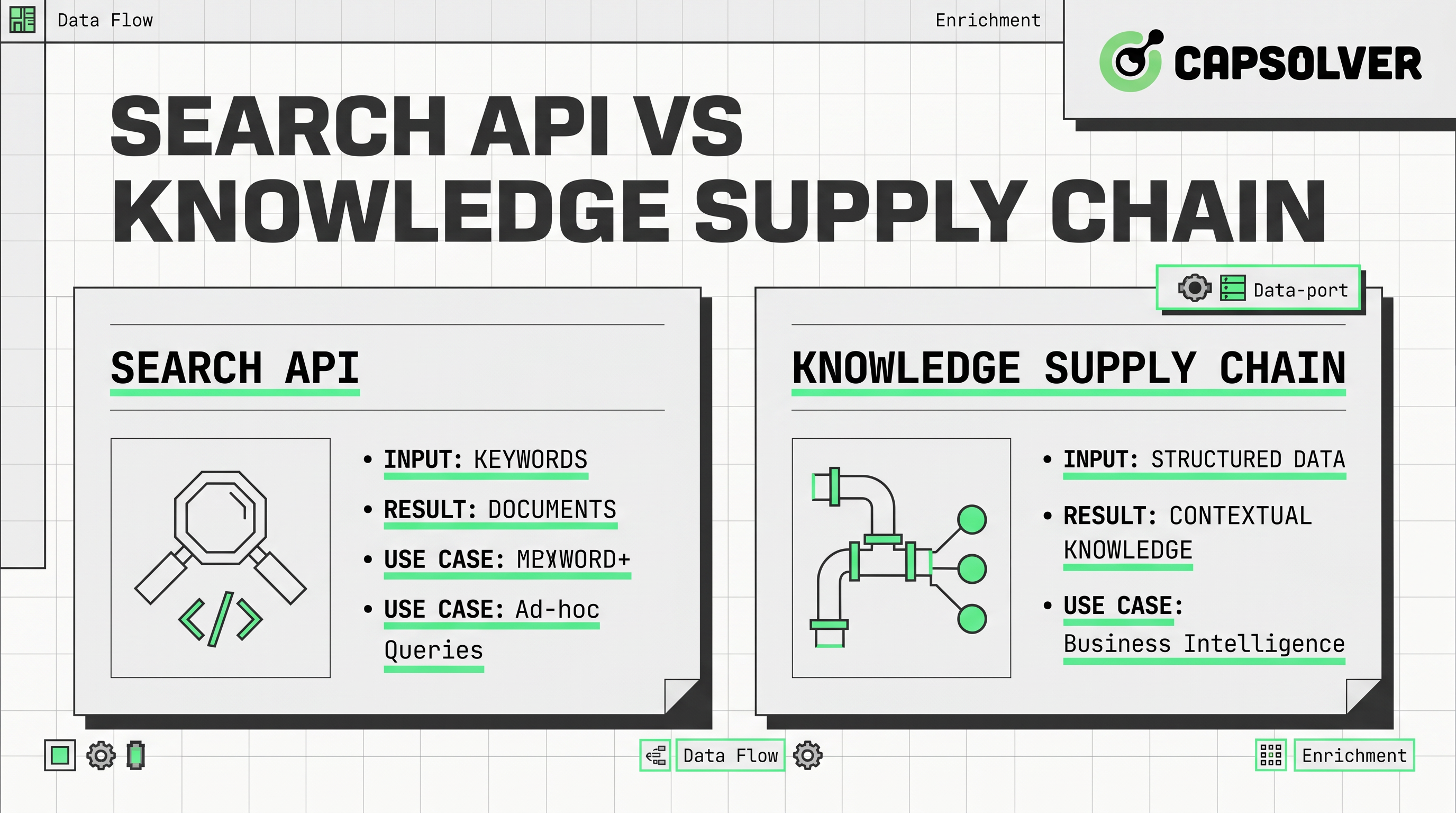
The main distinction is architectural. A search API usually accepts a query and returns ranked links, snippets, or summarized results from an index. That makes these tools attractive when teams need fast answers, lightweight enrichment, or early-stage prototypes.
A knowledge supply chain is broader by design. It treats data acquisition for AI as a continuous flow from source discovery to collection, validation, storage, transformation, and delivery. That model aligns better with agent systems, market intelligence tools, and retrieval layers that must support repeatable decisions.
This difference matters because AI systems act on what they receive. The NIST AI Risk Management Framework explains that trustworthy AI depends on design, development, use, and evaluation practices, not only model outputs. In practice, that means the retrieval layer is part of the risk surface.
Another reason is policy. Google Search Central states that robots.txt is used primarily to manage crawler traffic and is not a universal method for hiding content. That reminder matters for any team building web data infrastructure. Compliance starts before the first request.
How Search APIs Work in Data Retrieval Systems
The simplest description is this. A search API sits at the discovery layer. It converts a text query into ranked results that can feed chatbots, copilots, or research assistants.
Most search tools optimize for speed and developer convenience. That usually means indexed data, cached results, or a prebuilt relevance layer. For low-stakes tasks, this is enough. A support bot, an SEO ideation tool, or a prototype agent often benefits from this kind of retrieval endpoint because the system needs direction before it needs deep evidence.
A SERP API is narrower. It focuses on search engine result pages and related result elements. That can be useful for rank tracking, query monitoring, and competitive SEO research. However, a SERP API still reflects the search layer, not the full content layer. If your system needs actual page text, structured fields, or historical comparisons, you usually need another step.
This is where people confuse discovery with knowledge. Discovery tells you where to look. Knowledge requires fetching, parsing, and checking what is actually there. A search endpoint helps with the first part. It does not complete the whole AI data pipeline.
What Is a Knowledge Supply Chain in AI Architecture
The better way to define it is operationally. A knowledge supply chain is the system that moves data from the open web into decision-ready context for models, agents, and analysts.
The supply-chain idea appears across recent industry writing, but many articles stop at metaphor. The practical version has six layers. First comes discovery through search interfaces, a SERP API, feeds, sitemaps, or known sources. Second comes extraction through a web scraping API, browser automation, or direct source connectors. Third comes normalization, where HTML, JSON, PDFs, and metadata are transformed into consistent records. Fourth comes verification, which checks freshness, duplication, ownership, and source quality. Fifth comes storage and indexing for retrieval. Sixth comes orchestration, where an AI data pipeline sends the result into RAG systems, evaluators, or agent tools.
The Model Context Protocol offers a useful clue here. MCP documentation defines it as an open standard for connecting AI applications to data sources, tools, and workflows. It does not replace a search layer, but it shows why a knowledge supply chain must include interfaces beyond retrieval.
In short, a search API is a tool. A knowledge supply chain is a system.
Key Differences Between Search APIs and Knowledge Supply Chains
The clearest answer is in the operating constraints. A search API is usually optimized for fast lookup. A knowledge supply chain is optimized for data quality under real workloads.
Comparison Summary
| Dimension | search API | SERP API | Knowledge supply chain |
|---|---|---|---|
| Primary job | Query-based discovery | Search-result collection | End-to-end data acquisition for AI |
| Typical output | Links, snippets, summaries | Ranked SERP elements | Full content, metadata, history, validation |
| Best for | Prototypes, assistants, lightweight research | SEO monitoring, result tracking | Agents, intelligence systems, production AI |
| Freshness control | Limited and provider-dependent | Moderate at search layer | High when paired with direct collection |
| Evidence depth | Low to medium | Low to medium | High |
| Governance fit | Limited | Moderate | Strong |
| Role in AI data pipeline | First step | First step with SERP emphasis | Multi-stage operating model |
The competitive gap in current articles is practical guidance. Many posts explain why search tools are fast, or why knowledge supply chains sound strategic. Fewer explain where one ends and the other begins inside real web data infrastructure. That boundary is what determines system reliability.
A second difference is auditability. When a model answers from snippets alone, teams often cannot inspect the source transformation path. When a knowledge supply chain stores page content, timestamps, extraction logs, and quality checks, the same answer is easier to review and improve.
A third difference is failure cost. If a discovery API returns a stale summary, a prototype chat app may still feel acceptable. If the same issue affects pricing intelligence or policy monitoring, the cost can be much higher.
Use Cases in AI Agents and Data Infrastructure
The fit is easiest to see through use cases. A search API works well when the system needs quick orientation. An agent can use this retrieval layer to find candidate URLs, recent mentions, or topic clusters before deeper retrieval starts.
A SERP API works well when the task is search-facing. SEO teams use a SERP API for rank monitoring, paid and organic result analysis, and regional query testing. The output is useful, but it remains one layer of evidence.
A knowledge supply chain is better when the task is operational. Price monitoring, lead intelligence, policy tracking, catalog enrichment, procurement research, and news verification all require more than ranked results. They need extraction, timestamps, schema control, and a dependable AI data pipeline.
This is also where internal tooling matters. Teams building agents may combine AI agent frameworks, best data extraction tools, and scaling data collection for LLM training into one stack. Those components are easier to evaluate when you separate discovery, extraction, and orchestration rather than treating every upstream input as the same tool category.
Implications for Web Scraping and Data Engineering Tools
The biggest lesson is that retrieval alone does not produce trustworthy data. A web scraping API matters because it converts links into usable records. A data engineering layer matters because raw page content is inconsistent, noisy, and often duplicated.
That is why compliant collection design is important. Respect robots guidance, rate limits, access policies, and contractual restrictions. Google’s crawler guidance makes clear that traffic management and crawl behavior are part of the web’s normal operating environment. Good web data infrastructure should reduce server strain, document source rules, and preserve audit trails.
From a tooling view, the stack usually looks like this. A discovery API or SERP API identifies targets. A web scraping API or browser tool collects content. An AI data pipeline parses, enriches, and stores records. Evaluation tools score freshness and source trust. Then agent frameworks or RAG systems use the result.
Operational reliability also deserves a realistic note. Some approved automation flows encounter verification steps that interrupt collection or monitoring. In those cases, teams sometimes add a support service such as why web automation keeps failing on captcha or price monitoring AI agents to keep authorized workflows stable. If that is part of your stack, CapSolver is relevant because it offers documented API patterns for those scenarios.
The safest way to discuss CapSolver is to stay close to its official documentation. The example below mirrors the documented createTask request format from CapSolver’s API guide and should only be used in approved automation environments.
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey": "YOUR_API_KEY",
"appId": "APP_ID",
"task": {
"type": "ImageToTextTask",
"body": "BASE64 image"
}
}That example is not the core of a knowledge supply chain. It is a supporting reliability component. The main point remains the same. Discovery, collection, and governance should be designed together.
Redeem Your CapSolver Bonus Code
Boost your automation budget instantly!
Use bonus code CAP26 when topping up your CapSolver account to get an extra 5% bonus on every recharge — with no limits.
Redeem it now in your CapSolver Dashboard
Conclusion
The practical conclusion is straightforward. A search API helps systems find information, but a knowledge supply chain helps systems trust, reuse, and operationalize it. If your workload is exploratory, this retrieval layer may be enough. If your workload affects product, revenue, or compliance, you need broader web data infrastructure with extraction, validation, and storage built in.
For most teams, the winning design is hybrid. Use a discovery API or SERP API for discovery. Use a web scraping API for content collection. Then connect both into an AI data pipeline with clear source policies, monitoring, and review. That is the most durable path for data acquisition for AI.
If you are planning the next step, audit your current stack by layer. Ask where discovery ends, where evidence starts, and where governance is recorded. That exercise usually reveals whether you need a faster interface, a deeper pipeline, or both.
FAQ
Is a search API the same as a SERP API?
No. A search API is a broad retrieval interface, while a SERP API is focused on search engine result pages and related result elements.
When is this kind of retrieval interface enough for AI applications?
It is often enough for prototypes, internal assistants, low-risk research tasks, and early discovery steps in a pipeline.
What makes a knowledge supply chain better for production AI?
A knowledge supply chain adds extraction, normalization, validation, storage, and orchestration. Those layers improve freshness, auditability, and reuse.
Where does a web scraping API fit in this model?
A web scraping API sits after discovery. It turns URLs and source pages into structured content that an AI data pipeline can process.
Why mention CapSolver in an article about AI data infrastructure?
Because some approved automation workflows face verification interruptions after discovery. In that narrow context, CapSolver can support operational continuity as one component inside a broader, policy-aware system.
More
AIApr 28, 2026
AI Agents in Web Scraping & Competitive Intelligence Guide
Discover how AI agents transform web scraping and competitive intelligence. Learn about automated data collection, anti-bot challenges, and CAPTCHA solutions for scalable workflows.

AIApr 24, 2026
AI Agent vs Chatbot: Key Differences in Automation Capabilities
Discover the key differences between AI agent vs chatbot. Learn how agentic AI outperforms traditional AI in automation, decision-making, and complex workflows.


