AI Agents in Web Scraping & Competitive Intelligence Guide

Sora Fujimoto
AI Solutions Architect

TL;DR
- AI agents are autonomous software systems that plan, execute, and adapt multi-step data collection tasks without constant human input.
- In the ai agents industry, web scraping and competitive intelligence are among the fastest-growing application areas.
- AI agents can monitor competitor pricing, track product changes, and extract structured data at a scale no manual team can match.
- Modern websites deploy CAPTCHAs, rate limiting, and bot-detection layers that interrupt automated pipelines — CAPTCHA-solving services like CapSolver help agents maintain continuity.
- Responsible, compliant use of AI agents for data collection requires respecting robots.txt, terms of service, and applicable data regulations.
Introduction
AI agents are reshaping how businesses collect and act on external data. In the ai agents industry, two use cases have moved from experimental to production faster than almost any other: web scraping and competitive intelligence. Companies now deploy agents that autonomously browse the web, extract structured information, and feed it directly into pricing engines, market dashboards, and strategic reports — all without a human clicking a single button. This article explains what these agents are, how they work, where they add the most value, and what technical obstacles (including CAPTCHAs) teams must plan for when building compliant, production-grade pipelines.
What Are AI Agents, and Why Do They Matter for Data Collection?
An AI agent is a software program that perceives its environment, reasons about a goal, and takes a sequence of actions to achieve it — then adjusts based on what it observes. Unlike a simple script that follows a fixed path, an agent can decide which page to visit next, how to handle an unexpected layout change, and when to retry a failed request.
IBM defines AI agents as systems that combine perception, reasoning, and action in a continuous loop. That loop is exactly what makes them powerful for data collection: the web is messy, dynamic, and inconsistent, and a reasoning layer handles that variability far better than a rigid scraper.
The ai agents industry is growing at a remarkable pace. According to MarketsandMarkets, the global AI agents market is projected to grow from USD 7.84 billion in 2025 to USD 52.62 billion by 2030, at a CAGR of 46.3%. Research and data collection are among the top three production use cases already in deployment. The LangChain State of AI Agents Report found that 51% of surveyed companies already had agents running in production as of 2024, with research and data gathering cited as the leading application — ahead of customer service and personal productivity.
Core Architecture: How AI Agents Operate in Scraping Pipelines
Understanding the architecture helps teams build more reliable systems. A typical ai agents industry scraping pipeline has four layers:
1. Planning layer
The agent receives a high-level goal — for example, "collect daily pricing for the top 50 SKUs across three competitor sites." It breaks this into sub-tasks: identify URLs, schedule requests, define extraction schemas. In more advanced setups, the planning layer uses an LLM to generate a step-by-step execution plan that can be revised mid-run if conditions change.
2. Execution layer
The agent sends HTTP requests or controls a headless browser (Playwright, Puppeteer, Selenium). It parses HTML, JSON APIs, or rendered JavaScript content and maps it to a structured output format. The execution layer must handle pagination, infinite scroll, login flows, and dynamic content rendered client-side — all scenarios where a static scraper would fail.
3. Observation and adaptation layer
After each action, the agent checks the result. Did the page load correctly? Was the expected data present? Did a CAPTCHA appear? Based on the observation, it decides the next step — retry, escalate, or move on. This is the layer that makes agents genuinely different from scripts: they do not just execute, they evaluate.
4. Memory and storage layer
Extracted data is written to a database, data warehouse, or downstream pipeline. Some agents maintain short-term memory (session context) and long-term memory (historical price trends, known URL patterns). Long-term memory allows the agent to detect anomalies — for example, a price that drops 80% overnight is likely a data error, not a real discount.
This four-layer model is what separates a modern data collection pipeline from a traditional cron-job scraper. The agent is not just fetching pages — it is reasoning about the task, and that distinction matters at production scale.
Key Use Cases in Competitive Intelligence
Competitive intelligence is one of the highest-value applications of ai agents industry tooling. Here are the most common scenarios where teams deploy agents today:
Price Monitoring
E-commerce teams use agents to track competitor pricing across thousands of SKUs in near real time. The agent visits product pages, extracts price and availability data, and writes it to a pricing engine that can trigger automatic adjustments. Manual monitoring at this scale is not feasible — a single analyst might track 50 products per day; an agent can track 50,000.
The agent's observation layer is critical here. If a product page returns a 429 (Too Many Requests) status, the agent backs off and retries with exponential delay. If the page layout changes — a common occurrence during site redesigns — the agent can use an LLM to re-identify the price element rather than failing silently.
Product and Feature Tracking
SaaS companies deploy agents to monitor competitor changelog pages, release notes, and feature announcement blogs. When a competitor ships a new integration or changes a pricing tier, the agent flags it within hours rather than days. Product managers receive structured summaries rather than raw HTML dumps, because the agent's extraction layer maps content to a predefined schema: feature name, release date, affected tier, and summary.
This kind of continuous monitoring used to require a dedicated analyst. In the ai agents industry today, it runs as a scheduled background process.
Review and Sentiment Aggregation
Agents collect customer reviews from platforms like G2, Trustpilot, and app stores. Natural language processing layers then classify sentiment, extract recurring themes, and surface product gaps — giving product teams a continuous signal from the market. A team can identify that a competitor's users consistently complain about slow onboarding, then use that insight to sharpen their own positioning.
SERP and Content Monitoring
SEO and content teams use agents to track keyword rankings, monitor backlink profiles, and identify new content published by competitors. This feeds directly into editorial calendars and link-building strategies. Agents can also detect when a competitor publishes content targeting a keyword you currently rank for, triggering an alert before rankings shift.
Job Posting Intelligence
Tracking competitor job postings reveals strategic intent. A sudden spike in data engineering hires signals a platform rebuild. A cluster of enterprise sales roles suggests a market expansion. Agents can monitor career pages daily and aggregate this signal automatically, giving strategy teams a leading indicator that is often more reliable than press releases.
For a broader look at how scraping tools are evolving to support these workflows, see Top Web Scraping Tools in 2026 and Best Data Extraction Tools.
Comparison: Traditional Scrapers vs. AI Agents
| Dimension | Traditional Scraper | AI Agent |
|---|---|---|
| Task definition | Fixed selectors, rigid paths | Goal-based, adaptive |
| Handling layout changes | Breaks, requires manual fix | Detects and adapts |
| Multi-step navigation | Limited | Native capability |
| Error recovery | Manual intervention | Autonomous retry logic |
| CAPTCHA handling | Blocks pipeline | Can integrate solving services |
| Scalability | Linear with engineering effort | Scales with compute |
| Compliance awareness | None built-in | Can be instructed to respect rules |
The CAPTCHA Problem: Where AI Agents Hit a Wall
Even the most sophisticated ai agents industry pipeline will eventually encounter a CAPTCHA. Websites use them as a primary defense against automated access. The most common types include:
- reCAPTCHA v2 — image-selection challenges ("select all traffic lights")
- reCAPTCHA v3 — invisible, score-based risk assessment
- Cloudflare Turnstile — a newer, privacy-focused challenge that replaces traditional CAPTCHAs
- GeeTest — slider and behavioral challenges common on Asian platforms
When an agent hits a CAPTCHA, the pipeline stalls. The agent cannot proceed without a valid token or a completed challenge. This is a structural problem, not an edge case — high-value data sources are almost always protected.
The compliant solution is to integrate a CAPTCHA-solving API into the agent's observation layer. When the agent detects a challenge, it passes the relevant parameters to the solving service, receives a token, and injects it into the request to continue. The agent never needs to stop.
CapSolver is an AI-powered CAPTCHA-solving service built specifically for this integration pattern. It supports reCAPTCHA v2/v3/Enterprise, Cloudflare Turnstile, GeeTest, and AWS WAF CAPTCHA. Solutions are returned in 1–5 seconds via a REST API, with no human involvement — the entire flow stays automated.
For teams building ai agents industry pipelines in Python, the integration follows the pattern documented in CapSolver's official API documentation. The agent submits a task, polls for the result, and uses the returned token to complete the protected request. This keeps the pipeline running without manual intervention.
You can also explore how to solve CAPTCHAs while web scraping for a practical walkthrough of common integration patterns.
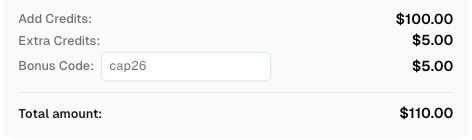
Redeem Your CapSolver Bonus Code
Boost your automation budget instantly!
Use bonus code CAP26 when topping up your CapSolver account to get an extra 5% bonus on every recharge — with no limits.
Redeem it now in your CapSolver Dashboard
AI Agent Frameworks Used in Scraping Workflows
Several open-source and commercial frameworks have emerged specifically to support ai agents industry use cases in data collection:
- LangChain / LangGraph — popular for building multi-step reasoning agents with tool use
- AutoGen (Microsoft) — supports multi-agent collaboration, useful for parallel scraping tasks
- CrewAI — role-based agent orchestration, well-suited for competitive intelligence workflows
- Crawl4AI — purpose-built for AI-friendly web crawling with structured output
- ScrapeGraph AI — combines LLMs with scraping to extract data using natural language instructions
For a detailed breakdown of the leading options, see Top 9 AI Agent Frameworks in 2026.
Each framework handles the planning and execution layers differently, but all of them eventually face the same infrastructure challenges: rate limiting, IP blocking, and CAPTCHAs. The framework choice affects architecture; the CAPTCHA-solving layer is a separate, composable component.
Compliance and Responsible Use
The ai agents industry operates in a legal and ethical landscape that teams must take seriously. Automated data collection is not inherently illegal, but it must be conducted responsibly.
Key principles:
- Respect robots.txt — this file signals which paths a site owner permits automated access to. Agents should parse and honor it.
- Review terms of service — many sites explicitly prohibit automated scraping. Legal review is appropriate for high-volume or commercially sensitive use cases.
- Rate limiting — agents should implement delays and respect Retry-After headers to avoid overloading target servers.
- Personal data — collecting personally identifiable information triggers GDPR, CCPA, and other regulations. Agents should be scoped to collect only what is necessary.
- Data freshness and accuracy — competitive intelligence is only valuable if the data is reliable. Agents should include validation steps to flag anomalies.
Deloitte's research on agentic AI highlights that governance and oversight are the top concerns for enterprise teams deploying agents in production. Building compliance into the agent's instruction set from the start is far easier than retrofitting it later.
Conclusion
AI agents have moved from a research concept to a production tool across the ai agents industry, and web scraping with competitive intelligence is one of the clearest demonstrations of their value. They handle dynamic pages, adapt to layout changes, execute multi-step navigation, and scale to volumes no manual process can match.
The technical challenges are real — CAPTCHAs, rate limits, and bot-detection systems are designed to interrupt exactly this kind of automation. Integrating a reliable CAPTCHA-solving service like CapSolver into the agent's pipeline removes one of the most common points of failure, keeping data collection continuous and compliant.
If you are building or evaluating an ai agents industry pipeline for competitive intelligence, start with a clear data goal, choose a framework that fits your orchestration needs, and plan for the infrastructure layer — including CAPTCHA handling — before you hit production.
FAQ
Q1: What is the difference between a web scraper and an AI agent for data collection?
A traditional web scraper follows a fixed set of instructions — specific selectors, predetermined URLs, and a rigid execution path. An AI agent adds a reasoning layer: it can interpret a goal, plan the steps needed to achieve it, adapt when a page changes, and recover from errors autonomously. For competitive intelligence at scale, the adaptive capability is the critical difference.
Q2: Are AI agents legal to use for web scraping?
Automated data collection is legal in many jurisdictions when it targets publicly accessible information and complies with the site's terms of service and applicable data protection laws. The legal landscape varies by country and use case. Teams should review robots.txt, terms of service, and relevant regulations (GDPR, CCPA) before deploying agents at scale.
Q3: How do AI agents handle CAPTCHAs during scraping?
When an agent encounters a CAPTCHA, it can integrate with a CAPTCHA-solving API. The agent passes the challenge parameters to the API, receives a valid token, and injects it into the request to continue. Services like CapSolver support this pattern for reCAPTCHA, hCaptcha, Cloudflare Turnstile, and other common challenge types, returning solutions in seconds via a REST API.
Q4: Which AI agent framework is best for competitive intelligence pipelines?
The right choice depends on your stack and workflow complexity. LangChain and LangGraph are widely adopted and have strong community support. CrewAI is well-suited for role-based multi-agent workflows. Crawl4AI and ScrapeGraph AI are purpose-built for web data extraction. Most teams start with one framework and add composable infrastructure components — proxies, CAPTCHA solvers, storage — as the pipeline matures.
Q5: How often should competitive intelligence agents run?
Frequency depends on the volatility of the data. Pricing data for e-commerce may need hourly updates. Feature tracking and job posting intelligence can run daily or weekly. SERP monitoring typically runs daily. Agents should be scheduled based on how quickly the underlying data changes, balanced against the load placed on target servers and the cost of compute.
More
AIApr 24, 2026
AI Agent vs Chatbot: Key Differences in Automation Capabilities
Discover the key differences between AI agent vs chatbot. Learn how agentic AI outperforms traditional AI in automation, decision-making, and complex workflows.

AIApr 24, 2026
Agentic AI vs AI Agents: Key Differences for Automation Engineers
Discover the key differences between Agentic AI and AI Agents. Learn how automation engineers can build scalable workflows and solve CAPTCHAs efficiently.


