How AI Agents Handle CAPTCHAs at Scale

Emma Foster
Machine Learning Engineer
TL;DR
- AI agents require robust infrastructure to handle CAPTCHAs at scale during automated web operations.
- Modern traffic validation systems use behavioral analysis and device fingerprinting to detect automated requests.
- Integrating a reliable CAPTCHA solving API ensures continuous operation for autonomous agents.
- Distributed architectures and proxy rotation are essential for managing high-volume risk control challenges.
- Ethical compliance and responsible use policies must guide all automated data collection efforts.
Introduction
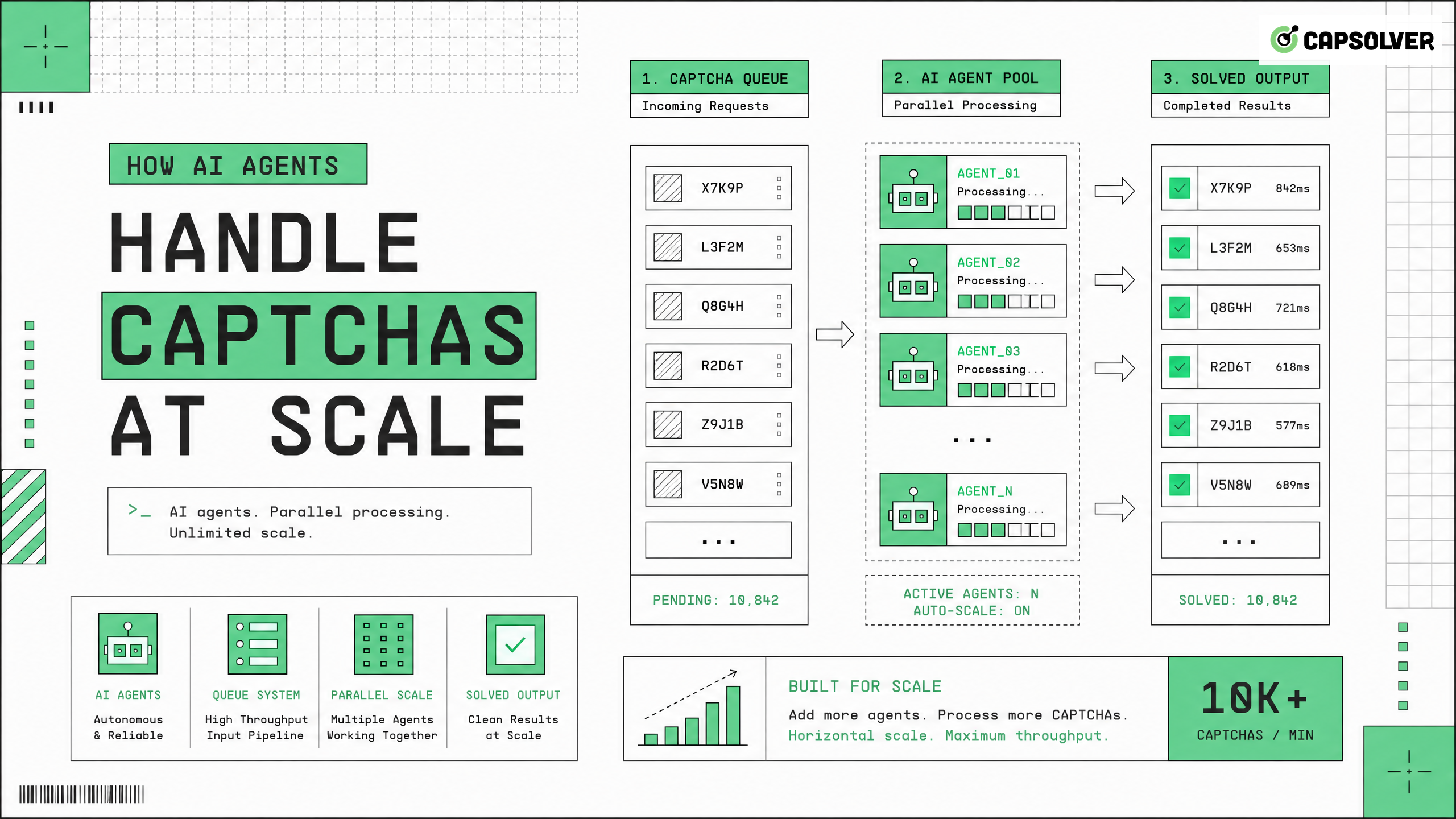
Autonomous systems must efficiently handle CAPTCHAs at scale to maintain continuous web operations. As websites implement stricter traffic validation measures, traditional automation scripts frequently fail when encountering complex risk control challenges. Modern AI agents solve this problem by integrating specialized infrastructure designed to process these challenges automatically. CapSolver provides the necessary API endpoints and machine learning models to process high-volume requests reliably. By delegating the validation process to a dedicated service, developers can focus on core agent logic rather than maintaining complex browser automation stacks. This approach ensures high success rates while adhering to target site rate limits and responsible use guidelines.
The Evolution of Traffic Validation
Web security systems have evolved from simple text recognition to complex behavioral analysis. Early CAPTCHA systems relied on distorted text, which optical character recognition (OCR) could easily process. Today, risk control platforms evaluate mouse movements, browser fingerprints, and network reputation to differentiate between human users and automated scripts.
When AI agents handle CAPTCHAs at scale, they must navigate these advanced validation layers. Modern challenges often require executing JavaScript, rendering complex images, or solving spatial puzzles. This complexity demands significant computational resources and specialized algorithms. For developers building autonomous systems, managing this infrastructure internally becomes a massive engineering burden.
To understand the underlying mechanisms, researchers often refer to the W3C guidelines on CAPTCHA alternatives, which detail the accessibility and security implications of automated Turing tests.
Core Infrastructure for Autonomous Agents
Building the right infrastructure is critical for systems that handle CAPTCHAs at scale. An effective architecture separates the core agent logic from the validation processing layer. This separation of concerns allows each component to scale independently based on workload demands.
Headless Browser Management
AI agents frequently rely on headless browsers to interact with modern web applications. These browsers must be carefully configured to avoid detection by risk control systems. Proper management includes rotating user agents, modifying navigator properties, and handling canvas fingerprinting. You can learn more about what is headless browser detection and how to avoid it in our detailed guide.
Proxy Networks and IP Reputation
Network reputation plays a crucial role in traffic validation. When systems handle CAPTCHAs at scale, they must distribute requests across diverse IP addresses to avoid rate limiting. High-quality residential or mobile proxies provide the necessary reputation to pass initial security checks. Combining proxy rotation with a robust CAPTCHA solving API for autonomous agents creates a resilient automation stack.
Asynchronous Processing
Validation challenges introduce variable latency into automated workflows. A challenge might take anywhere from a few seconds to over a minute to resolve. Agents must implement asynchronous processing patterns to handle this latency without blocking other operations. Message queues and event-driven architectures are standard solutions for managing these asynchronous workflows.
Advanced Techniques for Traffic Validation
As risk control systems become more sophisticated, the techniques used to process them must also advance. When organizations handle CAPTCHAs at scale, they employ a variety of advanced methods to ensure high success rates.
Behavioral Simulation
Some validation systems monitor how a user interacts with the page. To pass these checks, agents must simulate human-like behavior, including realistic mouse movements, varied typing speeds, and natural scrolling patterns. Implementing these simulations requires deep understanding of human-computer interaction metrics. The latest research on behavioral biometrics highlights the increasing sophistication of these detection mechanisms.
Device Fingerprinting Mitigation
Risk control platforms collect extensive data about the client device, including screen resolution, installed fonts, and hardware concurrency. To handle CAPTCHAs at scale, agents must present consistent and realistic device fingerprints. This involves injecting custom scripts into the browser environment to override default properties and present a unified profile.
Redeem Your CapSolver Bonus Code
Boost your automation budget instantly!
Use bonus code CAP26 when topping up your CapSolver account to get an extra 5% bonus on every recharge — with no limits.
Redeem it now in your CapSolver Dashboard

Integrating Machine Learning Models
Advanced AI agents handle CAPTCHAs at scale by utilizing specialized machine learning models. These models are trained on vast datasets of validation challenges, allowing them to recognize patterns and solve puzzles with high accuracy.
Computer Vision for Image Challenges
Image-based challenges require sophisticated computer vision algorithms. Object detection models identify specific items within a grid, while segmentation models outline complex shapes. Training these models requires continuous updates to adapt to new challenge types introduced by risk control providers.
Audio Challenge Processing
For accessibility reasons, many validation systems offer audio alternatives. Agents can handle CAPTCHAs at scale by processing these audio files using speech-to-text models. This approach often provides a more reliable path when visual challenges become too complex. The NIST speech recognition evaluations provide benchmarks for the accuracy of these models.
For a comprehensive overview of the necessary components, review the web automation infrastructure stack for AI agents.
Managing High-Volume Operations
When organizations need to handle CAPTCHAs at scale, operational efficiency becomes paramount. Processing thousands of requests per minute requires robust error handling, retry logic, and performance monitoring.
Error Handling and Retries
Validation challenges can fail for numerous reasons, including network timeouts, proxy bans, or model inaccuracies. Agents must implement intelligent retry mechanisms with exponential backoff to manage these failures gracefully. It is essential to distinguish between temporary network issues and permanent blocks to optimize resource usage.
Performance Monitoring
Monitoring the success rate and latency of validation processing is critical. Dashboards should track metrics such as average solve time, error rates by challenge type, and proxy performance. This data allows engineering teams to identify bottlenecks and optimize their infrastructure. Choosing a CAPTCHA solver for agent infrastructure 2026 requires careful evaluation of these performance metrics.
The Role of APIs in Autonomous Systems
APIs provide the connective tissue that allows agents to interact with external services. When systems handle CAPTCHAs at scale, they rely on specialized APIs to offload the computational burden of validation processing.
Synchronous vs. Asynchronous APIs
Validation APIs can be synchronous or asynchronous. Synchronous APIs block the agent until the challenge is resolved, which can lead to performance bottlenecks. Asynchronous APIs allow the agent to submit a challenge and poll for the result later, improving overall throughput.
API Rate Limiting and Quotas
When agents handle CAPTCHAs at scale, they must carefully manage API rate limits and quotas. Exceeding these limits can result in temporary bans or degraded performance. Implementing token bucket algorithms and request queuing helps ensure compliance with API usage policies. For more details, see our guide on CAPTCHA solving infrastructure for AI agents.
Scaling Data Collection Workflows
Data collection is a primary use case for autonomous agents. As the volume of data increases, the systems must scale accordingly. When agents handle CAPTCHAs at scale, they enable organizations to gather competitive intelligence, monitor market trends, and aggregate public information efficiently.
Distributed Crawling Architectures
To process millions of pages, agents are often deployed in distributed clusters. Each node in the cluster operates independently, fetching pages and processing validation challenges as needed. This distributed approach ensures that the system can handle CAPTCHAs at scale without creating a single point of failure.
Data Normalization and Storage
Once the data is collected, it must be normalized and stored for analysis. Agents often integrate with data pipelines that clean and structure the raw HTML before inserting it into a database. This pipeline must be resilient to interruptions caused by validation challenges.
Security Considerations for Agent Infrastructure
Security is a critical concern when deploying autonomous agents. Systems that handle CAPTCHAs at scale must protect sensitive credentials, API keys, and proxy configurations from unauthorized access.
Credential Management
Agents should never hardcode credentials in their source code. Instead, they should use secure secret management systems to retrieve API keys and proxy passwords at runtime. This practice minimizes the risk of credential exposure if the codebase is compromised.
Network Security
The communication between the agent and the validation API must be encrypted using TLS. This encryption prevents man-in-the-middle attacks and ensures the integrity of the validation tokens. Organizations must also monitor their network traffic for anomalies that could indicate a security breach.
Comparison of Validation Processing Approaches
| Approach | Scalability | Maintenance Burden | Success Rate | Best Use Case |
|---|---|---|---|---|
| In-house ML Models | High | Very High | Variable | Specialized, proprietary challenges |
| Manual Solving Teams | Low | High | High | Low-volume, highly complex tasks |
| Automated API Services | Very High | Low | Very High | High-volume, standard challenges |
| Browser Extensions | Low | Medium | Medium | Desktop automation, testing |
Compliance and Responsible Use
Automated data collection must always adhere to legal and ethical standards. When systems handle CAPTCHAs at scale, they interact with third-party infrastructure that has specific terms of service. Organizations must ensure their automation practices comply with relevant regulations, such as the GDPR and CCPA.
Responsible use includes respecting robots.txt directives, implementing reasonable rate limits, and avoiding disruption to the target service. The Electronic Frontier Foundation's guidelines on automated access provide valuable context for maintaining ethical standards in web scraping. For more information on building compliant systems, explore our guide on bot protection infrastructure for AI agents.
Future Trends in Traffic Validation
The landscape of web security is constantly evolving. As AI agents become more sophisticated, risk control systems will adapt to detect them. Organizations that handle CAPTCHAs at scale must stay ahead of these trends to maintain continuous operations.
Zero-Trust Architectures
Zero-trust architectures assume that all traffic is potentially malicious. These systems require continuous validation throughout the user session, rather than a single check at login. Agents will need to adapt to these continuous validation models to maintain access.
Privacy-Preserving Validation
New validation methods are emerging that prioritize user privacy. These methods use cryptographic proofs to verify human interaction without collecting sensitive data. As these technologies mature, agents will need to integrate new protocols to handle CAPTCHAs at scale. The IETF specifications on privacy pass outline the technical foundations for these new validation mechanisms.
Conclusion
Building systems that efficiently handle CAPTCHAs at scale is essential for modern web automation. By separating validation processing from core agent logic and utilizing specialized APIs, developers can achieve high success rates and maintain continuous operations. Implementing robust error handling, proxy management, and asynchronous processing ensures that autonomous systems can navigate complex risk control environments reliably. For enterprise-grade validation processing, CapSolver offers the infrastructure and machine learning capabilities required to support large-scale AI agent deployments.
FAQ
What is the most efficient way to process validation challenges?
Using a dedicated API service is generally the most efficient approach. It offloads the computational burden and maintenance requirements to specialized infrastructure, allowing your agents to focus on their primary tasks.
How do proxy networks affect validation success rates?
Proxy networks are critical for distributing requests and maintaining a positive IP reputation. High-quality residential proxies reduce the likelihood of triggering advanced risk control measures, thereby improving overall success rates.
Can autonomous systems simulate human behavior?
Yes, advanced systems can simulate human-like mouse movements, typing patterns, and scrolling behavior. This simulation is often necessary to pass behavioral analysis checks implemented by modern security platforms.
What are the legal considerations for automated web operations?
Automated operations must comply with data privacy regulations, terms of service, and copyright laws. It is essential to implement responsible scraping practices, respect rate limits, and avoid causing harm to the target infrastructure.
How do machine learning models solve image challenges?
Machine learning models use computer vision techniques, such as object detection and image segmentation, to analyze and solve visual puzzles. These models are continuously trained on new data to maintain high accuracy against evolving challenge types.
More
AIJun 25, 2026
Enterprise CAPTCHA Solving for AI Agent Teams
Learn how enterprise AI agent teams can implement scalable, reliable CAPTCHA solving infrastructure to keep automation workflows running without interruption.

AIJun 25, 2026
The Headless Browser CAPTCHA Layer for Agents
Explore how headless browsers and CAPTCHA-solving layers enable reliable automation for AI agents, overcoming bot detection and ensuring efficient web interaction.

