ウェブスクレイピング CAPTCHA処理: セーフオートメーションガイド

Sora Fujimoto
AI Solutions Architect
TL;DR
- WebスクレイピングにおけるCAPTCHA処理は、技術的な統合を追加する前に、許可、レート制御、明確な停止ルールを最初に考慮する必要があります。
- 主なチャレンジタイプにはreCAPTCHA、Cloudflare Turnstile、画像認識、およびページ固有のトラフィック検証フローが含まれます。
- CapSolverは、一般的なチャレンジタイプのタスク作成と結果取得APIを提供することで、承認されたWebスクレイピングCAPTCHAワークフローに適合します。
- 良い自動化は、トークンを短期間の検証アーティファクトとして扱い、すべてのタスク、リトライ、ターゲットドメイン、および失敗状態を記録します。
イントロダクション
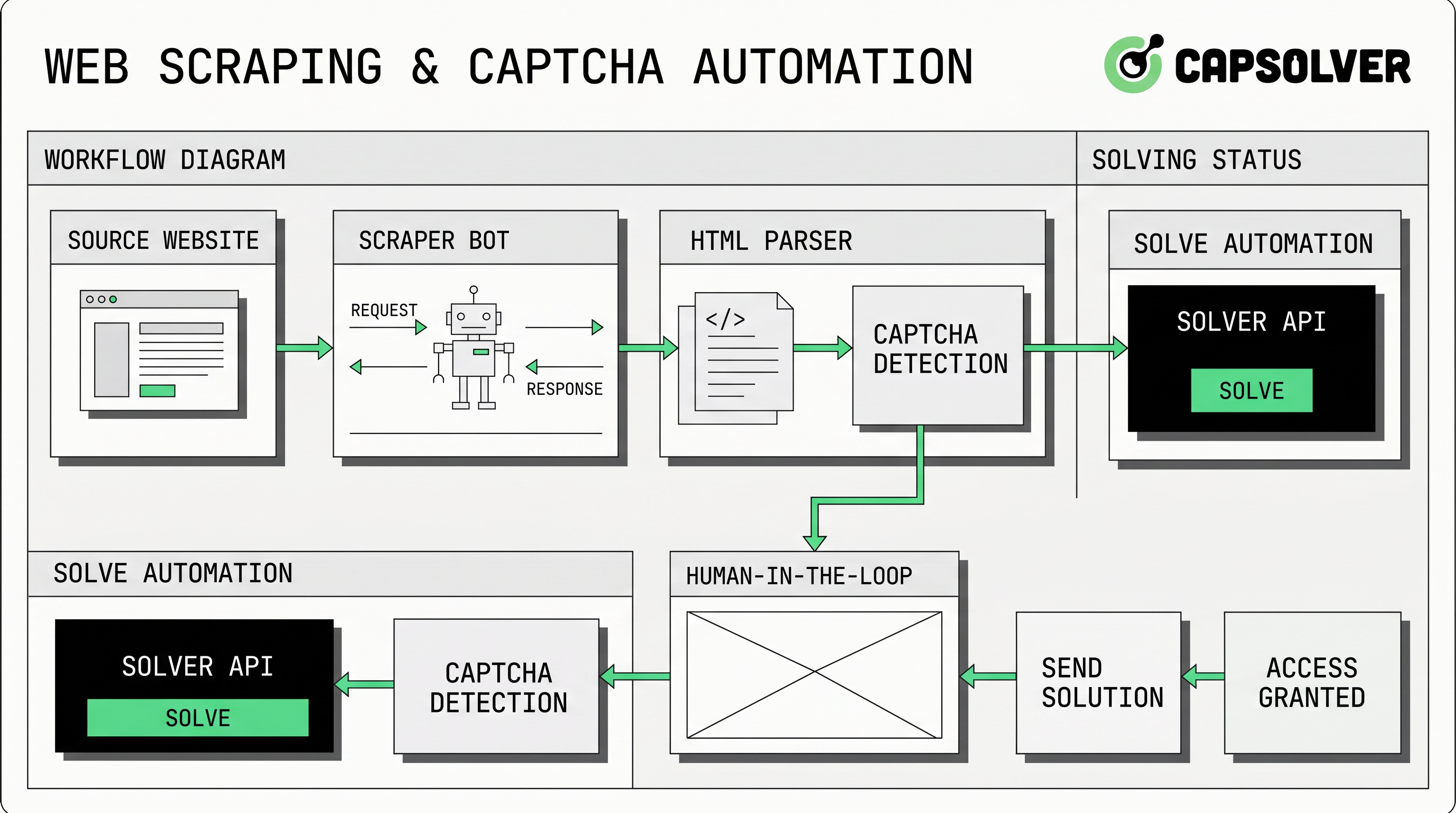
WebスクレイピングにおけるCAPTCHA処理は、許可された公開データを収集するチーム、市場モニタリングを実行するチーム、所有するアプリケーションをテストするチーム、または内部オートメーションを運用するチームにとって現実的な問題です。CapSolverは、制御されたチャレンジ処理を目的とした場合にこれらのワークフローをサポートできます。最善のアプローチは、最初にソルバーを追加することではなく、許可を確認し、不要なリクエストを減らし、チャレンジタイプを特定し、ブラウザコンテキストを保持し、許可されている場所でのみAPIワークフローを追加することです。このガイドでは、技術的に信頼性があり、監査がしやすく、責任あるオートメーションルールに合致したWebスクレイピングプロセスの設計方法について説明します。
自動化ワークフローにWebスクレイピングCAPTCHAが現れる理由
WebスクレイピングCAPTCHAチェックは、サイトが訪問者、リクエストパターン、ブラウザ環境、またはアカウント行動についてより高い信頼性を求めるときに通常現れます。いくつかのチャレンジは可視され、他のものはスコアベースまたはトークンベースです。GoogleはreCAPTCHA v3がユーザーを中断しないと述べており、各リクエストに対して0.0から1.0のリスクスコアを返します。CloudflareはTurnstileトークンがサーバーで検証され、1回限りで、300秒有効であると述べています。これらのシステムは単なる視覚的なパズルではなく、より広範なトラフィック検証パターンの一部です。
これは、WebスクレイピングCAPTCHA処理がリクエストの質から切り離せないことを意味します。高いリクエストレート、不安定なIPの評判、欠如するブラウザシグナル、または一貫しないセッション状態は、チャレンジの頻度を増加させます。APIを追加する前に、チームはキャッシュを適切にし、ロボットおよび利用規約を尊重し、並行処理を制限し、適切な使用ケースを特定し、サイトがアクセスを拒否または制限した場合に停止することで、避けられるトリガーを減らすべきです。
| 原因 | 実践的な対応 | なぜ役立つのか |
|---|---|---|
| 高いリクエストレート | キュー制限とバックオフを追加 | 負荷と失敗試行を減らす。 |
| ブラウザの不一致 | 一貫したブラウザ自動化プロファイルを使用 | ページコンテキストを安定させる。 |
| プロキシの不一致 | プロキシ、セッション、チャレンジタスクを一致させる | トークンコンテキストの不一致を防ぐ。 |
| 分からないチャレンジタイプ | タスク作成前にreCAPTCHA、Turnstile、または画像チャレンジを検出 | 正しいAPIペイロードを送信。 |
| 明確でない許可 | 利用規約、ロボット、契約、データの機密性を確認 | 自動化を承認された境界内に保つ。 |
WebスクレイピングCAPTCHA統合の前にポリシーを構築
WebスクレイピングCAPTCHA作業は、ガバナンスから始める必要があります。OWASPは不要な自動化をソフトウェアとして説明しており、これはWebアプリケーションから逸脱した行動で、望ましくない影響をもたらし、その自動化された脅威の分類にはスクレイピングやCAPTCHA関連の悪用シナリオが含まれます。チームにとって、同じ技術ワークフローが一つの文脈では許容可能で、別の文脈では不許容である可能性があります。
責任あるポリシーは、許可されたドメイン、許可されたデータタイプ、ビジネス目的、リクエストレート制限、アカウントルール、保持ルール、エスカレーション連絡先をリストアップする必要があります。また、自動化がしてはいけないことを説明する必要があります。例えば、プライベート領域へのアクセス、許可なしの機密データの収集、拒否信号の後に継続することなどです。このポリシーは、ターゲットサイトと自社組織の両方を保護し、承認されたデータ収集と禁止活動の明確な境界を作成します。
適切なWebスクレイピングCAPTCHAワークフローを選択
WebスクレイピングCAPTCHA処理は通常、3つの技術的なパターンのいずれかに適合します。最初は、より良いリクエストの整備を通じた回避: 少ないリクエスト、より良いキャッシュ、ノイジーなブラウザ行動の減少。第二は、エッジケースのための人間のレビューで、低ボリュームのプロセスが難しいページをオペレーターにルーティングします。第三は、承認されたジョブがチャレンジパラメータをプロバイダーに送信し、解決策を取得するAPIベースのチャレンジワークフローです。
CapSolverの公式APIドキュメンテーションは、createTaskとgetTaskResultを用いたタスクベースのフローを説明しています。このモデルでは、スクレイパーがチャレンジを検出し、適切なタスクオブジェクトを送信し、タスクIDを取得し、結果が利用可能になるまでポーリングします。createTaskガイドでは、リクエストにclientKeyとタスクオブジェクトが必要であり、getTaskResultガイドでは非同期タスクのprocessingとready状態がドキュメント化されています。
reCAPTCHAページの場合、チームは汎用的なペイロードをコピーする代わりに、CapSolverのreCAPTCHA v2ガイドまたはreCAPTCHA v3ガイドを確認する必要があります。Turnstileページの場合、Cloudflare Turnstileガイドを使用し、Cloudflareの独自のサーバーサイド検証ルールによりトークンの新鮮さが重要であることを思い出してください。
ブラウザ、プロキシ、トークンコンテキストを一貫して保つ
WebスクレイピングCAPTCHAエラーは通常、コンテキストの不一致から発生します。ブラウザが1つのプロキシを通じてページをリクエストし、チャレンジタスクが別のネットワーク経路を使用する場合、返されたトークンは期待される環境に一致しない可能性があります。検出と送信の間にページアクションが変化すると、スコアベースのトークンが意図した通りに検証されない可能性があります。作業者が長時間待つと、トークンが期限切れになる可能性があります。
このため、自動化レイヤーはチャレンジタスクをジョブID、ブラウザセッション、プロキシ、ターゲットURL、サイトキー、タイムスタンプに関連付ける必要があります。Web自動化におけるSeleniumとWeb自動化におけるPuppeteerに関するCapSolverのリソースは、チャレンジ処理を追加する前にブラウザドライバを標準化するチームにとって有用な内部リンクです。プロキシが関与する場合、スクレイピングと自動化のためのプロキシポートのガイドラインは、ネットワーク設定を一貫させることに役立ちます。
ボーナスコード
CapSolverボーナスコードを取得する
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコードCAP26を使用すると、毎回5%のボーナスが追加されます—制限なし。
今すぐCapSolverダッシュボードで取得してください
一般的なWebスクレイピングCAPTCHAオプションの比較概要
WebスクレイピングCAPTCHA処理は、仕事のボリューム、許可レベル、信頼性の要件に合わせる必要があります。低ボリュームのリサーチタスクは人間のレビューのみが必要かもしれません。定期的なモニタリングジョブは通常、APIベースの状態処理、ログ、停止条件が必要です。不適切に管理された高ボリュームのジョブは、技術的な統合が動作していても実行しないべきです。
| オプション | 最適な使用ケース | 主なリスク |
|---|---|---|
| リクエストの整備のみ | 少ないチャレンジ頻度の公開ページ | チャレンジページが現れたときに処理できない可能性がある。 |
| 人間のレビュー | 低ボリュームのリサーチまたはデバッグ | 遅く、スケジュールされたジョブには不適切。 |
| APIベースの処理 | 知られているチャレンジタイプを持つ承認された定期的なワークフロー | 正確なコンテキスト、監査ログ、ポリシー制御が必要。 |
| 実行しない | 制限付き、プライベート、機密、または拒否されたアクセス | 継続すると法的、プライバシー、セキュリティリスクを生じる。 |
CapSolverのWebスクレイピングにおけるSeleniumとPuppeteerの比較は、ブラウザ自動化ツールの選択に役立ち、開発者向けブラウザ自動化ガイドは、ブラウザコントロールとチャレンジ処理を分離するチームに役立ちます。
WebスクレイピングCAPTCHAの実装チェックリスト
WebスクレイピングCAPTCHAの実装は、小規模で観測可能で、逆転可能であるべきです。ステージングワークフローと制限付き許可リストから始めます。チャレンジタイプ、ターゲットURL、サイトキー、プロキシID、タスクID、タスクステータス、レイテンシー、最終結果を記録します。サイトがポリシー、チャレンジ行動、または応答ステータスを変更した場合、ジョブを停止し、ワークフローを再確認するべきです。リトライを増やすのではなく、ワークフローをレビューします。
実践的なチェックリストには、許可のレビュー、ロボットと利用規約のレビュー、データ最小化、ドメイン許可リスト、レート制限、ブラウザプロファイル、プロキシの一貫性、チャレンジ検出、APIタスク作成、ポーリングポリシー、タイムアウト、エラー処理、監査ログ、および実行後のレビューが含まれます。チームは、WebスクレイピングおよびCAPTCHA解決サービスの使用に関するガイダンスを内部ドキュメンテーションに追加すべきです。これは、サービスを広範なワークフローの一部としてではなく、単独のショートカットとしてフレームするためです。
避けるべき一般的なミス
WebスクレイピングCAPTCHAプロジェクトは、チームがチャレンジ処理を別個の追加として扱うとよく失敗します。APIから返されたトークンは、ブラウザ状態、ターゲットページ、アクション、およびタイムウィンドウに合致している場合にのみ有用です。もう一つの一般的なミスは無制限のリトライです。タスクが繰り返し失敗する場合、正しい対応はパラメータ、許可、およびサイトシグナルを検査することであり、負荷を増やすことではありません。
チームは、スクリプトにシークレットを保存したり、環境間でAPIキーを共有したり、承認された許可リスト外のドメインのチャレンジタスクを送信したりするのも避けるべきです。中央の設定、シークレットストレージ、ジョブレベルのログを活用してください。APIをワークフローで使用する場合、CapSolverのAPIドキュメンテーションとgetTaskResultガイドは、エンドポイントの動作に関する真実のソースでなければなりません。
結論/CTA
WebスクレイピングCAPTCHA処理は、制御されたワークフローとして設計されたときに最も安全です: 許可を最優先にし、リクエストの整備を次にし、チャレンジ検出を第三にし、許可されている場所でのみAPI統合を行います。正しい設定により、ブラウザコンテキストが安定し、トークンが短期間のものと扱われ、すべての結果が記録され、アクセスが許可されていない場合は停止されます。あなたのチームが承認されたスクレイピング、QA、またはモニタリングのための文書化されたチャレンジ処理が必要な場合、CapSolverを使用して小さなテストワークフローから始めてください。
FAQ
WebスクレイピングCAPTCHAとは何ですか?
WebスクレイピングCAPTCHAとは、データを収集中にトラフィック検証チャレンジに遭遇するスクリパーを指します。適切な対応は、許可、チャレンジタイプ、レート制限、およびサイトのアクセスルールに依存します。
WebスクレイピングCAPTCHAはAPIで処理できますか?
はい、承認されたワークフローでは、APIがチャレンジタスクを作成し、ドキュメント化された結果エンドポイントを通じて解決策を返すことができます。一般的な概要については、WebスクレイピングおよびCAPTCHA解決サービスがAPIを提供する方法を参照してください。
SeleniumとPuppeteerスクリパーがCAPTCHAチェックを表示する理由は?
SeleniumとPuppeteerは、高リクエストレートや不安定なセッションで、サイトがトラフィック検証中にレビューするブラウザパターンを生成する可能性があります。SeleniumのWeb自動化またはPuppeteerの設定を標準化することで、避けられる不一致を減らすことができます。
WebスクレイピングCAPTCHAワークフローでプロキシをどのように使用するべきですか?
プロキシは法的かつ許可された場所でのみ使用し、ブラウザセッションとチャレンジタスクの間でプロキシアイデンティティを一貫させます。目標は、積極的なリクエストボリュームではなく、安定したコンテキストです。
あらゆる公開ウェブサイトでWebスクレイピングCAPTCHA処理は合法ですか?
いいえ。公開されているからといって自動収集が許可されるわけではありません。あらゆるスクリパーを実行する前に、サイトの利用規約、ロボットのガイドライン、契約、プライバイの要件、データの機密性、レート制限を確認してください。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
