AIエージェントが大規模にCAPTCHAを処理する方法

Sora Fujimoto
AI Solutions Architect
TL;DR
- AIエージェントは、自動化されたウェブ操作中に大規模なCAPTCHAを処理するための堅牢なインフラストラクチャを必要とする。
- 現代のトラフィック検証システムは、行動分析とデバイスのファインティングを用いて自動化されたリクエストを検出する。
- 信頼性の高いCAPTCHAソルビングAPIを統合することで、自律的なエージェントの連続運用を確保できる。
- 分散アーキテクチャとプロキシローテーションは、高ボリュームのリスク管理の課題を管理するために不可欠である。
- 倫理的なコンプライアンスと責任ある使用ポリシーは、すべての自動化されたデータ収集活動を指導する必要がある。
イントロダクション
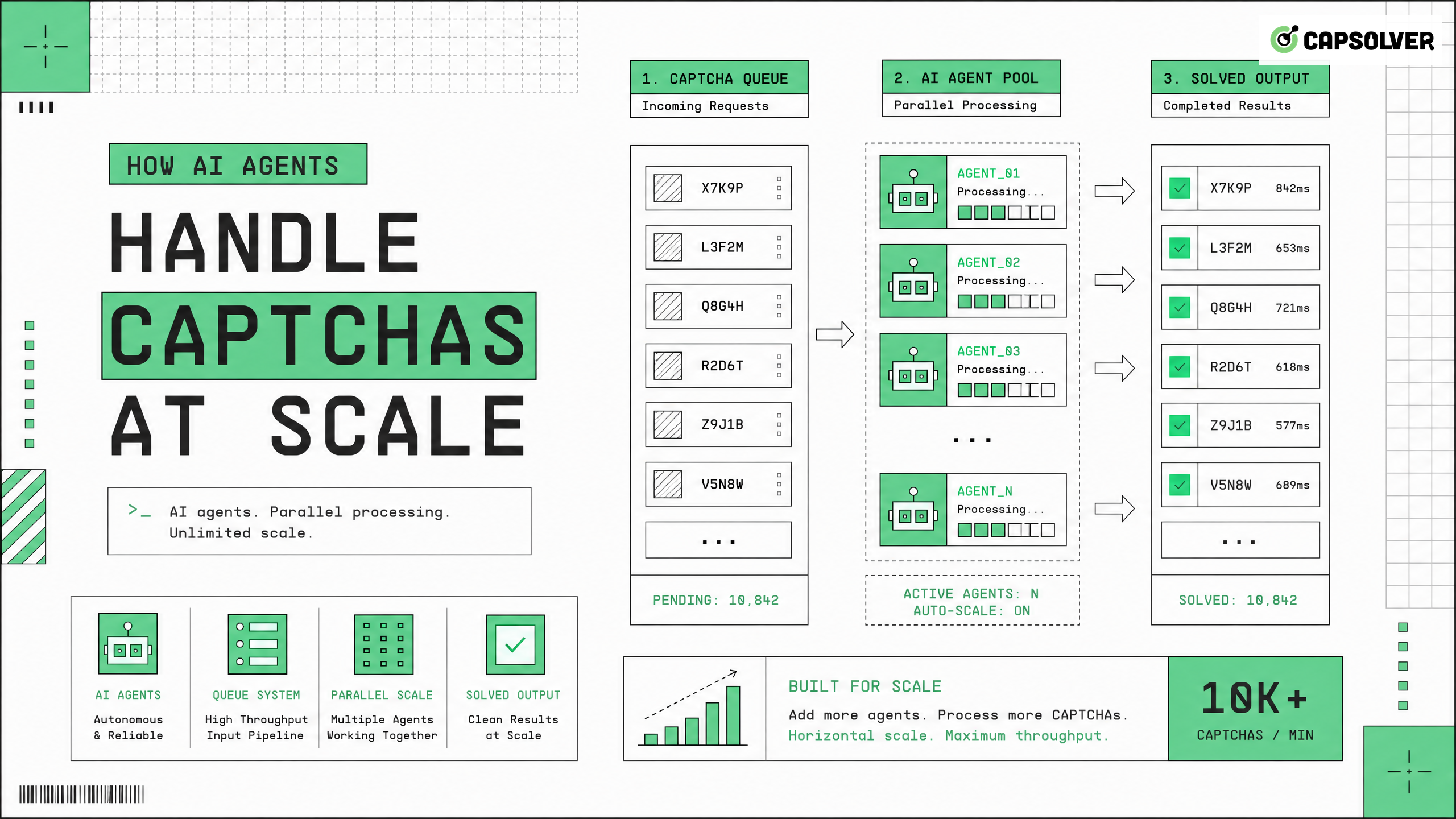
自律的なシステムは、継続的なウェブ操作を維持するために大規模なCAPTCHAを効率的に処理する必要がある。ウェブサイトがより厳格なトラフィック検証措置を導入するにつれて、従来の自動化スクリプトは複雑なリスク管理の課題に遭遇するたびに頻繁に失敗する。現代のAIエージェントは、これらの課題を自動的に処理するように設計された専門的なインフラストラクチャを統合することで、この問題を解決する。CapSolverは、高ボリュームのリクエストを信頼性を持って処理するための必要なAPIエンドポイントと機械学習モデルを提供する。検証プロセスを専用サービスに委譲することで、開発者は複雑なブラウザ自動化スタックの維持ではなく、コアエージェントロジックに焦点を当てることができる。このアプローチにより、ターゲットサイトのレートリミットと責任ある使用ガイドラインに準拠しながら高い成功確率を確保することができる。
トラフィック検証の進化
ウェブセキュリティシステムは、単純なテキスト認識から複雑な行動分析へと進化した。初期のCAPTCHAシステムは歪んだテキストに依存しており、光学文字認識(OCR)が簡単に処理できた。今日では、リスク管理プラットフォームはマウスの動き、ブラウザのファインティング、ネットワークの評判を評価して、人間のユーザーと自動スクリプトを区別する。
AIエージェントが大規模なCAPTCHAを処理する際には、これらの高度な検証レイヤーを通過する必要がある。現代の課題は、JavaScriptの実行、複雑な画像のレンダリング、または空間的なパズルの解決を必要とすることが多い。この複雑さは、大きな計算リソースと専門的なアルゴリズムを必要とする。自律的なシステムを構築する開発者にとって、このインフラストラクチャを内部で管理することは、大きなエンジニアリングの負担となる。
理解するために、研究者はしばしばW3CのCAPTCHA代替案に関するガイドラインを参照し、自動化されたチューリングテストのアクセシビリティとセキュリティへの影響を詳細に説明している。
自律エージェントのコアインフラ
大規模なCAPTCHAを処理するシステムでは、正しいインフラストラクチャの構築が不可欠である。効果的なアーキテクチャは、コアエージェントロジックと検証処理レイヤーを分離する。この責任の分離により、各コンポーネントは作業負荷の要件に応じて独立してスケールできる。
ヘッドレスブラウザの管理
AIエージェントは、現代のウェブアプリケーションと対話するためにヘッドレスブラウザを頻繁に使用する。これらのブラウザは、リスク管理システムによる検出を回避するために慎重に構成される必要がある。適切な管理には、ユーザー代理のローテーション、ナビゲータープロパティの変更、キャンバスファイニングの処理が含まれる。ヘッドレスブラウザ検出とは何か、そしてそれを回避する方法についての詳細なガイドでさらに学ぶことができる。
プロキシネットワークとIP評判
ネットワーク評判はトラフィック検証において重要な役割を果たす。CAPTCHAを大規模に処理するシステムは、レートリミットを回避するためにリクエストを多様なIPアドレスに分散する必要がある。高品質な住宅用またはモバイルプロキシは、初期のセキュリティチェックを通過するための必要な評判を提供する。プロキシローテーションと信頼性の高い自律エージェント用CAPTCHAソルビングAPIを組み合わせることで、耐障害性のある自動化スタックが構築される。
非同期処理
検証チャレンジは、自動ワークフローに変動する遅延をもたらす。チャレンジの解決には数秒から1分以上かかることがある。エージェントは、他の操作をブロックせずにこの遅延を処理するために非同期処理パターンを実装する必要がある。メッセージキューとイベント駆動アーキテクチャは、これらの非同期ワークフローを管理する標準的な解決策である。
トラフィック検証の高度な技術
リスク管理システムがより複雑になるにつれて、それらを処理するための技術も進化しなければならない。大規模なCAPTCHAを処理する組織は、高い成功確率を確保するために多様な高度な方法を採用する。
行動シミュレーション
一部の検証システムは、ユーザーがページとどのように相互作用するかを監視する。これらのチェックを通過するためには、エージェントは現実的なマウスの動き、変化する入力速度、自然なスクロールパターンなどの人間らしい行動をシミュレートする必要がある。これらのシミュレーションの実装には、人間とコンピュータのインタラクションメトリクスの深い理解が必要である。行動バイオメトリクスに関する最新の研究は、これらの検出メカニズムの増加する複雑さを示している。
デバイスファインティングの軽減
リスク管理プラットフォームは、画面解像度、インストールされたフォント、ハードウェアの並列性などのクライアントデバイスに関する膨大なデータを収集する。大規模なCAPTCHAを処理するエージェントは、一貫性があり現実的なデバイスファインティングを提示しなければならない。これは、ブラウザ環境にカスタムスクリプトを挿入してデフォルトのプロパティを上書きし、一貫したプロファイルを提示することを含む。
CapSolverボーナスコードを取得する
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、すべてのチャージで 5%のボーナス を受け取れる — 制限なし。
CapSolverダッシュボードで今すぐ取得してください

マシンラーニングモデルの統合
高度なAIエージェントは、大規模なCAPTCHAを処理するために専門的な機械学習モデルを利用する。これらのモデルは、膨大な量の検証チャレンジデータセットで訓練されており、高い正確性でパターンを認識しパズルを解決できる。
イメージチャレンジのためのコンピュータビジョン
画像ベースのチャレンジには、高度なコンピュータビジョンアルゴリズムが必要である。オブジェクト検出モデルはグリッド内の特定のアイテムを識別し、セグメンテーションモデルは複雑な形状の輪郭を示す。これらのモデルを訓練するには、リスク管理プロバイダーが導入する新しいチャレンジタイプに適応するために継続的な更新が必要である。
音声チャレンジの処理
アクセシビリティの理由から、多くの検証システムは音声の代替を提供する。エージェントは、音声ファイルを音声認識モデルを使用して処理することで、大規模なCAPTCHAを処理できる。視覚的なチャレンジが複雑すぎる場合、このアプローチはより信頼性の高い方法となることがある。NIST音声認識評価は、これらのモデルの正確性のベンチマークを提供する。
詳細な概要が必要な場合は、AIエージェントのウェブ自動化インフラストラクチャスタックを参照してください。
高ボリューム運用の管理
組織が大規模なCAPTCHAを処理する必要があるとき、運用効率が最も重要となる。1分間に数千件のリクエストを処理するには、堅牢なエラー処理、リトライロジック、パフォーマンスモニタリングが必要である。
エラー処理とリトライ
検証チャレンジは、ネットワークタイムアウト、プロキシのブロック、モデルの不正確さなど、多くの理由で失敗する可能性がある。エージェントは、指数関数的なバックオフを備えた知的なリトライメカニズムを実装して、これらの失敗をスムーズに管理する必要がある。一時的なネットワーク問題と永続的なブロックを区別することがリソースの最適化に不可欠である。
パフォーマンスモニタリング
検証処理の成功確率と遅延をモニタリングすることは、非常に重要である。ダッシュボードは、平均解決時間、チャレンジタイプ別のエラーレート、プロキシのパフォーマンスなどのメトリクスを追跡する必要がある。このデータにより、エンジニアリングチームはボトルネックを特定し、インフラストラクチャを最適化できる。2026年のエージェントインフラストラクチャ用CAPTCHAソルバーの選定には、これらのパフォーマンスメトリクスの慎重な評価が必要である。
自律システムにおけるAPIの役割
APIは、エージェントが外部サービスと相互作用するための接続部品を提供する。大規模なCAPTCHAを処理するシステムは、検証処理の計算負荷をオフロードするために専門的なAPIに依存する。
シンクロナスAPIとアシンクロナスAPI
検証APIはシンクロナスまたはアシンクロナスのいずれかである。シンクロナスAPIは、チャレンジが解決されるまでエージェントをブロックするため、パフォーマンスのボトルネックを引き起こす可能性がある。アシンクロナスAPIは、チャレンジを提出し、後で結果をポーリングすることで、全体的なスループットを向上させる。
APIのレートリミットとクォータ
エージェントが大規模なCAPTCHAを処理する際、APIのレートリミットとクォータを慎重に管理する必要がある。これらの制限を超えると、一時的なブロックやパフォーマンスの低下が発生する可能性がある。トークンバケットアルゴリズムとリクエストキューイングの実装により、API使用ポリシーに準拠することができる。詳細については、AIエージェント用CAPTCHAソルビングインフラストラクチャのガイドを参照してください。
データ収集ワークフローのスケーリング
データ収集は、自律エージェントの主なユースケースである。データ量が増加するにつれて、システムはそれに応じてスケールする必要がある。エージェントが大規模なCAPTCHAを処理するとき、組織は競争情報の収集、市場トレンドのモニタリング、公開情報の集約を効率的に実行できる。
分散クローリングアーキテクチャ
何百万ものページを処理するため、エージェントは通常、分散クラスターに配置される。クラスター内の各ノードは、必要なときにページを取得し、検証チャレンジを処理しながら独立して動作する。この分散アプローチにより、単一の障害ポイントを作成することなく、CAPTCHAを大規模に処理できる。
データの正規化と保存
データが収集された後、分析のために正規化され保存される必要がある。エージェントは、通常、生のHTMLをデータベースに挿入する前にクリーンアップし構造化するデータパイプラインと統合する。このパイプラインは、検証チャレンジによって引き起こされる中断に耐えなければならない。
エージェントインフラのセキュリティに関する考慮事項
自律エージェントを展開する際、セキュリティは重要な懸念事項である。大規模なCAPTCHAを処理するシステムは、不正アクセスから機密資格情報、APIキー、プロキシ設定を保護する必要がある。
資格情報の管理
エージェントは、ソースコードに資格情報をハードコードしてはならない。代わりに、実行時にAPIキーとプロキシパスワードを取得するためのセキュアなシークレット管理システムを使用するべきである。この実践により、コードベースが侵害された場合の資格情報の露出リスクが最小限に抑えられる。
ネットワークセキュリティ
エージェントと検証APIとの通信は、TLSを使用して暗号化される必要がある。この暗号化により、MITM攻撃を防ぎ、検証トークンの整合性を確保する。組織は、セキュリティ侵害を示す異常なネットワークトラフィックを監視する必要がある。
検証処理アプローチの比較
| アプローチ | スケーラビリティ | メンテナンス負荷 | 成功確率 | 最適なユースケース |
|---|---|---|---|---|
| 自社のMLモデル | 高 | 非常に高 | 変動 | 特定の、特許取得されたチャレンジ |
| 手動解決チーム | 低 | 高 | 高 | 低ボリューム、非常に複雑なタスク |
| 自動化APIサービス | 非常に高 | 低 | 非常に高 | 高ボリューム、標準的なチャレンジ |
| ブラウザ拡張機能 | 低 | 中 | 中 | デスクトップ自動化、テスト |
コンプライアンスと責任ある使用
自動化されたデータ収集は常に法的および倫理的な基準に準拠する必要がある。大規模なCAPTCHAを処理するシステムは、特定の利用規約を持つサードパーティインフラストラクチャと相互作用する。組織は、GDPRやCCPAなどの関連規制に準拠する自動化の実践を確保しなければならない。
責任ある使用には、robots.txtの指示を尊重し、合理的なレートリミットを実装し、ターゲットサービスへの干渉を避けることが含まれる。電子フロントイーフの自動アクセスに関するガイドラインは、ウェブスクリーピングにおける倫理基準を維持するための貴重な文脈を提供する。コンプライアンスされたシステムを構築するための詳細については、AIエージェント用ボット保護インフラストラクチャのガイドを参照してください。
トラフィック検証の今後のトレンド
ウェブセキュリティの状況は常に進化している。AIエージェントがより高度になるにつれて、リスク管理システムはそれらを検出するために適応する。大規模なCAPTCHAを処理する組織は、これらのトレンドに先んじて対応する必要があり、継続的な運用を維持する。
ゼロトラストアーキテクチャ
ゼロトラストアーキテクチャは、すべてのトラフィックが潜在的に悪意あるものであると仮定する。これらのシステムは、ログイン時の単一のチェックではなく、ユーザーのセッション全体を通して継続的な検証を必要とする。エージェントは、アクセスを維持するためにこれらの継続的な検証モデルに適応する必要がある。
プライバシー保護型検証
ユーザーのプライバシーを重視する新しい検証方法が登場している。これらの方法は、敏感なデータを収集することなく人間の相互作用を検証する暗号化証明を使用する。これらの技術が成熟するにつれて、エージェントは新しいプロトコルを統合して大規模なCAPTCHAを処理する必要がある。プライバシーパスに関するIETF仕様は、これらの新しい検証メカニズムの技術的基盤を明示している。
結論
現代のウェブ自動化において、大規模なCAPTCHAを効率的に処理するシステムの構築は不可欠である。検証処理をコアエージェントロジックから分離し、専門的なAPIを使用することで、開発者は高い成功確率を達成し、継続的な運用を維持できる。堅牢なエラー処理、プロキシ管理、非同期処理の実装により、自律的なシステムは複雑なリスク管理環境を信頼性を持ってナビゲートできる。エンタープライズグレードの検証処理には、CapSolverが大規模なAIエージェントの展開をサポートするために必要なインフラストラクチャと機械学習の能力を提供する。
FAQ
検証チャレンジを処理する最も効率的な方法は何ですか?
専用のAPIサービスを使用することは一般的に最も効率的な方法です。計算負荷とメンテナンス要件を専門的なインフラに転嫁し、エージェントが主要なタスクに集中できるようにします。
プロキシネットワークは検証成功確率にどのように影響しますか?
プロキシネットワークはリクエストの配布とポジティブなIPの評判の維持に不可欠です。高品質な住宅プロキシは、高度なリスク管理措置を発動する可能性を低減し、全体的な成功確率を向上させます。
自律システムは人間の行動をシミュレートできますか?
はい、高度なシステムは人間のようなマウスの動き、タイピングパターン、スクロール動作をシミュレートできます。このシミュレーションは、現代のセキュリティプラットフォームによって実装された行動分析チェックを通過するためにしばしば必要です。
自動化されたウェブ操作における法的考慮事項は何ですか?
自動化された操作は、データプライバシー規制、利用規約、著作権法に準拠する必要があります。責任あるスクラピング実践を実装し、レートリミットを尊重し、ターゲットインフラに損害を与えないことが重要です。
機械学習モデルは画像の課題をどのように解決しますか?
機械学習モデルは、オブジェクト検出や画像セグメンテーションなどのコンピュータビジョン技術を使用して、視覚的なパズルを分析し解決します。これらのモデルは、進化する課題の種類に対して高い精度を維持するために、新しいデータで継続的に訓練されます。
もっと見る
AIJun 26, 2026
CAPTCHA: AIエージェントインフラの欠けている要素
なぜトラフィック検証がAIエージェントインフラストラクチャの欠かせない要素であるかを発見してください。自律型エージェント向けの堅牢なソリューションを統合する方法を学びましょう。
AIJun 26, 2026
CAPTCHA耐性をAIエージェントに組み込む
- AIエージェントは、自動化されたタスク中に継続的な運用を維持するために強力なCAPTCHAの耐性が必要です。 - 構造化されたトラフィック検証戦略を実装することで、リスク管理メカニズムによる混乱を最小限に抑えることができます。 - 信頼性の高いCAPTCHA解決APIを活用することで、複雑な課題の効率的な処理が保証されます。 - 適切なインフラ設計により、コアエージェントロジックとボット保護管理を分離することができます。