CAPTCHA: AIエージェントインフラの欠けている要素

Sora Fujimoto
AI Solutions Architect
TL;DR
- AIエージェントインフラには、トラフィック検証とリスク制御システムを効果的に処理する堅牢なメカニズムが必要です。
- 伝統的なウェブオートメーションツールは、現代のセキュリティチェックポイントや行動分析に遭遇すると多くの場合失敗します。
- 信頼性の高い解決APIを統合することで、自律的なエージェントの継続的な運用と高い成功確率を確保できます。
- CapSolverは、既存のアーキテクチャに直接統合できるエージェント対応のソリューションを提供しています。
- 検証チャレンジの適切な処理は、スケーラブルで信頼性があり、コンプライアンスに合致したデータ収集パイプラインにおいて不可欠です。
イントロダクション
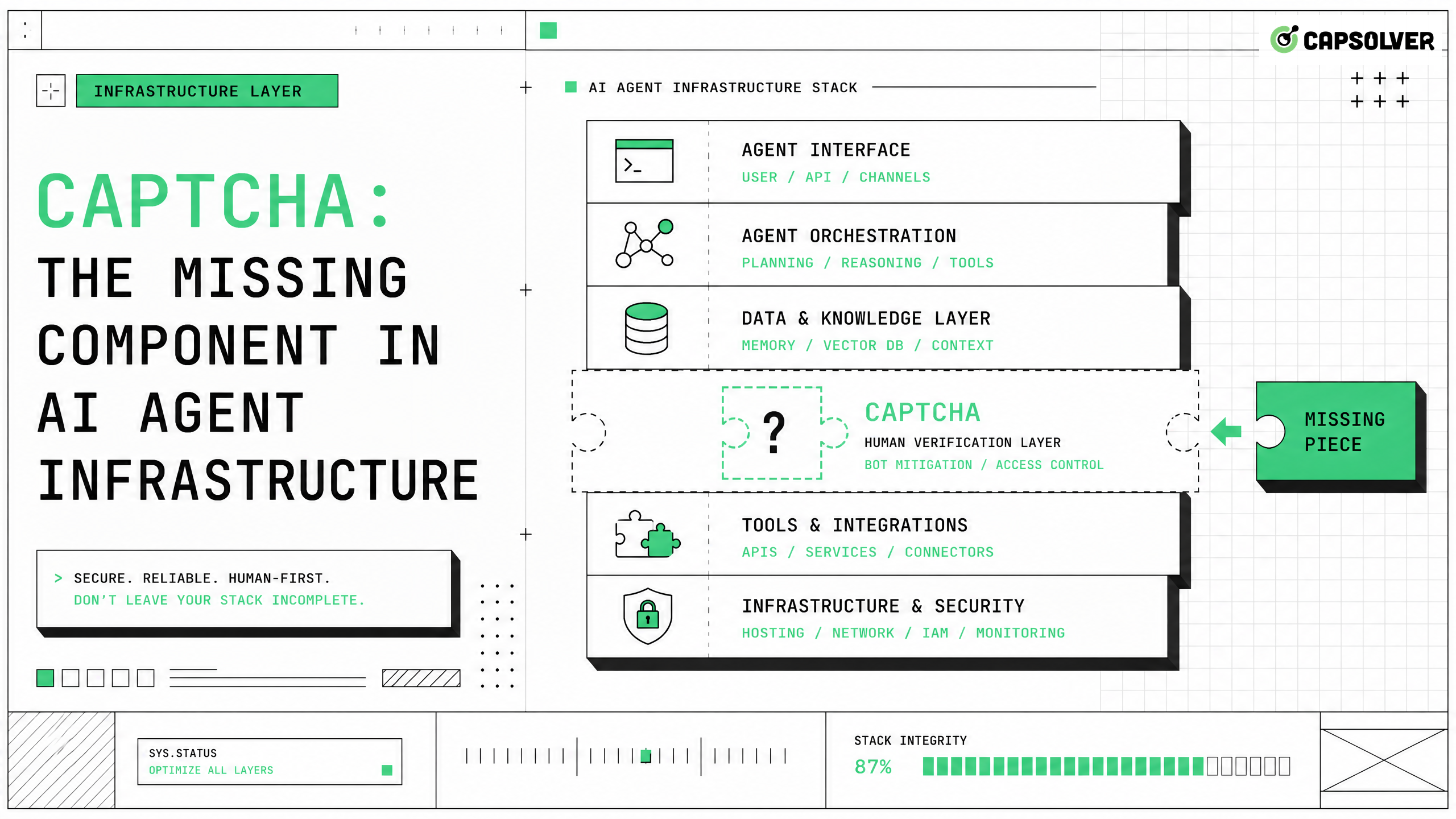
堅牢なAIエージェントインフラを構築するには、高度な言語モデルや実行環境だけでなく、より多くの要素が必要です。ウェブ上で自律的に動作するエージェントにとって最も大きな障壁は、複雑なトラフィック検証システムを乗り越えることです。エージェントがこれらの課題に遭遇すると、運用が停止し、データ収集が失敗し、全体のワークフローが破綻します。CapSolverのような信頼性の高いソリューションを統合することは、継続的な実行を維持するために不可欠です。現代のウェブ環境では、人間のユーザーと自動スクリプトを区別するための高度なリスク制御メカニズムが導入されています。これらの課題を専用のコンポーネントで処理しない限り、AIエージェントインフラは不完全で脆いままになります。この記事では、トラフィック検証を扱うことが自律システムにとってなぜ重要なのか、そしてさまざまなウェブプラットフォームで信頼性があり、コンプライアンスに合致し、スケーラブルな運用を確保するための効果的なソリューションの実装方法について探ります。
AIエージェントインフラの進化
自律エージェントの開発は、単純なスクリプト実行から複雑な目標指向の行動へと移行しています。初期のオートメーションは基本的なHTTPリクエストと静的HTMLの解析に依存していました。これらの方法は初期のウェブアプリケーションには十分でしたが、インターネットの進化に伴いすぐに陳腐化しました。現在、AIエージェントインフラはヘッドレスブラウザ、コンピュータビジョン、動的な意思決定機能を含んでいます。この進化により、エージェントは人間ユーザーのようにJavaScriptを多用する現代のウェブアプリケーションと対話できるようになります。
しかし、エージェントがより高度になるにつれて、自動トラフィックを管理するシステムもさらに複雑になっています。ウェブプラットフォームは、リソースを保護し、サービス品質を維持するために多層的なリスク制御措置を導入しています。これらの措置には行動分析、デバイスファINGERプリント、複雑な検証チャレンジが含まれます。エージェントが効果的に動作するためには、下位のAIエージェントインフラがこれらのセキュリティレイヤーを考慮する必要があります。この要件を無視すると、生産環境で高い失敗率と信頼性のないパフォーマンスに直面することになります。
この問題の範囲を理解するには、現代のオートメーションスタックを構成する要素を検討する必要があります。一般的な設定には、推論用の言語モデル、コンテキスト保持用のメモリシステム、外部インターフェースとの対話用の実行環境が含まれます。開発者は推論やメモリに多くの注力を注いでいますが、実行環境はトラフィック検証に必要なツールを欠いていることがよくあります。このAIエージェントインフラのギャップが、現実世界のアプリケーションで多くの自律システムが失敗する原因です。このギャップを埋めるには、自動化システムの設計および展開方法に根本的な変化が必要です。
現代のトラフィック検証メカニズムの理解
現代のウェブプラットフォームは、自動トラフィックを識別および管理するための多様な技術を採用しています。これらのシステムは単なるIPレート制限をはるかに超えています。数百のデータポイントを分析して訪問者の包括的なプロフィールを作成します。これらのメカニズムを理解することは、耐障害性のあるオートメーションアーキテクチャを構築するために不可欠です。
主な方法の一つはブラウザファINGERプリントです。この技術は、ユーザーのオペレーティングシステム、ブラウザバージョン、インストールされたフォント、画面解像度、ハードウェアの並列性などの情報を収集します。ファINGERプリントが既知のオートメーションツールと一致している、または人間ユーザーの典型的なエントロピーを欠いている場合、システムはリクエストをフラグ付けます。さらに、プラットフォームはマウスの動き、キーストロークのダイナミクス、ナビゲーション速度などの行動パターンを監視します。自動スクリプトは、人間の行動と区別がつきにくい硬直的で予測可能なパターンを示すことがよくあります。
システムがファINGERプリントや行動に異常を検出すると、通常は検証チャレンジが提示されます。これらのチャレンジは、標準スクリプトでは再現が難しい認知処理を必要とします。画像内のオブジェクトの識別、変形したテキストの転写、論理パズルの解決などが含まれます。自律エージェントが専用の解決メカニズムなしでこれらのチャレンジに遭遇すると、直ちに失敗します。したがって、AIエージェントのボット保護インフラを理解することは、信頼性のあるオートメーションワークフローを開発するための前提条件です。
OWASP Automated Threats to Web Applicationsプロジェクトは、プラットフォームが自動化された相互作用を識別および緩和する方法について詳細なドキュメンテーションを提供しており、現代のリスク制御システムの複雑さを強調しています。
トラフィック検証が自律エージェントを妨げる理由
自律エージェントがターゲットウェブサイトに移動すると、しばしばトラフィック検証チェックポイントに遭遇します。これらのチェックポイントは、上述した要因に基づいてリクエストを評価します。システムが異常を検出すると、チャレンジが提示されます。
人間ユーザーにとって、検証チャレンジを解決することは小さな不便さです。自動システムにとっては、ハードブロッカーです。標準的なウェブオートメーションツールは、これらのチャレンジをネイティブに解釈または解決できません。エージェントがチェックポイントに遭遇すると、通常タイムアウトまたはエラーを返し、全体のワークフローが中断します。この中断は、多くのAIエージェントインフラ設計における重要な欠点を示しています。つまり、ウェブインターフェースが常にアクセス可能で応答性があると仮定していることです。
信頼性の高いシステムを構築するには、自律エージェント用のCAPTCHA解決APIを統合する必要があります。この統合により、エージェントはチャレンジを検出、専門的なサービスに転送し、手動の介入なしで解決を提出できます。この機能をAIエージェントインフラに組み込むことで、開発者は、積極的なリスク制御措置に直面しても継続的に運用できるシステムを確保できます。
これらのチェックポイントを処理できないことは、即時のタスクの失敗だけでなく、エージェントの状態の破損にもつながります。エージェントがページが正常に読み込まれたと仮定しているが、実際には検証画面に詰まっている場合、後続のアクションは失敗し、連鎖的なエラーを引き起こします。これにより、堅牢なエラー処理と状態検証が、あらゆるオートメーションフレームワークの必須要素となります。
W3C Working Group Note on CAPTCHAによると、自動システムは検証チェックポイントを効果的に通過するためのアクセス可能な代替手段やプログラムインターフェースを持つ必要があります。これは構造化されたソリューションの必要性を強調しています。
アーキテクチャへのソリューションの統合
エージェントフレームワークに解決コンポーネントを追加するには、慎重な計画が必要です。統合は信頼性があり、高速で、さまざまなチャレンジタイプを処理できる必要があります。不適切に実装されたソリューションは、レイテンシーを導入し、エージェント全体の効率を低下させる可能性があります。
最初のステップは適切なサービスの選択です。開発者は、エージェント対応のCAPTCHAソルバーを検討する必要があります。このサービスは高い正確性と低レイテンシーを提供し、現代のチャレンジタイプ、例えば画像認識、オーディオトランスクリプション、行動パズルをサポートする必要があります。サービスが選択されると、エージェントの実行ループに統合する必要があります。
エージェントが検証チェックポイントを検出すると、主なタスクを一時停止し、解決プロセスを開始します。エージェントはページから必要なパラメータを抽出し、解決APIに送信し、応答を待ちます。解決が受け取られると、エージェントはその解決をターゲットウェブサイトに提出し、ワークフローを再開します。このプロセスは非同期で処理される必要があります。これにより、エージェントが他の操作をブロックしないようにします。
エラー回復も統合において重要な側面です。解決が失敗したりタイムアウトしたりした場合、エージェントはプロセスを再試行するか、問題をエスカレーションする能力が必要です。指数関数的バックオフとフォールバック戦略を実装することで、一時的なネットワーク問題やサービスの低下が恒久的なタスクの失敗を引き起こさないようにします。
CapSolverボーナスコードを取得する
オートメーション予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、毎回チャージに対して 5%のボーナス を受け取れます — 限度はありません。
今すぐCapSolverダッシュボードで取得してください

オートメーションにおけるヘッドレスブラウザの役割
ヘッドレスブラウザは現代のAIエージェントインフラの基本的な構成要素です。これらはJavaScriptをレンダリングし、動的な要素と対話し、人間の行動をシミュレートする能力をエージェントに提供します。しかし、ヘッドレスブラウザはトラフィック検証の処理において独自の課題ももたらします。
多くのリスク制御システムは、ヘッドレスブラウザを特定するために実行環境を分析します。特定のJavaScript変数、ブラウザのプロパティ、レンダリングの不一致をチェックします。ヘッドレスブラウザが検出されると、システムは検証チャレンジを提示するか、リクエストを完全にブロックする可能性が高くなります。ヘッドレスブラウザ検出とは何か、そしてそれを回避する方法を理解することは、信頼性のある運用を維持するために不可欠です。
この問題を軽減するために、開発者はヘッドレスブラウザを標準的なユーザー環境に模倣するように構成する必要があります。これはブラウザファINGERプリントの変更、クッキーの管理、現実的なインタラクションパターンのシミュレーションを含みます。これらの予防策を講じても、エージェントは依然として検証チェックポイントに遭遇します。したがって、堅牢なAIエージェントインフラは、ステルス的なブラウザ設定と信頼性の高い解決サービスの組み合わせを必要とします。
MDN Web Docs on WebDriverは、自動ブラウザがウェブ要素とどのように相互作用するかについての広範なガイドラインを提供しており、これはステルス環境の構成とブラウザオートメーションプロトコルの管理に不可欠です。
トラフィック検証のアプローチの比較
AIエージェントインフラを設計する際、開発者はトラフィック検証を扱うためのいくつかのオプションがあります。それぞれのアプローチには利点と制限があります。選択は、プロジェクトの具体的な要件、規模、予算、技術的専門知識に依存します。
| アプローチ | 説明 | 利点 | 欠点 |
|---|---|---|---|
| 人間の介入 | エージェントを一時停止し、人間オペレーターにチャレンジを解決してもらう。 | 高い正確性、追加のAPIコストなし。 | スケーラブルではない、大きなレイテンシーを導入する、オートメーションの目的を無効にする。 |
| インハウスの機械学習 | 特定のチャレンジタイプを解決するカスタムモデルを開発する。 | プロセスの完全なコントロール、長期的なコストが低い可能性。 | 専門知識が必要、高いメンテナンスオーバーヘッド、新しいチャレンジタイプに苦労する。 |
| 第三者APIの統合 | 専門的なサービスを使用してチャレンジ解決を処理する。 | 高度なスケーラビリティ、多様なチャレンジタイプをサポート、メンテナンスが少ない。 | 継続的なサブスクリプションまたは使用料が必要、外部依存が生じる。 |
| ハイブリッドシステム | 基本的なインハウスモデルと複雑なチャレンジ用の第三者APIを組み合わせる。 | コストと能力のバランス、リソースの最適化。 | 実装とメンテナンスが複雑、高度なルーティングロジックが必要。 |
ほとんどの企業アプリケーションでは、第三者APIを統合することが最も実用的なアプローチです。これにより、開発者は複雑なコンピュータビジョンモデルの維持ではなく、オートメーションシステムのコアロジックの構築に集中できます。オプションを評価する際には、2026年のAIエージェントに最適なCAPTCHA APIを確認して、パフォーマンス要件と統合能力に合致するサービスを選択することが役立ちます。
信頼性のあるデータ収集パイプラインの構築
自律システムをスケーリングするには、信頼性のあるAIエージェント用のウェブオートメーションインフラスタックが必要です。リクエストの量が増えるにつれて、検証チャレンジの頻度も増加します。オートメーションアーキテクチャは、パフォーマンスの低下なしにこの増加した負荷を処理できる必要があります。
これは、複数のノードで同時に動作できる分散アーキテクチャを必要とします。解決コンポーネントもそれに応じてスケーリングする必要があります。高並列性と迅速な応答時間をサポートする必要があります。マイクロサービスアーキテクチャを実装することで、解決ロジックをコアエージェント実行から分離し、信頼性と保守性を向上させることができます。
さらに、モニタリングとロギングは、健全なAIエージェントインフラの維持に不可欠です。開発者は成功確率、応答時間、エラー頻度を追跡し、運用に影響を与える潜在的な問題を事前に特定する必要があります。このデータを継続的に分析することで、組織はオートメーションスタックを最適化し、すべての展開で一貫したパフォーマンスを確保できます。
プロキシ管理も信頼性のあるパイプラインの重要な要素です。IPアドレスをローテーションすることで、リクエストを分散し、レートリミットやIPベースのブロックの可能性を低下させます。高品質なプロキシと効果的な検証解決を組み合わせることで、非常に信頼性の高いオートメーション環境が構築されます。
コンプライアンスと責任あるオートメーション
AIエージェントインフラがより能力を備えるにつれて、責任あるオートメーションの重要性が高まっています。エージェントは、相互作用するプラットフォームの利用規約に従って動作する必要があります。トラフィック検証システムは、通常、ユーザーのデータ保護、詐欺防止、リソースへの公平なアクセスを確保するために導入されています。
あなたのエージェントフレームワークに解決機能を統合する際には、操作の影響を考慮することが重要です。自動化システムはサーバーを過負荷にしたり、機密の個人情報を取り込んだり、悪意のある活動に使用したりしてはなりません。開発者はレート制限を実装し、robots.txtの指示を尊重し、必要に応じてエージェントが適切に自己紹介することを確保しなければなりません。
電子フロント・ファウンデーションのイノベーションに関するガイドラインでは、技術の進歩を促進しつつ、ユーザーのプライバシーやプラットフォームの整合性を尊重する自動化システムの必要性が強調されています。
これらの原則に従うことで、組織は有害な影響を与えずに価値を提供する持続可能な自動化システムを構築できます。責任ある自動化は長期的な持続可能性を確保し、法的または評判上の損害のリスクを低減し、開発者とプラットフォーム運用者にとってより健全なエコシステムを育みます。
結論
現代のウェブで運用される自律システムにとって、トラフィック検証は依然として大きな障壁です。この課題を扱う専用のメカニズムがなければ、最も高度なエージェントでも信頼性を持ってタスクを実行できなくなります。AIエージェントインフラに堅牢な解決コンポーネントを統合することで、継続的な運用、スケーラビリティ、効率性を確保できます。この欠如しているコンポーネントに対処することで、脆弱なスクリプトが耐障害性のあるエンタープライズグレードの自動化システムに変貌します。アーキテクチャを強化したい開発者にとって、CapSolverを実装することで、複雑なリスク制御環境を効果的に乗り越え、作業フローを途切れることなく維持するための必要な機能が得られます。
よくある質問
ウェブ上の自律エージェントにとって最大の課題は何ですか?
最も重要な課題は、トラフィック検証とリスク制御システムを乗り越えることであり、これらは自動化されたリクエストをしばしばブロックし、ワークフローを妨げます。
ヘッドレスブラウザはトラフィック検証にどのように影響しますか?
ヘッドレスブラウザは、人間の操作パターンを正確にシミュレートしない、またはリスク制御システムによって実行環境が検出された場合、検証チェックポイントをトリガーする可能性があります。
なぜ手動介入はAIエージェントには適していないのでしょうか?
手動介入は大きな遅延を引き起こし、システムのスケーラビリティを妨げ、自律的な自動化の目的そのものを根本的に損ないます。
開発者が解決APIで求めなければならないものは何ですか?
開発者は高い正確性、低い応答時間、多様なチャレンジタイプのサポート、およびスケールでの並行リクエスト処理の能力を優先して検討すべきです。
組織はどのようにして責任ある自動化を確保すればよいのでしょうか?
組織はレート制限を実装し、プラットフォームのガイドラインを尊重し、機密データのスクレイピングを避けること、およびターゲットサーバーを過負荷にしない自動化システムを確保する必要があります。
もっと見る
AIJun 26, 2026
CAPTCHA耐性をAIエージェントに組み込む
- AIエージェントは、自動化されたタスク中に継続的な運用を維持するために強力なCAPTCHAの耐性が必要です。 - 構造化されたトラフィック検証戦略を実装することで、リスク管理メカニズムによる混乱を最小限に抑えることができます。 - 信頼性の高いCAPTCHA解決APIを活用することで、複雑な課題の効率的な処理が保証されます。 - 適切なインフラ設計により、コアエージェントロジックとボット保護管理を分離することができます。
AIJun 26, 2026
AIエージェントが大規模にCAPTCHAを処理する方法
- AIエージェントは、自動化されたウェブ操作中に大規模なCAPTCHAを処理するための堅牢なインフラを必要とします。 - 現代のトラフィック検証システムは、行動分析とデバイスファイントプリントを用いて自動化されたリクエストを検出します。 - 信頼できるCAPTCHA解決APIを統合することは、自律的なエージェントの継続的な運用を確保します。 - 分散アーキテクチャとプロキシローテーションは、高ボリュームを管理するために不可欠です。