Integrating Crawlab with CapSolver: Automated CAPTCHA Solving for Distributed Crawling

Ethan Collins
Pattern Recognition Specialist

Managing web crawlers at scale requires robust infrastructure that can handle modern anti-bot challenges. Crawlab is a powerful distributed web crawler management platform, and CapSolver is an AI-powered CAPTCHA solving service. Together, they enable enterprise-grade crawling systems that automatically bypass CAPTCHA challenges.
This guide provides complete, ready-to-use code examples for integrating Capsolver into your Crawlab spiders.
What You Will Learn
- Solving reCAPTCHA v2 with Selenium
- Solving Cloudflare Turnstile
- Scrapy middleware integration
- Node.js/Puppeteer integration
- Best practices for CAPTCHA handling at scale
What is Crawlab?
Crawlab is a distributed web crawler admin platform designed for managing spiders across multiple programming languages.
Key Features
- Language Agnostic: Supports Python, Node.js, Go, Java, and PHP
- Framework Flexible: Works with Scrapy, Selenium, Puppeteer, Playwright
- Distributed Architecture: Horizontal scaling with master/worker nodes
- Management UI: Web interface for spider management and scheduling
Installation
bash
# Using Docker Compose
git clone https://github.com/crawlab-team/crawlab.git
cd crawlab
docker-compose up -dAccess the UI at http://localhost:8080 (default: admin/admin).
What is Capsolver?
CapSolver is an AI-powered CAPTCHA solving service that provides fast and reliable solutions for various CAPTCHA types.
Supported CAPTCHA Types
- reCAPTCHA: v2, v3, and Enterprise
- Cloudflare: Turnstile and Challenge
- AWS WAF: Protection bypass
- And More
API Workflow
- Submit CAPTCHA parameters (type, siteKey, URL)
- Receive task ID
- Poll for solution
- Inject token into page
Prerequisites
- Python 3.8+ or Node.js 16+
- Capsolver API Key - Sign up here
- Chrome/Chromium browser
bash
# Python dependencies
pip install selenium requestsSolving reCAPTCHA v2 with Selenium
Complete Python script for solving reCAPTCHA v2:
python
"""
Crawlab + CapSolver: reCAPTCHA v2 Solver
Complete script for solving reCAPTCHA v2 challenges with Selenium
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Configuration
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverClient:
"""Capsolver API client for reCAPTCHA v2"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def create_task(self, task: dict) -> str:
"""Create a CAPTCHA solving task"""
payload = {
"clientKey": self.api_key,
"task": task
}
response = self.session.post(
f"{CAPSOLVER_API}/createTask",
json=payload
)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Capsolver error: {result.get('errorDescription')}")
return result['taskId']
def get_task_result(self, task_id: str, timeout: int = 120) -> dict:
"""Poll for task result"""
for _ in range(timeout):
payload = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(
f"{CAPSOLVER_API}/getTaskResult",
json=payload
)
result = response.json()
if result.get('status') == 'ready':
return result['solution']
if result.get('status') == 'failed':
raise Exception("CAPTCHA solving failed")
time.sleep(1)
raise Exception("Timeout waiting for solution")
def solve_recaptcha_v2(self, website_url: str, site_key: str) -> str:
"""Solve reCAPTCHA v2 and return token"""
task = {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
print(f"Creating task for {website_url}...")
task_id = self.create_task(task)
print(f"Task created: {task_id}")
print("Waiting for solution...")
solution = self.get_task_result(task_id)
return solution['gRecaptchaResponse']
def get_balance(self) -> float:
"""Get account balance"""
response = self.session.post(
f"{CAPSOLVER_API}/getBalance",
json={"clientKey": self.api_key}
)
return response.json().get('balance', 0)
class RecaptchaV2Crawler:
"""Selenium crawler with reCAPTCHA v2 support"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.capsolver = CapsolverClient(CAPSOLVER_API_KEY)
def start(self):
"""Initialize browser"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--window-size=1920,1080")
self.driver = webdriver.Chrome(options=options)
print("Browser started")
def stop(self):
"""Close browser"""
if self.driver:
self.driver.quit()
print("Browser closed")
def detect_recaptcha(self) -> str:
"""Detect reCAPTCHA and return site key"""
try:
element = self.driver.find_element(By.CLASS_NAME, "g-recaptcha")
return element.get_attribute("data-sitekey")
except:
return None
def inject_token(self, token: str):
"""Inject solved token into page"""
self.driver.execute_script(f"""
// Set g-recaptcha-response textarea
var responseField = document.getElementById('g-recaptcha-response');
if (responseField) {{
responseField.style.display = 'block';
responseField.value = '{token}';
}}
// Set all hidden response fields
var textareas = document.querySelectorAll('textarea[name="g-recaptcha-response"]');
for (var i = 0; i < textareas.length; i++) {{
textareas[i].value = '{token}';
}}
""")
print("Token injected")
def submit_form(self):
"""Submit the form"""
try:
submit = self.driver.find_element(
By.CSS_SELECTOR,
'button[type="submit"], input[type="submit"]'
)
submit.click()
print("Form submitted")
except Exception as e:
print(f"Could not submit form: {e}")
def crawl(self, url: str) -> dict:
"""Crawl URL with reCAPTCHA v2 handling"""
result = {
'url': url,
'success': False,
'captcha_solved': False
}
try:
print(f"Navigating to: {url}")
self.driver.get(url)
time.sleep(2)
# Detect reCAPTCHA
site_key = self.detect_recaptcha()
if site_key:
print(f"reCAPTCHA v2 detected! Site key: {site_key}")
# Solve CAPTCHA
token = self.capsolver.solve_recaptcha_v2(url, site_key)
print(f"Token received: {token[:50]}...")
# Inject token
self.inject_token(token)
result['captcha_solved'] = True
# Submit form
self.submit_form()
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
result['error'] = str(e)
print(f"Error: {e}")
return result
def main():
"""Main entry point"""
# Check balance
client = CapsolverClient(CAPSOLVER_API_KEY)
print(f"Capsolver balance: ${client.get_balance():.2f}")
# Create crawler
crawler = RecaptchaV2Crawler(headless=True)
try:
crawler.start()
# Crawl target URL (replace with your target)
result = crawler.crawl("https://example.com/protected-page")
print("\n" + "=" * 50)
print("RESULT:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Solving Cloudflare Turnstile
Complete Python script for solving Cloudflare Turnstile:
python
"""
Crawlab + Capsolver: Cloudflare Turnstile Solver
Complete script for solving Turnstile challenges
"""
import os
import time
import json
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
# Configuration
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class TurnstileSolver:
"""Capsolver client for Turnstile"""
def __init__(self, api_key: str):
self.api_key = api_key
self.session = requests.Session()
def solve(self, website_url: str, site_key: str) -> str:
"""Solve Turnstile CAPTCHA"""
print(f"Solving Turnstile for {website_url}")
print(f"Site key: {site_key}")
# Create task
task_data = {
"clientKey": self.api_key,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": site_key
}
}
response = self.session.post(f"{CAPSOLVER_API}/createTask", json=task_data)
result = response.json()
if result.get('errorId', 0) != 0:
raise Exception(f"Capsolver error: {result.get('errorDescription')}")
task_id = result['taskId']
print(f"Task created: {task_id}")
# Poll for result
for i in range(120):
result_data = {
"clientKey": self.api_key,
"taskId": task_id
}
response = self.session.post(f"{CAPSOLVER_API}/getTaskResult", json=result_data)
result = response.json()
if result.get('status') == 'ready':
token = result['solution']['token']
print(f"Turnstile solved!")
return token
if result.get('status') == 'failed':
raise Exception("Turnstile solving failed")
time.sleep(1)
raise Exception("Timeout waiting for solution")
class TurnstileCrawler:
"""Selenium crawler with Turnstile support"""
def __init__(self, headless: bool = True):
self.headless = headless
self.driver = None
self.solver = TurnstileSolver(CAPSOLVER_API_KEY)
def start(self):
"""Initialize browser"""
options = Options()
if self.headless:
options.add_argument("--headless=new")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
self.driver = webdriver.Chrome(options=options)
def stop(self):
"""Close browser"""
if self.driver:
self.driver.quit()
def detect_turnstile(self) -> str:
"""Detect Turnstile and return site key"""
try:
turnstile = self.driver.find_element(By.CLASS_NAME, "cf-turnstile")
return turnstile.get_attribute("data-sitekey")
except NoSuchElementException:
return None
def inject_token(self, token: str):
"""Inject Turnstile token"""
self.driver.execute_script(f"""
var token = '{token}';
// Find cf-turnstile-response field
var field = document.querySelector('[name="cf-turnstile-response"]');
if (field) {{
field.value = token;
}}
// Find all turnstile inputs
var inputs = document.querySelectorAll('input[name*="turnstile"]');
for (var i = 0; i < inputs.length; i++) {{
inputs[i].value = token;
}}
""")
print("Token injected!")
def crawl(self, url: str) -> dict:
"""Crawl URL with Turnstile handling"""
result = {
'url': url,
'success': False,
'captcha_solved': False,
'captcha_type': None
}
try:
print(f"Navigating to: {url}")
self.driver.get(url)
time.sleep(3)
# Detect Turnstile
site_key = self.detect_turnstile()
if site_key:
result['captcha_type'] = 'turnstile'
print(f"Turnstile detected! Site key: {site_key}")
# Solve
token = self.solver.solve(url, site_key)
# Inject
self.inject_token(token)
result['captcha_solved'] = True
time.sleep(2)
result['success'] = True
result['title'] = self.driver.title
except Exception as e:
print(f"Error: {e}")
result['error'] = str(e)
return result
def main():
"""Main entry point"""
crawler = TurnstileCrawler(headless=True)
try:
crawler.start()
# Crawl target (replace with your target URL)
result = crawler.crawl("https://example.com/turnstile-protected")
print("\n" + "=" * 50)
print("RESULT:")
print(json.dumps(result, indent=2))
finally:
crawler.stop()
if __name__ == "__main__":
main()Scrapy Integration
Complete Scrapy spider with Capsolver middleware:
python
"""
Crawlab + Capsolver: Scrapy Spider
Complete Scrapy spider with CAPTCHA solving middleware
"""
import scrapy
import requests
import time
import os
CAPSOLVER_API_KEY = os.getenv('CAPSOLVER_API_KEY', 'YOUR_CAPSOLVER_API_KEY')
CAPSOLVER_API = 'https://api.capsolver.com'
class CapsolverMiddleware:
"""Scrapy middleware for CAPTCHA solving"""
def __init__(self):
self.api_key = CAPSOLVER_API_KEY
def solve_recaptcha_v2(self, url: str, site_key: str) -> str:
"""Solve reCAPTCHA v2"""
# Create task
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": self.api_key,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": url,
"websiteKey": site_key
}
}
)
task_id = response.json()['taskId']
# Poll for result
for _ in range(120):
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={"clientKey": self.api_key, "taskId": task_id}
).json()
if result.get('status') == 'ready':
return result['solution']['gRecaptchaResponse']
time.sleep(1)
raise Exception("Timeout")
class CaptchaSpider(scrapy.Spider):
"""Spider with CAPTCHA handling"""
name = "captcha_spider"
start_urls = ["https://example.com/protected"]
custom_settings = {
'DOWNLOAD_DELAY': 2,
'CONCURRENT_REQUESTS': 1,
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.capsolver = CapsolverMiddleware()
def parse(self, response):
# Check for reCAPTCHA
site_key = response.css('.g-recaptcha::attr(data-sitekey)').get()
if site_key:
self.logger.info(f"reCAPTCHA detected: {site_key}")
# Solve CAPTCHA
token = self.capsolver.solve_recaptcha_v2(response.url, site_key)
# Submit form with token
yield scrapy.FormRequest.from_response(
response,
formdata={'g-recaptcha-response': token},
callback=self.after_captcha
)
else:
yield from self.extract_data(response)
def after_captcha(self, response):
"""Process page after CAPTCHA"""
yield from self.extract_data(response)
def extract_data(self, response):
"""Extract data from page"""
yield {
'title': response.css('title::text').get(),
'url': response.url,
}
# Scrapy settings (settings.py)
"""
BOT_NAME = 'captcha_crawler'
SPIDER_MODULES = ['spiders']
# Capsolver
CAPSOLVER_API_KEY = 'YOUR_CAPSOLVER_API_KEY'
# Rate limiting
DOWNLOAD_DELAY = 2
CONCURRENT_REQUESTS = 1
ROBOTSTXT_OBEY = True
"""Node.js/Puppeteer Integration
Complete Node.js script with Puppeteer:
javascript
/**
* Crawlab + Capsolver: Puppeteer Spider
* Complete Node.js script for CAPTCHA solving
*/
const puppeteer = require('puppeteer');
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY || 'YOUR_CAPSOLVER_API_KEY';
const CAPSOLVER_API = 'https://api.capsolver.com';
/**
* Capsolver client
*/
class Capsolver {
constructor(apiKey) {
this.apiKey = apiKey;
}
async createTask(task) {
const response = await fetch(`${CAPSOLVER_API}/createTask`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
task: task
})
});
const result = await response.json();
if (result.errorId !== 0) {
throw new Error(result.errorDescription);
}
return result.taskId;
}
async getTaskResult(taskId, timeout = 120) {
for (let i = 0; i < timeout; i++) {
const response = await fetch(`${CAPSOLVER_API}/getTaskResult`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
clientKey: this.apiKey,
taskId: taskId
})
});
const result = await response.json();
if (result.status === 'ready') {
return result.solution;
}
if (result.status === 'failed') {
throw new Error('Task failed');
}
await new Promise(r => setTimeout(r, 1000));
}
throw new Error('Timeout');
}
async solveRecaptchaV2(url, siteKey) {
const taskId = await this.createTask({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse;
}
async solveTurnstile(url, siteKey) {
const taskId = await this.createTask({
type: 'AntiTurnstileTaskProxyLess',
websiteURL: url,
websiteKey: siteKey
});
const solution = await this.getTaskResult(taskId);
return solution.token;
}
}
/**
* Main crawling function
*/
async function crawlWithCaptcha(url) {
const capsolver = new Capsolver(CAPSOLVER_API_KEY);
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
try {
console.log(`Crawling: ${url}`);
await page.goto(url, { waitUntil: 'networkidle2' });
// Detect CAPTCHA type
const captchaInfo = await page.evaluate(() => {
const recaptcha = document.querySelector('.g-recaptcha');
if (recaptcha) {
return {
type: 'recaptcha',
siteKey: recaptcha.dataset.sitekey
};
}
const turnstile = document.querySelector('.cf-turnstile');
if (turnstile) {
return {
type: 'turnstile',
siteKey: turnstile.dataset.sitekey
};
}
return null;
});
if (captchaInfo) {
console.log(`${captchaInfo.type} detected!`);
let token;
if (captchaInfo.type === 'recaptcha') {
token = await capsolver.solveRecaptchaV2(url, captchaInfo.siteKey);
// Inject token
await page.evaluate((t) => {
const field = document.getElementById('g-recaptcha-response');
if (field) field.value = t;
document.querySelectorAll('textarea[name="g-recaptcha-response"]')
.forEach(el => el.value = t);
}, token);
} else if (captchaInfo.type === 'turnstile') {
token = await capsolver.solveTurnstile(url, captchaInfo.siteKey);
// Inject token
await page.evaluate((t) => {
const field = document.querySelector('[name="cf-turnstile-response"]');
if (field) field.value = t;
}, token);
}
console.log('CAPTCHA solved and injected!');
}
// Extract data
const data = await page.evaluate(() => ({
title: document.title,
url: window.location.href
}));
return data;
} finally {
await browser.close();
}
}
// Main execution
const targetUrl = process.argv[2] || 'https://example.com';
crawlWithCaptcha(targetUrl)
.then(result => {
console.log('\nResult:');
console.log(JSON.stringify(result, null, 2));
})
.catch(console.error);Best Practices
1. Error Handling with Retries
python
def solve_with_retry(solver, url, site_key, max_retries=3):
"""Solve CAPTCHA with retry logic"""
for attempt in range(max_retries):
try:
return solver.solve(url, site_key)
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"Attempt {attempt + 1} failed: {e}")
time.sleep(2 ** attempt) # Exponential backoff2. Cost Management
- Detect before solving: Only call Capsolver when CAPTCHA is present
- Cache tokens: reCAPTCHA tokens valid for ~2 minutes
- Monitor balance: Check balance before batch jobs
3. Rate Limiting
python
# Scrapy settings
DOWNLOAD_DELAY = 3
CONCURRENT_REQUESTS_PER_DOMAIN = 14. Environment Variables
bash
export CAPSOLVER_API_KEY="your-api-key-here"Troubleshooting
| Error | Cause | Solution |
|---|---|---|
ERROR_ZERO_BALANCE |
No credits | Top up CapSolver account |
ERROR_CAPTCHA_UNSOLVABLE |
Invalid parameters | Verify site key extraction |
TimeoutError |
Network issues | Increase timeout, add retries |
WebDriverException |
Browser crash | Add --no-sandbox flag |
FAQ
Q: How long are CAPTCHA tokens valid?
A: reCAPTCHA tokens: ~2 minutes. Turnstile: varies by site.
Q: What's the average solve time?
A: reCAPTCHA v2: 5-15s, Turnstile: 1-10s.
Q: Can I use my own proxy?
A: Yes, use task types without "ProxyLess" suffix and provide proxy config.
Conclusion
Integrating CapSolver with Crawlab enables robust CAPTCHA handling across your distributed crawling infrastructure. The complete scripts above can be copied directly into your Crawlab spiders.
Ready to start? Sign up for CapSolver and supercharge your crawlers!
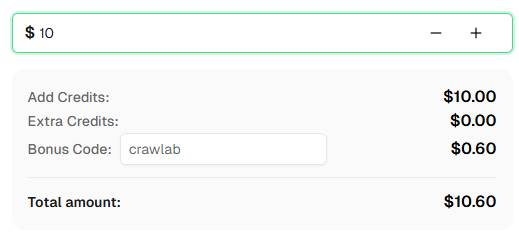
💡 Exclusive Bonus for Crawlab Integration Users:
To celebrate this integration, we’re offering an exclusive 6% bonus code — Crawlab for all CapSolver users who register through this tutorial.
Simply enter the code during recharge in Dashboard to receive an extra 6% credit instantly.
13. Documentations
- 13.1. Crawlab Documentation
- 13.2. Crawlab GitHub
- 13.3. Capsolver Documentation
- 13.4. Capsolver API Reference
More
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
Learn scalable Rust web scraping architecture with reqwest, scraper, async scraping, headless browser scraping, proxy rotation, and compliant CAPTCHA handling.

Web ScrapingApr 17, 2026
How to Scrape Job Listings Without Getting Blocked
Learn the best techniques to scrape job listings without getting blocked. Master Indeed scraping, Google Jobs API, and web scraping API with CapSolver.