Rust网络爬虫架构:可扩展的数据提取

Ethan Collins
Pattern Recognition Specialist
TL;DR
- Rust网络爬虫在将获取、解析、渲染和存储分层为独立模块时效果最佳。
reqwest和scraper能以较低资源成本和更清晰的维护方式覆盖许多静态目标。- 使用Tokio进行异步爬虫能提升I/O密集型任务的吞吐量,但仍需要速率限制、重试和队列控制。
- 无头浏览器爬虫应作为JavaScript渲染页面的可选备用方案,而不是默认路径。
- 机器人保护、代理轮换和验证码事件应通过明确的政策和合规的自动化设计来处理。
- 对于符合实际业务需求的合法自动化流程,CapSolver可以通过其官方API流程融入狭窄的备用层。
Rust网络爬虫在设计为架构而非单个脚本时最为有效。本文面向需要可扩展可靠提取的工程师、数据团队和技术操作人员。主要结论如下:最佳的Rust网络爬虫系统应使用reqwest和scraper保持快速路径简单,仅在目标确实需要时才添加异步爬虫、无头浏览器爬虫、代理轮换和挑战处理。这种结构可降低成本、提高稳定性,并使长期运行的流水线更易于监控。
Rust网络爬虫概览
Rust网络爬虫是大规模提取任务的强项选择,因为它结合了内存安全和可预测的性能。当一个工作进程可能处理数千页、解析不稳定的标记并持续数小时写入标准化记录时,这些特性至关重要。
大多数搜索结果中的文章解释了如何获取单个页面并解析选择器。这些内容很有用,但很少回答更困难的问题:当需要弹性、可观测性和扩展空间时,完整的Rust网络爬虫架构应该是什么样子?
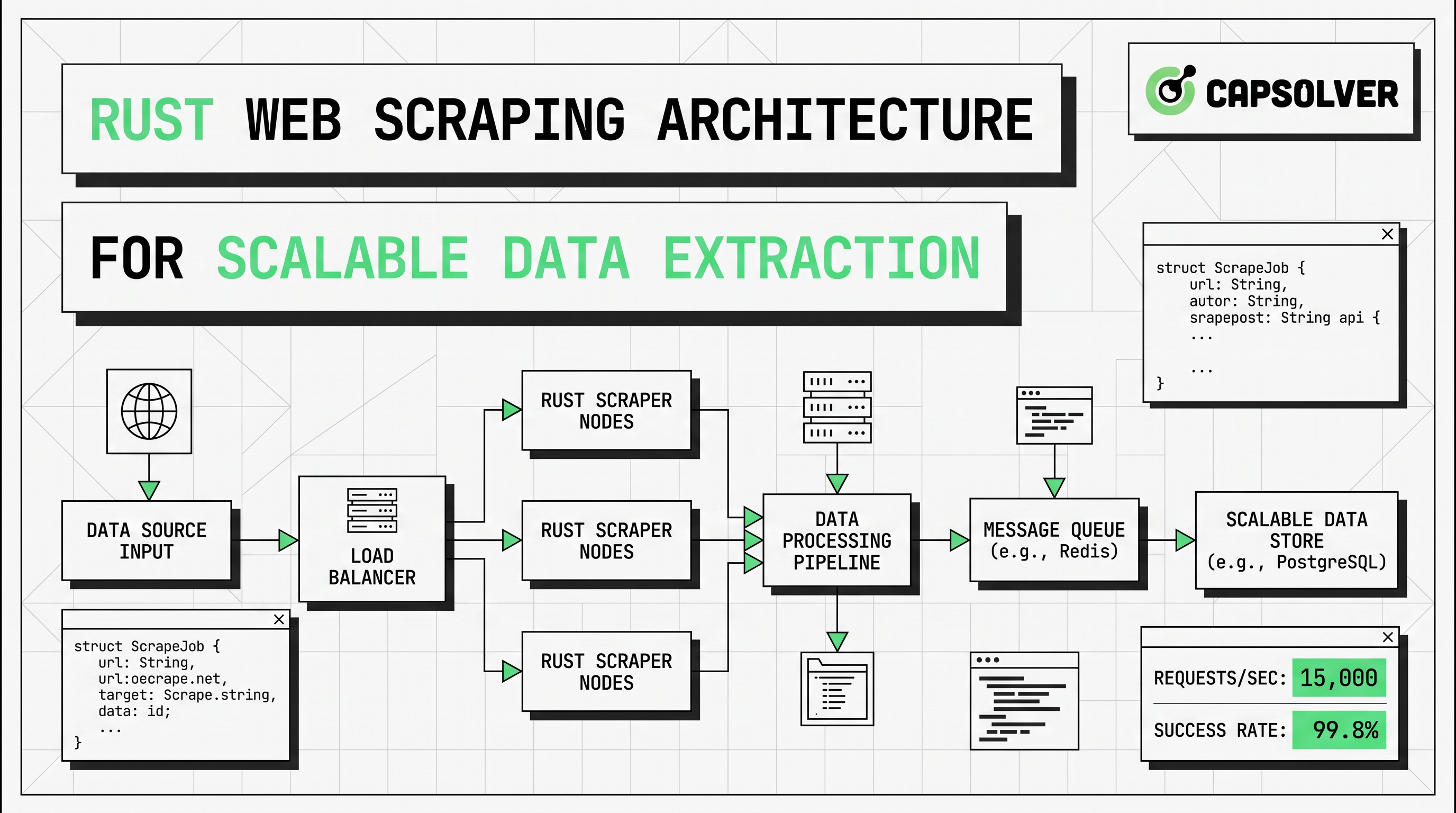
生产设计通常需要一个HTTP获取层、一个解析层、一个JavaScript页面的渲染分支、一个存储层,以及一个用于重试、指标和请求节奏的运营层。正确的顺序也很重要。首先从最廉价的路径开始。获取原始HTML。仅解析您需要的字段。仅当服务器HTML中不包含目标数据时,才升级到无头浏览器爬虫。仅当需要流量分布或区域访问时才添加代理轮换。仅当合规自动化流程有正当理由继续时才添加验证码处理。
对于计划这些边界的团队,网络爬虫和网络爬虫有助于明确范围,如何提取结构化数据是在开始字段映射前有用的内部资料。
Rust爬虫的核心库
Rust网络爬虫通常从三个基础组件开始:reqwest、scraper和Tokio。官方 reqwest文档 将reqwest描述为具有异步支持、cookie、重定向、TLS和代理支持的高级HTTP客户端。这使其成为Rust网络爬虫的实用传输层。
官方 Tokio异步教程 解释了为什么future和执行器模型适合高并发I/O工作负载。这很重要,因为Rust网络爬虫大部分时间都在等待远程服务器,而不是在本地计算上消耗CPU。
使用reqwest进行HTTP请求
reqwest应位于传输层。每个工作进程或工作进程组应复用单个客户端。这可以保持连接池的有效性,并在一个地方定义头部、超时、cookie和代理策略。
rust
use reqwest::Client;
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let client = Client::builder()
.user_agent("Mozilla/5.0")
.build()?;
let html = client
.get("https://example.com")
.send()
.await?
.error_for_status()?
.text()
.await?;
let document = Html::parse_document(&html);
let card = Selector::parse("article")?;
for node in document.select(&card) {
println!("{}", node.text().collect::<Vec<_>>().join(" "));
}
Ok(())
}这种模式使Rust网络爬虫在静态页面上保持高效。它还使错误处理更容易标准化。状态检查、重试预算和结构化日志都可以围绕请求层存在,而不是混入解析器代码中。
使用scraper进行HTML解析
scraper应位于保持小型且可测试的解析层中。如果预期模板会发生变化,不要将选择器与网络逻辑混合。强大的解析器接受原始HTML并返回类型化记录、部分记录或清晰的提取错误。
这种分离很重要,因为选择器漂移很常见。类名会变化。文本会移动到属性中。目标元素之间会出现装饰性节点。在Rust网络爬虫中,解析器隔离会在整个流水线开始写入不完整数据之前使这些断开在测试中可见。
异步爬虫架构
异步爬虫是Rust网络爬虫在中等基础设施上能够良好扩展的主要原因之一。运行时不会让网站响应更快。它让工作者在许多请求等待网络或源响应时更高效。
可扩展的Rust网络爬虫流水线通常遵循以下结构。
| 层 | 角色 | Rust默认 | 主要风险 |
|---|---|---|---|
| 调度器 | 选择URL和优先级 | 队列或通道 | 突发流量 |
| 获取器 | 发送HTTP请求 | reqwest::Client |
403、429、超时 |
| 解析器 | 提取字段 | scraper选择器 |
模板漂移 |
| 渲染器 | 加载JS页面 | 无头浏览器爬虫 | CPU和内存成本 |
| 验证码层 | 处理允许的验证码事件 | CapSolver备用 | 任务类型错误 |
| 存储 | 写入标准化输出 | JSON、CSV、DB | 模式不匹配 |
| 可观测性 | 跟踪健康和质量 | 日志、追踪、指标 | 静默数据丢失 |
关键设计规则是选择性升级。从低成本路径开始处理每个目标。如果返回的HTML中已包含数据,请继续使用reqwest和scraper。如果目标字段仅在填充后、客户端渲染或浏览器事件后出现,请将该页面类型路由到无头浏览器爬虫。如果在批准的工作流中出现机器人保护或验证码检查,请将这些事件路由到狭窄的备用分支,而不是逐一修补。
这就是许多系统变得浪费的地方。团队默认对每个请求使用浏览器自动化。这会增加成本,降低并发性,并使失败更难分类。HTTP档案库JavaScript现状报告显示,现代页面仍然严重依赖JavaScript,所选报告视图中桌面页面的JavaScript传输中位数为803.3 KB,包含23个外部脚本请求。这解释了为什么某些目标需要渲染,但不意味着为每页使用浏览器。
处理JavaScript渲染的页面
当数据在初始HTML响应后生成时,无头浏览器爬虫是必要的。常见信号包括空的服务器HTML、填充后注入的内容、无限滚动列表,或只有在用户交互后才显示字段的页面。
Rust网络爬虫应将浏览器渲染视为独立分支,而不是通用基线。用于在客户端请求后填充的产品网格、浏览器渲染的仪表板,或关键内容被点击和滚动逻辑隐藏的界面。保持浏览器池小,并将其与主要异步HTTP工作者隔离。
一个实用的决策规则很简单。如果数据存在于原始HTML中,请继续使用reqwest和scraper。如果字段仅在JavaScript执行后出现,请将该路径转移到无头浏览器爬虫。如果同一目标也应用了机器人保护控制,请一起审查网络策略、浏览器行为和备用需求,而不是逐一修补。
相关内部阅读资料:开发者浏览器自动化 和 在无头浏览器中自动化验证码解决 自然地融入这种分层模型。
验证码和爬虫限制
Rust网络爬虫始终有其限制。有些是技术性的,有些是法律或操作性的。技术方面包括IP声誉、会话处理、浏览器指纹检查、隐藏API和分层机器人保护。操作方面包括请求节奏、错误预算和对目标网站的流量影响。
这就是为什么合规性必须构建到架构中。Google搜索中心robots.txt指南解释了robots.txt主要用于管理爬虫流量并避免过度负载网站。这一点对Rust网络爬虫很重要,因为设计良好的系统不仅试图提取数据,还试图控制负载、减少不必要的请求并保持收集行为合理。
当合法自动化流程遇到验证码步骤时,CapSolver 作为聚焦的备用服务是相关的。最安全的方法是遵循官方文档,而不是自定义请求格式。CapSolver createTask文档 显示了标准请求体模式如下。
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey":"YOUR_API_KEY",
"appId": "APP_ID",
"task": {
"type":"ImageToTextTask",
"body":"BASE64图片"
}
}相同的官方流程返回taskId用于异步任务,然后应通过getTaskResult检查。在可扩展的Rust网络爬虫系统中,该挑战逻辑应保持在标准获取和解析路径之外,以使正常请求保持快速且易于监控。
领取您的CapSolver优惠码
立即提升您的自动化预算!
在充值CapSolver账户时使用优惠码CAP26,每次充值可获得额外5%的奖励——无限制。
现在在您的CapSolver仪表板
为大规模数据收集扩展Rust爬虫
扩展Rust爬虫主要是关于控制,而不是代码量。架构应强制实施按域名的并发控制、重试上限、超时预算和输出验证。没有这些控制,更快的工作者只会导致更快的失败。
代理轮换应位于传输层而非解析层。当请求需要跨IP地址分布以实现速率平衡、区域访问或工作负载隔离时使用它。保持策略具体。按域名、端点类别或工作负载类型轮换。避免随机代理更换,这会破坏会话连续性并增加调试噪音。
这也是内部支持资源变得有用的地方。最佳代理服务 可帮助评估网络策略,而 网络爬虫法律 是在扩展收集量之前有用的内部检查点。
最强的Rust网络爬虫系统还会直接测量提取质量。跟踪成功率、空字段率、选择器漂移、渲染比例、中位获取延迟和每个成功记录的成本。这些指标显示简单HTML路径是否仍然足够,以及无头浏览器爬虫、代理轮换或挑战处理是否变得过于昂贵。
对比总结
| 方法 | 最佳使用场景 | 成本概况 | 可靠性概况 | 说明 |
|---|---|---|---|---|
reqwest + scraper |
静态或轻度动态页面 | 低 | 选择器稳定时可靠性高 | Rust网络爬虫的最佳默认方法 |
| 使用Tokio工作者的异步爬虫 | 多个I/O密集型URL | 低到中 | 有速率限制时可靠性高 | 提升吞吐量,不影响解析器质量 |
| 无头浏览器爬虫 | JavaScript渲染的页面 | 高 | 中 | 在小型池中隔离它 |
| 代理轮换 | 分布式速率控制和地理访问 | 中 | 中 | 当流量身份重要时有用 |
| CapSolver备用 | 自动化流程中的允许验证码事件 | 按事件计费 | 中到高 | 保持实现与官方文档一致 |
结论
当架构保持选择性时,Rust网络爬虫可以扩展。使用reqwest和scraper作为快速路径。当需要更多吞吐量时添加异步爬虫。将无头浏览器爬虫保留给真正需要渲染的页面。将代理轮换和挑战处理作为受控的备用层。这种设计可降低成本、提高可观测性,并使解析器维护更容易。
如果当前流水线将每页都通过浏览器处理,最干净的改进通常是路径拆分。将静态目标移回简单HTTP。将JavaScript页面保留在较小的渲染分支中。将挑战逻辑隔离。这种更改通常能同时提升可靠性和单位经济性。
FAQ
Rust网络爬虫在大型任务中是否优于Python?
Rust网络爬虫在长时间运行的稳定性、并发性和内存安全最为重要时通常是强项选择。Python仍有更广泛的爬虫生态系统,但当工作者效率和可预测性能是主要优先事项时,Rust更具吸引力。
何时应从reqwest切换到无头浏览器爬虫?
仅当服务器HTML中不包含所需字段时才切换。如果目标数据在填充后、客户端事件或延迟API请求后出现,无头浏览器爬虫就变得合理。
异步爬虫如何帮助Rust?
异步爬虫帮助Rust网络爬虫用更少的浪费资源处理大量等待请求。它提升I/O密集型任务的吞吐量,但仍需要速率限制、重试逻辑和解析器测试。
我是否总是需要代理轮换?
不,许多任务在没有它的情况下也能很好地运行。当需要区域访问、按域名的流量分配或降低来自单一IP范围的集中度时,代理轮换才显得重要。
在合规的工作流程中应该如何处理验证码页面?
保持验证码处理范围有限、文档记录明确,并与正常获取路径分开。如果合法的自动化工作流程需要处理验证码,请使用官方的CapSolver任务流程,并确保实现与已发布的文档一致。


