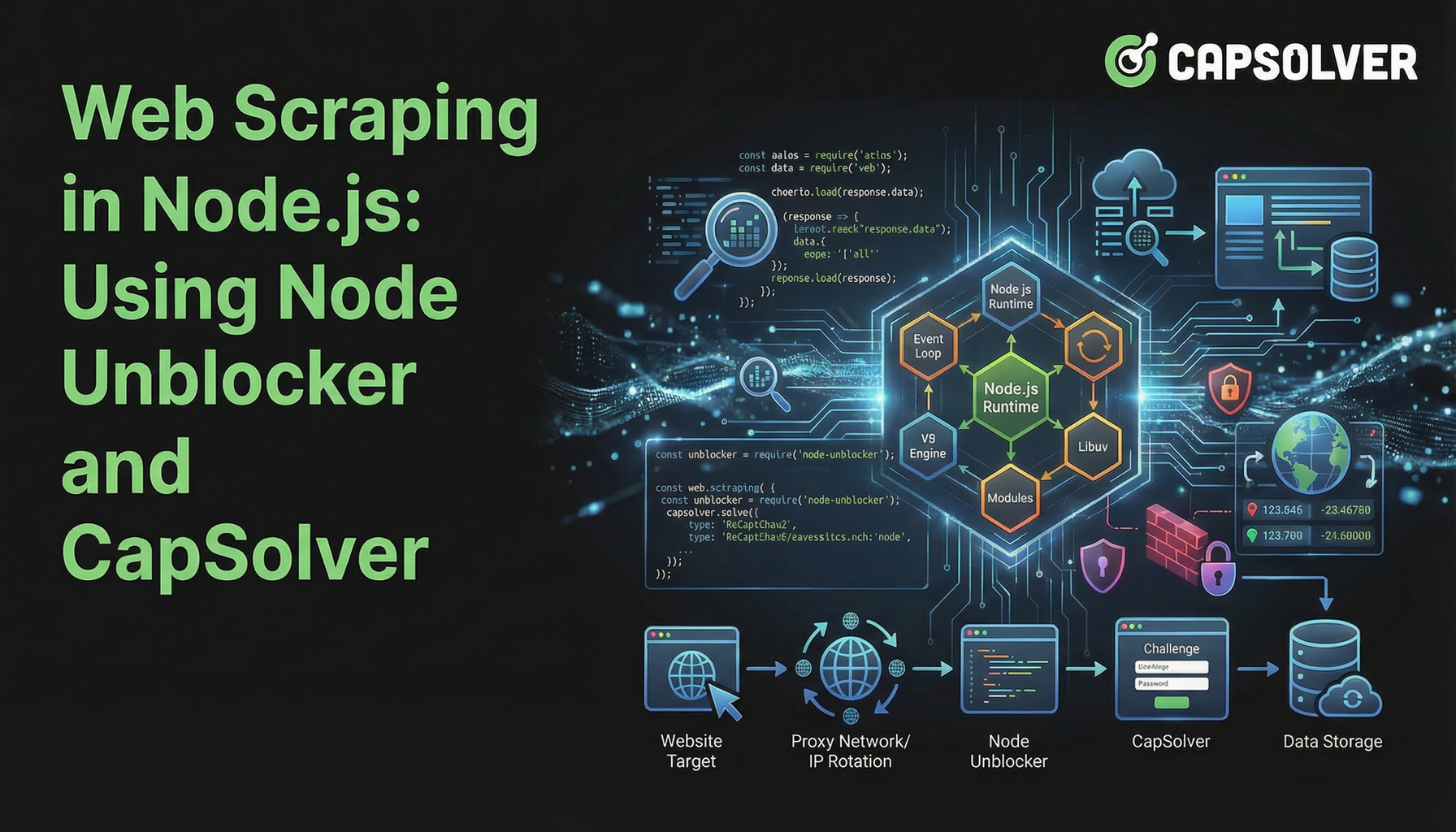
Thu thập dữ liệu web trong Node.js: Sử dụng Node Unblocker và CapSolver

Sora Fujimoto
AI Solutions Architect
TL;Dr
- Web scraping trong Node.js đối mặt với những thách thức ngày càng tăng từ việc phát hiện bot và CAPTCHAs tinh vi.
- Node Unblocker hiệu quả trong việc xử lý các biện pháp chống gian lận cơ bản như chặn IP và hạn chế địa lý bằng cách hoạt động như middleware proxy.
- CapSolver là thiết yếu để vượt qua các thách thức tiên tiến, cụ thể là CAPTCHAs, mà Node Unblocker không thể xử lý riêng lẻ.
- Kết hợp Node Unblocker với CapSolver tạo ra giải pháp web scraping trong Node.js mạnh mẽ và hiệu quả.
- Việc tích hợp đúng cách các công cụ này đảm bảo thu thập dữ liệu đáng tin cậy từ các trang web phức tạp.
Giới thiệu
Web scraping trong Node.js đã trở thành kỹ thuật mạnh mẽ để thu thập dữ liệu, nhưng thường gặp phải những rào cản đáng kể. Các trang web ngày càng triển khai các biện pháp phòng thủ tiên tiến để ngăn chặn truy cập tự động, khiến việc trích xuất dữ liệu thành công trở nên phức tạp. Bài viết này khám phá cách nâng cao các dự án web scraping trong Node.js bằng cách kết hợp Node Unblocker, một middleware proxy linh hoạt, với CapSolver, một dịch vụ giải CAPTCHA chuyên dụng. Chúng tôi sẽ hướng dẫn bạn xây dựng cơ sở hạ tầng gian lận bền bỉ có thể vượt qua các hạn chế phổ biến trên web và đảm bảo luồng dữ liệu ổn định. Hướng dẫn này dành cho các nhà phát triển tìm kiếm các phương pháp hiệu quả và đáng tin cậy cho web scraping trong Node.js trong môi trường trực tuyến ngày nay.
Hiểu bối cảnh của các thách thức web scraping
Các trang web hiện đại sử dụng nhiều kỹ thuật để ngăn chặn các nỗ lực gian lận tự động. Các biện pháp phòng thủ này dao động từ chặn IP đơn giản đến các thách thức tương tác phức tạp. Việc thực hiện web scraping trong Node.js thành công đòi hỏi sự hiểu biết và giải quyết các rào cản này.
Các thách thức phổ biến bao gồm:
- Chặn IP: Các trang web phát hiện và chặn các yêu cầu đến từ các địa chỉ IP đáng ngờ, thường liên quan đến các trung tâm dữ liệu hoặc các hoạt động gian lận đã biết.
- Hạn chế tốc độ: Máy chủ giới hạn số lượng yêu cầu từ một IP trong khoảng thời gian nhất định, dẫn đến việc chặn tạm thời hoặc lỗi.
- Hạn chế địa lý: Sự sẵn có của nội dung thay đổi tùy theo vị trí địa lý, ngăn cản truy cập dữ liệu nhất định từ các khu vực cụ thể.
- CAPTCHAs: Chúng được thiết kế để phân biệt người dùng thực với bot, đưa ra các câu đố trực quan hoặc tương tác mà các script tự động khó giải quyết.
- Nội dung động: Các trang web hiển thị nội dung bằng JavaScript yêu cầu các công cụ gian lận phải thực thi JavaScript, làm tăng độ phức tạp.
- Quản lý phiên làm việc: Việc duy trì trạng thái phiên và xử lý cookie chính xác là điều cần thiết để duyệt các phần được xác thực của trang web.
Những thách thức này nhấn mạnh nhu cầu về các công cụ phức tạp hơn các thư viện yêu cầu HTTP cơ bản khi tham gia vào web scraping nghiêm túc trong Node.js.
Node Unblocker: Nền tảng cho việc gian lận bền bỉ
Node Unblocker là một middleware Node.js mã nguồn mở được thiết kế để hỗ trợ web scraping trong Node.js bằng cách vượt qua các hạn chế web phổ biến. Nó hoạt động như một proxy, định tuyến các yêu cầu của bạn qua một máy chủ trung gian, từ đó che giấu địa chỉ IP ban đầu của bạn và có thể vượt qua các hạn chế địa lý. Sức mạnh chính của nó nằm ở khả năng thay đổi tiêu đề yêu cầu và phản hồi, xử lý cookie và quản lý phiên, làm cho nó trở thành tài sản quý giá cho lớp bảo vệ ban đầu.
Ưu điểm chính của Node Unblocker:
- Ẩn địa chỉ IP: Định tuyến lưu lượng qua proxy, che giấu địa chỉ IP thực của công cụ gian lận. Điều này giúp tránh bị chặn IP.
- Vượt qua hạn chế địa lý: Bằng cách sử dụng các proxy ở các khu vực khác nhau, bạn có thể truy cập nội dung bị hạn chế về mặt địa lý.
- Quản lý tiêu đề: Cho phép thay đổi dễ dàng các tiêu đề HTTP, chẳng hạn như User-Agent, Referer và Accept-Language, để mô phỏng các yêu cầu từ trình duyệt hợp lệ.
- Xử lý cookie: Tự động quản lý cookie, điều này rất quan trọng để duy trì trạng thái phiên qua nhiều yêu cầu.
- Tích hợp middleware: Được thiết kế để tích hợp mượt mà với các khung công tác Node.js phổ biến như Express.js, đơn giản hóa việc cài đặt và sử dụng.
- Linh hoạt mã nguồn mở: Là mã nguồn mở, nó cung cấp kiểm soát đầy đủ và tùy chỉnh cho các nhà phát triển để điều chỉnh nó theo nhu cầu gian lận cụ thể.
Cài đặt Node Unblocker cho web scraping trong Node.js
Việc tích hợp Node Unblocker vào dự án web scraping trong Node.js của bạn là khá đơn giản. Trước tiên, hãy đảm bảo bạn đã cài đặt Node.js và npm. Sau đó, bạn có thể cài đặt Node Unblocker và Express.js:
bash
npm init -y
npm install express unblockerTiếp theo, tạo tệp index.js và cấu hình Node Unblocker như middleware:
javascript
const express = require("express");
const Unblocker = require("unblocker");
const app = express();
const unblocker = new Unblocker({ prefix: "/proxy/" });
app.use(unblocker);
const port = 3000;
app.listen(port).on("upgrade", unblocker.onUpgrade);
console.log(`Proxy đang chạy trên http://localhost:${port}/proxy/`);Cài đặt cơ bản này tạo ra một máy chủ proxy cục bộ. Bạn có thể định tuyến các yêu cầu gian lận của mình qua http://localhost:3000/proxy/ theo sau là URL đích. Để cấu hình chi tiết hơn, hãy tham khảo kho lưu trữ GitHub của Node Unblocker.
Mảnh ghép còn thiếu: Giải CAPTCHAs với CapSolver
Mặc dù Node Unblocker xuất sắc trong việc xử lý các hạn chế cấp mạng, nhưng nó không giải quyết các thách thức như CAPTCHAs. Những câu đố trực quan hoặc tương tác này được thiết kế đặc biệt để phân biệt người dùng thực với bot. Khi web scraping trong Node.js của bạn gặp phải CAPTCHA, quy trình gian lận sẽ dừng lại.
Đây là lúc CapSolver trở thành công cụ không thể thiếu. CapSolver là một dịch vụ giải CAPTCHA chuyên dụng cung cấp API để giải các loại CAPTCHA một cách chương trình, bao gồm reCAPTCHA v2, reCAPTCHA v3 và Cloudflare Turnstile. Việc tích hợp CapSolver vào quy trình gian lận trong Node.js của bạn cho phép công cụ gian lận của bạn tự động vượt qua các bước xác minh người dùng, đảm bảo việc thu thập dữ liệu không bị gián đoạn.
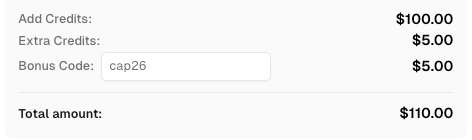
Sử dụng mã
CAP26khi đăng ký tại CapSolver để nhận thêm tín dụng!
Cách CapSolver nâng cao web scraping trong Node.js:
- Giải CAPTCHA tự động: Giải các CAPTCHA phức tạp mà không cần can thiệp thủ công.
- Hỗ trợ rộng rãi CAPTCHA: Xử lý nhiều loại CAPTCHA, cung cấp giải pháp toàn diện.
- Tích hợp API: Cung cấp API đơn giản để tích hợp dễ dàng vào các dự án Node.js hiện có.
- Tin cậy: Cung cấp tỷ lệ thành công cao trong việc giải CAPTCHA, giảm thiểu gián đoạn.
- Tốc độ: Cung cấp giải pháp CAPTCHA nhanh, duy trì hiệu quả của các hoạt động gian lận của bạn.
Tích hợp CapSolver vào trình gian lận Node.js của bạn
Để tích hợp CapSolver, bạn thường sẽ thực hiện một cuộc gọi API đến CapSolver mỗi khi phát hiện CAPTCHA. Quy trình bao gồm việc gửi chi tiết CAPTCHA đến CapSolver, nhận giải pháp và sau đó gửi lại giải pháp đó cho trang web đích. Điều này có thể được thực hiện bằng cách sử dụng trình khách HTTP như Axios trong ứng dụng Node.js của bạn.
Ví dụ, sau khi thiết lập máy chủ proxy Node Unblocker, logic gian lận của bạn sẽ bao gồm việc kiểm tra CAPTCHA. Nếu phát hiện CAPTCHA, bạn sẽ khởi động cuộc gọi đến CapSolver. Bạn có thể tìm thấy các ví dụ chi tiết và tài liệu hướng dẫn cách tích hợp CapSolver cho các loại CAPTCHA khác nhau trong các bài viết của chúng tôi, chẳng hạn như Cách giải reCAPTCHA với Node.js và Cách giải CAPTCHA Cloudflare Turnstile với NodeJS.
So sánh: Node Unblocker riêng lẻ vs. Node Unblocker + CapSolver
Hiểu rõ vai trò riêng biệt của Node Unblocker và CapSolver là điều cần thiết cho web scraping trong Node.js. Mặc dù Node Unblocker cung cấp khả năng proxy cơ bản, CapSolver giải quyết một thách thức cụ thể, tiên tiến.
| Tính năng/Công cụ | Node Unblocker riêng lẻ | Node Unblocker + CapSolver |
|---|---|---|
| Ẩn địa chỉ IP | Có | Có |
| Vượt qua hạn chế địa lý | Có | Có |
| Quản lý tiêu đề/cookie | Có | Có |
| Giải CAPTCHA | Không | Có |
| Phát hiện bot (cơ bản) | Một phần (thông qua thay đổi IP/tiêu đề) | Nâng cao (giải CAPTCHA, giảm điểm bot) |
| Độ phức tạp của việc cài đặt | Trung bình | Trung bình đến cao (yêu cầu tích hợp API CapSolver) |
| Chi phí | Miễn phí (mã nguồn mở) | Miễn phí (mã nguồn mở) + phí dịch vụ CapSolver |
| Tin cậy cho các trang web phức tạp | Giới hạn | Cao |
| Trường hợp sử dụng lý tưởng | Các trang web đơn giản, thu thập dữ liệu cơ bản, kiểm tra ban đầu | Các trang web phức tạp có CAPTCHA, trích xuất dữ liệu quy mô lớn, môi trường sản xuất |
So sánh này rõ ràng cho thấy rằng để gian lận web trong Node.js mạnh mẽ chống lại các biện pháp phòng thủ web hiện đại, cách tiếp cận kết hợp là tốt hơn. Node Unblocker xử lý định tuyến và tránh cơ bản, trong khi CapSolver cung cấp trí tuệ để vượt qua CAPTCHA.
Chiến lược nâng cao cho web scraping trong Node.js
Ngoài việc sử dụng Node Unblocker và CapSolver, một số chiến lược nâng cao có thể làm tăng hiệu quả hơn nữa các dự án web scraping trong Node.js của bạn. Các kỹ thuật này tập trung vào việc mô phỏng hành vi con người và quản lý tài nguyên hiệu quả.
- Quay vòng User-Agent: Thay đổi định kỳ tiêu đề User-Agent giúp tránh bị phát hiện. Một bộ sưu tập đa dạng của User-Agent khiến các yêu cầu của bạn dường như đến từ các trình duyệt và thiết bị khác nhau. Học thêm về cách quản lý User-Agent trong bài viết của chúng tôi về User-Agent tốt nhất.
- Khoảng thời gian và ngẫu nhiên yêu cầu: Thêm khoảng thời gian ngẫu nhiên giữa các yêu cầu ngăn chặn việc chạm vào giới hạn tốc độ. Mẫu lướt web của con người hiếm khi nhất quán hoàn toàn.
- Trình duyệt không đầu: Đối với các trang web phụ thuộc nhiều vào JavaScript, sử dụng trình duyệt không đầu như Puppeteer hoặc Playwright là điều cần thiết. Các công cụ này có thể thực thi JavaScript và hiển thị trang giống như trình duyệt thực sự. Bạn có thể tích hợp CapSolver với các công cụ này; xem hướng dẫn của chúng tôi về Cách tích hợp Puppeteer và Cách tích hợp Playwright.
- Quay vòng proxy: Trong khi Node Unblocker cung cấp lớp proxy đơn, quay vòng qua một nhóm các proxy khác nhau (dân cư, di động) có thể giảm đáng kể khả năng bị chặn IP. Điều này đặc biệt quan trọng cho các hoạt động gian lận web trong Node.js quy mô lớn.
- Xử lý lỗi và thử lại: Triển khai xử lý lỗi mạnh mẽ với cơ chế thử lại cho các yêu cầu thất bại. Điều này làm cho công cụ gian lận của bạn trở nên bền bỉ hơn trước các vấn đề mạng tạm thời hoặc các khối mềm.
Kết hợp các chiến lược này với Node Unblocker và CapSolver, bạn xây dựng được một giải pháp gian lận web trong Node.js rất phức tạp và hiệu quả. Đối với các mẹo chung về việc tránh bị phát hiện, tham khảo bài viết của chúng tôi về Tránh bị cấm IP.
Kết luận
Việc gian lận web trong Node.js vào năm 2026 đòi hỏi một cách tiếp cận đa mặt để vượt qua các biện pháp phòng thủ ngày càng phức tạp. Node Unblocker cung cấp nền tảng mã nguồn mở mạnh mẽ để quản lý kết nối proxy, ẩn địa chỉ IP và xử lý các chi tiết HTTP cơ bản. Tuy nhiên, để vượt qua các chướng ngại vật khó khăn nhất, đặc biệt là CAPTCHA, một dịch vụ chuyên dụng như CapSolver là không thể thiếu. Sự kết hợp giữa Node Unblocker và CapSolver tạo ra cơ sở hạ tầng gian lận mạnh mẽ và đáng tin cậy, cho phép các nhà phát triển trích xuất dữ liệu một cách nhất quán và hiệu quả.
Bằng cách tích hợp các công cụ này và áp dụng các chiến lược gian lận nâng cao, bạn có thể xây dựng các ứng dụng gian lận web trong Node.js bền bỉ có thể chống lại các cơ chế phát hiện bot hiện đại. Trang bị các công cụ phù hợp cho các dự án của bạn để đảm bảo các nỗ lực thu thập dữ liệu của bạn thành công và bền vững.
Câu hỏi thường gặp (FAQ)
Câu hỏi: Node Unblocker được sử dụng để làm gì trong web scraping?
Trả lời: Node Unblocker chủ yếu được sử dụng như middleware proxy trong web scraping trong Node.js để ẩn địa chỉ IP của công cụ gian lận, vượt qua các hạn chế địa lý và quản lý tiêu đề HTTP và cookie. Nó giúp vượt qua các biện pháp chống gian lận cơ bản và khiến các yêu cầu dường như hợp lệ.
Câu hỏi: Node Unblocker có thể giải CAPTCHAs không?
Trả lời: Không, Node Unblocker bản thân nó không thể giải CAPTCHAs. Chức năng của nó tập trung vào việc định tuyến mạng và thay đổi yêu cầu. Để giải CAPTCHAs gặp phải trong web scraping trong Node.js, bạn cần tích hợp một dịch vụ giải CAPTCHA chuyên dụng như CapSolver.
Câu hỏi: Tại sao bạn nên sử dụng CapSolver cùng với Node Unblocker?
Trả lời: Bạn nên sử dụng CapSolver cùng với Node Unblocker để tạo ra giải pháp web scraping trong Node.js toàn diện. Node Unblocker xử lý ẩn IP và tránh cơ bản, trong khi CapSolver cung cấp khả năng quan trọng để tự động giải CAPTCHAs, những rào cản phổ biến cho các công cụ gian lận trên các trang web được bảo vệ.
Câu hỏi: Có những lựa chọn thay thế nào cho Node Unblocker trong quản lý proxy không?
Trả lời: Có, có một số lựa chọn thay thế cho quản lý proxy trong web scraping trong Node.js, bao gồm các script quay vòng proxy tùy chỉnh, các dịch vụ proxy thương mại hoặc các thư viện mã nguồn mở khác. Tuy nhiên, Node Unblocker cung cấp cách tiếp cận tiện lợi cho các ứng dụng Express.js.
Câu hỏi: Những yếu tố pháp lý nào cần xem xét cho web scraping?
Trả lời: Các yếu tố pháp lý cho web scraping trong Node.js bao gồm việc tôn trọng các tệp robots.txt, tuân thủ các điều khoản dịch vụ của trang web và tuân thủ các quy định bảo vệ dữ liệu như GDPR hoặc CCPA. Luôn đảm bảo rằng các hoạt động gian lận của bạn là đạo đức và hợp pháp.
Xem thêm
AIMar 27, 2026
Nâng cao Tự động hóa Doanh nghiệp: Cơ sở hạ tầng Dựa trên Mô hình Ngôn ngữ Lớn (LLM) cho Nhận dạng CAPTCHA Mượt mà & Hiệu quả Hoạt động
Khám phá cách cơ sở hạ tầng tự động hóa AI được cung cấp bởi Mô hình Ngôn ngữ lớn (LLM) đột phá trong việc nhận diện CAPTCHA, nâng cao hiệu quả quy trình kinh doanh và giảm thiểu sự can thiệp thủ công. Tối ưu hóa các quy trình tự động của bạn với các giải pháp xác minh tiên tiến.

AIMar 27, 2026
Mở rộng thu thập dữ liệu cho huấn luyện LLM: Giải quyết CAPTCHAs ở quy mô lớn
Hãy học cách mở rộng thu thập dữ liệu cho việc huấn luyện mô hình LLM bằng cách giải CAPTCHAs quy mô lớn. Khám phá các chiến lược tự động để xây dựng các bộ dữ liệu chất lượng cao cho các mô hình AI.
