パペットイアとは?ウェブスクラビングにおける使い方|完全ガイド 2026

Anh Tuan
Data Science Expert

ウェブスクレイピングは、ウェブからデータを抽出する誰にとっても重要なスキルとなっています。開発者、データサイエンティスト、またはウェブサイトから情報を収集したいエンジニアであれば、Puppeteerは利用可能な最も強力なツールの一つです。この完全なガイドでは、Puppeteerとは何か、そしてウェブスクレイピングでどのように効果的に使用するかについて詳しく説明します。
Puppeteerの紹介
Puppeteerは、DevToolsプロトコルを介してChromeまたはChromiumを制御するためのNodeライブラリです。Google Chromeチームによってメンテナンスされており、開発者にスクリーンショットの生成、ウェブサイトのスクレイピング、そして最も重要であるウェブスクレイピングなどのさまざまなブラウザタスクを実行する能力を提供します。ヘッドレスブラウジングの機能により、グラフィカルユーザーインターフェースなしで動作できるため、自動化タスクに最適で、非常に人気があります。
CapSolverボーナスコードを取得する
オートメーション予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAPN を使用すると、毎回チャージに対して5%のボーナスを獲得できます — 制限なし。
CapSolverダッシュボードで今すぐ取得してください
.
なぜPuppeteerをウェブスクレイピングに使うのか?
AxiosとCheerioはJavaScriptのウェブスクレイピングに良い選択肢ですが、制限があります:動的コンテンツの処理や、スクレイピング防止メカニズムの回避です。
ヘッドレスブラウザとして、Puppeteerは動的コンテンツのスクレイピングに優れています。ターゲットページを完全に読み込み、JavaScriptを実行し、XHRリクエストをトリガーして追加のデータを取得することもできます。これは静的スクレイパーでは達成できないことで、特に初期HTMLに重要なデータが含まれていないシングルページアプリケーション(SPAs)において特にそうです。
Puppeteerは何ができるでしょうか?画像のレンダリング、スクリーンショットのキャプチャ、さまざまなキャプチャを解決する拡張機能(例: reCAPTCHA、キャプチャ)などがあります。例えば、スクリプトをプログラムしてページを移動し、特定のタイミングでスクリーンショットを撮り、それらの画像を分析して競争上の洞察を得ることができます。可能性はほぼ無限です!
Puppeteerの簡単な使い方
以前、ScrapingClubの第一部分をSeleniumとPythonを使用して完了しました。今度はPuppeteerを使って第二部分を完了しましょう。
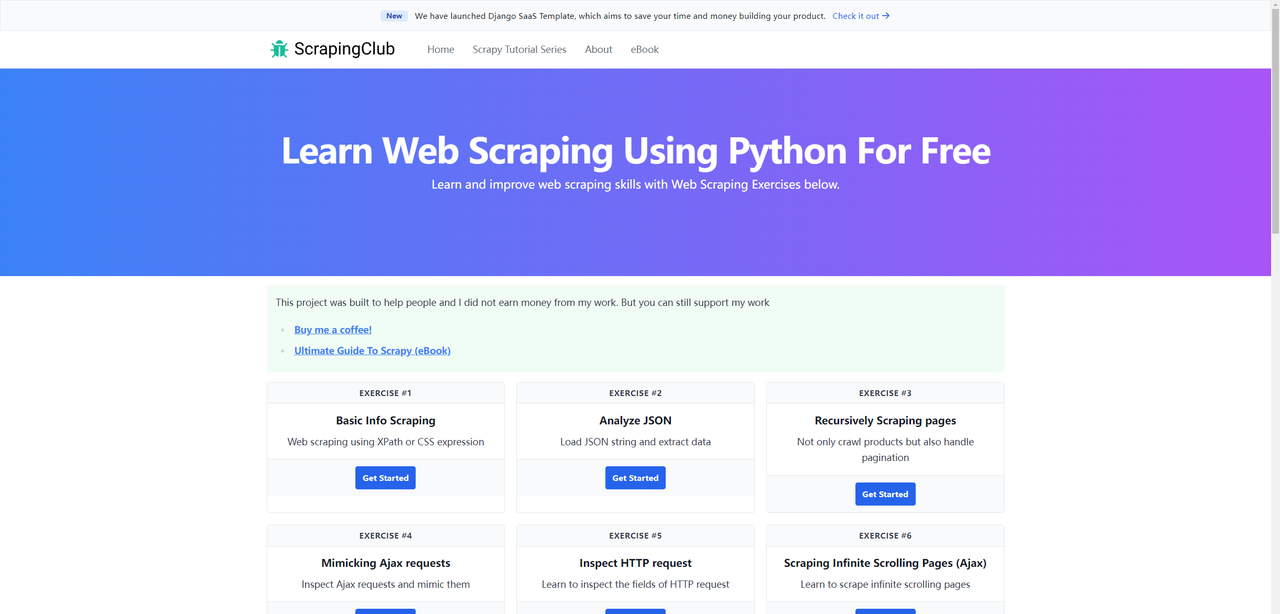
開始する前に、ローカルマシンにPuppeteerがインストールされていることを確認してください。まだインストールしていない場合は、以下のコマンドを使用してください:
bash
npm i puppeteer # インストール時に互換性のあるChromeをダウンロードします。
npm i puppeteer-core # 代わりにライブラリとしてインストールし、Chromeをダウンロードしないこともできます。ページにアクセスする
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// 5秒間停止
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();puppeteer.launchメソッドは、新しいPuppeteerインスタンスを起動するために使用され、複数のオプションを含む構成オブジェクトを受け取ることができます。最も一般的なのはheadlessで、ブラウザをヘッドレスモードで実行するかどうかを指定します。このパラメータを指定しない場合、デフォルトはtrueになります。他の一般的な構成オプションは以下の通りです:
| パラメータ | タイプ | デフォルト値 | 説明 | 例 |
|---|---|---|---|---|
args |
string[] |
ブラウザを起動するときに渡すコマンドライン引数の配列 | args: ['--no-sandbox', '--disable-setuid-sandbox'] |
|
debuggingPort |
number |
使用するデバッグポート番号を指定します | debuggingPort: 8888 |
|
defaultViewport |
dict |
{width: 800, height: 600} |
デフォルトのビューポートサイズを設定します | defaultViewport: {width: 1920, height: 1080} |
devtools |
boolean |
false |
DevToolsを自動的に開くかどうか | devtools: true |
executablePath |
string |
ブラウザの実行ファイルのパスを指定します | executablePath: '/path/to/chrome' |
|
headless |
boolean or 'shell' |
true |
ブラウザをヘッドレスモードで実行するかどうか | headless: false |
userDataDir |
string |
ユーザーデータディレクトリのパスを指定します | userDataDir: '/path/to/user/data' |
|
timeout |
number |
30000 |
ブラウザが起動するまで待つタイムアウト(ミリ秒) | timeout: 60000 |
ignoreHTTPSErrors |
boolean |
false |
HTTPSエラーを無視するかどうか | ignoreHTTPSErrors: true |
ウィンドウサイズの設定
最適なブラウジング体験を得るために、ビューポートサイズとブラウザウィンドウサイズの2つのパラメータを調整する必要があります。コードは以下の通りです:
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({
headless: false,
args: ['--window-size=1920,1080']
});
const page = await browser.newPage();
await page.setViewport({width: 1920, height: 1080});
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// 5秒間停止
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();データの抽出
Puppeteerでは、データを抽出するためのさまざまな方法があります。
-
evaluateメソッドの使用evaluateメソッドは、ブラウザコンテキストでJavaScriptコードを実行して必要なデータを抽出します。javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.evaluate(() => { const image = document.querySelector('.card-img-top').src; const title = document.querySelector('.card-title').innerText; const price = document.querySelector('.card-price').innerText; const description = document.querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('製品名:', data.title); console.log('製品価格:', data.price); console.log('製品画像:', data.image); console.log('製品説明:', data.description); // 5秒間停止 await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
$evalメソッドの使用$evalメソッドは、単一の要素を選択し、そのコンテンツを抽出します。javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const title = await page.$eval('.card-title', el => el.innerText); const price = await page.$eval('.card-price', el => el.innerText); const image = await page.$eval('.card-img-top', el => el.src); const description = await page.$eval('.card-description', el => el.innerText); console.log('製品名:', title); console.log('製品価格:', price); console.log('製品画像:', image); console.log('製品説明:', description); // 5秒間停止 await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
$$evalメソッドの使用$$evalメソッドは、一度に複数の要素を選択し、それらのコンテンツを抽出します。javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.$$eval('.my-8.w-full.rounded.border > *', elements => { const image = elements[0].querySelector('img').src; const title = elements[1].querySelector('.card-title').innerText; const price = elements[1].querySelector('.card-price').innerText; const description = elements[1].querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('製品名:', data.title); console.log('製品価格:', data.price); console.log('製品画像:', data.image); console.log('製品説明:', data.description); // 5秒間停止 await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
page.$とevaluateメソッドの使用page.$メソッドは要素を選択し、evaluateメソッドはブラウザコンテキストでJavaScriptコードを実行してデータを抽出します。javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const imageElement = await page.$('.card-img-top'); const titleElement = await page.$('.card-title'); const priceElement = await page.$('.card-price'); const descriptionElement = await page.$('.card-description'); const image = await page.evaluate(el => el.src, imageElement); const title = await page.evaluate(el => el.innerText, titleElement); const price = await page.evaluate(el => el.innerText, priceElement); const description = await page.evaluate(el => el.innerText, descriptionElement); console.log('製品名:', title); console.log('製品価格:', price); console.log('製品画像:', image); console.log('製品説明:', description); // 5秒間停止 await new Promise(r => setTimeout(r, 5000)); await browser.close(); })();
ウェブスクレイピング防止技術を回避する
ScrapingClubの演習を完了するのは比較的簡単です。しかし、現実世界のデータスクレイピングのシナリオでは、データを取得することが常に簡単ではありません。一部のウェブサイトでは、スクレイピングスクリプトをボットとして検出し、ブロックするようなウェブスクレイピング防止技術を使用しています。最も一般的な状況は、キャプチャ、キャプチャ、reCAPTCHA、キャプチャ、キャプチャなどのキャプチャチャレンジです。
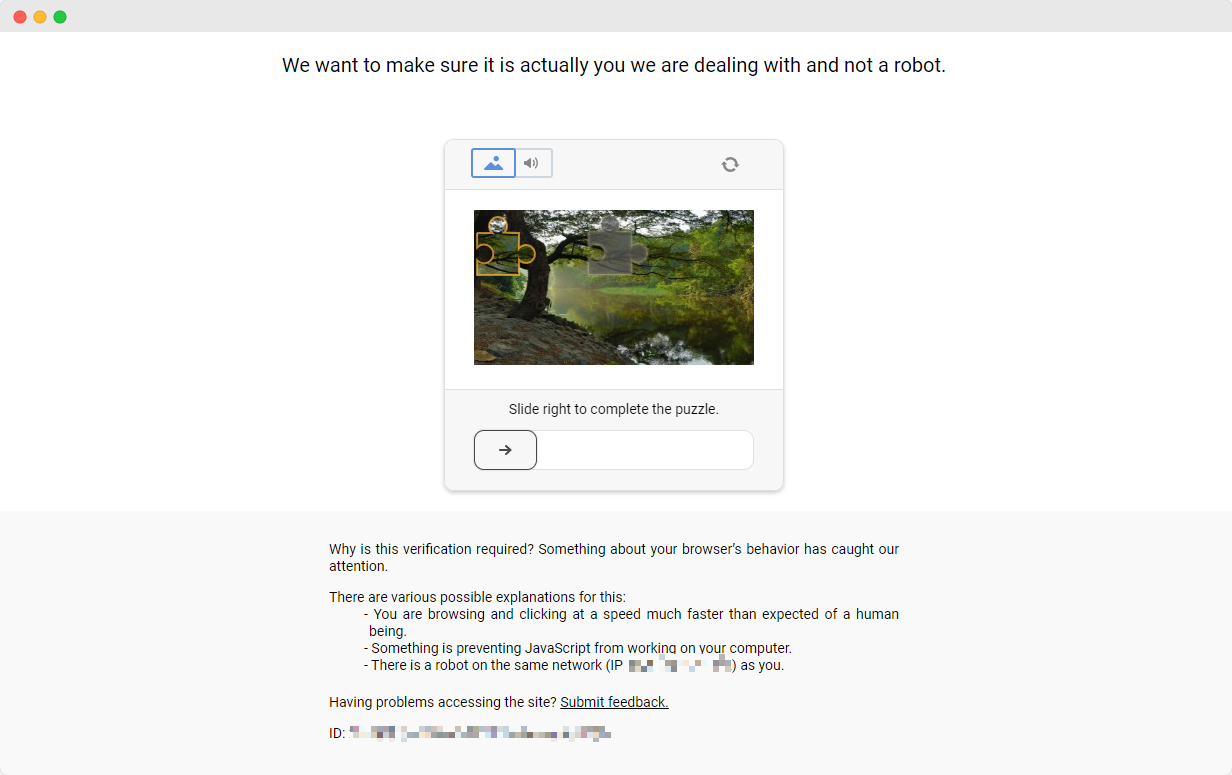
これらのキャプチャチャレンジを解決するには、機械学習、逆エンジニアリング、ブラウザのファINGERプリント対策などの幅広い経験が必要で、時間がかかります。
幸いなことに、あなた自身ですべての作業を行う必要はもうありません。CapSolverは、すべての課題を簡単に解決する包括的なソリューションを提供しています。CapSolverは、Puppeteerを使用してデータスクレイピングを行う際に、自動的にキャプチャチャレンジを解決するブラウザ拡張機能を提供しています。さらに、APIメソッドを使用してキャプチャを解決し、トークンを取得することもできます。すべては数秒で行えます。このドキュメントをチェックして、遭遇したさまざまなキャプチャ対応方法について確認してください!
結論
ウェブスクレイピングは、ウェブデータ抽出に関与する誰にとっても価値あるスキルであり、高度なAPIと強力な機能を持つツールとしてのPuppeteerは、この目標を達成するための最良の選択肢の一つです。動的コンテンツを処理し、スクレイピング防止メカニズムを解決する能力により、スクレイピングツールの中で際立っています。
このガイドでは、Puppeteerとは何か、ウェブスクレイピングにおけるその利点、および効果的に設定および使用する方法について探ります。ウェブページへのアクセス、ビューポートサイズの設定、さまざまな方法でデータを抽出する例を示します。また、キャプチャ技術による課題と、CapSolverがキャプチャチャレンジにどのように対処するかについても説明します。
FAQ
1. Puppeteerはウェブスクレイピングで主に何に使われますか?
Puppeteerは、実際のChrome/Chromiumブラウザを制御し、動的JavaScriptを読み込み、SPAページをレンダリングし、要素と対話し、通常のHTTPベースのスクレイパーではアクセスできないデータを抽出するのに使用されます。
2. Puppeteerはウェブサイトのキャプチャチャレンジを処理できますか?
Puppeteer単体ではキャプチャを回避することはできませんが、CapSolverのブラウザ拡張機能またはAPIと組み合わせることで、スクレイピングタスク中にreCAPTCHA、hCaptcha、FunCAPTCHAなどの検証チャレンジを自動的に解決できます。
3. Puppeteerは可視ブラウザウィンドウで実行する必要がありますか?
いいえ。Puppeteerはヘッドレスモードをサポートしており、GUIなしでChromeを実行できます。このモードは高速で、自動化に最適です。デバッグや視覚的なモニタリングのために非ヘッドレスモードで実行することもできます。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。

Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
