スクレイピングボットとは何か、そしてどのように構築するか

Emma Foster
Machine Learning Engineer

TL;Dr: スクリーピングボットを構築するための重要なポイント
- スクリーピングボットは、スケールに応じて構造化されたデータを抽出する高度な自動化されたプログラムであり、単一ページのスクリプトとは異なります。
- 現代のボットは、JavaScriptや動的コンテンツを効果的に処理するために、PlaywrightやScrapy-Playwrightなどの高度なツールを必要とします。
- セキュリティ対策(レート制限、CAPTCHA、ファーザープリンティング)が最大の課題です。これに打ち勝つには、プロキシ、リクエストのスローティング、専門的なCAPTCHA解決サービスが必要です。
- 倫理的および法的遵守は不可欠です。常に
robots.txtとサイトの利用規約を尊重し、法的問題を避けてください。 - 2026年の差別化の鍵は、AI/LLMを統合してよりスマートなデータ解析を行うことと、継続的で大規模な運用に耐える堅牢なクラウドベースのインフラを構築することです。
はじめに
データは現代のビジネスの生命線であり、効率的なデータ収集の能力が競争優位性を決定します。このガイドでは、スクリーピングボットとは何か、そして2026年の現代のウェブ標準に適合した堅牢でスケーラブルなスクリーピングボットの構築方法を詳しく説明します。適切に設計されたスクリーピングボットは、大規模なウェブスクリーピングにおいて不可欠なツールであり、未加工のウェブページを行動可能な構造化データセットに変換します。この包括的なチュートリアルは、開発者、データサイエンティスト、ビジネスアナリスト向けで、インターネットから自動データ抽出をマスターするための知識を提供します。コアの定義やテクノロジースタックから、2026年の成功に必要なセキュリティ対策技術まで、すべてをカバーします。
スクリーピングボットとは何か?
スクリーピングボットは、ウェブサイトをナビゲートし、特定の構造化データを抽出する自律的なソフトウェアアプリケーションです。これらのプログラムは、単純なスクリプトよりも複雑で、継続的に動作し、複雑なウェブサイト構造を処理し、検出を避けるために人間の行動を模倣することがあります。スクリーピングボットのコア機能は、情報の繰り返し収集タスクを自動化することであり、これはあらゆる手動プロセスよりも速く、一貫性のあるデータ収集を可能にします。
コア定義と動作方法
スクリーピングボットは、ターゲットウェブサイトにHTTPリクエストを送信し、HTMLコンテンツを受け取り、そのコンテンツを解析して必要なデータポイントを特定・抽出します。基本的なスクリプトとの主要な違いは、ボットが状態を維持し、セッションを管理し、動的要素と対話できる能力です。
このプロセスは一般的に以下のステップに従います:
- リクエスト: ボットは、通常、ローテーションされるプロキシを使用してURLにリクエストを送信します。
- レンダリング: 現代のJavaScriptを多く使用するサイトでは、ボットはヘッドレスブラウザ(PlaywrightやPuppeteerなど)を使用してページをレンダリングし、必要なクライアントサイドコードを実行します。
- パース: ボットは、ドキュメントオブジェクトモデル(DOM)をナビゲートし、CSSセレクターやXPathを使用してターゲットデータを特定するためにパースライブラリ(BeautifulSoupやlxmlなど)を使用します。
- 抽出: 抽出されたデータは、クリーンアップされ、構造化形式(例:JSON、CSV)に変換されます。
- ストレージ: 最終的なデータは、後続の分析のためにデータベースやファイルシステムに保存されます。
スクリーピングボットの種類
すべてのスクリーピングボットが同じではありません。設計は、ターゲットウェブサイトの複雑さと必要なスケールに大きく依存します。
| ボットタイプ | 説明 | 最適な用途 | 主要技術 |
|---|---|---|---|
| シンプルスクリプト | 単一リクエストを実行し、静的HTMLをパースします。真の「ボット」ではありません。 | JavaScriptのない小さな静的ウェブサイト。 | requests, BeautifulSoup |
| ブラウザ自動化ボット | JavaScriptをレンダリングし、人間の操作をシミュレートするためにヘッドレスブラウザを使用します。 | 動的ウェブサイト、シングルページアプリケーション(SPA)、ログインが必要なサイト。 | Selenium, Puppeteer, Playwright |
| 分散型ボット | 複数のマシンやクラウド関数で動作するボットのネットワークで、中央オーケストレーターによって管理されます。 | 大規模で高ボリュームのウェブスクリーピングプロジェクトで速度が必要な場合。 | Scrapy, Kubernetes, Cloud Functions |
| AI強化ボット | 大規模言語モデル(LLM)を統合して、非構造化データの知的解析や複雑なセキュリティ課題の解決を行います。 | 高度に変化するまたは非構造化されたテキストコンテンツからのデータ抽出。 | LLM APIs, Model Context Protocol (MCP) |
スクリーピングボットの主要統計
スクリーピングボットの使用は、リアルタイムの市場インテリジェンスの需要によって推進される巨大で成長中の業界です。最近の業界報告によると、グローバルウェブスクリーピング市場は2027年までに100億ドルを超えると予測され、年平均成長率(CAGR)は15%以上で成長するとされています グランドビュー・リサーチ:ウェブスクリーピング市場規模、シェア、トレンド分析レポート。さらに、インターネットトラフィックの40%以上が非人間的であり、そのうちの多くは検索エンジンクローラーや商業用スクリーピングボットを含む正当な高度なボットです。このデータは、現代のデータ環境で競争するためには、非常に効果的で耐障害性のあるボットの構築が不可欠であることを示しています。
スクリーピングボットを構築し使用する理由
スクリーピングボットを構築する決定は、通常APIで入手できないデータやリアルタイムモニタリングが必要なデータの収集の必要性から生じます。
1. 競争力の強化と市場調査
企業はスクリーピングボットを競争優位を得るために使用します。例えば、ECサイトは、競合の価格、在庫、製品説明をリアルタイムでモニタリングできます。これにより、動的価格調整が可能になり、競争力を維持できます。これは市場調査におけるウェブスクリーピングの主要な応用です。
2. コンテンツ集約とリード生成
メディア企業や専門プラットフォームは、ボットを使ってさまざまなソースからのコンテンツを集約し、ユーザーにとって価値のある中央集約リソースを作成します。同様に、販売チームは公開ディレクトリから連絡先情報や会社の詳細を抽出し、リード生成のパイプラインを駆動します。
3. 自動化と効率性
スクリーピングボットは、人間が数百時間かかるタスクを数分で行います。これは、金融データの収集、学術研究、数千ページにわたるコンプライアンスのモニタリングなど、効率が重要なタスクにおいて不可欠です。このプロセスの自動化は、企業がスクリーピングボットを構築する方法を学ぶために投資する主な理由です。 landmark case of hiQ Labs, Inc. v. LinkedIn Corp.は、公開データのスクリーピングの合法性をさらに明確にしました。
スクリーピングボットを構築する方法:ステップバイステップガイド
スクリーピングボットを構築する方法を学ぶには、構造化されたアプローチが必要です。これは、初期計画からデプロイメントとメンテナンスに至るまでです。
ステップ1:範囲と倫理を定義する
コードを書く前に、必要なデータポイントとターゲットサイトを明確に定義してください。重要なのは、サイトのrobots.txtファイルを確認することです。このファイルは、クローラーがアクセスできるサイトの部分を指定しています。常にサイトの利用規約に従ってください。これらのガイドラインを無視すると、IPのブロック、法的措置、倫理違反につながる可能性があります。コンプライアンスについて詳しく知るには、Googleの公式robots.txtガイドを参照してください。
ステップ2:適切なテクノロジースタックを選ぶ
テクノロジースタックは、ターゲットサイトの複雑さによって決まります。現代のサイトでは、ブラウザ自動化フレームワークが必須です。
| コンポーネント | 静的サイト(シンプル) | 動的サイト(複雑) |
|---|---|---|
| 言語 | Python、Node.js | Python、Node.js |
| HTTPクライアント | requests(Python) |
ブラウザ自動化ツールで処理されます |
| パーサー | BeautifulSoup、lxml |
Playwright、Puppeteer(組み込みのDOMアクセスを使用) |
| フレームワーク | なし/カスタムスクリプト | Scrapy、Scrapy-Playwright |
| セキュリティ | ベーシックなUser-Agentローテーション | プロキシ、CAPTCHAソルバー、ファーザープリンティング管理 |
2026年の堅牢なスクリーピングボットチュートリアルには、Pythonが推奨されます。これは、2026年のトップPythonウェブスクリーピングライブラリの豊富なエコシステムがあるためです。特にScrapyは、大規模プロジェクトに適した強力なフレームワークです。
ステップ3:セキュリティナビゲーション技術を実装する
これはウェブスクリーピングにおいて最も難しい部分です。サイトは、不正な自動データ抽出を防ぐために積極的にセキュリティ対策を採用しています。
A. リクエストスローティングとIPローテーション
レートリミットを回避するために、ボットはリクエスト間にランダムな遅延を導入する必要があります。さらに重要なのは、信頼性の高いプロキシネットワークを使用してIPアドレスをローテーションすることです。これにより、リクエストが多くの異なるユーザーから来ているように見えます。2026年にCAPTCHAソルバーを使用する際のIPブロックを回避する方法で効果的な戦略を学んでください。
B. 動的コンテンツとファーザープリンティングの処理
JavaScriptを実行し、人間ユーザーが見るのと同じようにページをレンダリングするため、Playwrightなどのヘッドレスブラウザを使用してください。 Playwright公式ドキュメントでは、CloudflareのTurnstileや高度なブラウザファーザープリンティングを含む、セキュリティ対策を回避する方法が示されています。これは、古いツールであるSeleniumよりも優れているとされています。
C. CAPTCHAの解決
CAPTCHAチャレンジが表示された場合、ボットは進行できません。専門的なサービスを統合して解決する必要があります。これらのサービスはAIを使用して画像やテキストのチャレンジを自動的に解決します。適切なCAPTCHAソルバーを選ぶことは、ボットの稼働時間の維持において重要です。2026年のウェブスクリーピングに最適な5つのCAPTCHAソルバーを比較して、最も信頼性の高いオプションを見つけてください。例えば、2026年の最適なreCAPTCHAソルバーを統合して、一般的なチャレンジを処理できます。
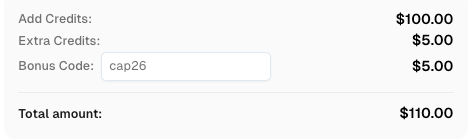
CapSolverにサインアップする際、コード
CAP26を使用してボーナスクレジットを取得してください!
ステップ4:データのクリーニング、ストレージ、スケジューリング
データが抽出されると、クリーニング(例:HTMLタグの削除、フォーマットの標準化)とストレージが必要です。継続的な運用のために、Cronジョブやクラウドネイティブなスケジューラーを使用してボットを定期的に実行する必要があります。これにより、市場調査用のウェブスクリーピングにおいてデータが新鮮で関連性を保たれます。
ステップ5:モニタリングとメンテナンス
サイトの構造は頻繁に変化します。あなたのスクリーピングボットは避けられない破損を起こします。ボットの失敗時に通知するためのロギングとモニタリングを実装してください。定期的なメンテナンスと新しいサイトレイアウトに合わせたセレクターの調整は、成功するスクリーピングボット運用者にとって継続的な作業です。
ケーススタディ:ECサイト価格モニタリングボット
3つの主要な競合ウェブサイトで、中規模な電子機器小売業者は毎時間上位500製品の価格をモニタリングする必要がありました。
- チャレンジ:競合サイトは、CloudflareのTurnstileや高度なブラウザファーザープリンティングなどの積極的なセキュリティ対策を採用していました。
- 解決策:彼らは、Scrapy-Playwrightを使用してクラウドプラットフォームにデプロイされた分散型スクリーピングボットを構築しました。IPローテーション用のプレミアムプロキシサービスを統合し、Cloudflareのチャレンジを解決する専門サービスを使用しました。
- 結果:ボットは99%の成功率を達成し、リアルタイムの価格データを提供しました。これにより、小売業者は動的価格戦略を実装でき、6か月以内にモニタリング対象製品の売上高が12%増加しました。これは、適切に設計されたスクリーピングボットの力の証明です。
結論と行動呼びかけ
スクリーピングボットとは何か、そしてどのように構築するかを理解することは、データ駆動型経済において今や必須のスキルです。高度なスクリーピングボットは、自動データ抽出のための強力なツールであり、市場インテリジェンスにおける非対称な効率性と深さを提供します。成功の鍵は、堅牢なセキュリティナビゲーション技術、現代的なテクノロジースタック、そして倫理的なスクリーピング実践へのコミットメントにあります。
最も高度なセキュリティ防御に対してボットが運用を維持するためには、信頼性の高いツールが必要です。プロフェッショナルなCAPTCHAソルバーがボットのワークフローにシームレスに統合される方法を調べて、複雑な課題に直面しても継続的なデータフローを保証してください。
FAQ: よくある質問
Q1: スクリーピングボットを構築することは合法ですか?
ウェブスクリーピングの合法性は複雑で、管轄、サイトの利用規約、データの性質に大きく依存します。一般的に、公開されているデータをスクリーピングすることは許容されることが多いですが、ログイン後のデータをスクリーピングしたり、サイトのrobots.txtを違反したりすることはリスクがあります。常に法的助言を求めて、倫理的な実践を優先してください。
Q2: スクリーピングボットとウェブクローラーの違いは何ですか?
ウェブクローラー(Googlebotなど)は、全体のウェブやその大きな部分をインデックス化することを目的としており、リンクの発見とインターネット構造のマッピングに焦点を当てています。スクリーピングボットは非常にターゲットに特化しており、限定されたページやウェブサイトから特定のデータポイントを抽出することを目的としています。スクリーピングボットは通常、クローリング機能を含みますが、インデックス化ではなくデータ抽出が主な目的です。
Q3: スクリーピングボットがブロックされるのを防ぐにはどうすればいいですか?
最も効果的な戦略は、人間の行動を模倣することです:ヘッドレスブラウザを使用し、高品質なプロキシでIPアドレスをローテーションし、リクエスト間にランダムな遅延を導入し、ブラウザのファーザープリンティングを管理してください。CAPTCHAやCloudflareなどのチャレンジが表示された場合は、専門的なセキュリティチャレンジ解決サービスを統合して自動的に解決してください。
Q4: AIは現代のスクリーピングボットにおいてどのような役割を果たしますか?
AIは、2つの主な方法でウェブスクリーピングを変革しています。第一に、セキュリティチャレンジの解決(AI駆動のCAPTCHAソルバー)において、第二にデータ解析においてです。LLMは、非常に非構造化されたテキスト(例:製品レビューやニュース記事)から構造化されたデータを抽出するために使用できます。これは、従来のセレクターに基づくボットが苦手とするタスクです。
Q5: スクリーピングボットに無料プロキシを使用できますか?
無料のプロキシーサーバーは非常に信頼性が低く、遅く、多くの場合、主要なウェブサイトによってブラックリストに載せられています。これにより、ブロック率が大幅に上昇し、データの完全性が損なわれる可能性があります。重要なウェブスクレイピングプロジェクトにおいては、プレミアムな住宅用またはISPプロキシーサービスへの投資が必須です。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。

Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
