Raspado de web Manejo de CAPTCHA: Guía de Automatización Segura

Aloísio Vítor
Image Processing Expert
TL;DR
- El manejo de CAPTCHA en el raspado de web debe comenzar con permiso, control de tasas y reglas claras de detención antes de agregar cualquier integración técnica.
- Los tipos principales de desafíos incluyen reCAPTCHA, Cloudflare Turnstile, reconocimiento de imágenes y flujos de validación de tráfico específicos de la página.
- CapSolver puede adaptarse a flujos de trabajo de raspado de web aprobados proporcionando APIs documentadas para crear tareas y recuperar resultados para los tipos comunes de desafío.
- La automatización buena trata los tokens como artefactos de validación de corta duración y registra cada tarea, reintento, dominio objetivo y estado de falla.
Introducción
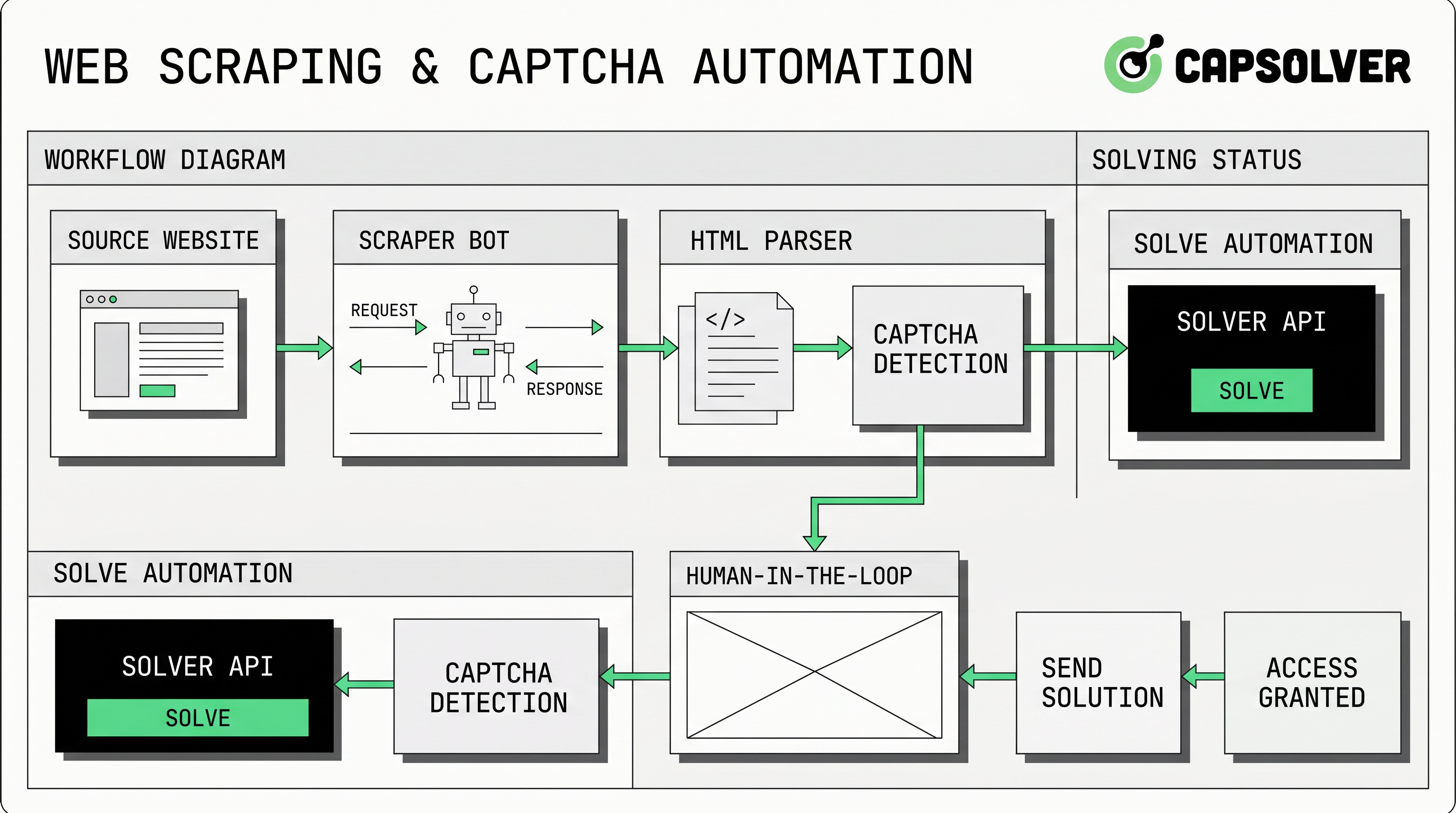
El manejo de CAPTCHA en el raspado de web es un problema práctico para equipos que recopilan datos públicos permitidos, realizan monitoreo de mercados, prueban aplicaciones propias o operan automatización interna. CapSolver puede apoyar estos flujos de trabajo cuando el objetivo es un manejo de desafíos controlado y legal, en lugar de tráfico no controlado. La mejor aproximación no es agregar un solucionador primero. Es confirmar el permiso, reducir las solicitudes innecesarias, identificar el tipo de desafío, preservar el contexto del navegador y agregar un flujo de API solo donde sea permitido. Esta guía explica cómo diseñar un proceso de raspado de web que sea técnicamente confiable, más fácil de auditar y alineado con las reglas de automatización responsable.
¿Por qué aparece el CAPTCHA en los flujos de automatización de raspado de web?
Las verificaciones de CAPTCHA en el raspado de web suelen aparecer cuando un sitio quiere más confianza sobre un visitante, un patrón de solicitud, un entorno de navegador o un comportamiento de cuenta. Algunos desafíos son visibles, mientras que otros son basados en puntuación o tokens. Google afirma que reCAPTCHA v3 funciona sin interrumpir a los usuarios y devuelve un puntaje de riesgo de 0.0 a 1.0 para cada solicitud. Cloudflare afirma que los tokens de Turnstile deben validarse en el servidor, son de uso único y son válidos durante 300 segundos. Estos sistemas forman parte de un patrón más amplio de validación de tráfico, no solo de un rompecabezas visual.
Esto significa que el manejo de CAPTCHA en el raspado de web no puede separarse de la calidad de las solicitudes. Altas tasas de solicitud, mala reputación de IP, señales de navegador faltantes o estado de sesión inconsistente pueden aumentar la frecuencia de los desafíos. Antes de agregar una API, los equipos deben reducir los disparadores evitables al cachear de manera responsable, respetar robots y términos, limitar la concurrencia, identificar su caso de uso cuando sea apropiado y detenerse cuando un sitio niegue o restrinja el acceso.
| Causa | Respuesta práctica | ¿Por qué ayuda? |
|---|---|---|
| Alta tasa de solicitud | Añadir límites de cola y retroceso | Reduce la carga y los intentos fallidos. |
| Mismatch de navegador | Usar un perfil de automatización de navegador consistente | Mantiene el contexto de la página estable. |
| Inconsistencia de proxy | Mantener alineados el proxy, la sesión y la tarea de desafío | Evita el desajuste de contexto de token. |
| Tipo de desafío desconocido | Detectar reCAPTCHA, Turnstile o desafío de imagen antes de crear la tarea | Envía el payload de API correcto. |
| Permiso no claro | Revisar términos, robots, contratos y sensibilidad de datos | Mantiene la automatización dentro de los límites aprobados. |
Construye la política antes de la integración de CAPTCHA en el raspado de web
El trabajo de CAPTCHA en el raspado de web debe comenzar con gobernanza. OWASP describe la automatización no deseada como software que se desvía del comportamiento aceptado y crea efectos indeseables para una aplicación web, y su taxonomía de amenazas automatizadas incluye escenarios de raspado y abuso relacionados con CAPTCHA. Para los equipos, esto significa que el mismo flujo técnico puede ser aceptable en un contexto y no en otro.
Una política responsable debe listar dominios permitidos, tipos de datos permitidos, propósito comercial, límites de tasa de solicitud, reglas de cuenta, reglas de retención y contactos de escalada. También debe explicar qué no debe hacer la automatización, como acceder a áreas privadas, recopilar datos sensibles sin permiso o continuar después de señales de denegación. Esta política protege tanto al sitio objetivo como a la propia organización, ya que crea una línea clara entre la recolección de datos aprobada y la actividad prohibida.
Elige el flujo de trabajo de CAPTCHA en el raspado de web adecuado
El manejo de CAPTCHA en el raspado de web generalmente se ajusta a uno de tres patrones técnicos. El primero es la evitación mediante una mejor higiene de solicitud: menos solicitudes, mejor caché y menos comportamiento ruidoso del navegador. El segundo es la revisión humana para casos extremos, donde un proceso de bajo volumen envía páginas difíciles a un operador. El tercero es un flujo de desafío basado en API, donde un trabajo aprobado envía parámetros de desafío a un proveedor y recupera una solución.
La documentación oficial de la API de CapSolver describe un flujo basado en tareas con createTask y getTaskResult. En este modelo, el raspador detecta el desafío, envía el objeto de tarea correcto, recibe un ID de tarea y consulta hasta que el resultado esté listo. La guía de createTask indica que las solicitudes requieren clientKey y un objeto de tarea, y la guía de getTaskResult documenta los estados processing y ready para tareas asíncronas.
Para páginas de reCAPTCHA, los equipos deben revisar las guías de reCAPTCHA v2 o reCAPTCHA v3 de CapSolver en lugar de copiar cargas útiles genéricas. Para páginas de Turnstile, use la guía de Cloudflare Turnstile y recuerde que las reglas de validación del lado del servidor de Cloudflare hacen que la frescura del token sea importante.
Mantén consistente el contexto del navegador, el proxy y el token
Los errores de CAPTCHA en el raspado de web suelen provenir de un desajuste de contexto. Si el navegador solicita una página a través de un proxy pero la tarea de desafío usa otro camino de red, el token devuelto puede no coincidir con el entorno esperado. Si la acción de la página cambia entre la detección y la presentación, un token basado en puntuación puede no validarse como se pretendía. Si el trabajador espera demasiado, un token puede expirar.
Por eso, la capa de automatización debe vincular una tarea de desafío a un ID de trabajo, sesión de navegador, proxy, URL objetivo, clave del sitio y marca de tiempo. Los recursos de CapSolver sobre Selenium en automatización web y Puppeteer en automatización web son enlaces internos útiles para equipos que necesitan estandarizar controladores de navegador antes de agregar manejo de desafíos. Cuando se usan proxies, la guía sobre puertos de proxy para raspado y automatización puede ayudar a mantener configuraciones de red consistentes.
Código adicional
Redime tu código de bonificación de CapSolver
¡Aumenta tu presupuesto de automatización instantáneamente!
Usa el código de bonificación CAP26 al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redímelo ahora en tu Panel de CapSolver
Resumen de comparación: opciones comunes de CAPTCHA en el raspado de web
El manejo de CAPTCHA en el raspado de web debe coincidir con el volumen, el nivel de permiso y los requisitos de confiabilidad del trabajo. Una tarea de investigación de bajo volumen puede solo necesitar revisión humana. Un trabajo recurrente de monitoreo generalmente necesita manejo basado en API, registros y condiciones de detención. Un trabajo de alto volumen mal gobernado no debe proseguir en absoluto, incluso si la integración técnica funciona.
| Opción | Mejor caso de uso | Riesgo principal |
|---|---|---|
| Solo higiene de solicitud | Páginas públicas con baja frecuencia de desafío | Puede no manejar páginas de desafío cuando aparecen. |
| Revisión humana | Investigación o depuración de bajo volumen | Lenta y no adecuada para trabajos programados. |
| Manejo basado en API | Flujos recurrentes aprobados con tipos de desafío conocidos | Requiere contexto preciso, registros de auditoría y controles de política. |
| No proseguir | Acceso restringido, privado, sensible o denegado | Continuar puede crear riesgos legales, de privacidad y de seguridad. |
El artículo de CapSolver sobre Selenium versus Puppeteer para resolver CAPTCHA es útil al seleccionar herramientas de automatización de navegador, mientras que la guía sobre automatización de navegador para desarrolladores puede ayudar a los equipos a separar el control del navegador del manejo de desafíos.
Lista de verificación para la implementación de CAPTCHA en el raspado de web
La implementación de CAPTCHA en el raspado de web debe ser pequeña, observable y reversible. Comience con un flujo de trabajo de prueba y una lista de permitidos limitada. Registre el tipo de desafío, la URL objetivo, la clave del sitio, el ID de proxy, el ID de tarea, el estado de la tarea, la latencia y el resultado final. Si el sitio cambia su política, el comportamiento del desafío o su estado de respuesta, detenga el trabajo y revise el flujo en lugar de aumentar los reintentos.
Una lista de verificación práctica incluye revisión de permisos, revisión de robots y términos, minimización de datos, lista de dominios permitidos, límite de tasa, perfil de navegador, consistencia de proxy, detección de desafío, creación de tarea de API, política de sondeo, tiempo de espera, manejo de errores, registros de auditoría y revisión posterior a la ejecución. Los equipos pueden agregar orientación sobre el uso de un servicio de raspado y resolución de CAPTCHA en documentación interna porque presenta el servicio como parte de un flujo más amplio en lugar de un atajo independiente.
Errores comunes a evitar
Los proyectos de CAPTCHA en el raspado de web suelen fallar cuando los equipos tratan el manejo de desafíos como un complemento separado. Un token devuelto por una API solo es útil si se ajusta al estado del navegador, la página objetivo, la acción y la ventana de tiempo. Otro error común es el reintentar sin límites. Si una tarea falla repetidamente, la respuesta correcta es inspeccionar parámetros, permisos y señales del sitio, no aumentar la carga.
Los equipos también deben evitar almacenar secretos en scripts de raspado, compartir claves de API entre entornos o enviar tareas de desafío para dominios fuera de la lista de permitidos aprobada. Use configuración central, almacenamiento de secretos y registro a nivel de trabajo. Si su flujo de trabajo usa una API, la documentación de la API de CapSolver y la guía de getTaskResult deben permanecer como la verdad sobre el comportamiento de los puntos finales.
Conclusión/CTA
El manejo de CAPTCHA en el raspado de web es más seguro cuando se diseña como un flujo controlado: permiso primero, higiene de solicitud segundo, detección de desafío tercero y integración de API solo donde sea permitido. La configuración correcta mantiene el contexto del navegador estable, trata los tokens como de corta duración, registra cada resultado y se detiene cuando el acceso no está autorizado. Si su equipo necesita manejo de desafíos documentado para raspado, QA o monitoreo aprobado, comience con un pequeño flujo de prueba usando CapSolver.
Preguntas frecuentes
¿Qué significa el CAPTCHA de raspado de web?
El CAPTCHA de raspado de web significa que un raspador encuentra un desafío de validación de tráfico al recopilar datos. La respuesta correcta depende del permiso, del tipo de desafío, de los límites de tasa y de las reglas de acceso del sitio.
¿Puede manejarse el CAPTCHA de raspado de web con una API?
Sí, en flujos aprobados, una API puede crear una tarea de desafío y devolver una solución a través de un punto final documentado. Para una visión general general, consulte cómo los servicios de raspado y resolución de CAPTCHA proporcionan una API.
¿Por qué los raspadores de Selenium y Puppeteer ven verificaciones de CAPTCHA?
Selenium y Puppeteer pueden generar patrones de navegador que los sitios revisan durante la validación de tráfico, especialmente a altas tasas de solicitud o con sesiones inestables. Estandarizar la automatización web de Selenium o la configuración de Puppeteer ayuda a reducir inconsistencias evitables.
¿Cómo deben usarse los proxies en un flujo de CAPTCHA de raspado de web?
Use proxies solo donde sea legal y permitido, y mantenga la identidad del proxy consistente entre la sesión del navegador y la tarea de desafío. El objetivo es un contexto estable, no un volumen de solicitud agresivo.
¿Es legal el manejo de CAPTCHA de raspado de web para cualquier sitio web público?
No. La visibilidad pública no crea automáticamente permiso para la recolección automatizada. Revise los términos del sitio, las directrices de robots, contratos, requisitos de privacidad, sensibilidad de datos y límites de tasa antes de ejecutar cualquier raspador.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.
Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.


