API de búsqueda vs. Cadena de suministro de conocimiento: Guía de infraestructura de datos de IA

Aloísio Vítor
Image Processing Expert
TL;DR
- Las herramientas de API de búsqueda son útiles para el descubrimiento rápido, pero no cubren todas las necesidades de los sistemas de IA de producción.
- Una cadena de suministro de conocimiento incluye descubrimiento, extracción, validación, almacenamiento, orquestación y monitoreo.
- Una API de SERP ayuda a recopilar resultados ordenados de búsqueda, mientras que una API de scraping web ayuda a recopilar contenido a nivel de página.
- Una infraestructura sólida de datos web depende de la frescura, la calidad de la fuente, la auditoría y la recopilación consciente de las políticas.
- Una tubería de datos de IA debe conectar la recuperación con el análisis, la enriquecimiento, la gobernanza y el uso de modelos posteriores.
- Para automatizaciones aprobadas, los equipos también pueden necesitar capas de confiabilidad cuando los pasos de verificación interrumpen los flujos de recopilación.
Introducción
La respuesta corta es sencilla. Una API de búsqueda es una interfaz de recuperación, mientras que una cadena de suministro de conocimiento es un modelo operativo para la infraestructura de datos de IA. Este artículo está dirigido a ingenieros de IA, fundadores técnicos, equipos de SEO y constructores de plataformas de datos que necesitan datos web actualizados sin perder el control de la calidad o el cumplimiento. Si está eligiendo entre una interfaz de búsqueda, una API de SERP y una pila de infraestructura de datos web más amplia, la decisión correcta depende del riesgo, la frescura y el uso posterior. El valor principal es claridad práctica. Verá dónde encaja cada opción, dónde falla y cómo diseñar una tubería de datos de IA más confiable.
Introducción a las APIs de búsqueda y cadenas de suministro de conocimiento
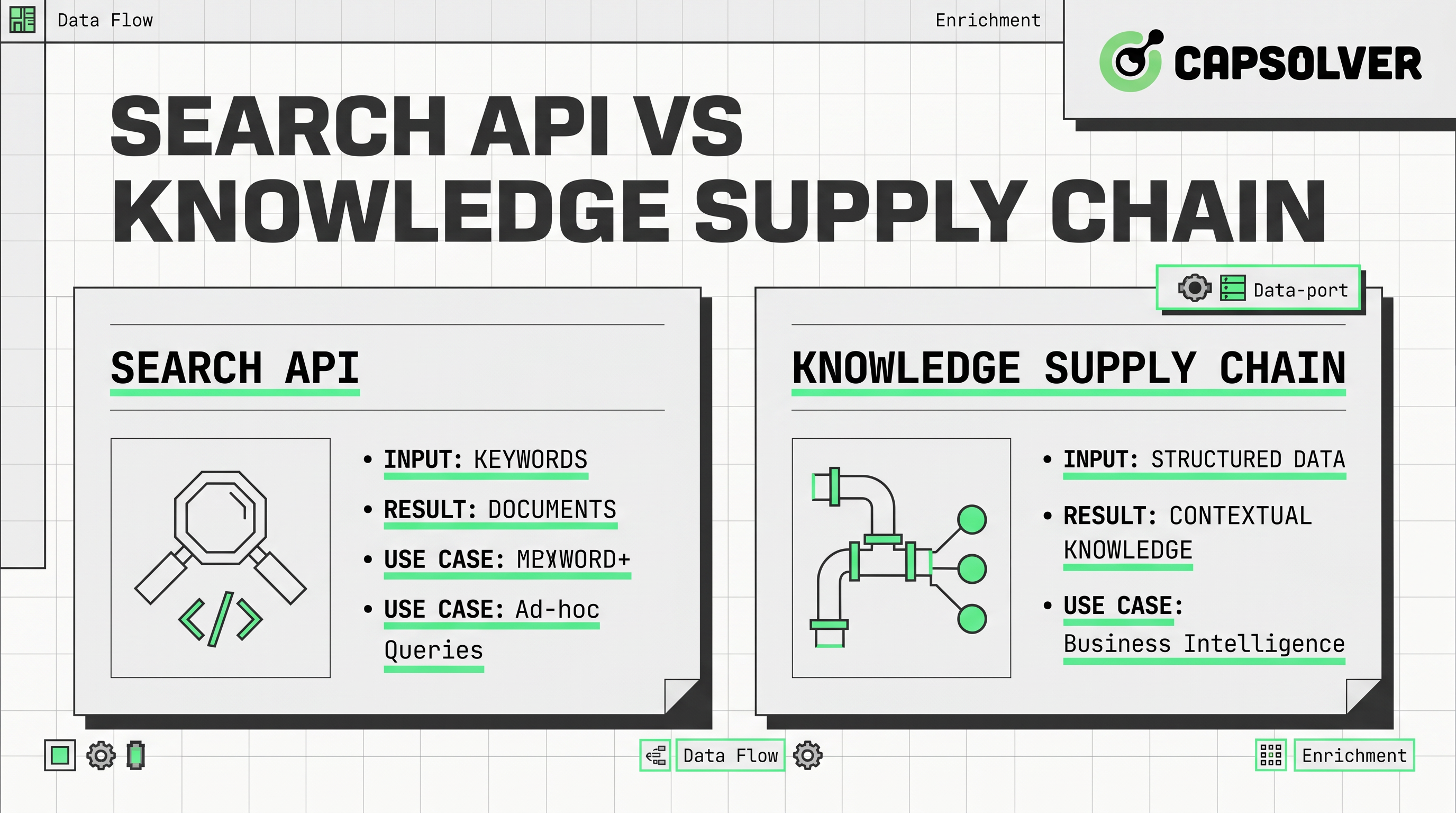
La diferencia principal es arquitectónica. Una API de búsqueda generalmente acepta una consulta y devuelve enlaces ordenados, fragmentos o resultados resumidos de un índice. Esto hace que estas herramientas sean atractivas cuando los equipos necesitan respuestas rápidas, enriquecimiento ligero o prototipos iniciales.
Una cadena de suministro de conocimiento es más amplia por diseño. Trata la adquisición de datos para la IA como un flujo continuo desde el descubrimiento de fuentes hasta la recopilación, validación, almacenamiento, transformación y entrega. Este modelo se alinea mejor con sistemas de agentes, herramientas de inteligencia de mercado y capas de recuperación que deben soportar decisiones repetibles.
Esta diferencia importa porque los sistemas de IA actúan sobre lo que reciben. El Marco de Gestión de Riesgos de IA de NIST explica que la IA confiable depende de prácticas de diseño, desarrollo, uso y evaluación, no solo de los resultados del modelo. En la práctica, eso significa que la capa de recuperación forma parte de la superficie de riesgo.
Otro motivo es la política. Google Search Central indica que robots.txt se utiliza principalmente para gestionar el tráfico de los rastreadores y no es un método universal para ocultar contenido. Esta recordación importa para cualquier equipo que construya infraestructura de datos web. El cumplimiento comienza antes de la primera solicitud.
Cómo funcionan las APIs de búsqueda en sistemas de recuperación de datos
La descripción más sencilla es esta. Una API de búsqueda se encuentra en la capa de descubrimiento. Convierte una consulta de texto en resultados ordenados que pueden alimentar chatbots, copilotos o asistentes de investigación.
La mayoría de las herramientas de búsqueda optimizan para velocidad y comodidad del desarrollador. Eso suele significar datos indexados, resultados en caché o una capa de relevancia preconstruida. Para tareas de bajo riesgo, esto es suficiente. Un bot de soporte, una herramienta de generación de ideas para SEO o un agente prototipo suele beneficiarse de este tipo de punto de entrada de recuperación porque el sistema necesita dirección antes de necesitar evidencia profunda.
Una API de SERP es más estrecha. Se enfoca en las páginas de resultados de los motores de búsqueda y elementos relacionados. Eso puede ser útil para el seguimiento de clasificaciones, el monitoreo de consultas y la investigación de SEO competitivo. Sin embargo, una API de SERP aún refleja la capa de búsqueda, no la capa completa de contenido. Si su sistema necesita texto de página real, campos estructurados o comparaciones históricas, generalmente necesita otro paso.
Este es el punto donde la gente confunde el descubrimiento con el conocimiento. El descubrimiento le dice dónde buscar. El conocimiento requiere recuperar, analizar y verificar lo que realmente está allí. Un punto de entrada de búsqueda ayuda con la primera parte. No completa toda la tubería de datos de IA.
¿Qué es una cadena de suministro de conocimiento en la arquitectura de IA?
La mejor forma de definirla es operativa. Una cadena de suministro de conocimiento es el sistema que mueve los datos desde la web pública hasta el contexto listo para la toma de decisiones para modelos, agentes y analistas.
La idea de cadena de suministro aparece en escritos recientes de la industria, pero muchos artículos se detienen en la metáfora. La versión práctica tiene seis capas. En primer lugar, el descubrimiento a través de interfaces de búsqueda, una API de SERP, fuentes, mapas del sitio o fuentes conocidas. En segundo lugar, la extracción a través de una API de scraping web, automatización del navegador o conectores directos de fuentes. Tercero, la normalización, donde HTML, JSON, PDFs y metadatos se transforman en registros consistentes. Cuarto, la verificación, que comprueba la frescura, la duplicación, la propiedad y la calidad de la fuente. Quinto, el almacenamiento e indexación para recuperación. Sexto, la orquestación, donde una tubería de datos de IA envía el resultado a sistemas RAG, evaluadores o herramientas de agente.
El Protocolo de Contexto del Modelo ofrece una pista útil aquí. Documentación de MCP lo define como un estándar abierto para conectar aplicaciones de IA con fuentes de datos, herramientas y flujos de trabajo. No reemplaza una capa de búsqueda, pero muestra por qué una cadena de suministro de conocimiento debe incluir interfaces más allá de la recuperación.
En resumen, una API de búsqueda es una herramienta. Una cadena de suministro de conocimiento es un sistema.
Diferencias clave entre APIs de búsqueda y cadenas de suministro de conocimiento
La respuesta más clara está en las restricciones operativas. Una API de búsqueda suele optimizarse para búsquedas rápidas. Una cadena de suministro de conocimiento se optimiza para la calidad de los datos bajo cargas de trabajo reales.
Resumen de comparación
| Dimensión | API de búsqueda | API de SERP | Cadena de suministro de conocimiento |
|---|---|---|---|
| Trabajo principal | Descubrimiento basado en consultas | Recopilación de elementos de SERP | Adquisición de datos integral para IA |
| Salida típica | Enlaces, fragmentos, resúmenes | Elementos de SERP ordenados | Contenido completo, metadatos, historia, validación |
| Ideal para | Prototipos, asistentes, investigación ligera | Monitoreo de SEO, seguimiento de resultados | Agentes, sistemas de inteligencia, IA de producción |
| Control de frescura | Limitado y dependiente del proveedor | Moderado en la capa de búsqueda | Alto cuando se combina con recopilación directa |
| Profundidad de evidencia | Baja a media | Baja a media | Alta |
| Ajuste de gobernanza | Limitado | Moderado | Fuerte |
| Rol en la tubería de datos de IA | Primer paso | Primer paso con énfasis en SERP | Modelo operativo de múltiples etapas |
La brecha competitiva en artículos actuales es orientación práctica. Muchos artículos explican por qué las herramientas de búsqueda son rápidas, o por qué las cadenas de suministro de conocimiento suenan estratégicas. Pocos explican dónde termina una y comienza la otra dentro de la infraestructura de datos web real. Esa frontera es la que determina la confiabilidad del sistema.
Una segunda diferencia es la auditoría. Cuando un modelo responde solo con fragmentos, a menudo los equipos no pueden inspeccionar la ruta de transformación de la fuente. Cuando una cadena de suministro de conocimiento almacena contenido de página, marcas de tiempo, registros de extracción y verificaciones de calidad, la misma respuesta es más fácil de revisar y mejorar.
Una tercera diferencia es el costo de fallo. Si una API de descubrimiento devuelve un resumen caduco, una aplicación de chat de prototipo puede aún sentirse aceptable. Si el mismo problema afecta inteligencia de precios o monitoreo de políticas, el costo puede ser mucho mayor.
Casos de uso en agentes de IA y infraestructura de datos
El ajuste es más fácil de ver a través de casos de uso. Una API de búsqueda funciona bien cuando el sistema necesita orientación rápida. Un agente puede usar esta capa de recuperación para encontrar URLs candidatas, menciones recientes o grupos de temas antes de iniciar una recuperación más profunda.
Una API de SERP funciona bien cuando la tarea es orientada a búsqueda. Los equipos de SEO usan una API de SERP para el seguimiento de clasificaciones, análisis de resultados pagados y orgánicos, y pruebas de consultas regionales. La salida es útil, pero sigue siendo una capa de evidencia.
Una cadena de suministro de conocimiento es mejor cuando la tarea es operativa. Monitoreo de precios, inteligencia de clientes, seguimiento de políticas, enriquecimiento de catálogos, investigación de compras y verificación de noticias requieren más que resultados ordenados. Necesitan extracción, marcas de tiempo, control de esquema y una tubería de datos de IA confiable.
También es aquí donde la herramientería interna importa. Los equipos que construyen agentes pueden combinar marcos de agentes de IA, herramientas de extracción de datos más efectivas, y escalado de la recopilación de datos para entrenamiento de LLM en una sola pila. Estos componentes son más fáciles de evaluar cuando separa descubrimiento, extracción y orquestación en lugar de tratar cada entrada de upstream como la misma categoría de herramienta.
Implicaciones para herramientas de scraping web y ingeniería de datos
La lección más grande es que la recuperación sola no produce datos confiables. Una API de scraping web importa porque convierte enlaces en registros utilizables. Una capa de ingeniería de datos importa porque el contenido de página crudo es inconsistente, ruidoso y a menudo duplicado.
Eso es por qué el diseño de recopilación cumplidor es importante. Respete las directivas de robots, límites de velocidad, políticas de acceso y restricciones contractuales. Las directivas de rastreador de Google dejan claro que la gestión del tráfico y el comportamiento de rastreo son parte del entorno operativo normal de la web. Una buena infraestructura de datos web debe reducir la carga en los servidores, documentar las reglas de las fuentes y preservar registros de auditoría.
Desde una perspectiva de herramientas, la pila suele verse así. Una API de descubrimiento o una API de SERP identifica objetivos. Una API de scraping web o una herramienta de navegador recopila contenido. Una tubería de datos de IA analiza, enriquece y almacena registros. Las herramientas de evaluación puntúan frescura y confianza de la fuente. Luego, los marcos de agentes o sistemas RAG usan el resultado.
La confiabilidad operativa también merece una nota realista. Algunos flujos de automatización aprobados encuentran pasos de verificación que interrumpen la recopilación o el monitoreo. En esos casos, a veces los equipos añaden un servicio de apoyo como por qué la automatización web sigue fallando en captchas o agentes de IA para monitoreo de precios para mantener flujos autorizados estables. Si eso forma parte de su pila, CapSolver es relevante porque ofrece patrones de API documentados para esos escenarios.
La forma más segura de hablar de CapSolver es mantenerse cerca de su documentación oficial. El ejemplo siguiente refleja el formato de solicitud createTask documentado en la guía de API de CapSolver y debe usarse solo en entornos de automatización aprobados.
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey": "TU_CLAVE_DE_API",
"appId": "ID_DE_APP",
"task": {
"type": "ImageToTextTask",
"body": "IMAGEN_EN_BASE64"
}
}Ejemplo no es el núcleo de una cadena de suministro de conocimiento. Es un componente de confiabilidad secundario. El punto principal sigue siendo el mismo. El descubrimiento, la recopilación y la gobernanza deben diseñarse juntos.
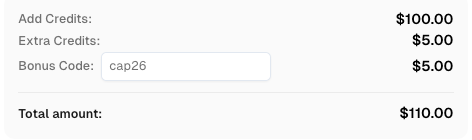
Redimir tu código de bonificación de CapSolver
¡Aumenta tu presupuesto de automatización de inmediato!
Usa el código de bonificación CAP26 al recargar tu cuenta de CapSolver para obtener un bono adicional del 5% en cada recarga — sin límites.
Redimiéndolo ahora en tu Panel de CapSolver
Conclusión
La conclusión práctica es sencilla. Una API de búsqueda ayuda a los sistemas a encontrar información, pero una cadena de suministro de conocimiento ayuda a los sistemas a confiar, reutilizar y operacionalizarla. Si su carga de trabajo es exploratoria, esta capa de recuperación puede ser suficiente. Si su carga de trabajo afecta productos, ingresos o cumplimiento, necesita una infraestructura de datos web más amplia con extracción, validación y almacenamiento integrados.
Para la mayoría de los equipos, el diseño ganador es híbrido. Use una API de descubrimiento o una API de SERP para descubrimiento. Use una API de scraping web para recopilar contenido. Luego conéctelos ambos en una tubería de datos de IA con políticas de fuente claras, monitoreo y revisión. Esa es la ruta más duradera para la adquisición de datos para IA.
Si está planeando el siguiente paso, audite su pila actual por capa. Pregunte dónde termina el descubrimiento, dónde comienza la evidencia y dónde se registra la gobernanza. Ese ejercicio suele revelar si necesita una interfaz más rápida, una tubería más profunda o ambas.
Preguntas frecuentes
¿Es igual una API de búsqueda que una API de SERP?
No. Una API de búsqueda es una interfaz de recuperación amplia, mientras que una API de SERP se enfoca en las páginas de resultados de los motores de búsqueda y elementos relacionados.
¿Cuándo es suficiente esta clase de interfaz de recuperación para aplicaciones de IA?
Suele ser suficiente para prototipos, asistentes internos, tareas de investigación de bajo riesgo y pasos iniciales de descubrimiento en una tubería.
¿Qué hace que una cadena de suministro de conocimiento sea mejor para IA de producción?
Una cadena de suministro de conocimiento agrega extracción, normalización, validación, almacenamiento y orquestación. Esas capas mejoran la frescura, la auditoría y la reutilización.
¿Dónde encaja una API de scraping web en este modelo?
Una API de scraping web se ubica después del descubrimiento. Convierte URLs y páginas de origen en contenido estructurado que una tubería de datos de IA puede procesar.
¿Por qué mencionar a CapSolver en un artículo sobre infraestructura de datos de IA?
Porque algunos flujos de automatización aprobados enfrentan interrupciones de verificación después del descubrimiento. En ese contexto estrecho, CapSolver puede apoyar la continuidad operativa como un componente dentro de un sistema más amplio y consciente de las políticas.
Ver más
aws wafJul 23, 2026
Cómo resolver AWS WAF en LangChain con CapSolver
Construya un flujo de trabajo de AWS WAF autorizado con herramientas CapSolver, detección de respuestas, puertas de política, manejo de sesiones, reintentos y verificación.
AIJul 23, 2026
Cómo resolver Cloudflare Turnstile en agentes de LangGraph
Construye un flujo de trabajo de solucionador de Cloudflare Turnstile de LangGraph con CapSolver, manejo de sesiones de Playwright, puertas de política, reintentos, verificación y revisión.