Web Scraping: Gerenciamento de CAPTCHA – Guia de Automação Segura

Adélia Cruz
Neural Network Developer
TL;DR
- O tratamento de captchas em raspagem de web deve começar com permissão, controle de taxa e regras claras para parar antes de qualquer integração técnica.
- Os principais tipos de desafios incluem reCAPTCHA, Cloudflare Turnstile, reconhecimento de imagem e fluxos de validação de tráfego específicos da página.
- A CapSolver pode se adequar aos fluxos de trabalho aprovados de raspagem de web com APIs de criação de tarefa e recuperação de resultados documentadas para os principais tipos de desafio.
- Automação boa trata tokens como artefatos de validação de curta duração e registra todas as tarefas, tentativas, domínio-alvo e estado de falha.
Introdução
O tratamento de captchas em raspagem de web é um problema prático para equipes que coletam dados públicos aprovados, monitoram o mercado, testam aplicações próprias ou operam automação interna. CapSolver pode apoiar esses fluxos de trabalho quando o objetivo é um gerenciamento de desafios controlado e legal, em vez de tráfego descontrolado. A melhor abordagem não é adicionar um solucionador primeiro. É confirmar a permissão, reduzir solicitações desnecessárias, identificar o tipo de desafio, preservar o contexto do navegador e adicionar um fluxo de API apenas onde for permitido. Este guia explica como projetar um processo de raspagem de web que seja tecnicamente confiável, mais fácil de auditoriar e alinhado com regras de automação responsável.
Por que o captcha de raspagem de web aparece nos fluxos de automação
As verificações de captcha em raspagem de web geralmente aparecem quando um site quer mais confiança sobre um visitante, padrão de solicitação, ambiente do navegador ou comportamento de conta. Alguns desafios são visíveis, enquanto outros são baseados em pontuação ou token. O Google afirma que o reCAPTCHA v3 funciona sem interromper os usuários e retorna uma pontuação de risco de 0,0 a 1,0 para cada solicitação. O Cloudflare afirma que os tokens do Turnstile devem ser validados no servidor, são de uso único e são válidos por 300 segundos. Esses sistemas fazem parte de um padrão mais amplo de validação de tráfego, não apenas um quebra-cabeça visual.
Isso significa que o tratamento de captcha em raspagem de web não pode ser separado da qualidade das solicitações. Altas taxas de solicitação, reputação de IP instável, sinais de navegador ausentes ou estado de sessão inconsistente podem aumentar a frequência dos desafios. Antes de adicionar uma API, as equipes devem reduzir gatilhos evitáveis, cacheando de forma responsável, respeitando robots e termos, limitando a concorrência, identificando seu caso de uso apropriadamente e parando quando um site negar ou restringir o acesso.
| Causa | Resposta prática | Por que ajuda |
|---|---|---|
| Alta taxa de solicitações | Adicionar limites de fila e backoff | Reduz a carga e tentativas falhas. |
| Mismatch de navegador | Usar um perfil consistente de automação de navegador | Mantém o contexto da página estável. |
| Inconsistência de proxy | Manter proxy, sessão e tarefa de desafio alinhados | Evita o mismatch de contexto do token. |
| Tipo de desafio desconhecido | Detectar reCAPTCHA, Turnstile ou desafio de imagem antes da criação da tarefa | Envia o payload de API correto. |
| Permissão não clara | Revisar termos, robots, contratos e sensibilidade de dados | Mantém a automação dentro dos limites aprovados. |
Crie a política antes da integração de captcha em raspagem de web
O trabalho com captcha em raspagem de web deve começar com governança. A OWASP descreve automação indesejada como software que se desvia do comportamento aceito e cria efeitos indesejados para um aplicativo web, e sua taxonomia de ameaças automatizadas inclui cenários de raspagem e abuso relacionados a CAPTCHA. Para as equipes, isso significa que o mesmo fluxo técnico pode ser aceitável em um contexto e inaceitável em outro.
Uma política responsável deve listar domínios permitidos, tipos de dados permitidos, propósito comercial, limites de taxa de solicitação, regras de conta, regras de retenção e contatos de escalonamento. Também deve explicar o que a automação não deve fazer, como acessar áreas privadas, coletar dados sensíveis sem permissão ou continuar após sinais de negação. Essa política protege tanto o site-alvo quanto a própria organização, pois cria uma linha clara entre a coleta de dados aprovada e atividades proibidas.
Escolha o fluxo correto de captcha em raspagem de web
O tratamento de captcha em raspagem de web geralmente se enquadra em um dos três padrões técnicos. O primeiro é a evitação por meio de melhor higiene de solicitação: menos solicitações, melhor cache e comportamento de navegador menos barulhento. O segundo é a revisão humana para casos excepcionais, onde um processo de baixo volume redireciona páginas difíceis para um operador. O terceiro é um fluxo de desafio baseado em API, onde um trabalho aprovado envia parâmetros de desafio para um provedor e recupera uma solução.
A documentação oficial da API da CapSolver descreve um fluxo baseado em tarefa com createTask e getTaskResult. Nesse modelo, o raspador detecta o desafio, envia o objeto de tarefa correto, recebe um ID de tarefa e verifica até que o resultado esteja pronto. O guia createTask afirma que as solicitações exigem clientKey e um objeto de tarefa, e o guia getTaskResult documenta os estados processing e ready para tarefas assíncronas.
Para páginas reCAPTCHA, as equipes devem revisar o guia reCAPTCHA v2 ou guia reCAPTCHA v3 da CapSolver em vez de copiar payloads genéricos. Para páginas Turnstile, use o guia Cloudflare Turnstile e lembre-se de que as regras de validação do lado do servidor do Cloudflare tornam a frescor do token importante.
Mantenha o contexto do navegador, proxy e token consistente
Erros de captcha em raspagem de web frequentemente vêm de mismatch de contexto. Se o navegador solicita uma página por meio de um proxy, mas a tarefa de desafio usa outro caminho de rede, o token retornado pode não corresponder ao ambiente esperado. Se a ação da página mudar entre a detecção e o envio, um token baseado em pontuação pode não validar conforme planejado. Se o trabalhador esperar muito, um token pode expirar.
É por isso que a camada de automação deve vincular uma tarefa de desafio a um ID de trabalho, sessão do navegador, proxy, URL-alvo, chave do site e horário. Os recursos da CapSolver sobre Selenium na automação da web e Puppeteer na automação da web são links úteis para equipes que precisam padronizar drivers de navegador antes de adicionar tratamento de desafio. Quando proxies estão envolvidos, a orientação sobre portas de proxy para raspagem e automação pode ajudar a manter as configurações de rede consistentes.
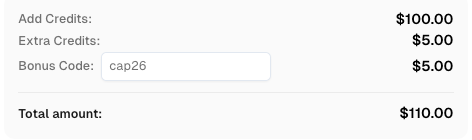
Código Bônus
Resgatar seu código promocional da CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código promocional CAP26 ao recarregar sua conta da CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel da CapSolver
Resumo da comparação: opções comuns de captcha em raspagem de web
O tratamento de captcha em raspagem de web deve corresponder ao volume, nível de permissão e exigência de confiabilidade do trabalho. Uma tarefa de pesquisa de baixo volume pode precisar apenas de revisão humana. Um trabalho de monitoramento recorrente geralmente precisa de gerenciamento de estado baseado em API, logs e condições de parada. Um trabalho de alto volume mal governado não deve prosseguir, mesmo que a integração técnica funcione.
| Opção | Caso de uso ideal | Risco principal |
|---|---|---|
| Higiene de solicitação apenas | Páginas públicas com baixa frequência de desafio | Pode não lidar com páginas de desafio quando elas aparecem. |
| Revisão humana | Pesquisa ou depuração de baixo volume | Lenta e não adequada para trabalhos agendados. |
| Tratamento baseado em API | Fluxos recorrentes aprovados com tipos de desafio conhecidos | Requer contexto preciso, logs de auditoria e controles de política. |
| Não prosseguir | Acesso restrito, privado, sensível ou negado | Continuar pode criar riscos legais, de privacidade e de segurança. |
O artigo da CapSolver sobre Selenium versus Puppeteer para resolução de CAPTCHA é útil ao selecionar ferramentas de automação de navegador, enquanto o guia sobre automação de navegador para desenvolvedores pode ajudar as equipes a separar o controle do navegador do tratamento de desafio.
Checklist de implementação para captcha em raspagem de web
A implementação de captcha em raspagem de web deve ser pequena, observável e reversível. Comece com um fluxo de staging e uma lista de permissões limitada. Registre o tipo de desafio, URL-alvo, chave do site, ID do proxy, ID da tarefa, status da tarefa, latência e resultado final. Se o site mudar sua política, comportamento de desafio ou status de resposta, pare o trabalho e revise o fluxo em vez de aumentar as tentativas.
Um checklist prático inclui revisão de permissão, revisão de robots e termos, minimização de dados, lista de domínios permitidos, limite de taxa, perfil de navegador, consistência de proxy, detecção de desafio, criação de tarefa de API, política de verificação, tempo limite, tratamento de erros, logs de auditoria e revisão pós-execução. As equipes podem adicionar orientações sobre o uso de um serviço de raspagem e resolução de CAPTCHA em documentação interna, pois o frame o serviço como parte de um fluxo mais amplo, em vez de um atalho isolado.
Erros comuns a evitar
Projetos de captcha em raspagem de web frequentemente falham quando as equipes tratam o tratamento de desafios como um complemento separado. Um token retornado por uma API só é útil se ele se encaixar no estado do navegador, página-alvo, ação e janela de tempo. Outro erro comum é o retry ilimitado. Se uma tarefa falhar repetidamente, a resposta correta é inspecionar parâmetros, permissão e sinais do site, não aumentar a carga.
As equipes também devem evitar armazenar segredos em scripts de raspagem, compartilhar chaves de API entre ambientes ou enviar tarefas de desafio para domínios fora da lista de permissões aprovada. Use configuração central, armazenamento de segredos e logs por nível de trabalho. Se seu fluxo usar uma API, a documentação da API da CapSolver e o guia getTaskResult devem permanecer como a verdadeira fonte para o comportamento dos pontos finais.
Conclusão/CTA
O tratamento de captcha em raspagem de web é mais seguro quando projetado como um fluxo controlado: permissão primeiro, higiene de solicitação em segundo, detecção de desafio em terceiro e integração de API apenas onde for permitido. A configuração correta mantém o contexto do navegador estável, trata tokens como artefatos de curta duração, registra todos os resultados e para quando o acesso não é autorizado. Se sua equipe precisar de tratamento de desafio documentado para raspagem, QA ou monitoramento aprovado, comece com um pequeno fluxo de teste usando CapSolver.
Perguntas Frequentes
O que significa captcha de raspagem de web?
Captcha de raspagem de web significa que um raspador encontra um desafio de validação de tráfego ao coletar dados. A resposta correta depende de permissão, tipo de desafio, limites de taxa e regras de acesso do site.
O captcha de raspagem de web pode ser tratado com uma API?
Sim, em fluxos aprovados, uma API pode criar uma tarefa de desafio e retornar uma solução por meio de um ponto final de resultado documentado. Para uma visão geral geral, veja como serviços de raspagem e resolução de CAPTCHA fornecem uma API.
Por que raspadores do Selenium e Puppeteer veem verificações de CAPTCHA?
O Selenium e Puppeteer podem gerar padrões de navegador que os sites revisam durante a validação de tráfego, especialmente em altas taxas de solicitação ou com sessões instáveis. Padronizar automação web do Selenium ou configurações do Puppeteer ajuda a reduzir inconsistências evitáveis.
Como os proxies devem ser usados em um fluxo de captcha de raspagem de web?
Use proxies apenas onde for legal e permitido, e mantenha a identidade do proxy consistente entre a sessão do navegador e a tarefa de desafio. O objetivo é um contexto estável, não uma alta volume de solicitações.
O tratamento de captcha de raspagem de web é legal para qualquer site público?
Não. Visibilidade pública não cria automaticamente permissão para coleta automatizada. Revise os termos do site, orientações de robots, contratos, requisitos de privacidade, sensibilidade de dados e limites de taxa antes de executar qualquer raspador.
Ver mais
Web ScrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.
Web ScrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

