Como os Agentes de IA lidam com CAPTCHAs em grande escala

Adélia Cruz
Neural Network Developer
Resumo
- Agentes de IA exigem infraestrutura robusta para lidar com CAPTCHAs em larga escala durante operações web automatizadas.
- Sistemas modernos de validação de tráfego usam análise comportamental e fingerprinting de dispositivos para detectar solicitações automatizadas.
- Integrar uma API confiável de resolução de CAPTCHA garante operação contínua para agentes autônomos.
- Arquiteturas distribuídas e rotação de proxies são essenciais para gerenciar desafios de controle de risco em alta volume.
- Conformidade ética e políticas de uso responsável devem orientar todos os esforços de coleta de dados automatizados.
Introdução
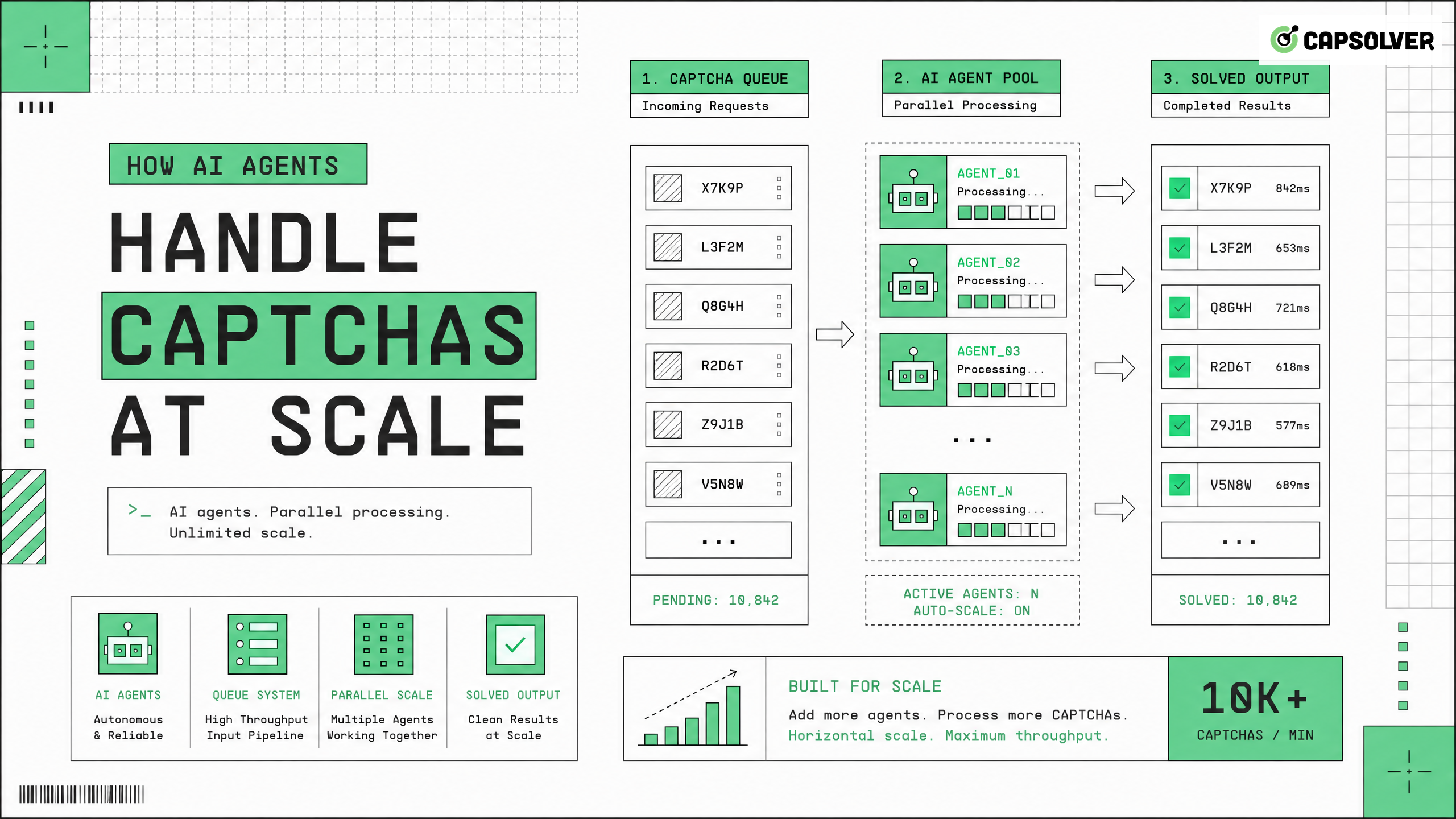
Sistemas autônomos devem lidar com CAPTCHAs em larga escala de forma eficiente para manter operações web contínuas. À medida que os sites implementam medidas de validação de tráfego mais rigorosas, scripts de automação tradicionais frequentemente falham ao encontrar desafios complexos de controle de risco. Agentes de IA resolvem esse problema integrando infraestrutura especializada projetada para processar esses desafios automaticamente. CapSolver fornece os pontos finais de API e modelos de aprendizado de máquina necessários para processar solicitações em grande volume de forma confiável. Ao delegar o processo de validação para um serviço dedicado, os desenvolvedores podem se concentrar na lógica do agente principal em vez de manter pilhas complexas de automação de navegador. Essa abordagem garante altas taxas de sucesso, ao mesmo tempo em que segue os limites de taxa dos sites-alvo e diretrizes de uso responsável.
A Evolução da Validação de Tráfego
Sistemas de segurança da web evoluíram da reconhecimento de texto simples para análise comportamental complexa. Sistemas antigos de CAPTCHA dependiam de texto distorcido, que o reconhecimento óptico de caracteres (OCR) podia processar facilmente. Hoje, plataformas de controle de risco avaliam movimentos do mouse, impressões digitais do navegador e reputação da rede para diferenciar usuários humanos de scripts automatizados.
Quando agentes de IA lidam com CAPTCHAs em larga escala, eles devem navegar por essas camadas de validação avançadas. Desafios modernos frequentemente exigem a execução de JavaScript, renderização de imagens complexas ou resolução de quebra-cabeças espaciais. Essa complexidade exige recursos computacionais significativos e algoritmos especializados. Para desenvolvedores que constroem sistemas autônomos, gerenciar essa infraestrutura internamente torna-se uma grande carga de engenharia.
Para entender os mecanismos subjacentes, pesquisadores frequentemente se referem às diretrizes da W3C sobre alternativas de CAPTCHA, que detalham as implicações de acessibilidade e segurança dos testes de Turing automatizados.
Infraestrutura Essencial para Agentes Autônomos
Construir a infraestrutura certa é crítico para sistemas que lidam com CAPTCHAs em larga escala. Uma arquitetura eficaz separa a lógica do agente principal da camada de processamento de validação. Essa separação de responsabilidades permite que cada componente escale independentemente com base nas demandas de trabalho.
Gestão de Navegadores Headless
Agentes de IA frequentemente dependem de navegadores headless para interagir com aplicações web modernas. Esses navegadores devem ser configurados cuidadosamente para evitar detecção por sistemas de controle de risco. Gestão adequada inclui rotação de agentes de usuário, modificação de propriedades do navegador e tratamento de fingerprinting de canvas. Você pode aprender mais sobre o que é detecção de navegador headless e como evitá-la em nosso guia detalhado.
Redes de Proxies e Reputação de IP
A reputação da rede desempenha um papel crucial na validação de tráfego. Quando sistemas lidam com CAPTCHAs em larga escala, eles devem distribuir solicitações por endereços IP diversos para evitar limites de taxa. Proxies de residência ou móveis de alta qualidade fornecem a reputação necessária para passar nas primeiras verificações de segurança. Combinar rotação de proxies com uma API de resolução de CAPTCHA para agentes autônomos cria uma pilha de automação resistente.
Processamento Assíncrono
Desafios de validação introduzem latência variável nos fluxos automatizados. Um desafio pode levar de alguns segundos a mais de um minuto para ser resolvido. Agentes devem implementar padrões de processamento assíncrono para lidar com essa latência sem bloquear outras operações. Filas de mensagens e arquiteturas orientadas a eventos são soluções padrão para gerenciar esses fluxos assíncronos.
Técnicas Avançadas para Validação de Tráfego
À medida que os sistemas de controle de risco se tornam mais sofisticados, as técnicas usadas para processá-los também devem avançar. Quando organizações lidam com CAPTCHAs em larga escala, elas empregam uma variedade de métodos avançados para garantir altas taxas de sucesso.
Simulação de Comportamento
Alguns sistemas de validação monitoram como um usuário interage com a página. Para passar nesses testes, os agentes devem simular comportamento humano, incluindo movimentos do mouse realistas, velocidades de digitação variadas e padrões naturais de rolagem. Implementar essas simulações requer compreensão aprofundada de métricas de interação humano-computador. O último estudo sobre biométrica comportamental destaca a crescente sofisticação desses mecanismos de detecção.
Mitigação do Fingerprinting de Dispositivo
Plataformas de controle de risco coletam dados extensos sobre o dispositivo cliente, incluindo resolução de tela, fontes instaladas e concorrência de hardware. Para lidar com CAPTCHAs em larga escala, os agentes devem apresentar impressões digitais de dispositivos consistentes e realistas. Isso envolve a injeção de scripts personalizados no ambiente do navegador para substituir propriedades padrão e apresentar um perfil unificado.
Resgate do Código de Bônus do CapSolver
Aumente seu orçamento de automação instantaneamente!
Use o código de bônus CAP26 ao recarregar sua conta do CapSolver para obter um bônus adicional de 5% em cada recarga — sem limites.
Resgate-o agora em seu Painel do CapSolver

Integração de Modelos de Aprendizado de Máquina
Agentes avançados de IA lidam com CAPTCHAs em larga escala utilizando modelos de aprendizado de máquina especializados. Esses modelos são treinados em grandes conjuntos de dados de desafios de validação, permitindo que reconheçam padrões e resolvam quebra-cabeças com alta precisão.
Visão Computacional para Desafios de Imagem
Desafios baseados em imagem exigem algoritmos avançados de visão computacional. Modelos de detecção de objetos identificam itens específicos em uma grade, enquanto modelos de segmentação delimitam formas complexas. Treinar esses modelos requer atualizações contínuas para se adaptar aos novos tipos de desafios introduzidos pelos provedores de controle de risco.
Processamento de Desafios de Áudio
Por razões de acessibilidade, muitos sistemas de validação oferecem alternativas de áudio. Agentes podem lidar com CAPTCHAs em larga escala processando esses arquivos de áudio usando modelos de reconhecimento de fala. Essa abordagem frequentemente fornece um caminho mais confiável quando desafios visuais tornam-se muito complexos. O avaliações de reconhecimento de fala da NIST fornecem benchmarks para a precisão desses modelos.
Para uma visão geral completa dos componentes necessários, revise a pilha de infraestrutura de automação web para agentes de IA.
Gerenciamento de Operações em Grande Volume
Quando organizações precisam lidar com CAPTCHAs em larga escala, a eficiência operacional torna-se primordial. Processar milhares de solicitações por minuto exige tratamento de erros robusto, lógica de repetição e monitoramento de desempenho.
Tratamento de Erros e Reinícios
Desafios de validação podem falhar por diversos motivos, incluindo timeout de rede, bloqueios de proxy ou imprecisões de modelo. Agentes devem implementar mecanismos de repetição inteligentes com backoff exponencial para gerenciar essas falhas de forma elegante. É essencial distinguir entre problemas temporários de rede e bloqueios permanentes para otimizar o uso de recursos.
Monitoramento de Desempenho
Monitorar a taxa de sucesso e a latência do processamento de validação é crítico. Dashboards devem rastrear métricas como tempo médio de resolução, taxas de erro por tipo de desafio e desempenho de proxies. Esses dados permitem que equipes de engenharia identifiquem gargalos e otimizem sua infraestrutura. Escolher um solucionador de CAPTCHA para infraestrutura de agente 2026 requer avaliação cuidadosa dessas métricas de desempenho.
O Papel de APIs em Sistemas Autônomos
APIs fornecem a conexão que permite aos agentes interagirem com serviços externos. Quando sistemas lidam com CAPTCHAs em larga escala, eles dependem de APIs especializadas para transferir a carga computacional do processamento de validação.
APIs Síncronas vs. Assíncronas
APIs de validação podem ser síncronas ou assíncronas. APIs síncronas bloqueiam o agente até que o desafio seja resolvido, o que pode levar a gargalos de desempenho. APIs assíncronas permitem que o agente submeta um desafio e verifique o resultado posteriormente, melhorando o throughput geral.
Limitação de Taxa e Quotas de API
Quando agentes lidam com CAPTCHAs em larga escala, eles devem gerenciar cuidadosamente as limitações de taxa e quotas de API. Exceder esses limites pode resultar em bloqueios temporários ou desempenho reduzido. Implementar algoritmos de balde de tokens e fila de solicitações ajuda a garantir conformidade com as políticas de uso de API. Para mais detalhes, consulte nosso guia sobre infraestrutura de resolução de CAPTCHA para agentes de IA.
Escalando Fluxos de Coleta de Dados
A coleta de dados é um caso de uso principal para agentes autônomos. À medida que o volume de dados aumenta, os sistemas devem escalar adequadamente. Quando agentes lidam com CAPTCHAs em larga escala, eles permitem que organizações coletem inteligência competitiva, monitorem tendências do mercado e agreguem informações públicas de forma eficiente.
Arquiteturas de Rastreamento Distribuído
Para processar milhões de páginas, os agentes são frequentemente implantados em clusters distribuídos. Cada nó no cluster opera de forma independente, buscando páginas e processando desafios de validação conforme necessário. Essa abordagem distribuída garante que o sistema possa lidar com CAPTCHAs em larga escala sem criar um único ponto de falha.
Normalização e Armazenamento de Dados
Uma vez que os dados são coletados, eles devem ser normalizados e armazenados para análise. Agentes frequentemente integram pipelines de dados que limpam e estruturam o HTML bruto antes de inseri-lo em um banco de dados. Essa pipeline deve ser resistente a interrupções causadas por desafios de validação.
Considerações de Segurança para Infraestrutura de Agente
Segurança é uma preocupação crítica ao implantar agentes autônomos. Sistemas que lidam com CAPTCHAs em larga escala devem proteger credenciais sensíveis, chaves de API e configurações de proxy contra acesso não autorizado.
Gerenciamento de Credenciais
Agentes nunca devem codificar credenciais em seu código-fonte. Em vez disso, devem usar sistemas de gerenciamento de segredos seguros para recuperar chaves de API e senhas de proxy em tempo de execução. Essa prática minimiza o risco de exposição de credenciais se o código-fonte for comprometido.
Segurança de Rede
A comunicação entre o agente e a API de validação deve ser criptografada usando TLS. Essa criptografia evita ataques de intermediário e garante a integridade dos tokens de validação. As organizações também devem monitorar seu tráfego de rede em busca de anomalias que possam indicar uma violação de segurança.
Comparação de Abordagens de Processamento de Validação
| Abordagem | Escalabilidade | Carga de Manutenção | Taxa de Sucesso | Melhor Caso de Uso |
|---|---|---|---|---|
| Modelos de ML Internos | Alta | Muito Alta | Variável | Desafios especializados, proprietários |
| Equipes de Resolução Manual | Baixa | Alta | Alta | Tarefas de baixo volume, altamente complexas |
| Serviços Automatizados de API | Muito Alta | Baixa | Muito Alta | Desafios de alto volume, padrão |
| Extensões de Navegador | Baixa | Média | Média | Automação de desktop, testes |
Conformidade e Uso Responsável
A coleta de dados automatizada deve sempre seguir padrões legais e éticos. Quando sistemas lidam com CAPTCHAs em larga escala, eles interagem com infraestrutura de terceiros que possui termos de serviço específicos. Organizações devem garantir que suas práticas de automação estejam em conformidade com regulamentações relevantes, como o GDPR e o CCPA.
Uso responsável inclui respeitar diretrizes de robots.txt, implementar limites de taxa razoáveis e evitar interrupções no serviço-alvo. O guia da Electronic Frontier Foundation sobre acesso automatizado fornece contexto valioso para manter padrões éticos na coleta de dados. Para mais informações sobre a construção de sistemas conformes, explore nosso guia sobre infraestrutura de proteção contra bots para agentes de IA.
Tendências Futuras na Validação de Tráfego
O cenário de segurança da web está em constante evolução. À medida que agentes de IA se tornam mais sofisticados, os sistemas de controle de risco se adaptarão para detectá-los. Organizações que lidam com CAPTCHAs em larga escala devem se manter à frente dessas tendências para manter operações contínuas.
Arquiteturas de Confiança Zero
Arquiteturas de confiança zero assumem que todo tráfego é potencialmente malicioso. Esses sistemas exigem validação contínua durante a sessão do usuário, em vez de uma verificação única no login. Agentes precisarão se adaptar a esses modelos de validação contínua para manter o acesso.
Validação com Preservação de Privacidade
Novos métodos de validação estão surgindo que priorizam a privacidade do usuário. Esses métodos usam provas criptográficas para verificar a interação humana sem coletar dados sensíveis. À medida que essas tecnologias amadurecem, os agentes precisarão integrar novos protocolos para lidar com CAPTCHAs em larga escala. O especificações da IETF sobre passes privados estabelecem as bases técnicas para esses novos mecanismos de validação.
Conclusão
Construir sistemas que lidem de forma eficiente com CAPTCHAs em larga escala é essencial para a automação web moderna. Ao separar o processamento de validação da lógica do agente principal e utilizar APIs especializadas, os desenvolvedores podem obter altas taxas de sucesso e manter operações contínuas. Implementar tratamento de erros robusto, gerenciamento de proxies e processamento assíncrono garante que sistemas autônomos possam navegar em ambientes de controle de risco complexos de forma confiável. Para processamento de validação de nível corporativo, CapSolver oferece a infraestrutura e capacidades de aprendizado de máquina necessárias para suportar implantações em larga escala de agentes de IA.
Perguntas Frequentes
Qual é a maneira mais eficiente de processar desafios de validação?
Usar um serviço de API dedicado é geralmente a abordagem mais eficiente. Ele transfere a carga computacional e os requisitos de manutenção para infraestrutura especializada, permitindo que seus agentes se concentrem em suas tarefas principais.
Como as redes de proxies afetam as taxas de sucesso da validação?
Redes de proxies são críticas para distribuir solicitações e manter uma boa reputação de IP. Proxies residenciais de alta qualidade reduzem a probabilidade de disparar medidas avançadas de controle de risco, melhorando assim as taxas de sucesso gerais.
Sistemas autônomos podem simular comportamento humano?
Sim, sistemas avançados podem simular movimentos do mouse, padrões de digitação e comportamento de rolagem semelhantes aos humanos. Essa simulação é frequentemente necessária para passar por verificações de análise comportamental implementadas por plataformas de segurança modernas.
Quais são as considerações legais para operações web automatizadas?
Operações automatizadas devem seguir regulamentações de privacidade de dados, termos de serviço e leis de direitos autorais. É essencial implementar práticas responsáveis de raspagem, respeitar os limites de taxa e evitar causar danos à infraestrutura alvo.
Como modelos de aprendizado de máquina resolvem desafios de imagens?
Modelos de aprendizado de máquina usam técnicas de visão computacional, como detecção de objetos e segmentação de imagens, para analisar e resolver enigmas visuais. Esses modelos são treinados continuamente com novos dados para manter alta precisão contra tipos de desafios em evolução.
Ver mais
AIJun 26, 2026
CAPTCHA: O Componente Faltante na Infraestrutura de Agentes de IA
Descubra por que o tratamento da validação de tráfego é o componente ausente na infraestrutura de agentes de IA. Aprenda como integrar soluções robustas para agentes autônomos.
AIJun 26, 2026
Incorporando Resiliência de CAPTCHA em Agentes de IA
- Agentes de IA requerem resiliência CAPTCHA robusta para manter a operação contínua durante tarefas automatizadas. - Implementar estratégias de validação de tráfego estruturado minimiza interrupções causadas por mecanismos de controle de risco. - Utilizar uma API de resolução CAPTCHA confiável garante o tratamento eficiente de desafios complexos. - Um projeto de infraestrutura adequado separa a lógica do agente principal da gestão de proteção contra bots.