MaxunでCapSolver統合を使用してCaptchaを解決する方法

Sora Fujimoto
AI Solutions Architect

ウェブデータ抽出において、Maxunは、チームがウェブからデータを収集するのを簡素化するオープンソースでノーコードのプラットフォームとして注目を集めています。ロボットベースのワークフローとSDKにより、開発者や非技術者でも、大きなエンジニアリング作業なしに、スクレイピングパイプラインを構築および維持することが可能です。
ただし、現実世界の多くのウェブサイトはCAPTCHAで保護されており、データ抽出中に主なボトルネックとなることがよくあります。CapSolverは、インフラレベルでこれらの課題を処理することでMaxunと効果的に連携します。CapSolverを導入することで、MaxunロボットはCAPTCHA保護ページでより信頼性高く動作し、使いやすさと実用的なプロダクション対応のスクレイピング機能を組み合わせることができます。
Maxunとは何ですか?
Maxun は、コードを書かずにウェブサイトからデータを抽出できるオープンソースでノーコードのプラットフォームです。視覚的なロボットビルダー、プログラマティックコントロール用の強力なSDK、クラウドおよびセルフホストドのデプロイメントをサポートしています。
Maxunの主な特徴
- ノーコードロボットビルダー: プログラミングなしで抽出ロボットをトレーニングするためのビジュアルインターフェース
- 強力なSDK: TypeScript/Node.js SDKでロボットのプログラム的実行
- 複数の抽出モード: 抽出、スクレイピング、クロール、検索の機能
- インテリジェントセレクター: 自動的な要素検出とスマートセレクター生成
- クラウドとセルフホストド: Maxunクラウドまたは自前のインフラストラクチャにデプロイ
- プロキシサポート: 内蔵のプロキシローテーションと管理
- スケジュール実行: クロンベースのスケジューリングでロボットの実行を自動化
コアSDKクラス
| クラス | 説明 |
|---|---|
| Extract | LLMまたはCSSセレクターを使用して構造化されたデータ抽出ワークフローを構築 |
| Scrape | ページをクリーンなMarkdown、HTML、またはスクリーンショットに変換 |
| Crawl | サイトマップとリンクを使用して複数のページを自動的に発見およびスクレイピング |
| Search | デッカデッゴで結果からコンテンツを抽出するウェブ検索を実行 |
Maxunの違い
Maxunはノーコードのシンプルさと開発者の柔軟性の間の橋渡しを行います:
- ビジュアル + コード: ロボットをビジュアルでトレーニングし、SDKを介してプログラム的に制御
- ロボットベースのアーキテクチャ: 再利用可能で共有可能な抽出テンプレート
- TypeScriptネイティブ: 現代のNode.jsアプリケーションに最適化
- オープンソース: 完全な透明性とコミュニティ駆動の開発
CapSolverとは何ですか?
CapSolver は、さまざまなCAPTCHAチャレンジを回避するためのAI駆動のソリューションを提供するリーディングCAPTCHA解決サービスです。複数のCAPTCHAタイプをサポートし、高速な応答時間を提供し、自動化ワークフローにシームレスに統合されます。
サポートされているCAPTCHAタイプ
CapSolverは、ウェブスクレイピングやブラウザ自動化中に一般的に遭遇する主流のCAPTCHAおよび検証チャレンジを処理する自動化ワークフローを支援します。以下が含まれます:
- reCAPTCHA v2 (画像ベースおよび非表示)
- reCAPTCHA v3 & v3 Enterprise
- Cloudflare Turnstile
- Cloudflare 5秒チャレンジ
- AWS WAF CAPTCHA
- その他の広く使用されているCAPTCHAおよびアンチボットメカニズム
MaxunにCapSolverを統合する理由
Maxunロボットを保護されたウェブサイトと連携させ、データ抽出、価格モニタリング、または市場調査のために構築する際、CAPTCHAチャレンジは大きな障害となります。統合が重要な理由は以下の通りです:
- 中断しないデータ抽出: ロボットが手動の介入なしでミッションを完了できます
- スケーラブルな運用: 複数の同時実行ロボットでCAPTCHAチャレンジを処理
- シームレスなワークフロー: 抽出パイプラインの一部としてCAPTCHAを解決
- コスト効率: 成功したCAPTCHAの解決のみを支払う
- 高成功率: すべてのサポートされているCAPTCHAタイプの業界リーディングの正確性
インストール
前提条件
- Node.js 18以上
- npmまたはyarn
- CapSolver APIキー

Maxun SDKのインストール
bash
# Maxun SDKをインストール
npm install maxun-sdk
# CapSolver統合の追加依存関係をインストール
npm install axiosDockerインストール(セルフホストド Maxun)
bash
# Maxunリポジトリをクローン
git clone https://github.com/getmaxun/maxun.git
cd maxun
# Docker Composeで起動
docker-compose up -d環境設定
設定ファイル.envを作成してください:
env
CAPSOLVER_API_KEY=your_capsolver_api_key
MAXUN_API_KEY=your_maxun_api_key
# Maxun Cloud (app.maxun.dev)
MAXUN_BASE_URL=https://app.maxun.dev/api/sdk
# セルフホストド Maxun (デフォルト)
# MAXUN_BASE_URL=http://localhost:8080/api/sdk注意: Maxun Cloudを使用する場合、
baseUrlの構成は必須です。セルフホストドインストールではデフォルトでhttp://localhost:8080/api/sdkが使用されます。
Maxun用のCapSolverサービスの作成
以下は、MaxunとCapSolverを統合する再利用可能なTypeScriptサービスです。
基本的なCapSolverサービス
typescript
import axios, { AxiosInstance } from 'axios';
interface TaskResult {
gRecaptchaResponse?: string;
token?: string;
cookies?: Array<{ name: string; value: string }>;
userAgent?: string;
}
interface CapSolverConfig {
apiKey: string;
timeout?: number;
maxAttempts?: number;
}
class CapSolverService {
private client: AxiosInstance;
private apiKey: string;
private maxAttempts: number;
constructor(config: CapSolverConfig) {
this.apiKey = config.apiKey;
this.maxAttempts = config.maxAttempts || 60;
this.client = axios.create({
baseURL: 'https://api.capsolver.com',
timeout: config.timeout || 30000,
headers: { 'Content-Type': 'application/json' },
});
}
private async createTask(taskData: Record<string, unknown>): Promise<string> {
const response = await this.client.post('/createTask', {
clientKey: this.apiKey,
task: taskData,
});
if (response.data.errorId !== 0) {
throw new Error(`CapSolver error: ${response.data.errorDescription}`);
}
return response.data.taskId;
}
private async getTaskResult(taskId: string): Promise<TaskResult> {
for (let attempt = 0; attempt < this.maxAttempts; attempt++) {
await this.delay(2000);
const response = await this.client.post('/getTaskResult', {
clientKey: this.apiKey,
taskId,
});
const { status, solution, errorDescription } = response.data;
if (status === 'ready') {
return solution as TaskResult;
}
if (status === 'failed') {
throw new Error(`Task failed: ${errorDescription}`);
}
}
throw new Error('Timeout waiting for CAPTCHA solution');
}
private delay(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
async solveReCaptchaV2(websiteUrl: string, websiteKey: string): Promise<string> {
const taskId = await this.createTask({
type: 'ReCaptchaV2TaskProxyLess',
websiteURL: websiteUrl,
websiteKey,
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse || '';
}
async solveReCaptchaV3(
websiteUrl: string,
websiteKey: string,
pageAction: string = 'submit'
): Promise<string> {
const taskId = await this.createTask({
type: 'ReCaptchaV3TaskProxyLess',
websiteURL: websiteUrl,
websiteKey,
pageAction,
});
const solution = await this.getTaskResult(taskId);
return solution.gRecaptchaResponse || '';
}
async solveTurnstile(
websiteUrl: string,
websiteKey: string,
action?: string,
cdata?: string
): Promise<string> {
const taskData: Record<string, unknown> = {
type: 'AntiTurnstileTaskProxyLess',
websiteURL: websiteUrl,
websiteKey,
};
// オプショナルメタデータを追加
if (action || cdata) {
taskData.metadata = {};
if (action) (taskData.metadata as Record<string, string>).action = action;
if (cdata) (taskData.metadata as Record<string, string>).cdata = cdata;
}
const taskId = await this.createTask(taskData);
const solution = await this.getTaskResult(taskId);
return solution.token || '';
}
async checkBalance(): Promise<number> {
const response = await this.client.post('/getBalance', {
clientKey: this.apiKey,
});
return response.data.balance || 0;
}
}
export { CapSolverService, CapSolverConfig, TaskResult };★ インサイト ─────────────────────────────────────
CapSolverサービスは、CAPTCHA解決が非同期であるためポーリングパターン(getTaskResult)を使用しています。APIはタスクを受信し、サーバーで処理し、準備ができたら結果を返します。ポール間の2秒の遅延は、応答性とAPIレートリミットのバランスを取っています。
─────────────────────────────────────────────────
異なるCAPTCHAタイプの解決
MaxunでのreCAPTCHA v2の解決
Maxunはブラウザ自動化よりも高レベルで動作するため、ロボットの実行前または実行中にCAPTCHAを解決するアプローチが焦点になります:
typescript
import { Extract } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY!;
const MAXUN_API_KEY = process.env.MAXUN_API_KEY!;
const MAXUN_BASE_URL = process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk';
const capSolver = new CapSolverService({ apiKey: CAPSOLVER_API_KEY });
const extractor = new Extract({
apiKey: MAXUN_API_KEY,
baseUrl: MAXUN_BASE_URL,
});
async function extractWithRecaptchaV2() {
const targetUrl = 'https://example.com/protected-page';
const recaptchaSiteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC';
console.log('reCAPTCHA v2を解決中...');
// まずCAPTCHAを解決
const token = await capSolver.solveReCaptchaV2(targetUrl, recaptchaSiteKey);
console.log('CAPTCHAが解決されました。抽出ロボットを作成中...');
// メソッドチェーンを使用してロボットを作成
const robot = await extractor
.create('製品抽出ロボット')
.navigate(targetUrl)
.type('#g-recaptcha-response', token)
.click('button[type="submit"]')
.wait(2000)
.captureList({ selector: '.product-item' });
// ロボットを実行
const result = await robot.run({ timeout: 30000 });
console.log('抽出完了:', result.data);
return result.data;
}
extractWithRecaptchaV2().catch(console.error);MaxunでのreCAPTCHA v3の解決
typescript
import { Extract } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY!;
const MAXUN_API_KEY = process.env.MAXUN_API_KEY!;
const MAXUN_BASE_URL = process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk';
const capSolver = new CapSolverService({ apiKey: CAPSOLVER_API_KEY });
const extractor = new Extract({
apiKey: MAXUN_API_KEY,
baseUrl: MAXUN_BASE_URL,
});
async function extractWithRecaptchaV3() {
const targetUrl = 'https://example.com/v3-protected';
const recaptchaSiteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxDEF';
console.log('reCAPTCHA v3を高スコアで解決中...');
// カスタムページアクションで解決
const token = await capSolver.solveReCaptchaV3(
targetUrl,
recaptchaSiteKey,
'submit' // pageAction
);
console.log('高スコアのトークンを取得しました。ロボットを作成中...');
// メソッドチェーンを使用して抽出ロボットを作成
const robot = await extractor
.create('V3保護抽出ロボット')
.navigate(targetUrl)
.type('input[name="g-recaptcha-response"]', token)
.click('#submit-btn')
.wait(2000)
.captureText({ resultData: '.result-data' });
const result = await robot.run({ timeout: 30000 });
console.log('データ抽出完了:', result.data);
return result.data;
}
extractWithRecaptchaV3().catch(console.error);MaxunでのCloudflare Turnstileの解決
typescript
import { Scrape } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const CAPSOLVER_API_KEY = process.env.CAPSOLVER_API_KEY!;
const MAXUN_API_KEY = process.env.MAXUN_API_KEY!;
const MAXUN_BASE_URL = process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk';
const capSolver = new CapSolverService({ apiKey: CAPSOLVER_API_KEY });
const scraper = new Scrape({
apiKey: MAXUN_API_KEY,
baseUrl: MAXUN_BASE_URL,
});
async function extractWithTurnstile() {
const targetUrl = 'https://example.com/turnstile-protected';
const turnstileSiteKey = '0x4xxxxxxxxxxxxxxxxxxxxxxxxxxxxGHI';
console.log('Cloudflare Turnstileを解決中...');
// オプショナルメタデータ(アクションとcdata)で解決
const token = await capSolver.solveTurnstile(
targetUrl,
turnstileSiteKey,
'login', // オプショナルアクション
'0000-1111-2222-3333-example-cdata' // オプショナルcdata
);
console.log('Turnstileが解決されました。スクレイプロボットを作成中...');
// サクセスロボットを作成 - Turnstileの場合、通常は最初にトークンをPOSTリクエストで送信する必要があります
const robot = await scraper.create('turnstile-scraper', targetUrl, {
formats: ['markdown', 'html'],
});
const result = await robot.run({ timeout: 30000 });
console.log('抽出完了');
console.log('Markdown:', result.data.markdown?.substring(0, 500));
return result.data;
}
extractWithTurnstile().catch(console.error);Maxunワークフローとの統合
Extractクラスとの使用
Extractクラスは、特定のページ要素から構造化されたデータを取得するために使用されます。LLM駆動の抽出(自然言語プロンプトを使用)と非LLM抽出(CSSセレクターを使用)の両方をサポートしています:
typescript
import { Extract } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const extractor = new Extract({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface ProductData {
name: string;
price: string;
rating: string;
}
async function extractProductsWithCaptcha(): Promise<ProductData[]> {
const targetUrl = 'https://example.com/products';
const siteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC';
// Pre-solve CAPTCHA
const captchaToken = await capSolver.solveReCaptchaV2(targetUrl, siteKey);
console.log('CAPTCHA solved, creating extraction robot...');
// Create extraction robot using method chaining
const robot = await extractor
.create('Product Extractor')
.navigate(targetUrl)
.type('#g-recaptcha-response', captchaToken)
.click('button[type="submit"]')
.wait(3000)
.captureList({
selector: '.product-card',
pagination: { type: 'clickNext', selector: '.next-page' },
maxItems: 50,
});
// Run the extraction
const result = await robot.run({ timeout: 60000 });
return result.data.listData as ProductData[];
}
extractProductsWithCaptcha()
.then((products) => {
products.forEach((product) => {
console.log(`${product.name}: ${product.price}`);
});
})
.catch(console.error);★ インサイト ─────────────────────────────────────
MaxunのExtractクラスのcaptureListメソッドは、リスト項目内のフィールドを自動的に検出し、ページネーションを処理します。ページネーションタイプ(scrollDown、clickNext、またはclickLoadMore)を指定すると、ロボットは指定された制限に達するか、ページがなくなるまで抽出を続けます。
─────────────────────────────────────────────────
Scrapeクラスとの使用方法
Scrapeクラスは、ウェブページをクリーンなHTML、LLM対応のMarkdown、またはスクリーンショットに変換します:
typescript
import { Scrape } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
import axios from 'axios';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const scraper = new Scrape({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface ScrapeResult {
url: string;
markdown?: string;
html?: string;
captchaSolved: boolean;
}
async function scrapeWithCaptchaHandling(): Promise<ScrapeResult[]> {
const urls = [
'https://example.com/page1',
'https://example.com/page2',
'https://example.com/page3',
];
const results: ScrapeResult[] = [];
for (const url of urls) {
try {
// CAPTCHA保護ページの場合、まずCAPTCHAを解決し、セッションを確立します
const siteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC'; // 必要に応じて動的に取得
console.log(`${url}のCAPTCHAを解決中...`);
const captchaToken = await capSolver.solveReCaptchaV2(url, siteKey);
// CAPTCHAを送信してセッションクッキーを取得
const verifyResponse = await axios.post(`${url}/verify`, {
'g-recaptcha-response': captchaToken,
});
// 認証されたページ用のスクレイプロボットを作成
const robot = await scraper.create(`scraper-${Date.now()}`, url, {
formats: ['markdown', 'html'],
});
const result = await robot.run({ timeout: 30000 });
results.push({
url,
markdown: result.data.markdown,
html: result.data.html,
captchaSolved: true,
});
// 使用後はロボットを削除
await robot.delete();
} catch (error) {
console.error(`${url}のスクレイプに失敗しました:`, error);
results.push({ url, captchaSolved: false });
}
}
return results;
}
scrapeWithCaptchaHandling().then(console.log).catch(console.error);Crawlクラスとの使用方法
Crawlクラスは、サイトマップやリンクのたどりにより複数のページを自動的に発見してスクレイプします:
typescript
import { Crawl } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
import axios from 'axios';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const crawler = new Crawl({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface PageResult {
url: string;
title: string;
text: string;
wordCount: number;
}
async function crawlWithCaptchaProtection(): Promise<PageResult[]> {
const startUrl = 'https://example.com';
const siteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC';
// ドメインアクセス用のCAPTCHAを事前に解決
console.log('ドメインアクセス用のCAPTCHAを解決中...');
const captchaToken = await capSolver.solveReCaptchaV2(startUrl, siteKey);
// CAPTCHAを送信してセッションを確立(サイト固有の処理)
await axios.post(`${startUrl}/verify`, {
'g-recaptcha-response': captchaToken,
});
// ドメインスコープの設定でクロールロボットを作成
const robot = await crawler.create('site-crawler', startUrl, {
mode: 'domain', // クロール範囲: 'domain', 'subdomain', 'path'
limit: 50, // クロールするページの最大数
maxDepth: 3, // リンクをたどる深さ
useSitemap: true, // sitemap.xmlを解析してURLを取得
followLinks: true, // ページ内のリンクを抽出してたどる
includePaths: ['/blog/', '/docs/'], // 結合する正規表現パターン
excludePaths: ['/admin/', '/login/'], // 排除する正規表現パターン
respectRobots: true, // robots.txtを尊重
});
// クロールを実行
const result = await robot.run({ timeout: 120000 });
// 結果の各ページには: メタデータ、html、text、wordCount、リンクが含まれます
return result.data.crawlData.map((page: any) => ({
url: page.metadata.url,
title: page.metadata.title,
text: page.text,
wordCount: page.wordCount,
}));
}
crawlWithCaptchaProtection()
.then((pages) => {
console.log(`クロール済みページ数: ${pages.length}`);
pages.forEach((page) => {
console.log(`- ${page.title}: ${page.url} (${page.wordCount}語)`);
});
})
.catch(console.error);事前認証パターン
コンテンツにアクセスする前にCAPTCHAが必要なサイトの場合、事前認証ワークフローを使用します:
typescript
import axios from 'axios';
import { Extract } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const extractor = new Extract({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface SessionCookies {
name: string;
value: string;
domain: string;
}
async function preAuthenticateWithCaptcha(
loginUrl: string,
siteKey: string
): Promise<SessionCookies[]> {
// ステップ1: CAPTCHAを解決
const captchaToken = await capSolver.solveReCaptchaV2(loginUrl, siteKey);
// ステップ2: CAPTCHAトークンを送信してセッションクッキーを取得
const response = await axios.post(
loginUrl,
{
'g-recaptcha-response': captchaToken,
},
{
withCredentials: true,
maxRedirects: 0,
validateStatus: (status) => status < 400,
}
);
// ステップ3: 応答からクッキーを抽出
const setCookies = response.headers['set-cookie'] || [];
const cookies: SessionCookies[] = setCookies.map((cookie: string) => {
const [nameValue] = cookie.split(';');
const [name, value] = nameValue.split('=');
return {
name: name.trim(),
value: value.trim(),
domain: new URL(loginUrl).hostname,
};
});
return cookies;
}
async function extractWithPreAuth() {
const loginUrl = 'https://example.com/verify';
const targetUrl = 'https://example.com/protected-data';
const siteKey = '6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC';
// セッションクッキーを取得するために事前認証
const sessionCookies = await preAuthenticateWithCaptcha(loginUrl, siteKey);
console.log('セッションを確立しました。抽出ロボットを作成しています...');
// 抽出ロボットを作成(メソッドチェーンを使用)
// 注意: 認証されたセッションクッキーを渡すためにsetCookies()を使用
const robot = await extractor
.create('認証済みエクトラクター')
.setCookies(sessionCookies)
.navigate(targetUrl)
.wait(2000)
.captureText({ content: '.protected-content' });
// 抽出を実行
const result = await robot.run({ timeout: 30000 });
return result.data;
}
extractWithPreAuth().then(console.log).catch(console.error);★ インサイト ─────────────────────────────────────
事前認証パターンは、CAPTCHAの解決とデータ抽出を分離します。これはMaxunにとって特に重要です。Maxunは高レベルの抽象化で動作するため、DOMにトークンをインジェクトするのではなく、まず認証されたセッションを確立し、その後Maxunのロボットにそのセッション内で作業させます。
─────────────────────────────────────────────────
CAPTCHA処理付きの並列ロボット実行
複数の並列ロボット実行でCAPTCHAを処理します:
typescript
import { Scrape } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
const capSolver = new CapSolverService({ apiKey: process.env.CAPSOLVER_API_KEY! });
const scraper = new Scrape({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: process.env.MAXUN_BASE_URL || 'https://app.maxun.dev/api/sdk',
});
interface ExtractionJob {
url: string;
siteKey?: string;
}
interface ExtractionResult {
url: string;
data: { markdown?: string; html?: string };
captchaSolved: boolean;
duration: number;
}
async function processJob(job: ExtractionJob): Promise<ExtractionResult> {
const startTime = Date.now();
let captchaSolved = false;
// siteKeyが指定されている場合、CAPTCHAを解決
if (job.siteKey) {
console.log(`${job.url}のCAPTCHAを解決中...`);
const token = await capSolver.solveReCaptchaV2(job.url, job.siteKey);
captchaSolved = true;
// トークンはセッションを確立するために送信されます
}
// スクレイプロボットを作成および実行
const robot = await scraper.create(`scraper-${Date.now()}`, job.url, {
formats: ['markdown', 'html'],
});
const result = await robot.run({ timeout: 30000 });
// 使用後はロボットを削除
await robot.delete();
return {
url: job.url,
data: {
markdown: result.data.markdown,
html: result.data.html,
},
captchaSolved,
duration: Date.now() - startTime,
};
}
async function runParallelExtractions(
jobs: ExtractionJob[],
concurrency: number = 5
): Promise<ExtractionResult[]> {
const results: ExtractionResult[] = [];
const chunks: ExtractionJob[][] = [];
// ジョブをチャンクに分割して制御された並列処理を実行
for (let i = 0; i < jobs.length; i += concurrency) {
chunks.push(jobs.slice(i, i + concurrency));
}
for (const chunk of chunks) {
const chunkResults = await Promise.all(chunk.map(processJob));
results.push(...chunkResults);
}
return results;
}
// 例の使用方法
const jobs: ExtractionJob[] = [
{ url: 'https://site1.com/data', siteKey: '6Lc...' },
{ url: 'https://site2.com/data' },
{ url: 'https://site3.com/data', siteKey: '6Lc...' },
// ... 他のジョブ
];
runParallelExtractions(jobs, 5)
.then((results) => {
const solved = results.filter((r) => r.captchaSolved).length;
console.log(`完了した抽出: ${results.length}件、CAPTCHA解決: ${solved}件`);
results.forEach((r) => {
console.log(`${r.url}: ${r.duration}ms`);
});
})
.catch(console.error);ベストプラクティス
1. エラー処理とリトライ
typescript
async function solveWithRetry<T>(
solverFn: () => Promise<T>,
maxRetries: number = 3
): Promise<T> {
let lastError: Error | undefined;
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
return await solverFn();
} catch (error) {
lastError = error as Error;
console.warn(`試行 ${attempt + 1} 失敗: ${lastError.message}`);
// 指数バックオフ
await new Promise((resolve) =>
setTimeout(resolve, Math.pow(2, attempt) * 1000)
);
}
}
throw new Error(`最大リトライ回数に達しました: ${lastError?.message}`);
}
// 使用例
const token = await solveWithRetry(() =>
capSolver.solveReCaptchaV2(url, siteKey)
);2. バランス管理
typescript
async function ensureSufficientBalance(minBalance: number = 1.0): Promise<void> {
const balance = await capSolver.checkBalance();
if (balance < minBalance) {
throw new Error(
`CapSolverの残高が不足しています: $${balance.toFixed(2)}。再充電してください。`
);
}
console.log(`CapSolverの残高: $${balance.toFixed(2)}`);
}
// 抽出ジョブを開始する前に残高を確認
await ensureSufficientBalance(5.0);3. トークンキャッシュ
typescript
interface CachedToken {
token: string;
timestamp: number;
}
class TokenCache {
private cache = new Map<string, CachedToken>();
private ttlMs: number;
constructor(ttlSeconds: number = 90) {
this.ttlMs = ttlSeconds * 1000;
}
private getKey(domain: string, siteKey: string): string {
return `${domain}:${siteKey}`;
}
get(domain: string, siteKey: string): string | null {
const key = this.getKey(domain, siteKey);
const cached = this.cache.get(key);
if (!cached) return null;
if (Date.now() - cached.timestamp > this.ttlMs) {
this.cache.delete(key);
return null;
}
return cached.token;
}
set(domain: string, siteKey: string, token: string): void {
const key = this.getKey(domain, siteKey);
this.cache.set(key, { token, timestamp: Date.now() });
}
}
const tokenCache = new TokenCache(90);
async function getCachedOrSolve(
url: string,
siteKey: string
): Promise<string> {
const domain = new URL(url).hostname;
const cached = tokenCache.get(domain, siteKey);
if (cached) {
console.log('キャッシュされたトークンを使用');
return cached;
}
const token = await capSolver.solveReCaptchaV2(url, siteKey);
tokenCache.set(domain, siteKey, token);
return token;
}設定オプション
Maxunは環境変数とSDKオプションを通じて設定をサポートしています:
| 設定 | 説明 | デフォルト |
|---|---|---|
MAXUN_API_KEY |
あなたのMaxun APIキー | - |
MAXUN_BASE_URL |
Maxun APIのベースURL | http://localhost:8080/api/sdk(セルフホスト)または https://app.maxun.dev/api/sdk(クラウド) |
CAPSOLVER_API_KEY |
あなたのCapSolver APIキー | - |
CAPSOLVER_TIMEOUT |
リクエストタイムアウト(ミリ秒) | 30000 |
CAPSOLVER_MAX_ATTEMPTS |
最大ポーリング試行回数 | 60 |
SDK設定
typescript
import { Extract, Scrape, Crawl, Search } from 'maxun-sdk';
import { CapSolverService } from './capsolver-service';
// Maxun Cloud(app.maxun.dev)用
const MAXUN_BASE_URL = 'https://app.maxun.dev/api/sdk';
// セルフホストMaxun(デフォルト)
// const MAXUN_BASE_URL = 'http://localhost:8080/api/sdk';
// Maxun SDKモジュールの設定
const extractor = new Extract({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: MAXUN_BASE_URL,
});
const scraper = new Scrape({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: MAXUN_BASE_URL,
});
const crawler = new Crawl({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: MAXUN_BASE_URL,
});
const searcher = new Search({
apiKey: process.env.MAXUN_API_KEY!,
baseUrl: MAXUN_BASE_URL,
});
// CapSolverの設定
const capSolver = new CapSolverService({
apiKey: process.env.CAPSOLVER_API_KEY!,
timeout: 30000,
maxAttempts: 60,
});結論
MaxunとCapSolverを統合することで、スケール可能なウェブデータ抽出が可能になります。Maxunのロボットベースのアーキテクチャは、低レベルのブラウザ自動化を抽象化していますが、CapSolverはそれ以外に抽出ワークフローをブロックするCAPTCHAチャレンジを回避するための必須機能を提供します。
成功する統合の鍵は、Maxunが従来のブラウザ自動化ツールよりも高い抽象化レベルで動作していることを理解することです。CAPTCHAトークンを直接DOMに挿入する代わりに、統合は次の点に焦点を当てています:
- 事前認証: ロボットの実行前にCAPTCHAを解決してセッションを確立
- クッキーを介した回避: 解決されたトークンやクッキーをMaxunロボットに渡す
- 並列処理: 同時に実行される抽出処理でCAPTCHAを効率的に処理
価格モニタリングシステム、市場調査のパイプライン、データ集約プラットフォームの構築に関わらず、Maxun + CapSolverの組み合わせは、本番環境で必要な信頼性とスケーラビリティを提供します。
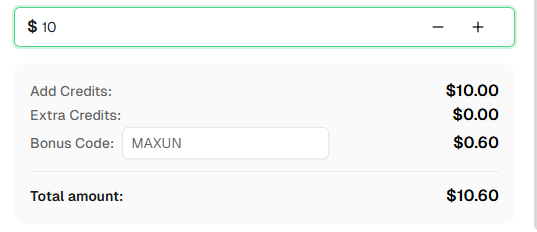
さっそく始めたいですか? CapSolverに登録 し、初回チャージで6%のボーナスを追加するためのボーナスコード MAXUN を使用してください!
FAQ
Maxunとは何ですか?
Maxunは、コードを書かずにウェブサイトをスクレイピングできる、オープンソースでノーコードのウェブデータ抽出プラットフォームです。視覚的なロボットビルダー、強力なTypeScript/Node.js SDK、クラウドおよびセルフホスト型のデプロイメントをサポートしています。
CapSolverはMaxunとどのように統合されますか?
CapSolverは、事前認証パターンを通じてMaxunに統合されます。Maxunロボットを実行する前に、CapSolverのAPIでCAPTCHAを解決し、その後、解決されたトークンやセッションクッキーを抽出ワークフローに渡します。このアプローチは、Maxunのより高い抽象化レベルと相性が良いです。
CapSolverはどのような種類のCAPTCHAを解決できますか?
CapSolverは、reCAPTCHA v2、reCAPTCHA v3、Cloudflare Turnstile、Cloudflare Challenge(5秒)、AWS WAF、GeeTest v3/v4など、多くのCAPTCHAタイプをサポートしています。
CapSolverの料金はいくらですか?
CapSolverは、解決するCAPTCHAの種類と量に基づいて競争力のある料金を提供しています。最新の料金詳細についてはcapsolver.comをご覧ください。初回チャージで6%のボーナスを得るためにコード MAXUN を使用してください。
Maxunはどのプログラミング言語をサポートしていますか?
MaxunのSDKはTypeScriptで構築され、Node.js 18+で動作します。プログラム的なロボット制御のための現代的で型安全なAPIを提供し、任意のNode.jsアプリケーションに統合可能です。
Maxunは無料で使用できますか?
Maxunはオープンソースで、セルフホストには無料です。Maxunはさらに、追加機能やマネージドインフラを提供するクラウドサービスも提供しています。詳細については、料金ページを確認してください。
CAPTCHAのサイトキーを見つける方法は?
サイトキーは通常、ページのHTMLソースにあります。次の場所を確認してください:
- reCAPTCHA:
.g-recaptcha要素のdata-sitekey属性 - Turnstile:
.cf-turnstile要素のdata-sitekey属性 - または、API呼び出しでキーをネットワークリクエストで確認
Maxunは認証済みセッションを処理できますか?
はい、Maxunはロボット構成でクッキーとカスタムヘッダーをサポートしています。CAPTCHAの解決から得られたセッションクッキーを抽出ロボットに渡すことで、認証が可能です。
MaxunとPlaywright/Puppeteerの違いは?
Maxunはより高い抽象化レベルで動作します。PlaywrightやPuppeteerが低レベルのブラウザコントロールを提供するのに対し、Maxunは視覚的またはプログラム的に作成できる再利用可能なロボットベースのワークフローに焦点を当てています。これにより、スケール可能な抽出パイプラインの構築と保守が容易になります。
追加の統合ガイドを読む:
Playwright & Puppeteer
抽出中に表示されるCAPTCHAをどうやって処理すればよいですか?
抽出中に表示されるCAPTCHA(初期ページロードでは表示されないもの)の場合、ロボットワークフローに検出メカニズムを実装し、検出時にCAPTCHAの解決をトリガーする必要があります。Maxunのwebhookやコールバック機能を使用して、抽出の一時停止と再開を検討してください。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
