NODRIVER 対 従来のブラウザ自動化ツール: ウェブスクリーピングにおける

Lucas Mitchell
Automation Engineer
TL;Dr
- NODRIVERは、SeleniumやWebDriverを介さずにChrome DevToolsプロトコル(CDP)に直接通信する、高性能で非同期のPythonライブラリです。
- 伝統的なツールとは異なり、NODRIVERは一般的な検出マーカーを回避するため、検出されないChromedriverの代替として優れています。
- 非同期ウェブスクリーピングにより、NODRIVERは並行処理を可能にし、データ抽出の速度を大幅に向上させます。
- 伝統的なツールであるSeleniumやPlaywrightはクロスブラウザサポートを提供しますが、高度なセキュリティ対策に遭遇した場合、ヘッドレスブラウザの制限に苦しむことがあります。
- CapSolverなどのサービスを統合することで、最も複雑なインタラクティブなチャレンジが自動化ワークフローを妨げることなくなります。
はじめに
現代のウェブデータ抽出は単なるHTTPリクエストを超えています。ウェブサイトがより高度なセキュリティを導入するにつれて、Pythonのブラウザ自動化ツールの選択が重要になります。SeleniumやPuppeteerなどの伝統的なフレームワークは長年この分野を支配してきましたが、検出やオーバーヘッドの問題に直面することがあります。NODRIVERは、ヘッドレスブラウザの制限を克服する現代的な非同期ソリューションです。この記事では、CDPの実装、パフォーマンス、そして非同期ウェブスクリーピングプロジェクトで効率性と信頼性を求める開発者にとって、なぜNODRIVERが検出されないChromedriverの代替として好まれているのかを、技術的な詳細に焦点を当てて説明します。アーキテクチャの基本的な違いを理解することで、開発者はコンプライアンスを尊重しながら高品質なデータを提供するより頑丈なスクリーパーを構築できます。
ブラウザ自動化の進化
ブラウザ自動化は、いくつかの世代にわたって進化してきました。初期のツールは、コードとブラウザの間のブリッジとして機能するWebDriverプロトコルに依存していました。テストには効果的でしたが、このブリッジはラティエンシーと検出可能なシグネチャを導入しました。
伝統的なWebDriverベースのツール
SeleniumはWebDriverベースのツールの典型的な例です。複数の言語とブラウザをサポートしていますが、そのアーキテクチャは本質的に同期的です。これは、各コマンドが前のコマンドの完了を待たなければならないことを意味し、大規模な非同期ウェブスクリーピングにおいてボトルネックになる可能性があります。さらに、WebDriverはセキュリティシステムによって簡単に識別される特定のJavaScriptプロパティ(例:navigator.webdriver)を残します。これにより、頻繁にブロックされ、メンテナンスが必要になります。伝統的なツールがインタラクティブなチャレンジをどのように扱うかについて詳しく知りたい場合は、Selenium vs Puppeteer for CAPTCHA Solvingに関する記事を参照してください。
CDP実装の台頭
PuppeteerやPlaywrightなどのツールは、Chrome DevToolsプロトコル(CDP)を使用することで、パラダイムを変化させました。これにより、ブラウザの内部をより直接的に制御できるようになりました。しかし、これら現代的なツールでさえ、正しく構成されない場合、検出される可能性があります。プロトコル自体は強力で、ネットワークイベント、コンソールログ、パフォーマンスメトリクスへのアクセスを提供します。しかし、これらのツールにおける標準的なCDP実装は、高度なセキュリティが検出できる「足跡」を残すことがあります。NODRIVERはこれをさらに進めて、通常の「ステルス」バージョンのツールがまだ保持している自動化レイヤーを削除します。ブラウザのデバッグポートに直接のWebSocket接続を使用することで、自動化スクリプトの存在を示すメタデータを最小限に抑えます。このアプローチにより、Pythonのブラウザ自動化は標準的なユーザーのセッションと区別がつかない状態を保つことができ、高度なセキュリティ対策によってフラグされるリスクを大幅に減らします。
現代のスクリーピングにおけるヘッドレスブラウザの制限の理解
ヘッドレスブラウザの制限のうち最も重要なのは、レンダリングとリソースの読み込みの方法です。多くのセキュリティシステムは、フォントレンダリングやキャンバスファーザープリント、特定のプラグインの存在に不一致を検出します。伝統的なツールはこれらの属性を信頼性を持って偽装できません。非同期ウェブスクリーピングを行う場合、これらのリクエストのタイミングも見破られる要因になります。NODRIVERは、ブラウザが自然に動作するクリーンな環境を提供することで、これらのヘッドレスブラウザの制限を克服します。検出された環境を「修正」するのではなく、最初から検出されない環境を構築するのです。これは、スクリプトのメンテナンスを頻繁に行う必要がない、大規模なデータスクリーピングに最適な検出されないChromedriverの代替ツールです。持続的な成功のためには、さまざまなウェブスクリーピングのアンチ検出技術を理解することが不可欠です。
NODRIVERの詳細な分析
NODRIVERは単なるラッパーではなく、Pythonのブラウザ自動化のあり方を完全に再考したものです。asyncioを活用することで、従来のスレッドに比べてリソースを多く消費しない、ネイティブな方法で複数のブラウザインスタンスを扱うことができます。
NODRIVERが検出されないChromedriverの代替として最適な理由
多くの開発者は以前、Seleniumの欠点を修正するためにundetected-chromedriverに依存していました。しかし、頻繁なChromeのアップデートに対応するためのパッチの維持は、猫と鼠の駆け引きのようなものです。NODRIVERは、ドライバを使用しないことでこれを回避します。代わりに、WebSocketを介してブラウザに直接通信し、環境が通常のユーザーのセッションと区別がつかないことを保証します。このネイティブなCDP実装がその核心的な強みです。現在利用可能なPythonブラウザ自動化ライブラリの中で、これほどのインビジビリティを実現するのは難しいです。
ヘッドレスブラウザの制限を乗り越える
ヘッドレスブラウザの制限のうち、最も重要なのは「ヘッドレス」フラグそのものです。多くのサイトはGUIなしで動作しているブラウザを検出できます。NODRIVERはこのフラグを伝統的なツールよりも効果的に管理し、多くの場合、調整されたPlaywrightやPuppeteerの設定よりもインビジビリティにおいて優れています。プロトコルの下層に焦点を当てることで、ターゲットウェブサイトにとって完全に自然に見える方法でブラウザの状態を操作できます。
NODRIVERと業界の比較概要
| 特徴 | NODRIVER | Selenium | Playwright | Puppeteer |
|---|---|---|---|---|
| 主な言語 | Python | 多言語 | 多言語 | Node.js |
| アーキテクチャ | 非同期CDP | WebDriver | CDP / カスタム | CDP |
| スピード | 非常に高速 | 中程度 | 高速 | 高速 |
| ステルスレベル | 非常に優れている | 低め(パッチなし) | 中程度 | 中程度 |
| セットアップの複雑さ | 低め | 中程度 | 中程度 | 中程度 |
| 非同期サポート | ネイティブ(asyncio) | 限られている | ネイティブ | ネイティブ |
非同期ウェブスクリーピングのパフォーマンス上の利点
従来のスクリーピング構成では、10のブラウザタブを開くには10のスレッドが必要で、それぞれが大きなメモリを消費します。NODRIVERの非同期ウェブスクリーピング機能により、1つのイベントループで数百の並行処理を管理できます。この効率性は、リアルタイムデータや大規模な歴史的抽出を必要とするプロジェクトにおいて非常に重要です。
自動化のスケーリングと課題の対処
自動化をスケーリングする際には、人間の存在を確認するためのインタラクティブな課題に直面する可能性があります。最良のPythonブラウザ自動化でも、これらの障壁はスクリプトの実行を妨げる可能性があります。ここがCapSolverがスタックにおいて不可欠になるポイントです。これらの課題の解決を自動化することで、非同期ウェブスクリーピングパイプラインが途切れることを防ぎます。たとえば、NODRIVERスクリプトが複雑な検証に遭遇した場合、CapSolver APIを使用してシームレスに処理できます。スケーリングは単にブラウザを多く動作させるだけでなく、それらが詰まることがないよう保証することも含まれます。1つの詰まったブラウザインスタンスはCPUとメモリを消費し、最終的に全体の非同期ウェブスクリーピングインフラストラクチャをクラッシュさせる可能性があります。
CapSolverの統合によるワークフローの円滑化
CapSolverのようなサービスをNODRIVERワークフローに統合するのは簡単です。スクリプトが検証チャレンジを検出すると、インタラクションを一時停止し、CapSolver APIに必要なパラメータを送信し、解決結果が返却されたら再開します。強力な検出されないChromedriverの代替と信頼性の高いチャレンジソルバーのこの連携が、アマチュアスクリーピングとプロフェッショナルなデータ収集を分けるポイントです。非同期ウェブスクリーピングを使用することで、異なるブラウザインスタンスで複数のチャレンジを同時に処理でき、個々のページが厳重に保護されている場合でも全体のスループットを維持できます。このアプローチは、インタラクティブなセキュリティチェックに関連する一般的なヘッドレスブラウザの制限を効果的に回避します。ヘッドレスブラウザでのCAPTCHA解決の自動化に関する詳細な戦略については、ヘッドレスブラウザでのCAPTCHA解決の自動化のガイドを参照してください。
NODRIVERの実装:技術的な例
CDP実装の力の理解のために、基本的な設定を見てみましょう。NODRIVERの構文は、asyncioに慣れたPython開発者向けに設計されています。この例は、高レベルのステルス性を保ちながらブラウザセッションを開始し、ページと対話する方法を示しています。
python
import nodriver as uc
import asyncio
import requests
# 実際のワークフローでCapSolverを統合する例
def solve_challenge(site_url, site_key):
api_key = "YOUR_CAPSOLVER_API_KEY"
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
task_id = res.json().get("taskId")
# 結果をポーリング...(この例では簡略化しています)
return "SOLVED_TOKEN"
async def main():
# 高度なCDP実装でブラウザを起動
# NODRIVERはブラウザの初期化を自動で処理します
browser = await uc.start()
# ターゲットURLに移動
page = await browser.get('https://www.example.com')
# 通常のヘッドレスブラウザの制限なしで対話を行う
# 特定の要素を待つことも、一定時間待つこともできます
await page.wait(2)
# ページのコンテンツを取得するか、要素と対話する
content = await page.get_content()
print(f"ページタイトル: {await page.title()}")
# 実際のシナリオでは、ここであなたのチャレンジが現れるかもしれません。
# 検証が表示された場合、ソルバー関数を呼び出します。
# token = solve_challenge('https://www.example.com', 'SITE_KEY')
# await page.evaluate(f'document.getElementById("g-recaptcha-response").innerHTML="{token}";')
# 常にブラウザを停止してリソースを解放するようにしてください
await browser.stop()
if __name__ == '__main__':
# NODRIVERの組み込みループを使用して便利に
uc.loop().run_until_complete(main())注:このコードはNODRIVERの標準的な実装パターンに従っており、CapSolverなどの外部サービスとの統合に適しています。CDP実装により、すべてのコマンドがブラウザに直接送信され、検出されやすいWebDriverプロトコルをバイパスします。
Pythonブラウザ自動化のベストプラクティス
Pythonブラウザ自動化スクリプトを構築する際には、長期的な安定性を確保するためにベストプラクティスを守ることが重要です。まず、例外を処理する必要があります。ブラウザはクラッシュする可能性があり、ネットワーク接続が切れる場合もあり、ウェブサイトの構造が変化することもあります。第二に、現実的な遅延を使用してください。完全な検出されないChromedriverの代替でも、人間のようなタイミングは重要です。第三に、識別子をローテーションしてください。NODRIVERは多くのファーザープリントの問題を処理しますが、IPアドレスやUser-Agent文字列のローテーションにより、セキュリティの層を追加します。最後に、成功確率を常にモニタリングしてください。データ品質が低下していることに気づいたら、CDP実装の更新やCapSolverなどのサービスを用いてチャレンジ解決戦略を見直す必要があります。これらのベストプラクティスと非同期ウェブスクリーピングの力の組み合わせにより、あなたの自動化インフラは頑丈でスケーラブルになります。
CapSolverで複雑なチャレンジを処理する
NODRIVERは初期の検出を回避するのに優れているものの、一部のウェブサイトはツールの種類に関係なく行動分析を用いてインタラクティブな検証をトリガーします。このようなケースでは、CapSolverが自動化ワークフローに直接統合される強力なAPIを提供します。これにより、最も厳しいセキュリティに直面しても、Pythonブラウザ自動化が生産性を維持できます。具体的な統合例については、PydollでCapSolverを使用してCAPTCHAを解決する方法を参照してください。
NODRIVERとCapSolverを併用する理由
- 信頼性: ウェブサイトが人間の対話要求をするときでもスクリプトが失敗しないようにします。
- スピード: CapSolverのAPIは高速な応答を最適化しており、非同期ウェブスクリーピングのスピードに補完的です。
- 使いやすさ: Pythonのrequestsや他のHTTPクライアントとのシンプルな統合が可能です。
最近の業界分析によると、ScrapingBeeは、ウェブセキュリティの複雑化への対応として、ドライバーレスの自動化へのシフトが重要であると述べています。さらに、ZenRowsは、NODRIVERのような検出されないChromedriverの代替ツールを使用することは、現在の高頻度データ収集の標準的な実践方法であると指摘しています。これらの外部リソースは、現代の環境において現代的なCDP実装の重要性を裏付けています。
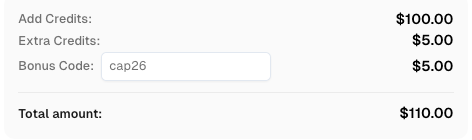
CapSolverに登録する際、コード
CAP26を使用するとボーナスクレジットが得られます!
結論
Pythonのブラウザ自動化に適切なツールを選ぶことは、プロジェクトの規模や対象サイトのセキュリティに依存します。SeleniumやPlaywrightなどの従来のツールはテストに優れていますが、NODRIVERは高リスクの非同期ウェブスクレイピングに特化した非検出型Chromedriverの代替として際立っています。直接的なCDP(Chrome DevTools Protocol)の実装により、通常のヘッドレスブラウザの制限を回避し、よりクリーンで高速かつ目立たない自動化体験を提供します。CapSolverの強力な解決機能と組み合わせることで、効率性と信頼性の最高基準に準拠した耐障害性とスケーラビリティを備えたデータ抽出システムを構築できます。コンプライアンスを確保し、ツールを責任を持って使用することは、成功した自動化プロジェクトの基盤です。
FAQ
1. NODRIVERはSeleniumよりも本当に速いですか?
はい、NODRIVERはWebDriverの仲介を排除し、Pythonのasyncioによるネイティブな非同期ウェブスクレイピングを採用しているため、はるかに高速です。
2. NODRIVERは高度なセキュリティシステムによって検出される可能性がありますか?
どのツールも100%検出されないわけではありませんが、NODRIVERのCDP実装は従来のPythonブラウザ自動化ツールを識別する一般的なマーカーを回避しています。
3. NODRIVERはFirefoxやSafariをサポートしていますか?
現在のところ、NODRIVERは最も堅牢な非検出型Chromedriverの代替と深いCDP実装を提供するため、Chromiumベースのブラウザに焦点を当てています。
4. NODRIVERでインタラクティブなチャレンジをどう処理すればよいですか?
自動化プロセス中に発生する可能性のあるインタラクティブな検証は、CapSolverを使用することをお勧めします。
5. ヘッドレスブラウザの主な制限は何ですか?
一般的なヘッドレスブラウザの制限には、欠落しているブラウザ機能、検出可能なJavaScriptプロパティ、一貫性のないレンダリングが含まれます。これらすべてに対してNODRIVERは最小限に抑えることを目指しています。
もっと見る
aws wafJul 23, 2026
AWS WAFをLangChainで解決する方法 with CapSolver
認可されたAWS WAF LangChainワークフローをCapSolverツール、応答検出、ポリシーゲート、セッション処理、リトライ、および検証を用いて構築してください。

AIJul 23, 2026
クラウドフレア トゥルネスティールを解決する方法 ラングラフ エージェントで
LangGraph Cloudflare Turnstileソルバーのワークフローを構築するには、CapSolver、Playwrightセッション処理、ポリシーゲート、リトライ、検証、およびレビューを用いてください。