Sample Post

Rajinder Singh
Deep Learning Researcher

वेब स्क्रैपिंग वेब से डेटा निकालने वाले किसी भी व्यक्ति के लिए एक महत्वपूर्ण कौशल बन गया है। चाहे आप डेटा विज्ञानी हों, विकासकर्ता हों या वेबसाइटों से जानकारी एकत्र करने के लिए रुचि रखने वाले शौकिया हों, पुप्पेटियर आपके उपलब्ध सबसे शक्तिशाली उपकरणों में से एक है। यह पूर्ण गाइड पुप्पेटियर क्या है और वेब स्क्रैपिंग में इसके उपयोग के बारे में गहराई से जांच करेगा।
पुप्पेटियर का परिचय
पुप्पेटियर एक नोड लाइब्रेरी है जो डेवटूल्स प्रोटोकॉल के माध्यम से क्रोम या क्रोमियम को नियंत्रित करने के लिए एक उच्च-स्तरीय एपीआई प्रदान करती है। इसका निर्माण गूगल क्रोम टीम द्वारा किया गया है और विकासकर्ताओं को विभिन्न ब्राउजर कार्य करने की क्षमता प्रदान करता है जैसे कि स्क्रीनशॉट बनाना, वेबसाइटों का अनुसरण करना, और सबसे महत्वपूर्ण बात यह कि वेब स्क्रैपिंग। पुप्पेटियर हेडलेस ब्राउजिंग क्षमताओं के कारण बहुत लोकप्रिय है, जिसका अर्थ है कि इसे ग्राफिकल उपयोगकर्ता इंटरफेस के बिना चलाया जा सकता है, जो स्वचालित कार्यों के लिए आदर्श है।
कैपसॉल्वर बोनस कोड के साथ लाभ उठाएं
अपने स्वचालन बजट को तत्काल बढ़ाएं!
कैपसॉल्वर खाता जमा करते समय बोनस कोड CAPN का उपयोग करके प्रत्येक भरोसे में 5% बोनस प्राप्त करें - कोई सीमा नहीं।
अपने कैपसॉल्वर डैशबोर्ड में अब इसे रीडीम करें
.
वेब स्क्रैपिंग के लिए पुप्पेटियर का उपयोग क्यों करें?
एक्सियस और चीरियो जावास्क्रिप्ट वेब स्क्रैपिंग के लिए अच्छे विकल्प हैं, लेकिन उनके सीमा हैं: डायनामिक सामग्री का निपटारा करना और विरोधी-स्क्रैपिंग तकनीकों को पार करना।
हेडलेस ब्राउजर के रूप में, पुप्पेटियर डायनामिक सामग्री के अनुसरण में अपनाता है। यह लक्ष्य पृष्ठ पूरी तरह से लोड करता है, जावास्क्रिप्ट निष्पादित करता है, और अतिरिक्त डेटा प्राप्त करने के लिए एक्सएचआर अनुरोध भी ट्रिगर कर सकता है। यह कुछ भी स्थैतिक स्क्रैपर नहीं कर सकते हैं, विशेष रूप से सिंगल-पेज एप्लिकेशन (एसपीए) में जहां प्रारंभिक एचटीएमएल में महत्वपूर्ण डेटा नहीं होता है।
पुप्पेटियर क्या कर सकता है? यह चित्र रेंडर कर सकता है, स्क्रीनशॉट ले सकता है, और विभिन्न कैप्चा के लिए एक्सटेंशन समाधान प्रदान करता है जैसे कि रीकैप्चा, कैप्चा, कैप्चा। उदाहरण के लिए, आप अपने स्क्रिप्ट को एक पृष्ठ के माध्यम से नेविगेट करने, विशिष्ट अवधि में स्क्रीनशॉट लेने और उन चित्रों का विश्लेषण करने के लिए कोड कर सकते हैं ताकि प्रतिस्पर्धी अंतर्दृष्टि प्राप्त की जा सके। संभावनाएं लगभग असीमित हैं!
पुप्पेटियर का सरल उपयोग
हमने पहले एक्सर्साइज के पहले हिस्से को सीलेनियम और पायथन के साथ पूरा कर लिया है। अब, हम पुप्पेटियर का उपयोग दूसरा हिस्सा पूरा करने के लिए करेंगे
शुरू करने से पहले, अपने स्थानीय मशीन पर पुप्पेटियर स्थापित करने का ध्यान रखें। अगर नहीं, तो निम्न आदेशों का उपयोग करके इसे स्थापित कर सकते हैं:
bash
npm i puppeteer # स्थापना के दौरान संगत क्रोम डाउनलोड करता है।
npm i puppeteer-core # विकल्प के रूप में एक लाइब्रेरी के रूप में स्थापित करें, क्रोम के बिना।एक वेबपेज तक पहुंचें
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// 5 सेकंड के लिए रोकें
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();puppeteer.launch विधि एक नए पुप्पेटियर उदाहरण शुरू करने के लिए उपयोग की जाती है और एक विन्यास वस्तु के साथ कई विकल्प स्वीकार कर सकती है। सबसे सामान्य एक headless है, जो ब्राउजर को हेडलेस मोड में चलाने के बारे में बताता है। अगर आप इस पैरामीटर को निर्दिष्ट नहीं करते हैं, तो इसका डिफ़ॉल्ट मान true होता है। अन्य सामान्य विन्यास विकल्प निम्नानुसार हैं:
| पैरामीटर | प्रकार | डिफ़ॉल्ट मान | विवरण | उदाहरण |
|---|---|---|---|---|
args |
string[] |
ब्राउजर शुरू करते समय पास करने के लिए कमांड-लाइन आर्ग्यूमेंट्स की सूची | args: ['--no-sandbox', '--disable-setuid-sandbox'] |
|
debuggingPort |
number |
उपयोग करने के लिए डिबगिंग पोर्ट संख्या निर्दिष्ट करें | debuggingPort: 8888 |
|
defaultViewport |
dict |
{width: 800, height: 600} |
डिफ़ॉल्ट व्यूपोर्ट आकार सेट करें | defaultViewport: {width: 1920, height: 1080} |
devtools |
boolean |
false |
क्या डेवटूल्स खुले रखें | devtools: true |
executablePath |
string |
ब्राउजर एक्सीक्यूटेबल के मार्ग को निर्दिष्ट करें | executablePath: '/path/to/chrome' |
|
headless |
boolean or 'shell' |
true |
क्या ब्राउजर हेडलेस मोड में चलाएं | headless: false |
userDataDir |
string |
उपयोगकर्ता डेटा निर्देशिका के मार्ग को निर्दिष्ट करें | userDataDir: '/path/to/user/data' |
|
timeout |
number |
30000 |
ब्राउजर शुरू होने के लिए प्रतीक्षा करने के लिए मिलीसेकंड में समय सीमा | timeout: 60000 |
ignoreHTTPSErrors |
boolean |
false |
क्या एचटीटीपीएस त्रुटियों को अनदेखा करें | ignoreHTTPSErrors: true |
विंडो के आकार को सेट करें
सबसे अच्छा ब्राउजिंग अनुभव प्राप्त करने के लिए, हमें दो पैरामीटर को समायोजित करने की आवश्यकता है: व्यूपोर्ट आकार और ब्राउजर विंडो आकार। कोड निम्नानुसार है:
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({
headless: false,
args: ['--window-size=1920,1080']
});
const page = await browser.newPage();
await page.setViewport({width: 1920, height: 1080});
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// 5 सेकंड के लिए रोकें
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();डेटा निकालें
पुप्पेटियर में डेटा निकालने के विभिन्न तरीके हैं।
-
evaluateविधि का उपयोग करेंevaluateविधि ब्राउजर संदर्भ में जावास्क्रिप्ट को चलाती है ताकि आवश्यक डेटा निकाला जा सके।javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.evaluate(() => { const image = document.querySelector('.card-img-top').src; const title = document.querySelector('.card-title').innerText; const price = document.querySelector('.card-price').innerText; const description = document.querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('उत्पाद का नाम:', data.title); console.log('उत्पाद की कीमत:', data.price); console.log('उत्पाद की छवि:', data.image); console.log('उत्पाद का विवरण:', data.description); // 5 सेकंड के लिए रोकें await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
$evalविधि का उपयोग करें$evalविधि एक तत्व का चयन करती है और उसकी सामग्री निकालती है।javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const title = await page.$eval('.card-title', el => el.innerText); const price = await page.$eval('.card-price', el => el.innerText); const image = await page.$eval('.card-img-top', el => el.src); const description = await page.$eval('.card-description', el => el.innerText); console.log('उत्पाद का नाम:', title); console.log('उत्पाद की कीमत:', price); console.log('उत्पाद की छवि:', image); console.log('उत्पाद का विवरण:', description); // 5 सेकंड के लिए रोकें await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
$$evalविधि का उपयोग करें$$evalविधि एक साथ कई तत्वों का चयन करती है और उनकी सामग्री निकालती है।javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.$$eval('.my-8.w-full.rounded.border > *', elements => { const image = elements[0].querySelector('img').src; const title = elements[1].querySelector('.card-title').innerText; const price = elements[1].querySelector('.card-price').innerText; const description = elements[1].querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('उत्पाद का नाम:', data.title); console.log('उत्पाद की कीमत:', data.price); console.log('उत्पाद की छवि:', data.image); console.log('उत्पाद का विवरण:', data.description); // 5 सेकंड के लिए रोकें await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
page.$औरevaluateविधि का उपयोग करेंpage.$विधि तत्वों का चयन करती है, औरevaluateविधि ब्राउजर संदर्भ में जावास्क्रिप्ट को चलाती है ताकि डेटा निकाला जा सके।javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const imageElement = await page.$('.card-img-top'); const titleElement = await page.$('.card-title'); const priceElement = await page.$('.card-price'); const descriptionElement = await page.$('.card-description'); const image = await page.evaluate(el => el.src, imageElement); const title = await page.evaluate(el => el.innerText, titleElement); const price = await page.evaluate(el => el.innerText, priceElement); const description = await page.evaluate(el => el.innerText, descriptionElement); console.log('उत्पाद का नाम:', title); console.log('उत्पाद की कीमत:', price); console.log('उत्पाद की छवि:', image); console.log('उत्पाद का विवरण:', description); // 5 सेकंड के लिए रोकें await new Promise(r => setTimeout(r, 5000)); await browser.close(); })();
विरोधी-स्क्रैपिंग सुरक्षा के चारों ओर घूमें
स्क्रैपिंगक्लब के अभ्यास पूरा करना आसान है। हालांकि, वास्तविक डेटा स्क्रैपिंग परिस्थितियों में, डेटा प्राप्त करना हमेशा इतना आसान नहीं होता है। कुछ वेबसाइटें विरोधी-स्क्रैपिंग तकनीकों का उपयोग करती हैं जो आपके स्क्रिप्ट को बॉट के रूप में पहचान सकती हैं और ब्लॉक कर सकती हैं। सबसे आम स्थिति में कैप्चा चुनौतियां शामिल हैं जैसे कि कैप्चा, कैप्चा, रीकैप्चा, कैप्चा, और कैप्चा।
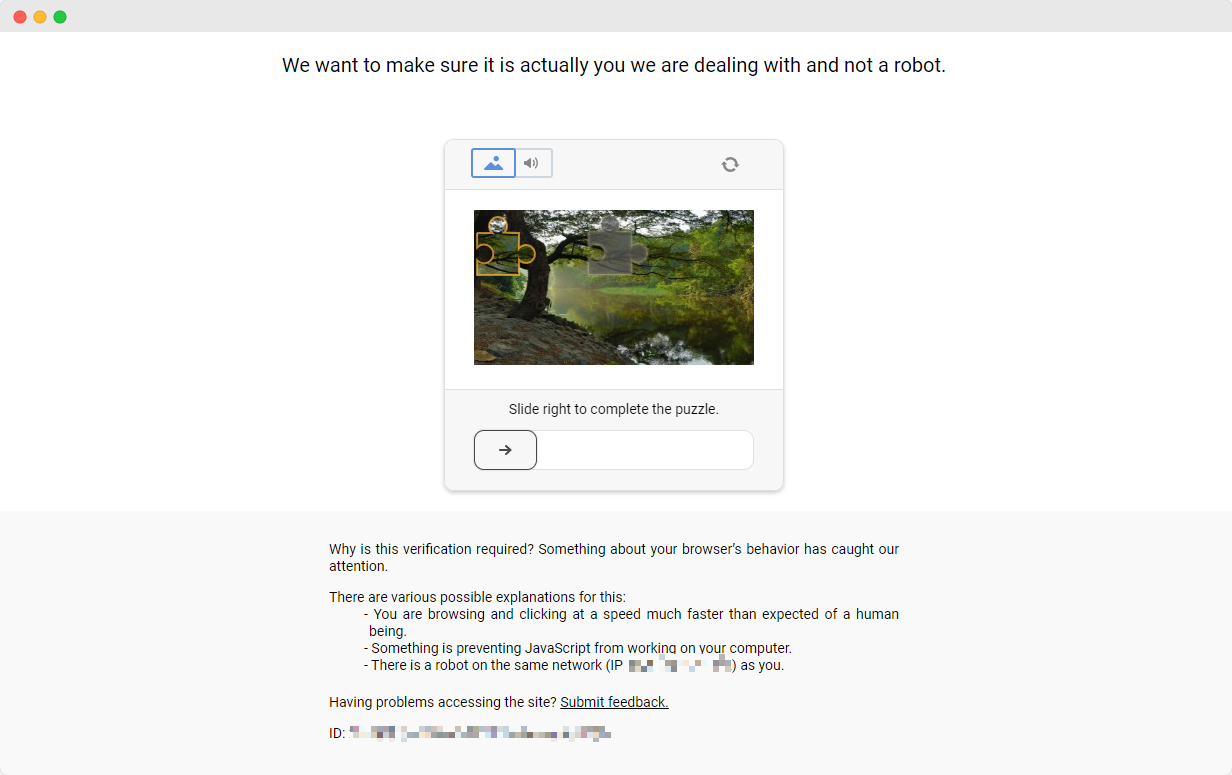
इन कैप्चा चुनौतियों को हल करने के लिए, मशीन लर्निंग, रिवर्स इंजीनियरिंग और ब्राउजर फिंगरप्रिंटिंग विरोधी उपायों में विस्तृत अनुभव की आवश्यकता होती है, जो काफी समय ले सकता है।
सुविधा के साथ, आपको अब सभी कार्यों को खुद नहीं करना पड़ेगा। कैपसॉल्वर आपके लिए एक व्यापक समाधान प्रदान करता है जो आपको सभी चुनौतियों को आसानी से हल करने में सक्षम बनाता है। कैपसॉल्वर ब्राउजर एक्सटेंशन प्रदान करता है जो आपको पुप्पेटियर के साथ डेटा स्क्रैपिंग के दौरान कैप्चा चुनौतियों को स्वचालित रूप से हल करने की अनुमति देता है। इसके अलावा, यह कैप्चा को हल करने और टोकन प्राप्त करने के लिए एपीआई विधि प्रदान करता है। सभी इसे केवल कुछ सेकंड में कर सकते हैं। अब इन विभिन्न कैप्चा संबंधों को हल करने के बारे में जानने के लिए इस दस्तावेज़ के साथ जाएं!
निष्कर्ष
वेब स्क्रैपिंग वेब डेटा निकालने में शामिल किसी भी व्यक्ति के लिए अमूल्य कौशल है, और पुप्पेटियर, एक उन्नत एपीआई और शक्तिशाली विशेषताओं वाले उपकरण के रूप में, इस लक्ष्य की प्राप्ति के लिए सबसे अच्छे विकल्पों में से एक है। इसकी डायनामिक सामग्री का निपटारा करने और विरोधी-स्क्रैपिंग तकनीकों का सामना करने की क्षमता इसे अन्य स्क्रैपिंग टूल्स के बीच अलग करती है।
इस गाइड में, हम पुप्पेटियर क्या है, वेब स्क्रैपिंग में इसके लाभ और इसकी सेटअप और उपयोग के बारे में अध्ययन करते हैं। हम विभिन्न विधियों के साथ वेब पृष्ठों तक पहुंचने, व्यूपोर्ट आकार सेट करने और डेटा निकालने के उदाहरण प्रदर्शित करते हैं। इसके अलावा, हम विरोधी-स्क्रैपिंग प्रौद्योगिकी द्वारा उठाए गए चुनौतियों और कैपसॉल्वर द्वारा कैप्चा चुनौती के लिए एक शक्तिशाली समाधान प्रदान करने के बारे में चर्चा करते हैं।
अक्सर पूछे जाने वाले प्रश्न
1. वेब स्क्रैपिंग में पुप्पेटियर का मुख्य उपयोग क्या है?
पुप्पेटियर का उपयोग वास्तविक क्रोम/क्रोमियम ब्राउजर को नियंत्रित करने के लिए किया जाता है, जो डायनामिक जावास्क्रिप्ट लोड करने, एसपीए पृष्ठों को रेंडर करने, तत्वों के साथ अंतःक्रिया करने और सामान्य HTTP-आधारित स्क्रैपर्स द्वारा पहुंच नहीं कर सकते हैं डेटा निकालने की अनुमति देता है।
2. क्या पुप्पेटियर वेबसाइटों पर कैप्चा चुनौतियों का सामना कर सकता है?
पुप्पेटियर अकेले कैप्चा को पार करने में असमर्थ है, लेकिन कैपसॉल्वर के ब्राउजर एक्सटेंशन या एपीआई के साथ संयोजन में, यह स्क्रैपिंग कार्यक्रमों के दौरान रीकैप्चा, हीकैप्चा, फनकैप्चा और अन्य सत्यापन चुनौतियों को स्वचालित रूप से हल कर सकता है।
3. क्या पुप्पेटियर को दृश्यमान ब्राउजर विंडो के साथ चलाना आवश्यक है?
नहीं। पुप्पेटियर हेडलेस मोड में चलाने के लिए समर्थन प्रदान करता है, जहां क्रोम ग्राफिकल उपयोगकर्ता इंटरफेस के बिना चलता है। इस मोड की गति अधिक होती है और ऑटोमेशन के लिए आदर्श होती है। आप डेबगिंग या दृश्य निगरानी के लिए गैर-हेडलेस मोड में भी चला सकते हैं।
और देखें
Web ScrapingApr 22, 2026
रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण
Rust में वेब स्क्रैपिंग के स्केलेबल आर्किटेक्चर सीखें, reqwest, scraper, असिंक्रोनस स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी रोटेशन, और संगत CAPTCHA का निपटारा।
Web ScrapingFeb 03, 2026
रॉक्सीब्राउज़र में कैप्चा हल करना कैपसॉल्वर एकीकरण के साथ
CapSolver के साथ RoxyBrowser के एकीकरण करें ताकि ब्राउज़र के कार्यों को स्वचालित किया जा सके और reCAPTCHA, Turnstile और अन्य CAPTCHAs को बायपास किया जा सके।