वेब स्क्रैपिंग CAPTCHA हैंडलिंग: सुरक्षित स्वचालन मार्गदर्शिका

Rajinder Singh
Deep Learning Researcher
संक्षिप्त सारांश
- वेब स्क्रैपिंग कैप्चा निपटान की शुरुआत परमिशन, दर नियंत्रण और स्पष्ट बंद नियमों से होनी चाहिए, तकनीकी एकीकरण से पहले।
- मुख्य चुनौती प्रकार में reCAPTCHA, Cloudflare Turnstile, चित्र स्वीकृति और पृष्ठ-विशिष्ट ट्रैफिक सत्यापन प्रवाह शामिल हैं।
- CapSolver अनुमोदित वेब स्क्रैपिंग कैप्चा वर्कफ़्लो के लिए विशिष्ट चुनौती प्रकार के लिए दस्तावेज़ीकृत कार्य निर्माण और परिणाम प्राप्ति एपीआई प्रदान कर सकता है।
- अच्छी ऑटोमेशन टोकन को अल्पकालिक सत्यापन कल्पना के रूप में लेती है और प्रत्येक कार्य, पुन: प्रयास, लक्ष्य डोमेन और विफलता स्थिति को लॉग करती है।
परिचय
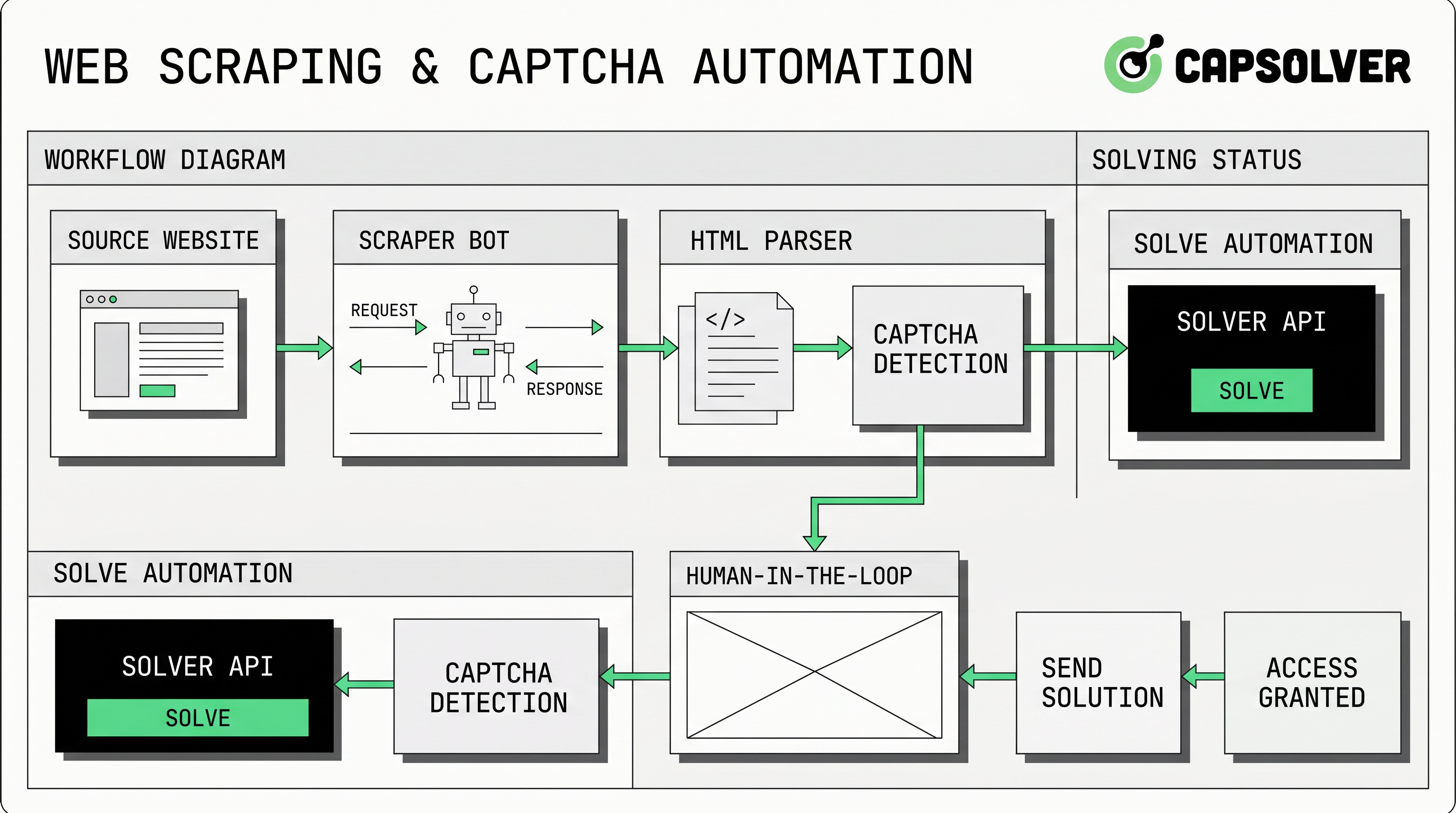
वेब स्क्रैपिंग कैप्चा निपटान टीम के लिए एक व्यावहारिक समस्या है जो अनुमोदित सार्वजनिक डेटा संग्रह, बाजार निरीक्षण चलाते हैं, स्वामित्व एप्लिकेशन का परीक्षण करते हैं या आंतरिक ऑटोमेशन चलाते हैं। CapSolver तब इन वर्कफ़्लो का समर्थन कर सकता है जब उद्देश्य कानूनी, नियंत्रित चुनौती निपटान होता है, बजाय अनियंत्रित ट्रैफिक के। सबसे अच्छा दृष्टिकोण पहले सॉल्वर जोड़ना नहीं है। यह अनुमति की पुष्टि करना, अवांछित अनुरोध कम करना, चुनौती प्रकार की पहचान करना, ब्राउज़र संदर्भ बरकरार रखना और केवल जहां अनुमति हो उस स्थान पर एपीआई वर्कफ़्लो जोड़ना है। यह गाइड एक तकनीकी रूप से विश्वसनीय, आसानी से जांचने योग्य और ज़िम्मेदार ऑटोमेशन नियमों के साथ संगत वेब स्क्रैपिंग प्रक्रिया के डिज़ाइन कैसे करें, इसके बारे में समझाता है।
ऑटोमेशन वर्कफ़्लो में वेब स्क्रैपिंग कैप्चा क्यों दिखाई देता है
वेब स्क्रैपिंग कैप्चा चेक आमतौर पर एक साइट के लिए एक दर्शक, अनुरोध पैटर्न, ब्राउज़र वातावरण या खाता व्यवहार के बारे में अधिक विश्वास चाहते समय दिखाई देता है। कुछ चुनौतियां दृश्य होती हैं, जबकि अन्य अंक-आधारित या टोकन-आधारित होती हैं। गूगल कहता है कि reCAPTCHA v3 उपयोगकर्ता को बाधित बिना चलता है और प्रत्येक अनुरोध के लिए 0.0 से 1.0 तक के जोखिम स्कोर वापस करता है। क्लाउडफ़ेयर कहता है कि Turnstile टोकन के सर्वर पर सत्यापित किए जाने चाहिए, एक ही बार के लिए उपयोग किए जा सकते हैं और 300 सेकंड के लिए वैध रहते हैं। इन प्रणालियां एक व्यापक ट्रैफिक सत्यापन पैटर्न का हिस्सा हैं, केवल एक दृश्य पहेली नहीं।
इसका मतलब है कि वेब स्क्रैपिंग कैप्चा निपटान को अनुरोध गुणवत्ता से अलग नहीं किया जा सकता है। उच्च अनुरोध दर, अस्थिर आईपी प्रतिष्ठा, कम ब्राउज़र संकेत या अस्थिर सत्र स्थिति चुनौती आवृत्ति बढ़ा सकती है। एपीआई जोड़ने से पहले, टीमें बेकार ट्रिगर कम करके अपने उपयोग मामले की पहचान करें, रोबोट्स और शर्तों के सम्मान में एक जवाबदेह तरीका अपनाएं, समानांतरता को सीमित करें, जब आवश्यक हो तो अपने उपयोग मामले की पहचान करें और जब एक साइट अनुमति या सीमा लगाती है तो रुक जाएं।
| कारण | व्यावहारिक प्रतिक्रिया | क्यों मदद करता है |
|---|---|---|
| उच्च अनुरोध दर | एक अनुरोध सीमा और बैकऑफ जोड़ें | लोड और विफल प्रयास कम करता है। |
| ब्राउज़र असंगतता | एक स्थिर ब्राउज़र ऑटोमेशन प्रोफ़ाइल का उपयोग करें | पृष्ठ संदर्भ स्थिर रखता है। |
| प्रॉक्सी असंगतता | प्रॉक्सी, सत्र और चुनौती कार्य को समायोजित रखें | टोकन संदर्भ असंगति रोकता है। |
| अज्ञात चुनौती प्रकार | कार्य निर्माण से पहले reCAPTCHA, Turnstile या चित्र चुनौती की पहचान करें | सही एपीआई पेलोड भेजता है। |
| अस्पष्ट अनुमति | शर्तों, रोबोट्स, संविदाओं और डेटा संवेदनशीलता की समीक्षा करें | ऑटोमेशन को अनुमोदित सीमाओं के भीतर रखता है। |
वेब स्क्रैपिंग कैप्चा एकीकरण से पहले नीति बनाएं
वेब स्क्रैपिंग कैप्चा कार्य की शुरुआत नीति से होनी चाहिए। OWASP अवांछित ऑटोमेशन को सॉफ्टवेयर के रूप में वर्णित करता है जो स्वीकृत व्यवहार से भिन्न होता है और वेब एप्लिकेशन के लिए अवांछित प्रभाव उत्पन्न करता है, और इसकी ऑटोमेशन खतरा वर्गीकरण में छापे और कैप्चा से संबंधित दुरुपयोग परिदृश्य शामिल हैं। टीम के लिए, यह एक ही तकनीकी वर्कफ़्लो एक संदर्भ में स्वीकार्य हो सकता है और दूसरे में अस्वीकार्य हो सकता है।
एक ज़िम्मेदार नीति अनुमोदित डोमेन, अनुमोदित डेटा प्रकार, व्यापार उद्देश्य, अनुरोध-दर सीमा, खाता नियम, अवधि नियम और एग्जेंसी संपर्कों की सूची बनानी चाहिए। इसे यह भी स्पष्ट करना चाहिए कि ऑटोमेशन क्या नहीं करना चाहिए, जैसे निजी क्षेत्रों की एक्सेस, अनुमति के बिना संवेदनशील डेटा का संग्रह, या अस्वीकृत संकेतों के बाद जारी रखना। यह नीति लक्ष्य साइट और अपने संगठन दोनों की सुरक्षा करती है क्योंकि यह अनुमोदित डेटा संग्रह और निषिद्ध गतिविधि के बीच स्पष्ट रेखा बनाती है।
सही वेब स्क्रैपिंग कैप्चा वर्कफ़्लो चुनें
वेब स्क्रैपिंग कैप्चा निपटान आमतौर पर तीन तकनीकी पैटर्न में से एक फिट होता है। पहला अच्छी अनुरोध हाइजीन के माध्यम से बचाव है: कम अनुरोध, बेहतर कैशिंग और कम शोर ब्राउज़र व्यवहार। दूसरा किन्हीं भी अंतर्निहित मामलों के लिए मानव समीक्षा है, जहां एक कम आउटपुट प्रक्रिया कठिन पृष्ठों को एक ऑपरेटर के लिए राउट करती है। तीसरा एपीआई-आधारित चुनौती वर्कफ़्लो है, जहां एक अनुमोदित कार्य चुनौती पैरामीटर के साथ एक प्रदाता को भेजता है और समाधान प्राप्त करता है।
CapSolver के आधिकारिक एपीआई दस्तावेज़ीकरण में createTask और getTaskResult के साथ एक कार्य-आधारित प्रवाह वर्णित है। इस मॉडल में, स्क्रैपर चुनौती की पहचान करता है, सही कार्य ऑब्जेक्ट जमा करता है, एक कार्य आईडी प्राप्त करता है और परिणाम तैयार होने तक पॉल करता है। createTask गाइड बताता है कि अनुरोध के clientKey और एक कार्य ऑब्जेक्ट की आवश्यकता होती है, और getTaskResult गाइड असिंक्रॉनस कार्य के processing और ready स्थिति का वर्णन करता है।
reCAPTCHA पृष्ठों के लिए, टीमें सामान्य लोड पेलोड की नकल करने के बजाय CapSolver के reCAPTCHA v2 गाइड या reCAPTCHA v3 गाइड की समीक्षा करनी चाहिए। Turnstile पृष्ठों के लिए, Cloudflare Turnstile गाइड का उपयोग करें और याद रखें कि Cloudflare के स्वयं के सर्वर-साइड सत्यापन नियम टोकन ताजगी के लिए महत्वपूर्ण हैं।
ब्राउज़र, प्रॉक्सी और टोकन संदर्भ को संगत रखें
वेब स्क्रैपिंग कैप्चा त्रुटियां आमतौर पर संदर्भ असंगति से आती हैं। अगर ब्राउज़र एक पृष्ठ के माध्यम से एक प्रॉक्सी के माध्यम से अनुरोध करता है लेकिन चुनौती कार्य दूसरे नेटवर्क पथ का उपयोग करता है, तो वापस आए टोकन की अपेक्षित वातावरण से मेल नहीं खाएगा। यदि पृष्ठ क्रिया विवरण और जमा के बीच बदल जाती है, तो एक अंक आधारित टोकन अपेक्षित रूप से सत्यापित नहीं हो सकता। यदि कार्यकर्ता बहुत लंबे समय तक प्रतीक्षा करता है, तो टोकन समाप्त हो सकता है।
इसलिए ऑटोमेशन लेयर को एक चुनौती कार्य को जॉब आईडी, ब्राउज़र सत्र, प्रॉक्सी, लक्ष्य URL, साइट कुंजी और समयचिह्न से बांधना चाहिए। CapSolver के वेब ऑटोमेशन में सेलेनियम और वेब ऑटोमेशन में पुप्पेटीयर पर संसाधन टीमों के लिए उपयोगी आंतरिक लिंक हैं जिन्हें चुनौती निपटान से पहले ब्राउज़र ड्राइवरों के मानकीकरण की आवश्यकता होती है। प्रॉक्सी के मामले में, स्क्रैपिंग और ऑटोमेशन के लिए प्रॉक्सी पोर्ट दिशा-निर्देश नेटवर्क सेटिंग्स को संगत रखने में मदद कर सकते हैं।
बोनस कोड
अपना CapSolver बोनस कोड जमा करें
अपने स्वचालन बजट को तुरंत बढ़ाएं!
अपने CapSolver खाते में जमा करते समय बोनस कोड CAP26 का उपयोग करें ताकि प्रत्येक भुगतान पर 5% बोनस मिले — कोई सीमा नहीं।
अब अपने CapSolver डैशबोर्ड में इसे जमा करें
तुलना सारांश: सामान्य वेब स्क्रैपिंग कैप्चा विकल्प
वेब स्क्रैपिंग कैप्चा निपटान कार्य के आयतन, अनुमति स्तर और विश्वसनीयता आवश्यकता के अनुरूप होना चाहिए। एक कम आउटपुट अनुसंधान कार्य केवल मानव समीक्षा की आवश्यकता हो सकती है। एक नियमित मॉनिटरिंग कार्य आमतौर पर एपीआई-आधारित स्थिति नियंत्रण, लॉग्स और बंद शर्तों की आवश्यकता होती है। एक खराब नियंत्रित उच्च आउटपुट कार्य को तकनीकी एकीकरण काम करता होने पर भी आगे बढ़ना चाहिए।
| विकल्प | सबसे अच्छा उपयोग मामला | मुख्य जोखिम |
|---|---|---|
| केवल अनुरोध हाइजीन | कम चुनौती आवृत्ति वाले सार्वजनिक पृष्ठ | जब वे दिखाई देते हैं तो चुनौती पृष्ठों का निपटान नहीं कर सकते। |
| मानव समीक्षा | कम आउटपुट अनुसंधान या डीबगिंग | धीमा है और नियमित कार्य के लिए उपयुक्त नहीं है। |
| एपीआई-आधारित निपटान | ज्ञात चुनौती प्रकार के साथ अनुमोदित नियमित वर्कफ़्लो | सटीक संदर्भ, लॉग, और नीति नियंत्रण की आवश्यकता होती है। |
| आगे बढ़ें नहीं | सीमित, निजी, संवेदनशील या अस्वीकृत पहुंच | जारी रखने से कानूनी, गोपनीयता और सुरक्षा जोखिम हो सकते हैं। |
CapSolver के Selenium और Puppeteer के बीच कैप्चा हल करने के लिए लेख ब्राउज़र ऑटोमेशन टूल के चयन के लिए उपयोगी है, जबकि विकासकर्ताओं के लिए ब्राउज़र ऑटोमेशन के गाइड टीमों को ब्राउज़र नियंत्रण को चुनौती निपटान से अलग करने में मदद कर सकते हैं।
वेब स्क्रैपिंग कैप्चा के लिए कार्यान्वयन चेकलिस्ट
वेब स्क्रैपिंग कैप्चा कार्यान्वयन छोटा, निरीक्षण और विलोपन योग्य होना चाहिए। एक स्टेजिंग वर्कफ़्लो और एक सीमित अनुमति सूची से शुरू करें। चुनौती प्रकार, लक्ष्य URL, साइट कुंजी, प्रॉक्सी ID, कार्य ID, कार्य स्थिति, लैटेंसी और अंतिम परिणाम दर्ज करें। यदि साइट अपनी नीति, चुनौती व्यवहार या प्रतिक्रिया स्थिति बदल जाती है, तो कार्य रोकें और वर्कफ़्लो की समीक्षा करें, बजाय दोहराव को बढ़ाने के।
एक व्यावहारिक चेकलिस्ट में अनुमति समीक्षा, रोबोट्स और शर्तों की समीक्षा, डेटा न्यूनतम, डोमेन अनुमति सूची, दर सीमा, ब्राउज़र प्रोफ़ाइल, प्रॉक्सी संगतता, चुनौती निर्धारण, एपीआई कार्य निर्माण, पॉलिंग नीति, समय सीमा, त्रुटि नियंत्रण, लॉग, और पोस्ट-रन समीक्षा शामिल है। टीम अपने आंतरिक दस्तावेज़ीकरण में वेब स्क्रैपिंग और कैप्चा हल करने वाली सेवा के बारे में दिशा-निर्देश जोड़ सकती है क्योंकि यह सेवा के एक व्यापक वर्कफ़्लो के हिस्से के रूप में अलग छोटा
और देखें
Web ScrapingApr 22, 2026
रस्ट वेब स्क्रैपिंग आर्किटेक्चर लिए स्केलेबल डेटा निष्कर्षण
Rust में वेब स्क्रैपिंग के स्केलेबल आर्किटेक्चर सीखें, reqwest, scraper, असिंक्रोनस स्क्रैपिंग, हेडलेस ब्राउज़र स्क्रैपिंग, प्रॉक्सी रोटेशन, और संगत CAPTCHA का निपटारा।
Web ScrapingFeb 03, 2026
रॉक्सीब्राउज़र में कैप्चा हल करना कैपसॉल्वर एकीकरण के साथ
CapSolver के साथ RoxyBrowser के एकीकरण करें ताकि ब्राउज़र के कार्यों को स्वचालित किया जा सके और reCAPTCHA, Turnstile और अन्य CAPTCHAs को बायपास किया जा सके।