¿Qué es Puppeteer y cómo usarlo en el scraping de web | Guía Completa 2026

Adélia Cruz
Neural Network Developer

El scraping web se ha convertido en una habilidad crucial para cualquiera que se dedique a la extracción de datos de la web. Ya sea que seas desarrollador, científico de datos o entusiasta que busca recopilar información de sitios web, Puppeteer es una de las herramientas más poderosas a tu disposición. Esta guía completa explorará qué es Puppeteer y cómo utilizarlo de manera efectiva en el scraping web.
Introducción a Puppeteer
Puppeteer es una biblioteca de Node.js que proporciona una API de alto nivel para controlar Chrome o Chromium a través del protocolo DevTools. Está mantenida por el equipo de Google Chrome y ofrece a los desarrolladores la capacidad de realizar una variedad de tareas del navegador, como generar capturas de pantalla, realizar scraping de sitios web y, lo más importante, scraping web. Puppeteer es muy popular debido a sus capacidades de navegación headless, lo que significa que puede ejecutarse sin una interfaz gráfica, lo que lo hace ideal para tareas automatizadas.
Redime tu código promocional de CapSolver
¡Aumenta tu presupuesto de automatización instantáneamente!
Usa el código promocional CAPN al recargar tu cuenta de CapSolver para obtener un 5% adicional en cada recarga — sin límites.
Redímelo ahora en tu Panel de control de CapSolver
.
¿Por qué usar Puppeteer para el scraping web?
Axios y Cheerio son buenas opciones para el scraping web en JavaScript, pero tienen limitaciones: manejar contenido dinámico y evadir mecanismos anti-scraping.
Como navegador headless, Puppeteer destaca en el scraping de contenido dinámico. Carga completamente la página objetivo, ejecuta JavaScript y puede incluso activar solicitudes XHR para recuperar datos adicionales. Esto es algo que los escrapeadores estáticos no pueden lograr, especialmente con aplicaciones de página única (SPAs) donde el HTML inicial carece de datos significativos.
¿Qué más puede hacer Puppeteer? Puede renderizar imágenes, capturar capturas de pantalla y tiene extensión para resolver diversos tipos de captcha como reCAPTCHA, captcha, captcha. Por ejemplo, puedes programar tu script para navegar por una página, tomar capturas de pantalla en intervalos específicos y analizar esas imágenes para obtener insights competitivos. Las posibilidades son virtualmente ilimitadas.
Uso simple de Puppeteer
Hemos completado la primera parte de ScrapingClub usando Selenium y Python. Ahora, usemos Puppeteer para completar la segunda parte
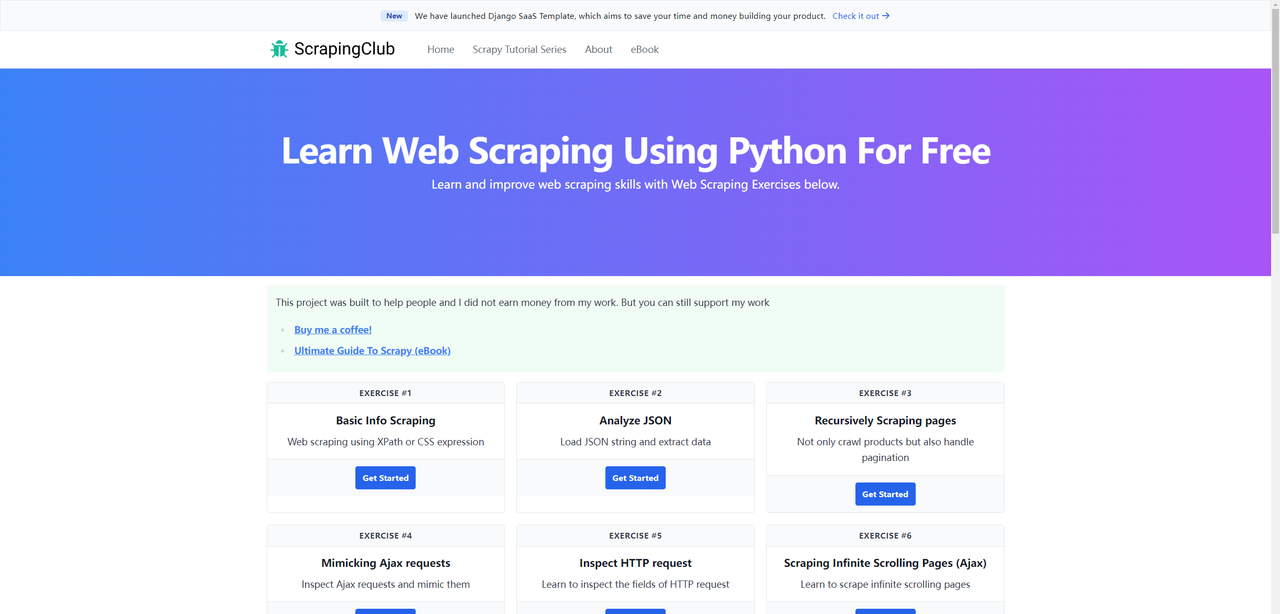
Antes de comenzar, asegúrate de tener Puppeteer instalado en tu máquina local. Si no es así, puedes instalarlo usando los siguientes comandos:
bash
npm i puppeteer # Descarga Chrome compatible durante la instalación.
npm i puppeteer-core # Alternativamente, instálalo como una biblioteca, sin descargar Chrome.Accediendo a una página web
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// Pausa durante 5 segundos
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();El método puppeteer.launch se utiliza para lanzar una nueva instancia de Puppeteer y puede aceptar un objeto de configuración con múltiples opciones. La más común es headless, que especifica si se ejecuta el navegador en modo headless. Si no especificas este parámetro, predeterminadamente es true. Otros parámetros comunes de configuración son los siguientes:
| Parámetro | Tipo | Valor predeterminado | Descripción | Ejemplo |
|---|---|---|---|---|
args |
string[] |
Matriz de argumentos de línea de comandos para pasar al lanzar el navegador | args: ['--no-sandbox', '--disable-setuid-sandbox'] |
|
debuggingPort |
number |
Especifica el número del puerto de depuración a utilizar | debuggingPort: 8888 |
|
defaultViewport |
dict |
{width: 800, height: 600} |
Establece el tamaño predeterminado de la ventana | defaultViewport: {width: 1920, height: 1080} |
devtools |
boolean |
false |
Si se abre automáticamente DevTools | devtools: true |
executablePath |
string |
Especifica la ruta al ejecutable del navegador | executablePath: '/ruta/a/chrome' |
|
headless |
boolean o 'shell' |
true |
Si se ejecuta el navegador en modo headless | headless: false |
userDataDir |
string |
Especifica la ruta al directorio de datos de usuario | userDataDir: '/ruta/a/datos/de-usuario' |
|
timeout |
number |
30000 |
Tiempo de espera en milisegundos para que el navegador se inicie | timeout: 60000 |
ignoreHTTPSErrors |
boolean |
false |
Si se ignora los errores HTTPS | ignoreHTTPSErrors: true |
Configurando el tamaño de la ventana
Para lograr la mejor experiencia de navegación, necesitamos ajustar dos parámetros: el tamaño de la ventana y el tamaño de la vista. El código es el siguiente:
javascript
const puppeteer = require('puppeteer');
(async function() {
const browser = await puppeteer.launch({
headless: false,
args: ['--window-size=1920,1080']
});
const page = await browser.newPage();
await page.setViewport({width: 1920, height: 1080});
await page.goto('https://scrapingclub.com/exercise/detail_json/');
// Pausa durante 5 segundos
await new Promise(r => setTimeout(r, 5000));
await browser.close();
})();Extrayendo datos
En Puppeteer, existen varios métodos para extraer datos.
-
Usando el método
evaluateEl método
evaluateejecuta código JavaScript en el contexto del navegador para extraer los datos necesarios.javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.evaluate(() => { const image = document.querySelector('.card-img-top').src; const title = document.querySelector('.card-title').innerText; const price = document.querySelector('.card-price').innerText; const description = document.querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('Nombre del producto:', data.title); console.log('Precio del producto:', data.price); console.log('Imagen del producto:', data.image); console.log('Descripción del producto:', data.description); // Pausa durante 5 segundos await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
Usando el método
$evalEl método
$evalselecciona un solo elemento y extrae su contenido.javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const title = await page.$eval('.card-title', el => el.innerText); const price = await page.$eval('.card-price', el => el.innerText); const image = await page.$eval('.card-img-top', el => el.src); const description = await page.$eval('.card-description', el => el.innerText); console.log('Nombre del producto:', title); console.log('Precio del producto:', price); console.log('Imagen del producto:', image); console.log('Descripción del producto:', description); // Pausa durante 5 segundos await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
Usando el método
$$evalEl método
$$evalselecciona múltiples elementos a la vez y extrae sus contenidos.javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const data = await page.$$eval('.my-8.w-full.rounded.border > *', elements => { const image = elements[0].querySelector('img').src; const title = elements[1].querySelector('.card-title').innerText; const price = elements[1].querySelector('.card-price').innerText; const description = elements[1].querySelector('.card-description').innerText; return {image, title, price, description}; }); console.log('Nombre del producto:', data.title); console.log('Precio del producto:', data.price); console.log('Imagen del producto:', data.image); console.log('Descripción del producto:', data.description); // Pausa durante 5 segundos await new Promise(r => setTimeout(r, 5000)); await browser.close(); })(); -
Usando los métodos
page.$yevaluateEl método
page.$selecciona elementos y el métodoevaluateejecuta código JavaScript en el contexto del navegador para extraer datos.javascriptconst puppeteer = require('puppeteer'); (async function () { const browser = await puppeteer.launch({ headless: false, args: ['--window-size=1920,1080'] }); const page = await browser.newPage(); await page.setViewport({width: 1920, height: 1080}); await page.goto('https://scrapingclub.com/exercise/detail_json/'); const imageElement = await page.$('.card-img-top'); const titleElement = await page.$('.card-title'); const priceElement = await page.$('.card-price'); const descriptionElement = await page.$('.card-description'); const image = await page.evaluate(el => el.src, imageElement); const title = await page.evaluate(el => el.innerText, titleElement); const price = await page.evaluate(el => el.innerText, priceElement); const description = await page.evaluate(el => el.innerText, descriptionElement); console.log('Nombre del producto:', title); console.log('Precio del producto:', price); console.log('Imagen del producto:', image); console.log('Descripción del producto:', description); // Pausa durante 5 segundos await new Promise(r => setTimeout(r, 5000)); await browser.close(); })();
Evitar las protecciones contra scraping
Completar los ejercicios de ScrapingClub es relativamente sencillo. Sin embargo, en escenarios reales de extracción de datos, obtener datos no siempre es tan fácil. Algunos sitios web utilizan tecnologías anti-scraping que pueden detectar tu script como un bot y bloquearlo. La situación más común implica desafíos de CAPTCHA como captcha, captcha, recaptcha, captcha y captcha.
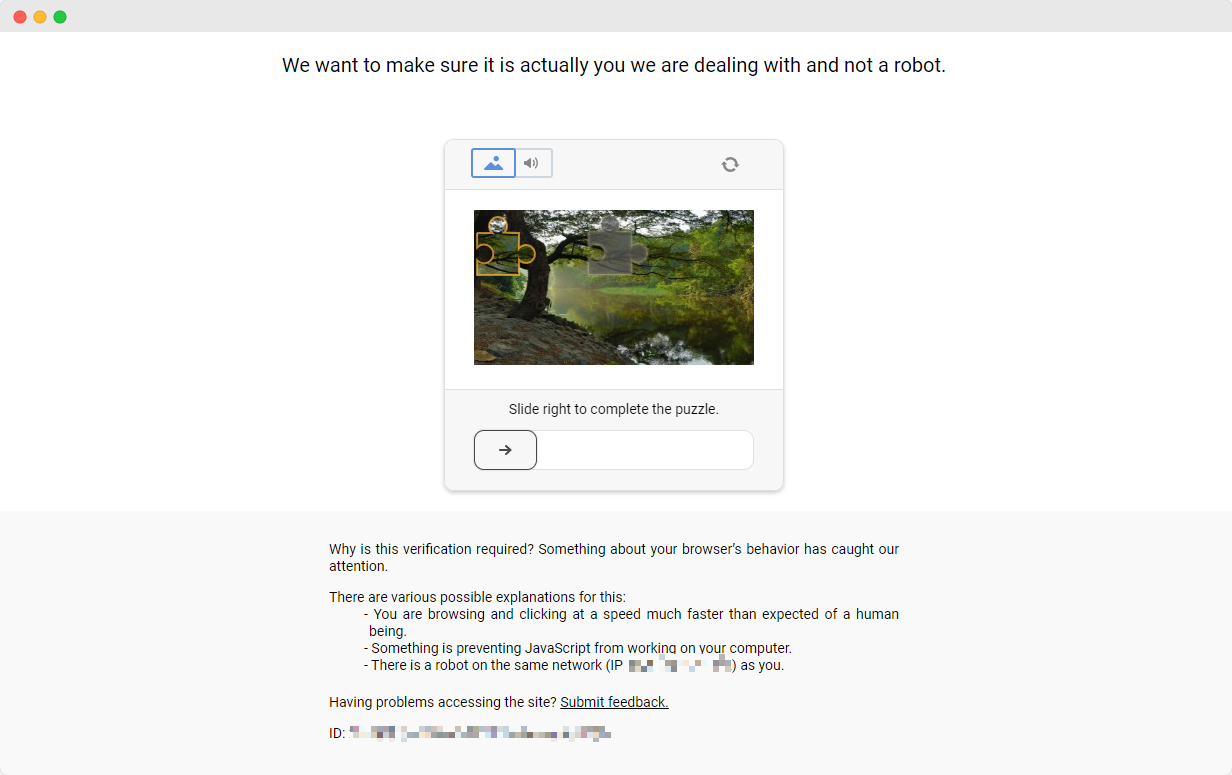
Para resolver estos desafíos de CAPTCHA, se necesita experiencia extensa en aprendizaje automático, ingeniería inversa y contra medidas de fingerprinting del navegador, lo cual puede tomar mucho tiempo.
Afortunadamente, ya no necesitas manejar todo este trabajo tú mismo. CapSolver ofrece una solución integral que te ayuda a resolver fácilmente todos los desafíos. CapSolver ofrece una extensión del navegador que te permite resolver automáticamente los desafíos de CAPTCHA mientras usas Puppeteer para la extracción de datos. Además, proporciona un método de API para resolver CAPTCHAS y obtener tokens. Todo esto se puede hacer en unos pocos segundos. ¡Consulta este documento para descubrir cómo resolver los diversos desafíos de CAPTCHA que has encontrado!
Conclusión
El scraping web es una habilidad invaluable para cualquiera involucrado en la extracción de datos de la web, y Puppeteer, como herramienta con una API avanzada y características poderosas, es una de las mejores opciones para lograr este objetivo. Su capacidad para manejar contenido dinámico y resolver mecanismos anti-scraping lo hace destacar entre las herramientas de scraping.
En esta guía, exploramos qué es Puppeteer, sus ventajas en el scraping web y cómo configurarlo y usarlo de manera efectiva. Mostramos con ejemplos cómo acceder a páginas web, configurar tamaños de vista y extraer datos usando diversos métodos. Además, discutimos los desafíos impuestos por tecnologías anti-captura y cómo CapSolver ofrece una solución poderosa para el desafío de CAPTCHA.
Preguntas frecuentes
1. ¿Para qué se utiliza principalmente Puppeteer en el scraping web?
Puppeteer se utiliza para controlar un navegador Chrome/Chromium real, permitiéndole cargar JavaScript dinámico, renderizar páginas SPA, interactuar con elementos y extraer datos que los escrapeadores basados en HTTP no pueden acceder.
2. ¿Puppeteer puede manejar desafíos de CAPTCHA en sitios web?
Puppeteer solo no puede evitar CAPTCHAS, pero al combinarse con la extensión del navegador de CapSolver o su método de API, puede resolver automáticamente reCAPTCHA, hCaptcha, FunCAPTCHA y otros desafíos de verificación durante las tareas de scraping.
3. ¿Es necesario que Puppeteer se ejecute con una ventana de navegador visible?
No. Puppeteer admite el modo headless, donde Chrome se ejecuta sin interfaz gráfica. Este modo es más rápido y ideal para automatización. También puedes ejecutarlo en modo no headless para depurar o monitorear visualmente.
Ver más
Web ScrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

Web ScrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.

