Cómo resolver el desafío de Cloudflare en Crawl4AI con la integración de CapSolver

Adélia Cruz
Neural Network Developer
Introducción
El desafío de Cloudflare es un mecanismo anti-bot sofisticado que a menudo implica verificaciones complejas, incluyendo la huella digital del navegador y la validación del User-Agent, para distinguir entre usuarios legítimos y tráfico automatizado. Estos desafíos pueden dificultar significativamente los esfuerzos de scraping web y extracción de datos, dificultando que los crawlers accedan a los sitios web objetivo. Superar el desafío de Cloudflare requiere una solución robusta y adaptable que pueda imitar el comportamiento de un navegador real.
Este artículo proporciona una guía completa sobre la integración de Crawl4AI, un raspador web avanzado, con CapSolver, un servicio líder de solución de CAPTCHA y mecanismos anti-bot, para superar eficazmente las protecciones del desafío de Cloudflare. Nos centraremos en el método de integración basado en API, proporcionando ejemplos de código detallados y explicaciones para garantizar que sus tareas de automatización web puedan proseguir sin interrupciones.
Comprensión del desafío de Cloudflare y sus complejidades para el scraping web
El desafío de Cloudflare está diseñado para ser más agresivo que las CAPTCHAs típicas, a menudo empleando una combinación de técnicas para identificar y bloquear bots:
- Huella digital del navegador: Analizar características únicas del navegador para detectar automatización.
- Validación del User-Agent: Requerir cadenas de User-Agent específicas y consistentes que coincidan con versiones reales de navegadores.
- Ejecución de JavaScript: Ejecutar JavaScript complejo en segundo plano para verificar las capacidades del navegador y la interacción similar a la humana.
- Gestión de cookies: Establecer y validar cookies específicas como parte del proceso de resolución del desafío.
CapSolver proporciona el tipo de tarea AntiCloudflareTask, específicamente diseñado para abordar estos desafíos complejos al proporcionar los tokens, cookies necesarios y recomendar User-Agents específicos. Al integrarlo con Crawl4AI, esto permite a sus crawlers navegar con éxito por sitios protegidos por Cloudflare.
Método de integración: Integración de la API de CapSolver con Crawl4AI
El método de integración de API es crucial para manejar el desafío de Cloudflare, ya que permite un control preciso sobre las configuraciones del navegador y la inyección de tokens y cookies necesarios. Este método implica usar CapSolver para obtener la solución requerida del desafío (token, cookies y User-Agent) y luego configurar Crawl4AI para usar estos parámetros.
Cómo funciona:
- Obtener la solución del desafío de Cloudflare: Antes de lanzar el raspador, llame a la API de CapSolver usando su SDK, especificando el tipo de tarea
AntiCloudflareTask. Deberá proporcionar lawebsiteURL, unproxy(si es aplicable) y unuserAgentque coincida con la versión del navegador que CapSolver utiliza para resolver. - Configurar el navegador de Crawl4AI: Utilice la solución devuelta por CapSolver (que incluye un
token,cookiesy unuserAgentrecomendado) para configurar elBrowserConfigde Crawl4AI. Esto asegura que la instancia del navegador de Crawl4AI imite el entorno utilizado para resolver el desafío. - Lanzar el raspador: Crawl4AI luego ejecuta con el navegador especialmente configurado, que incluye las cookies y User-Agent necesarios, permitiendo que evite el desafío de Cloudflare.
- Continuar las operaciones: Con el desafío de Cloudflare superado con éxito, Crawl4AI puede proseguir con sus tareas de extracción de datos en el sitio web objetivo.
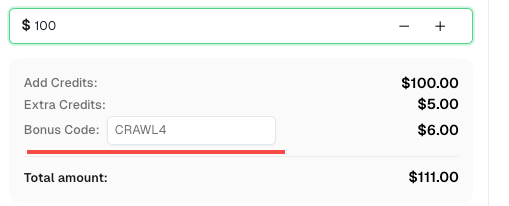
💡 Bonificación exclusiva para usuarios de integración de Crawl4AI:
Para celebrar esta integración, ofrecemos un código de bonificación exclusivo de 6% —CRAWL4para todos los usuarios de CapSolver que se registren a través de este tutorial.
Simplemente ingrese el código durante el recarga en Panel de control para recibir créditos adicionales de 6% de inmediato.
Ejemplo de código: Integración de API para el desafío de Cloudflare
El siguiente código de Python demuestra cómo integrar la API de CapSolver con Crawl4AI para resolver el desafío de Cloudflare. Este ejemplo apunta a una página de artículo de noticias protegida por Cloudflare.
python
import asyncio
import time
import capsolver
from crawl4ai import *
# TODO: configure su configuración
api_key = "CAP-XXX" # su clave de API de CapSolver
site_url = "https://www.tempo.co/hukum/polisi-diduga-salah-tangkap-pelajar-di-magelang-yang-dituduh-perusuh-demo-2070572" # URL de su sitio objetivo
captcha_type = "AntiCloudflareTask" # tipo de su CAPTCHA objetivo
api_proxy = "http://127.0.0.1:13120"
capsolver.api_key = api_key
user_data_dir = "./crawl4ai_/browser-profile/Default1493"
# o
cdp_url = "ws://localhost:xxxx"
async def main():
print("inicio de solución de token")
start_time = time.time()
# obtener token de Cloudflare usando el SDK de capsolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"proxy": api_proxy,
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
})
token_time = time.time()
print(f"solución de token: {token_time - start_time:.2f} s")
# establecer cookies
cookies = solution.get("cookies", [])
if isinstance(cookies, dict):
cookies_array = []
for name, value in cookies.items():
cookies_array.append({
"name": name,
"value": value,
"url": site_url,
})
cookies = cookies_array
elif not isinstance(cookies, list):
cookies = []
token = solution["token"]
print("token de desafío:", token)
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
user_data_dir=user_data_dir,
# cdp_url=cdp_url,
user_agent=solution["userAgent"],
cookies=cookies,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
print(result.markdown[:500])
if __name__ == "__main__":
asyncio.run(main())Análisis del código:
- Llamada al SDK de CapSolver: El método
capsolver.solvees central aquí, utilizando el tipoAntiCloudflareTask. RequierewebsiteURL,proxyy unuserAgentespecífico. CapSolver procesa el desafío y devuelve un objetosolutionque contiene untoken,cookiesy eluserAgentutilizado para resolver el desafío. - Configuración del navegador: El
BrowserConfigpara Crawl4AI se configura cuidadosamente usando la información de la solución de CapSolver. Esto incluyeuser_agentycookiespara asegurar que la instancia del navegador de Crawl4AI coincida perfectamente con las condiciones en las que se resolvió el desafío de Cloudflare. También se especificauser_data_dirpara mantener un perfil de navegador consistente. - Ejecución del raspador: Crawl4AI luego ejecuta su método
aruncon estabrowser_configcuidadosamente configurada, permitiéndole acceder con éxito a la URL objetivo sin activar nuevamente el desafío de Cloudflare.
Conclusión
Superar el desafío de Cloudflare en el scraping web es una tarea compleja que requiere un enfoque sofisticado. La integración de Crawl4AI con CapSolver proporciona una solución poderosa y efectiva, permitiendo a los desarrolladores navegar a través de estas protecciones anti-bot avanzadas de manera fluida. Al aprovechar la tarea especializada AntiCloudflareTask de CapSolver para obtener los tokens, cookies y User-Agent necesarios, y luego configurar el navegador de Crawl4AI para que coincida con estos parámetros, puede asegurar la estabilidad y el éxito de sus operaciones de scraping web.
Esta sinergia entre las capacidades avanzadas de raspado de Crawl4AI y la tecnología anti-bot robusta de CapSolver marca un avance significativo en la extracción automatizada de datos web, permitiéndole enfocarse en recopilar datos valiosos sin ser obstaculizado por las medidas de protección de Cloudflare.
Preguntas frecuentes (FAQ)
P1: ¿Qué es el desafío de Cloudflare y por qué se utiliza?
R1: El desafío de Cloudflare es un mecanismo anti-bot avanzado diseñado para verificar si un visitante es un humano real o un script automatizado. Utiliza diversas técnicas como la huella digital del navegador, la validación del User-Agent y la ejecución de JavaScript para proteger sitios web contra bots maliciosos, ataques DDoS y otros riesgos.
P2: ¿Por qué el desafío de Cloudflare es particularmente difícil para los raspadores?
R2: El desafío de Cloudflare es difícil para los raspadores porque va más allá de las CAPTCHAs simples. Analiza activamente las características del navegador, requiere cadenas de User-Agent consistentes, ejecuta JavaScript complejo y gestiona cookies específicas. Esta detección sofisticada hace difícil que las herramientas automatizadas imiten la interacción humana genuina sin soluciones especializadas.
P3: ¿Cómo ayuda CapSolver a superar el desafío de Cloudflare?
R3: CapSolver proporciona un tipo de tarea especializado, AntiCloudflareTask, para resolver desafíos de Cloudflare. Procesa el desafío y devuelve una solución que incluye un token, cookies necesarias y un User-Agent recomendado. Esta información luego se utiliza para configurar Crawl4AI para superar con éxito el desafío.
P4: ¿Cuáles son las consideraciones clave al integrar Crawl4AI y CapSolver para el desafío de Cloudflare?
R5: Las consideraciones clave incluyen asegurar que el userAgent utilizado en su configuración de Crawl4AI coincida con el proporcionado por CapSolver, manejar correctamente e inyectar las cookies devueltas por CapSolver y proporcionar un proxy si sus operaciones de scraping lo requieren. Estos pasos aseguran que el entorno del navegador de Crawl4AI refleje con precisión las condiciones en las que se resolvió el desafío.
Referencias
Ver más
CloudflareMar 26, 2026
Solucionar el error de Cloudflare 1005: Guía y soluciones de scraping web
Aprende a solucionar el error de Cloudflare 1005 acceso denegado durante el scraping de web. Descubre soluciones como proxies residenciales, fingerprinting del navegador y CapSolver para CAPTCHA. Optimiza tu extracción de datos.

CloudflareMar 17, 2026
Cómo navegar Cloudflare Turnstile con Playwright Stealth en Flujos de Trabajo de IA
Descubre cómo manejar eficazmente Cloudflare Turnstile en flujos de trabajo de IA utilizando técnicas de stealth de Playwright y CapSolver para la resolución confiable de captchas. Aprende estrategias de integración prácticas y mejores prácticas para automatización ininterrumpida.