How AI Data Extraction Works: CAPTCHA Solving, LLM Parsing & Structured Web Data Pipelines

Lucas Mitchell
Automation Engineer
Introduction: Beyond Parsing, It's About Acquisition
Traditional web data extraction relies on mechanical matching methods such as CSS selectors, XPath, and regular expressions, which lock onto fixed positions in the DOM tree to retrieve values. Faced with frequent page redesigns, the widespread adoption of dynamic rendering, and multi-layered anti-scraping upgrades, this paradigm has exposed structural weaknesses such as high maintenance costs and "blindness" to asynchronous content. The maturity of large language models (LLMs) brings a turning point: data extraction no longer asks “in which tag is the data located?”, but rather understands “what question does the page content answer?”, entering a new paradigm driven by natural language understanding. This shift is not purely theoretical; frameworks like AXE, by pruning irrelevant DOM nodes and combining with smaller models to generate structured output, have surpassed larger models with an F1 score of 88.1% on the SWDE dataset, validating the feasibility and efficiency of semantic extraction. This article will, from an engineering implementation perspective, deconstruct the technical principles and key trade-offs of each stage according to the data flow sequence, from the data acquisition layer dealing with anti-crawling and CAPTCHAs, to the processing layer of content cleaning and LLM semantic extraction, finally arriving at the storage and consumption of structured data.
I. Paradigm Shift: From Rule-Based Parsing to Natural Language Processing
Before delving into the technical details of AI data extraction, it is necessary to understand why the old paradigm it replaces has reached its limits, and in what dimension the new paradigm has achieved a breakthrough.
1.1 Three Dilemmas of the Rule-Based Parsing Era
The core method of traditional web data extraction is “path positioning”: developers inspect the DOM node where the target data is located using browser developer tools, and then manually write CSS selectors or XPath expressions to pinpoint that node. This paradigm has supported the vast majority of web data collection needs over the past decade, but it has three structural flaws that have continuously amplified with the evolution of web technology.
1.1.1 Fragile Anchors: Static Rules Unable to Adapt to a Dynamic World
Modern websites undergo significant DOM structure changes every 3 to 6 months on average. Each redesign means that crawler rules based on fixed paths become invalid. For teams maintaining hundreds of target nodes simultaneously, this constitutes a continuous “whack-a-mole” maintenance cycle. Figure 1-1 illustrates the complete workflow of traditional crawlers when facing modern websites, showing each stage from request to data extraction and the problems encountered:
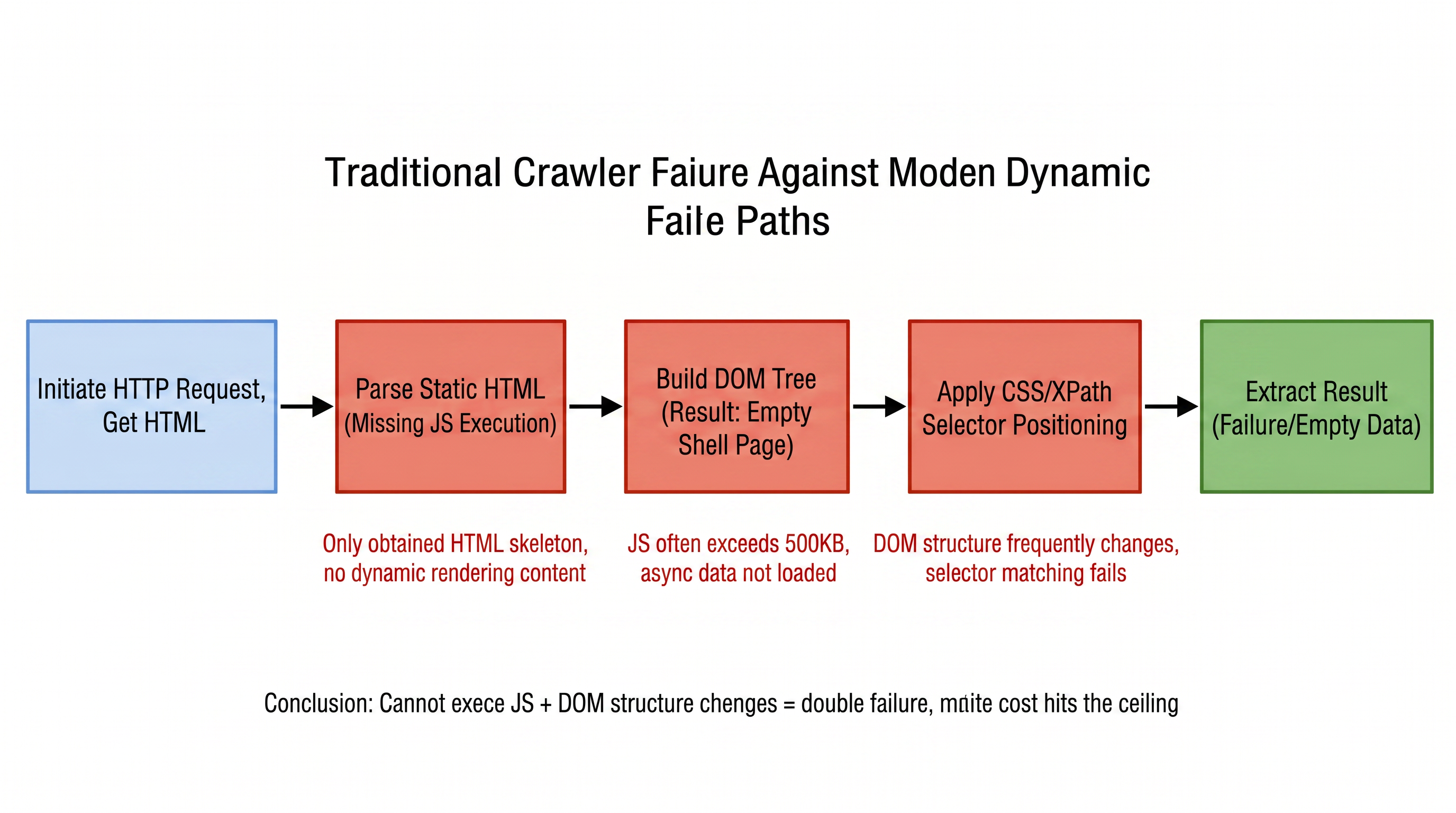
This process reveals the core logic of the first dilemma: the mismatch between static parsing capabilities and dynamically rendered content. According to W3Techs statistics, by the end of 2025, approximately X% of websites globally will use anti-scraping services like Cloudflare. Based on Netcraft’s concurrent detection of the total number of websites, this involves over 290 million sites, and the median JS size of web pages exceeds 500KB. Traditional crawlers can only obtain the unrendered skeleton, not only “seeing no data” but also, once the website is redesigned, the painstakingly written selectors immediately become invalid. This “technical incapacitation” and “maintenance fragility” superimpose, continuously narrowing the scope of rule-based parsing.
1.1.2 Blind Eyes: Syntactic Matching Completely Fails to Grasp Semantics
Traditional methods can only answer “the data is at this position,” not “what is the data at this position?” On the same product listing page, there might be promotional prices, recommended prices, and product prices simultaneously—they have identical tags in the DOM, making it impossible for traditional rules to distinguish them. Faced with three heterogeneous date formats like “2026-04-28,” “April 28, 2026,” and “28/04/2026,” traditional parsers need to write separate regular expressions for each format and cannot cope with dynamic changes in format. Figure 1-2 uses a radar chart to visually compare the differences between traditional rule-based parsing and AI semantic extraction across six core dimensions:
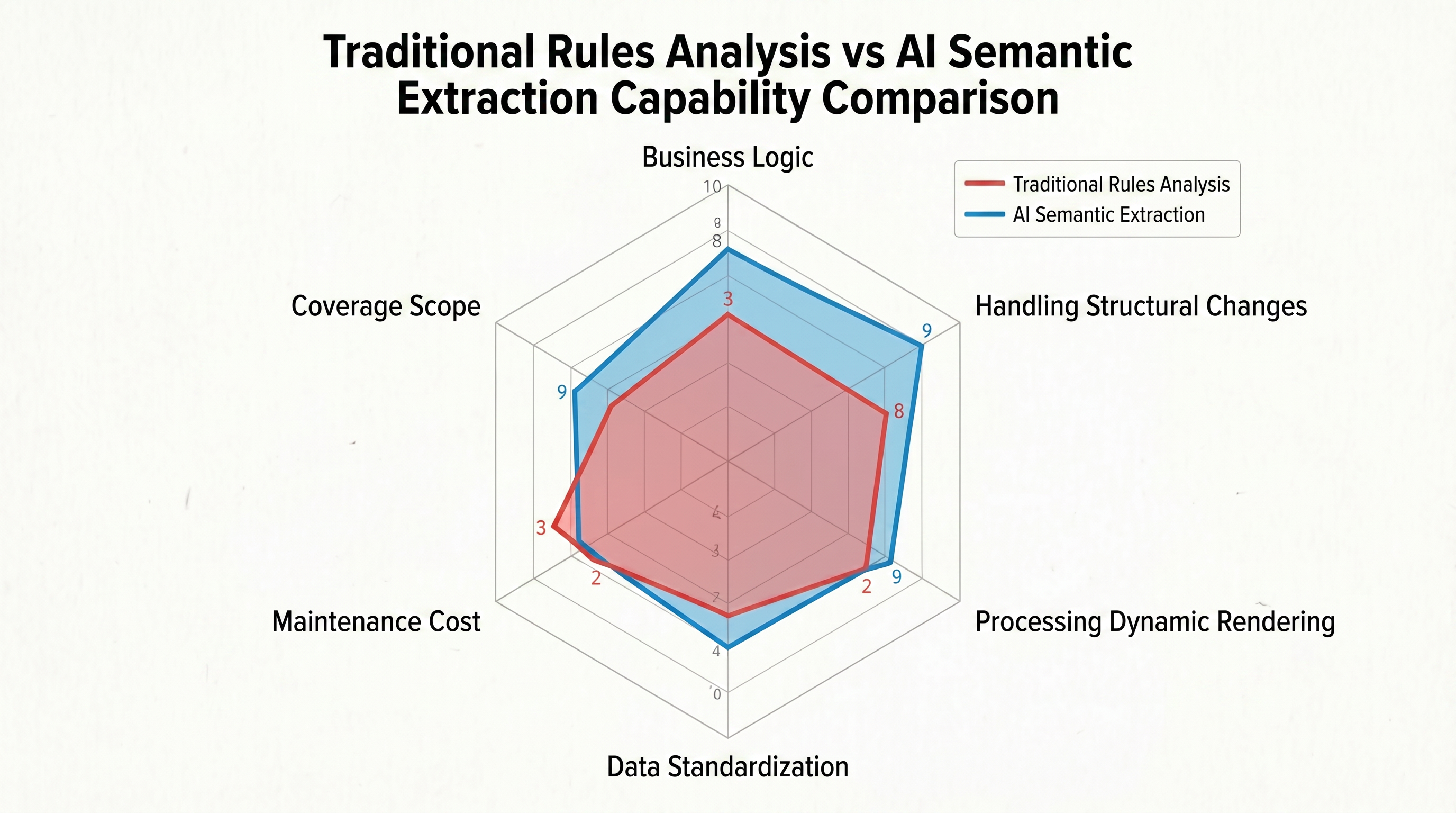
The shape of the radar chart clearly shows that traditional rule-based parsing relies on precise DOM path positioning in the “working logic” dimension, which is its only executable strategy. However, in the other five dimensions, its performance is comprehensively constrained—its ability to adapt to structural changes is extremely weak, dynamic rendering processing relies entirely on external tools, data standardization requires manual regular expression writing, maintenance costs increase linearly with the number of sites, and its coverage is limited to one set of rules per site. Five of the six axes are severely recessed, and the graph appears as a “compressed” irregular polygon.
In contrast, the radar chart for AI semantic extraction expands evenly both internally and externally: it automatically adapts to structural changes based on semantic understanding, fully processes dynamic rendering with the browser, achieves zero-rule standardization through LLM’s internalized format conversion capabilities, maintenance costs decrease with improved model capabilities, and a single Schema can cover similar pages across an entire site.
Each of these six capability shortcomings is not an isolated technical bottleneck but a natural consequence of the underlying logic of “mechanical matching”—as long as data extraction remains at the syntactic level, no matter how cleverly designed the rules are, this structural limitation cannot be overcome. Therefore, to thoroughly solve these problems, what is needed is not to patch the rules, but to change the paradigm.
1.1.3 The Tangible Ceiling: Why This Paradigm is Destined to Be Replaced
All the dilemmas of the rule-based parsing paradigm stem from one source: it always performs “mechanical matching” at the “syntactic level.” This working logic determines its ability to achieve “precise positioning”—accurately finding the DOM path of the data—but at the cost of “passively adapting” to every page structure change. If the site is redesigned, the rules become invalid; if data types are heterogeneous, new regular expressions need to be manually written. This mode of being led by the target website constitutes a “structural ceiling” that rule-based parsing cannot overcome. Figure 1-3 previews the fundamental leap direction of this paradigm in the form of a comparative evolution.
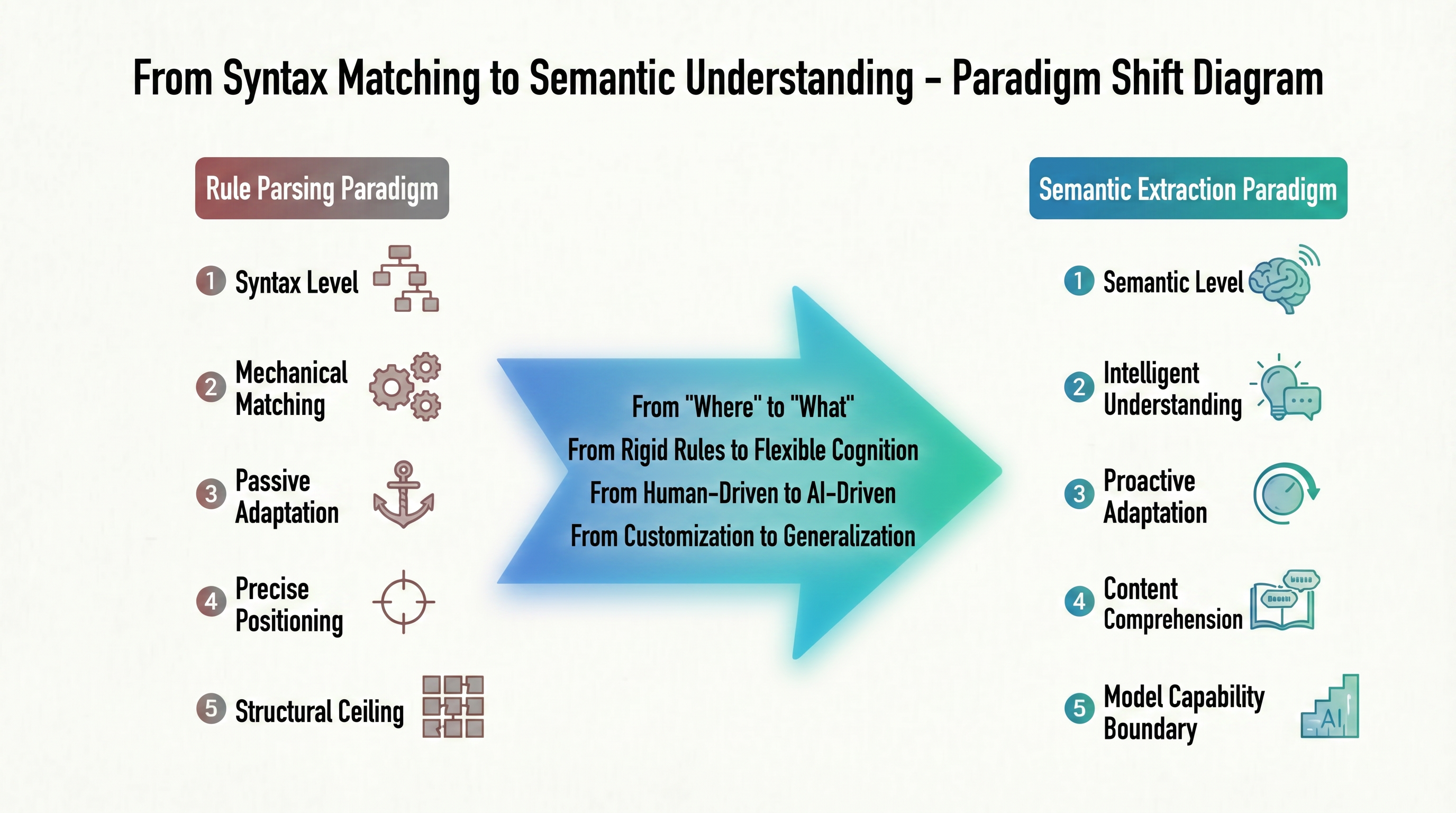
From the figure above, it is clear that this is not a technical improvement along the same path, but two fundamentally different paths. The rule-based parsing paradigm on the left is built on the “syntactic level,” aiming for “precise positioning,” passively adapting to structural changes, and quickly hitting a “structural ceiling”—it is like a person who knows a passage in a book is on page 3, line 5, but has no idea what the passage is about. The semantic extraction paradigm on the right fundamentally changes the working level: from “syntax” to “semantics,” from “mechanical matching” to “intelligent understanding.” Its goal is no longer to locate node coordinates, but to directly understand the page content itself, and its capability boundaries are no longer determined by DOM changes.
This also explains why the three dilemmas of the rule-based parsing era are not independent problems, but different manifestations of the underlying logic of “syntactic matching.” As long as data extraction technology remains at the syntactic level, no matter how elaborate the rule design, it cannot break through the structural paradox of coexisting “precise positioning” and “semantic blind spots.” Therefore, the emergence of the AI semantic extraction paradigm is not an acceleration on the old path, but a revolution at the cognitive level, from “finding positions” to “understanding content.” The specific mechanisms and advantages of this paradigm shift will be elaborated in Section 1.2.
1.2 AI Paradigm: From Syntactic Matching to Semantic Understanding
AI-driven methods completely redefine how problems are approached. Figure 1-4 compares the fundamental differences between rule-based parsing and AI semantic paradigms across four dimensions: core problem, dependent factors, adaptation to changes, and expansion mode:
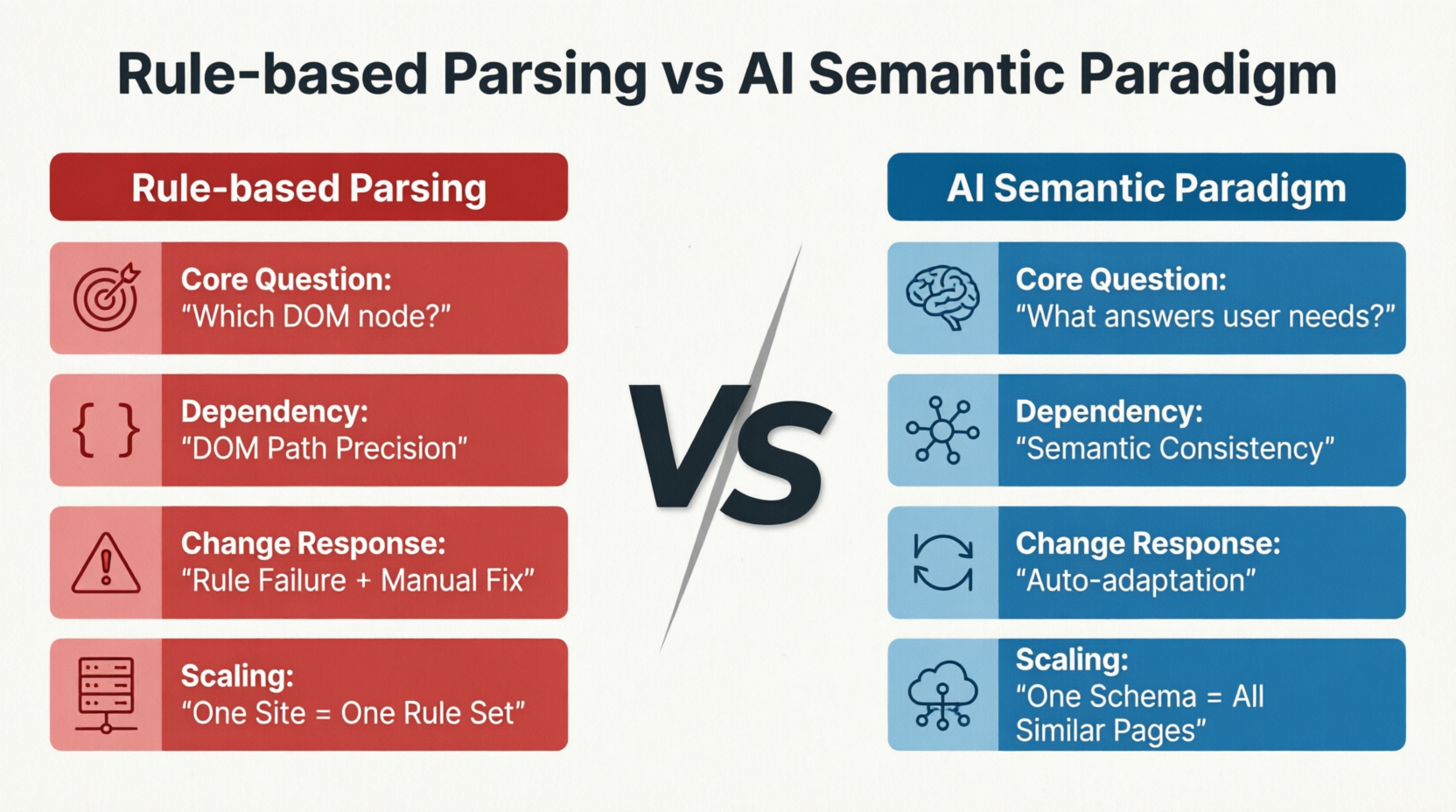
Traditional methods ask “where is the data in the DOM node?”, while AI methods ask “what content on the page is the core information of interest to the user?” This difference in questioning determines the divergence of all subsequent technical routes: the former relies on the precision of DOM paths, and once the page is redesigned or nodes shift, the rules become invalid and must be manually repaired; the latter relies on the consistency of page semantics. DOM structures can change, and data positions can move, but as long as the semantic content remains unchanged, the model can still correctly identify and extract it. In terms of expansion mode, rule-based parsing requires rewriting a set of rules for each new site, while the AI semantic paradigm can horizontally cover similar pages across an entire site with the same Schema.
It is this shift from “precise syntactic positioning” to “fuzzy semantic understanding” that gives AI methods the robustness that traditional rules lack. The AXE framework proposed by academia provides the clearest engineering example of this paradigm shift. Figure 1-5 summarizes its core processing flow:
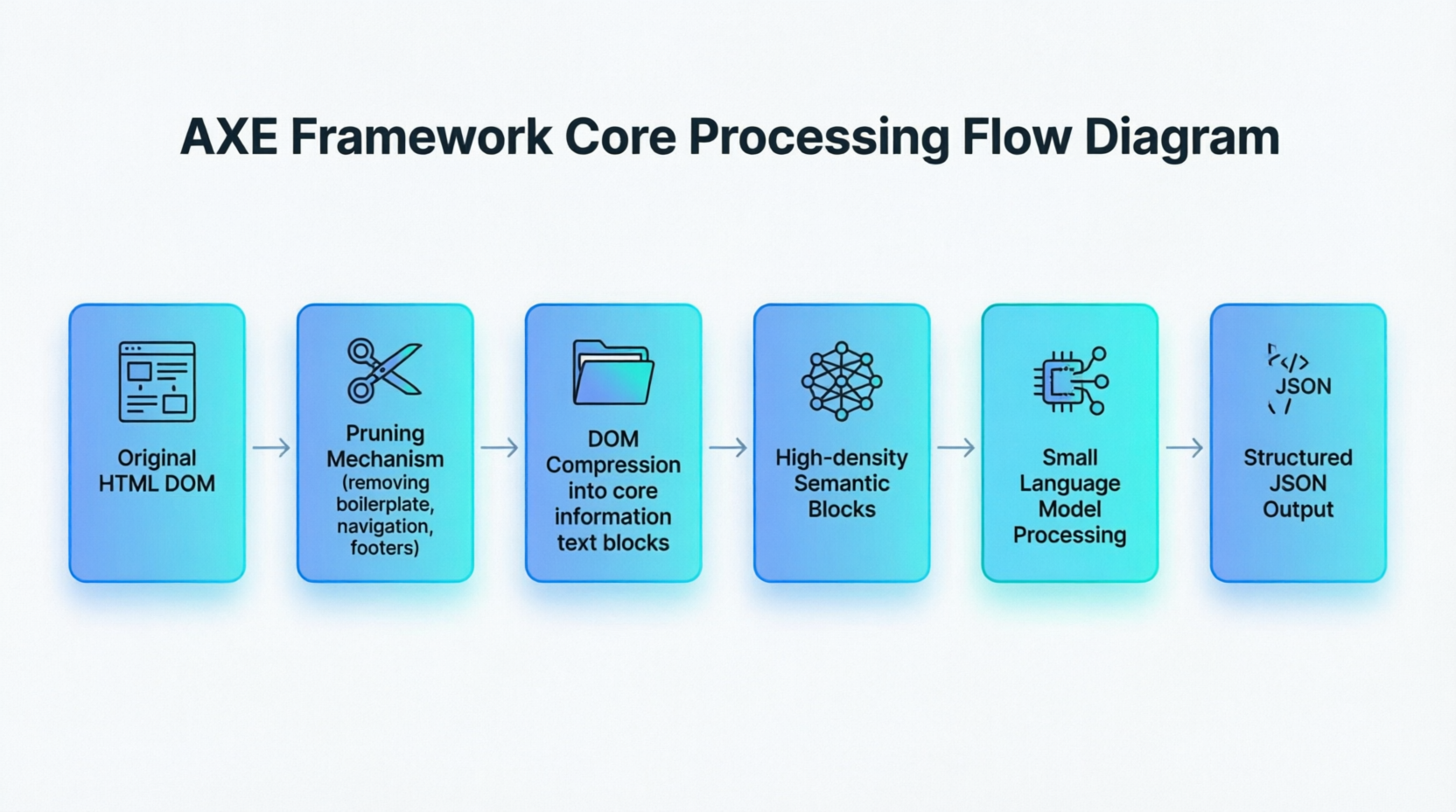
Figure 1-5 shows a complete chain from raw HTML to structured output: AXE first treats the HTML DOM as a tree that needs pruning, stripping irrelevant nodes such as navigation bars, footers, and boilerplate code through a specialized pruning mechanism; then the DOM is compressed into a few high-density semantic blocks containing core information; finally, a lightweight small model reads these semantic blocks to generate structured JSON output. The entire process bypasses the DOM path positioning that traditional methods must rely on, acting directly on the page’s semantic content.
On the SWDE dataset, which covers 8 vertical domains and over 80 real websites, AXE achieved an F1 score of 88.1%, surpassing multiple models much larger than itself. This result proves a counter-intuitive but crucial fact: semantic extraction capability does not depend on giant models; a carefully designed and specifically trained miniature model can also achieve production-level accuracy. This is the core evidence that the AI semantic paradigm is competitive in terms of cost and engineering feasibility.
Another representative work, Dripper, takes a different technical route, redefining main content extraction as a “semantic block sequence classification” task. Figure 1-6 uses a card comparison to juxtapose the differences in methods between AXE and Dripper, as well as the resulting evolution of operation and maintenance modes between the rule era and the AI era:
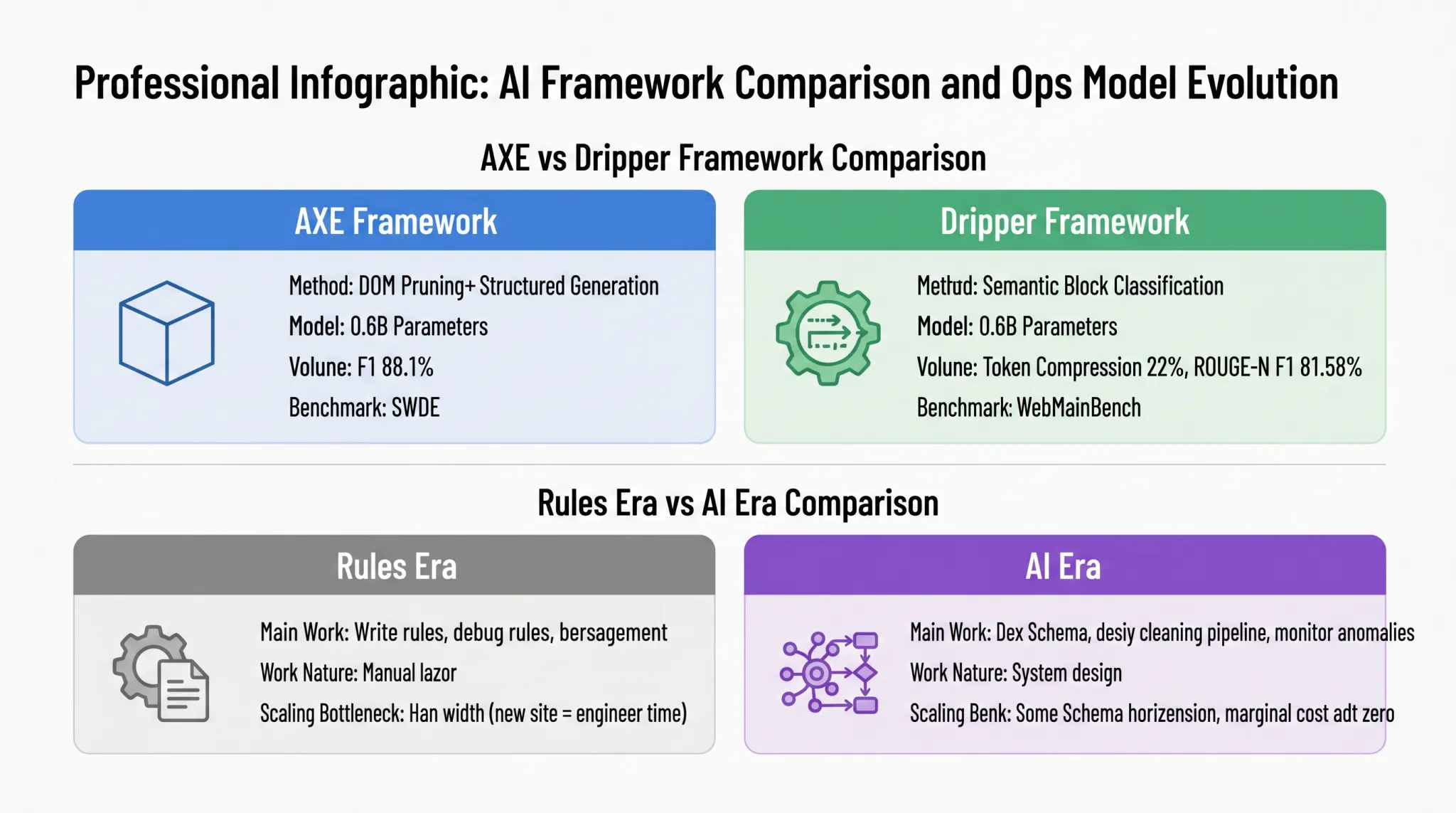
AXE adopts the “DOM pruning + structured generation” path, compressing HTML DOM into high-density semantic blocks and then directly outputting JSON via a small model; Dripper takes the “semantic block binary classification” route, transforming main content extraction into a classification task of determining whether each semantic block belongs to the main text. Both models have a similar scale of 0.6B parameters and have achieved production-ready accuracy on their respective benchmarks. AXE achieved an F1 score of 88.1% on the SWDE dataset, while Dripper compressed input tokens to 22% of the original HTML and achieved an 81.58% ROUGE-N F1 score on WebMainBench. These two different paths point to the same conclusion: AI data extraction is competitive in accuracy and does not rely on giant models; a carefully designed miniature model can also be competent.
The right half reveals a deeper meaning of the paradigm shift: it not only changes the technical route but also reconstructs the daily operation mode of data teams. The main work in the rule era was writing rules, fixing rules, and version management, which was essentially manual labor. The bottleneck for expansion lay in human bandwidth: every time a new target site was added, engineers’ time had to be invested to rewrite and debug rules. In the AI era, the focus of work shifts to defining Schemas, designing cleaning pipelines, and monitoring abnormal cases. The nature changes from manual labor to system design, and the expansion mode also changes from “one set of rules per site” to “horizontal extension with the same Schema.” Adding similar sites requires almost no additional engineering investment, and the marginal cost approaches zero. This shift frees data extraction capabilities from human bandwidth limitations, redefining the economics of data collection.
II. Core Process of AI Data Structured Extraction
The complete AI data extraction Pipeline includes 7 stages, which can be divided into three functional groups:
- Data Acquisition Layer (URL Queue → Web Scraping → Anti-Scraping Detection): Responsible for “getting” the HTML of the target page in a complex network environment. This is the highest risk zone of the entire Pipeline, with the 14% core bottleneck indicated in Figure 2-2 pointing to this layer.
- Content Processing Layer (Content Cleaning → LLM Parsing → Schema Validation): Responsible for transforming noisy raw HTML into high-quality structured data. The accuracy bottleneck (18%) is mainly concentrated in the content cleaning stage of this layer.
- Data Storage Layer (Data Storage): The final output for downstream consumption, accounting for approximately 5% of the entire link’s load.
This chapter will focus on the technical details of Layer 2, the content processing layer, demonstrating how AI semantic extraction fundamentally surpasses traditional rule engines. For Layer 1, the critical prerequisite that determines whether data can flow into the processing layer, we will conduct a dedicated breakdown and practical solution discussion in Chapter 3.
2.1 AI Data Extraction Pipeline
Before delving into the processing layer, let’s take a bird’s-eye view of the entire Pipeline through Figure 2-1 to understand the complete path from URL queuing to data storage and the actual traffic distribution at each stage. This serves as an overview for this chapter and lays the groundwork for tackling bottlenecks in Chapter 3.

The URL queue is the entry point of the Pipeline, managing the list of URLs to be crawled and controlling the request rhythm. As shown in Figure 2-1, approximately 32% of requests in the URL scheduling stage are already pre-marked with CAPTCHA risks, while 68% can directly initiate normal requests. The web scraping stage is responsible for initiating HTTP requests or driving browser rendering to obtain the raw content of the page. At this point, 12% of requests will be directly intercepted by CAPTCHAs, and 80% can smoothly enter downstream stages.
After initial scraping, requests enter the anti-scraping detection stage. Modern anti-scraping systems simultaneously analyze signals from four dimensions: IP reputation, TLS fingerprint, browser characteristics, and behavior patterns, performing multi-layered cross-validation. Figure 2-1 shows that approximately 10% of traffic in the anti-scraping detection stage will be identified as automated requests and intercepted, and 20% requires reliance on IP proxy pools and TLS fingerprint spoofing to bypass detection. This is the most uncertain node in the entire Pipeline. Once a CAPTCHA is triggered and not handled, all subsequent stages’ computing resources will be idle.
After passing anti-scraping detection, raw HTML content is obtained. A typical news page’s raw HTML can exceed 2MB, reaching 300,000 to 500,000 tokens after processing with OpenAI’s tiktoken tokenizer, filled with navigation menus, embedded CSS, Base64 encoded tracking pixels, and compressed JavaScript. Therefore, content cleaning is an essential step. Figure 2-1 shows that HTML to Markdown conversion accounts for 50% of the work in this stage, and DOM simplification and noise removal account for 30%. These two combined compress the raw HTML into high-density semantic text, ensuring that LLM’s effective computing power is focused on information rather than noise.
The cleaned text then enters the LLM parsing stage, where the model extracts structured fields from the text according to a predefined Schema. Figure 2-1 combines this stage with the subsequent Schema validation, showing an accuracy rate of 94.7%. This means that approximately 1 in 20 extractions will fail to pass field completeness or format consistency checks. The successful outputs become structured JSON data, which is finally stored in systems like PostgreSQL or MongoDB for downstream business consumption.
To more clearly break down the technical carriers, performance indicators, and engineering bottlenecks of each stage, Figure 2-2 presents a panoramic view in the form of a dashboard:
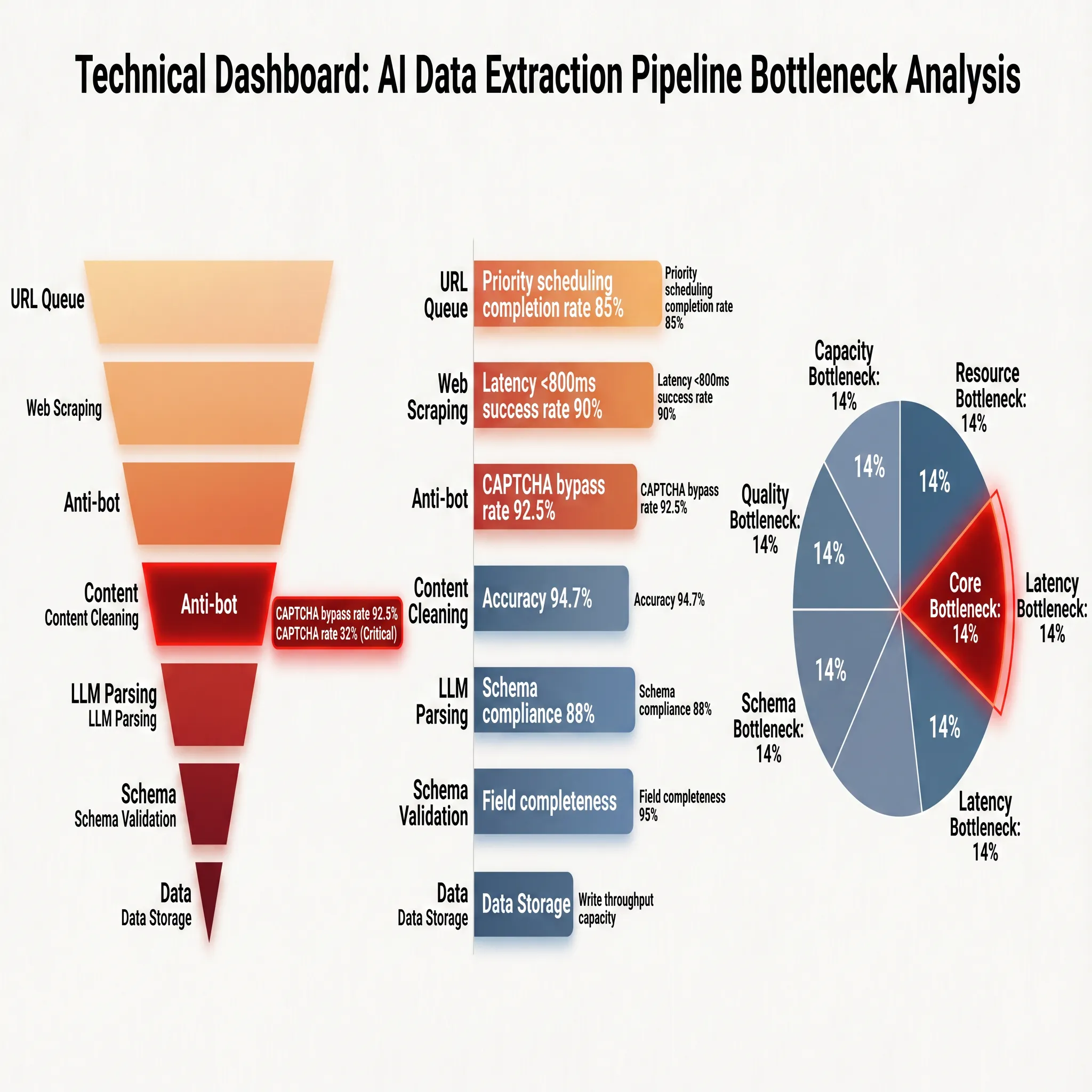
The performance indicators on the right side of the figure reveal the actual operating baselines of each stage: the priority scheduling achievement rate of the URL queue is 85%, meaning approximately 15% of tasks are delayed or degraded due to scheduling contention; web scraping achieves a success rate of 90% under a latency constraint of less than 800ms, clearly showing the boundaries of network and rendering resources; the anti-scraping mechanism has an accuracy rate of 94.7%, meaning approximately 5 out of every 100 requests are intercepted or trigger verification; after content cleaning, the Schema compliance rate is 88% and field completeness is 95%. These two indicators together define the starting point of data quality, with approximately 12% of pages having deviations in main content identification and 5% of required fields missing.
The bottom of Figure 2-2 directly indicates the bottleneck distribution: the core bottleneck points to the anti-scraping mechanism (14%), the accuracy bottleneck points to content cleaning (18%), the capacity bottlenecks point to URL scheduling and web scraping stages respectively, and the cost bottleneck falls on the quality inspection overhead of Schema validation. These data highly align with the analysis above. Anti-scraping detection is the “throat” of the entire chain; once an anti-scraping strategy is triggered and cannot be effectively bypassed, no matter how high the accuracy of subsequent stages, they will all fail due to the lack of input data. This is consistent with the core problem of traditional rule-based crawlers: in the era of AI semantic extraction, the ceiling of accuracy has been significantly raised, but the “entry qualification” for acquiring data remains the first hurdle for engineering implementation. For this reason, Chapter 3 will specifically discuss the evolution of anti-scraping confrontation technology and countermeasures.
2.2 Content Cleaning: From Noisy HTML to LLM-Readable Text
Directly feeding raw HTML to LLMs for structured extraction is extremely inefficient in engineering. LLM’s attention mechanism can be distracted by DOM boilerplate code, such as deep nesting of <div> tags, embedded CSS styles, tracking scripts, navigation menus, and footer links. These elements not only provide zero semantic value but also drastically inflate token consumption. In large-scale scenarios processing thousands of pages per day, this waste quickly becomes financially unsustainable. The composition of a typical news page’s HTML intuitively illustrates the severity of the problem. Figure 2-3 presents the proportion of effective information to various noises in raw HTML in a circular chart:
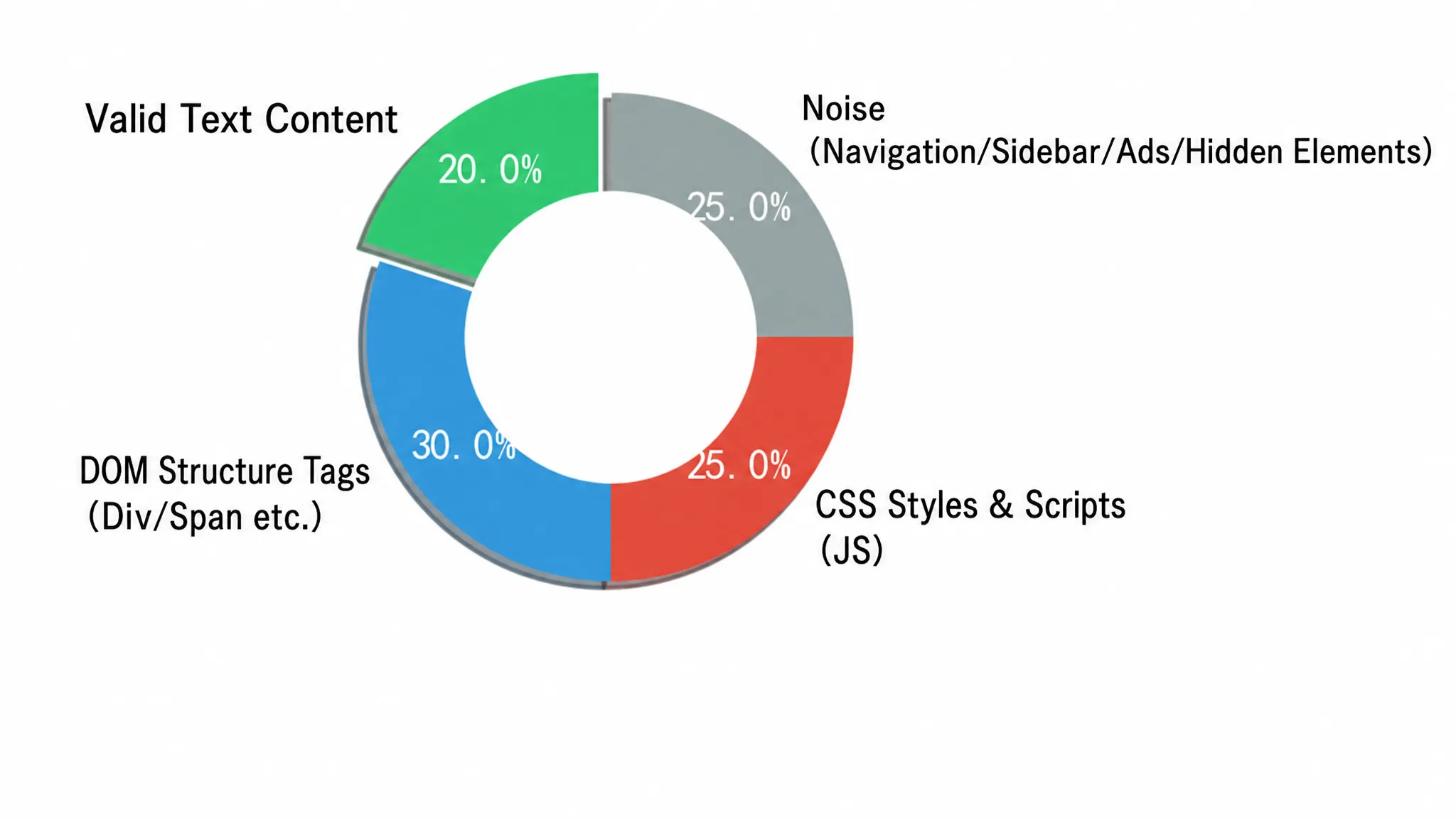
The circular chart divides the raw HTML into four areas. The green part (45%) is effective body content, including text and images—this is the signal that LLM truly needs. The yellow part (20%) is structural and style noise, i.e., <script>, <style>, <svg> tags; the blue part (20%) is navigation and sidebars; the red part (15%) is advertisements and trackers. The three parts of noise combined exceed 55%, meaning that more than half of the tokens sent to LLM are billed without contributing any semantic value.
This reality of “signal drowned in noise” has given rise to a three-layered progressive cleaning strategy. Figure 2-4 shows the complete processing chain from raw HTML to LLM-readable text:
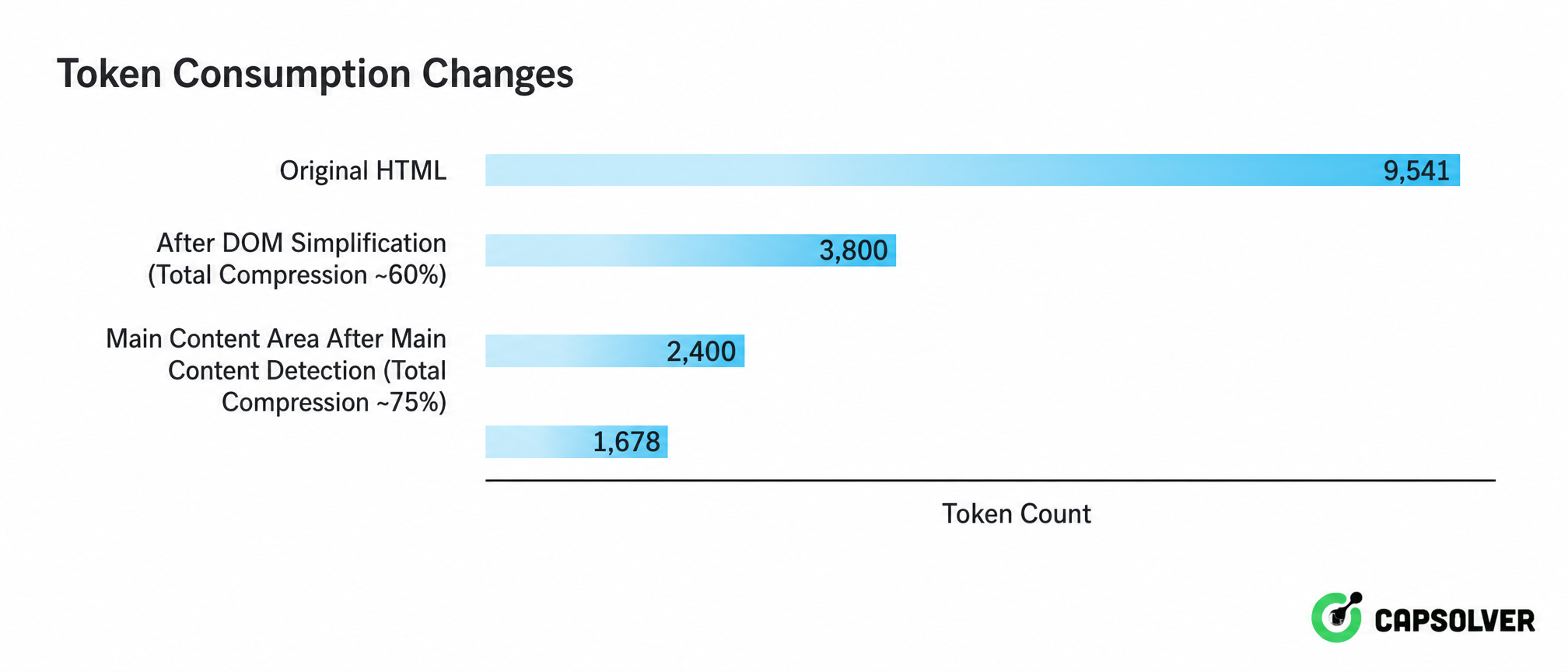
From the perspective view, it is clear at a glance that the three layers of cleaning compress tokens from 9,541 to 1,678, only 18% of the original HTML. This compression ratio means that in large-scale processing, API call costs can be reduced to less than one-fifth of the original, and the 10–100 times context reduction achieved by semantic context filtering ensures that LLM’s attention is focused on signals rather than noise. This is an indispensable part of the engineering implementation of AI data extraction.
2.3 LLM Parsing and Schema Validation: From Text to Structured Data
The Markdown text, cleaned through content cleaning, enters the LLM parsing stage, aiming to generate structured JSON that strictly adheres to a predefined Schema. Depending on the scenario, there are currently three mainstream technical paths available. Path one uses general large models like GPT-4o, which, with a 128K context window, offers the fastest inference speed and highest quality score, but at a moderate cost, suitable for rapid prototype verification with few fields and simple formats. Path two employs Schema-first specialized models like Schematron-3B, running in a compact server-side deployment, with medium-high speed and a quality score only slightly behind general large models by 0.12 points, while reducing costs to the lowest tier, making it the optimal choice for large-scale production scenarios. Path three leverages multimodal language models to build hybrid architectures, simultaneously parsing screenshots and HTML, capable of handling highly dynamic interactive pages such as infinite scrolling and modal pop-ups, but with medium speed, highest cost, and relatively lowest quality score, making it almost the only viable route for complex interactive scenarios. Regardless of the chosen path, the initially generated structured JSON must pass three layers of Schema validation—field completeness, type compliance, and format consistency—before being output as final data. Figure 2-5 illustrates the complete relationship between these three paths and Schema validation from both the process chain and core metrics perspectives.

The matrix clearly shows a counter-intuitive but crucial engineering fact: the largest model is not always the optimal solution. Schematron-3B, with only 3B parameters, approaches the quality score of large models like GPT-4o while significantly reducing costs. When processing reaches a scale of one million pages per day, its inference cost is only about 1/80 of that of large general models, which constitutes a critical turning point from “technically feasible” to “commercially profitable.” Although Webscraper+MLLM has the highest cost and relatively lowest quality score, it is almost the only feasible route for highly dynamic interactive scenarios, which precisely confirms a principle: the correctness of technology selection depends on scenario constraints, not absolute metric values.
Schema validation is the last checkpoint to ensure data usability. Among them, format consistency checks are particularly crucial for fields such as dates, currencies, and phone numbers. Traditional regular expression solutions require manually writing rules for each input variant, while LLM’s internalized format conversion capabilities can achieve standardization with zero rules. In terms of accuracy, the AXE framework has achieved an F1 score of 88.1% on the SWDE dataset. Experience in actual production environments shows that pursuing 90% automated extraction accuracy combined with a rapid manual review path is a more pragmatic engineering strategy than stubbornly pursuing 100% theoretical accuracy at dozens of times the cost. The position of this trade-off line depends on each team’s specific calculation of “data continuity” and “budget ceiling,” but it is clear that moderate accuracy is more commercially viable.
III. The Triple Gates of AI Data Extraction: Anti-Scraping, CAPTCHA Breakthrough, and Cost Control
In Chapter 2, we thoroughly explored the technical chain of the content processing layer—from HTML cleaning to Schema validation—demonstrating how AI semantic extraction significantly raises the accuracy ceiling. However, as revealed in Figure 2-2 of Section 2.1, the core bottleneck (14%) of the entire Pipeline is not in the processing layer, but in the preceding data acquisition layer. If the HTML cannot be obtained, all subsequent intelligent parsing is built on thin air. This chapter will directly tackle this critical stage that determines “entry qualification.”
3.1 Data Acquisition Layer: The First Fatal Bottleneck of the Pipeline
If content cleaning and LLM parsing solve the problem of “how to process data,” the data acquisition layer addresses a more fundamental and thorny issue: “can the data be obtained?” In the path from the URL queue to normal access, the anti-scraping system is the most uncontrollable variable in the entire Pipeline.
Modern anti-scraping systems have evolved into a four-layered defense-in-depth architecture, simultaneously analyzing each request from network, transport, browser, and behavior layers. Figure 3-1 horizontally expands this layered detection architecture.
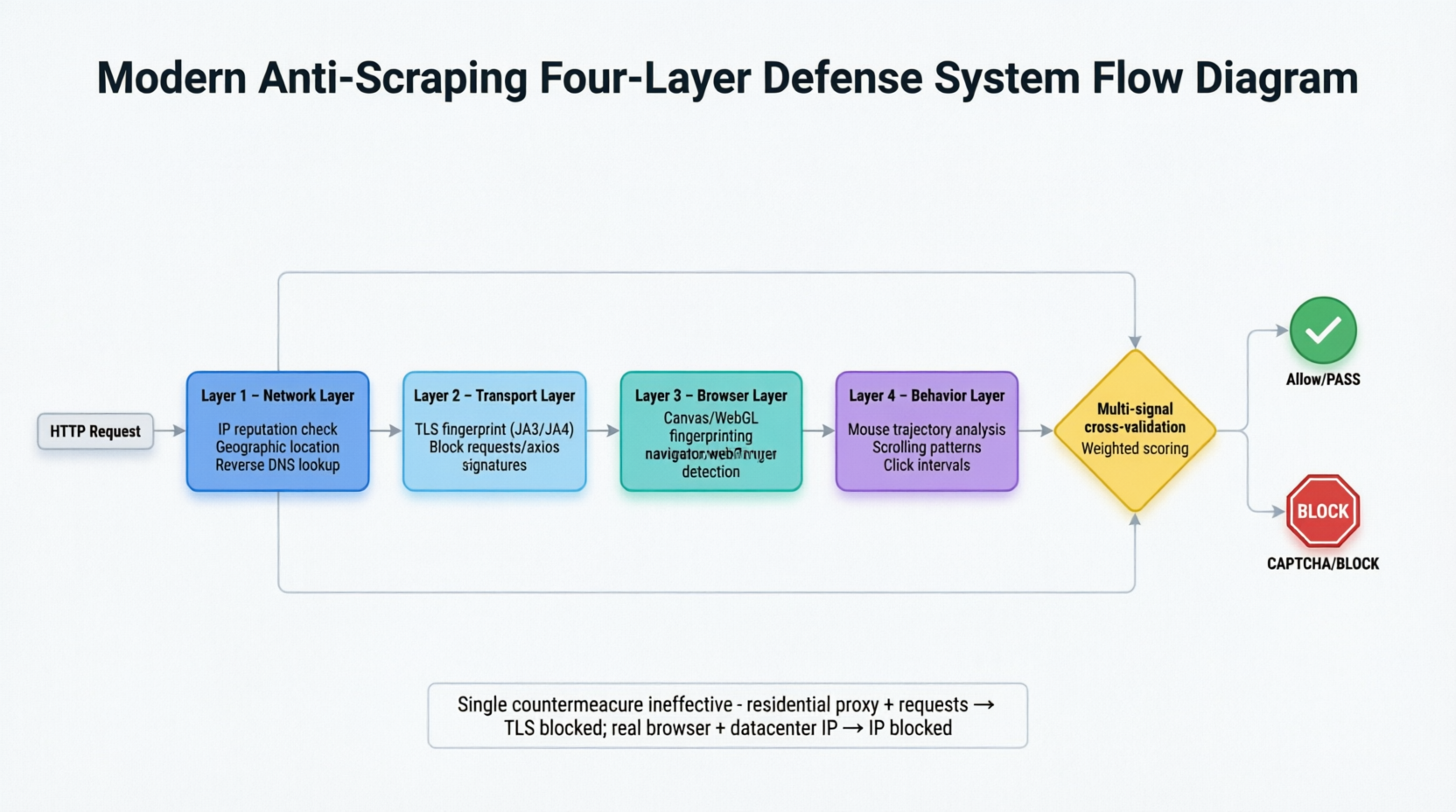
Requests pass through four layers of filtering sequentially. The network layer checks static signals such as IP location, whether it belongs to a data center, and missing reverse DNS; the transport layer compares TLS fingerprints; the browser layer captures automation traces such as navigator.webdriver property in headless mode, Canvas fingerprints, and WebGL renderer information; the behavior layer analyzes human behavior characteristics that are difficult to precisely simulate, such as mouse trajectories, scrolling patterns, and click intervals. The four layers of signals are cross-validated to form a weighted score, making it difficult for any single layer of disguise to pass. When the system cannot make a clear determination, the final line of defense—CAPTCHA—is triggered.
When all passive detection methods cannot clearly determine the nature of the traffic, the system pops up a CAPTCHA, which is the last line of defense for anti-scraping systems. Modern CAPTCHAs are no longer simple distorted character recognition but intelligent challenge systems based on risk scores. Table 3-1 compares the four mainstream CAPTCHA systems currently available.
| CAPTCHA System | Interaction Form | Judgment Mechanism | AI Decoding Capability/Features | Threat to Crawlers |
|---|---|---|---|---|
| reCAPTCHA v2 | Click checkbox / Image recognition | User interaction + AI behavior scoring | Accuracy 85%–100% | High, but breakable |
| reCAPTCHA v3 | Completely invisible, no visible challenge | Background continuous behavior scoring | Cannot be directly “broken,” relies on behavior simulation | Extremely high, invisible scoring |
| Cloudflare Turnstile | Browser environment consistency check | Non-interactive verification | Verifies browser integrity | High, alternative to reCAPTCHA |
| AWS WAF CAPTCHA | Risk-based, configurable challenges | AWS integrated environment judgment | Cloud environment specific | Medium, specific ecosystem |
CAPTCHA is located at the very end of the entire defense chain. Once triggered and not handled, all subsequent content cleaning and LLM parsing stages become completely ineffective. This is the fundamental reason why the data acquisition layer is called the “first fatal bottleneck of the Pipeline”: the anti-scraping mechanism determines whether data can flow into the system, and it itself is a variable deeply controlled by the target website. In an era where AI semantic extraction has significantly improved the efficiency of data processing, the offense and defense on the acquisition side remain the critical point for engineering success.
3.2 Completing the Puzzle: Technical Paths for Modern CAPTCHA Breakthrough
In the four-layered anti-scraping defense-in-depth system, CAPTCHA is the last and most difficult hurdle to automatically solve. CAPTCHA recognition solutions represented by CapSolver play a “fuse-like” role in the entire Pipeline—it is embedded between “anti-scraping detection” and “normal access.” When a crawler encounters challenges like reCAPTCHA v2/v3, Cloudflare Turnstile, or AWS WAF CAPTCHA, it completes recognition in seconds and returns a valid Token, resuming the data flow. Figure 3-2 uses CapSolver as an example to illustrate the intervention position and processing logic of this type of solution:
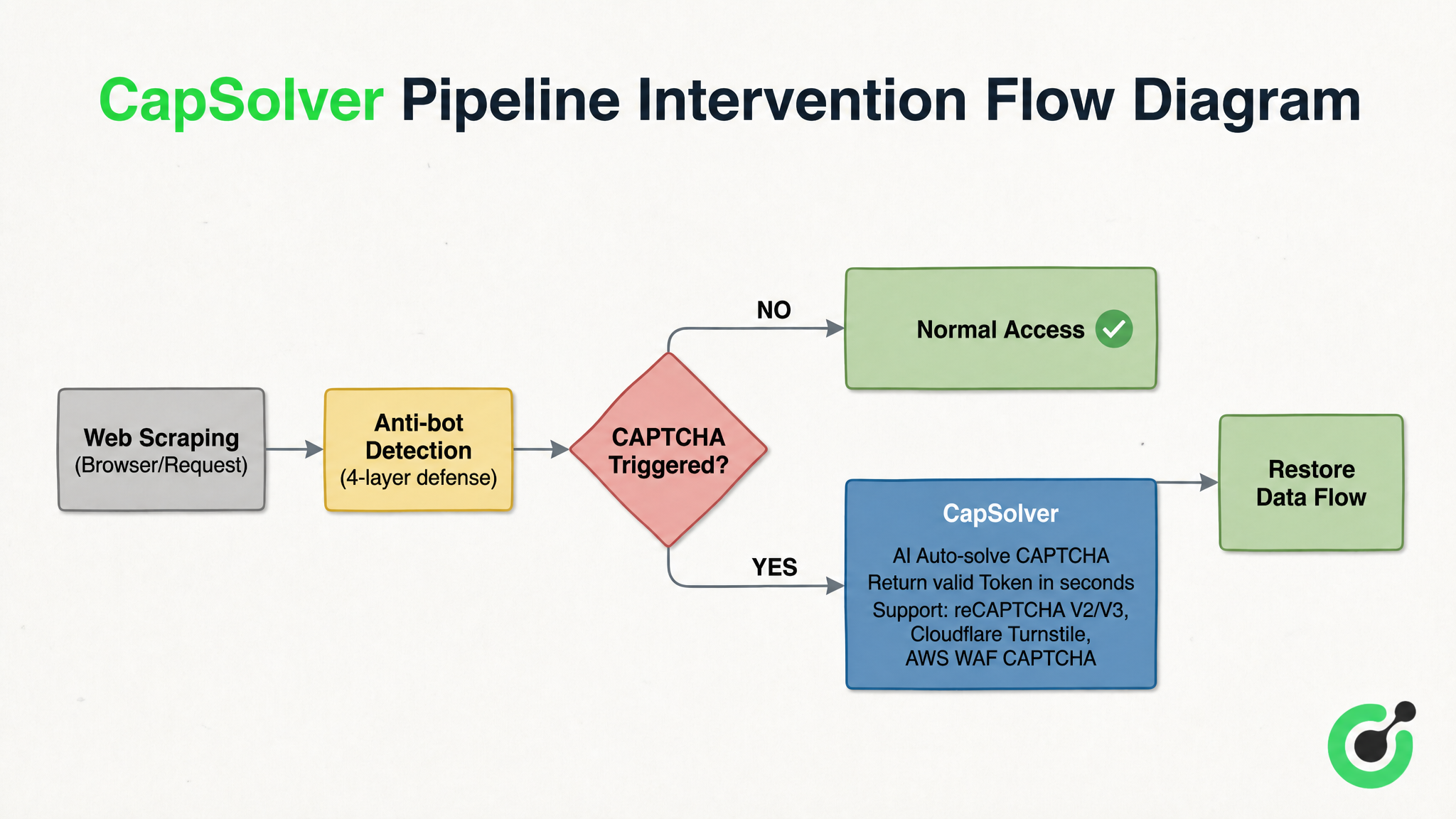
From Figure 3-2, the working mechanism of this type of solution is clear: after the scraping request is detected by the four-layered defense system, if CAPTCHA is not triggered, it is directly released for normal access; once a CAPTCHA challenge is triggered, the recognition service immediately intervenes and submits the CAPTCHA type and parameters. The AI completes recognition in seconds and returns a valid Token, and the data flow is reconnected at the breakpoint. It does not replace any existing components but acts like a fuse in an electrical system, preventing the entire system from crashing at the moment an anomaly occurs.
CapSolver is one of the representative solutions in this field. Similar services such as 2Captcha and Anti-Captcha also provide similar capabilities, and developers can choose the most suitable vendor based on latency requirements, supported types, and pricing models. This embedding directly changes the reliability model of the data acquisition layer. Figure 3-3 uses CapSolver as a case study to quantify the changes in key indicators before and after introducing CAPTCHA recognition:
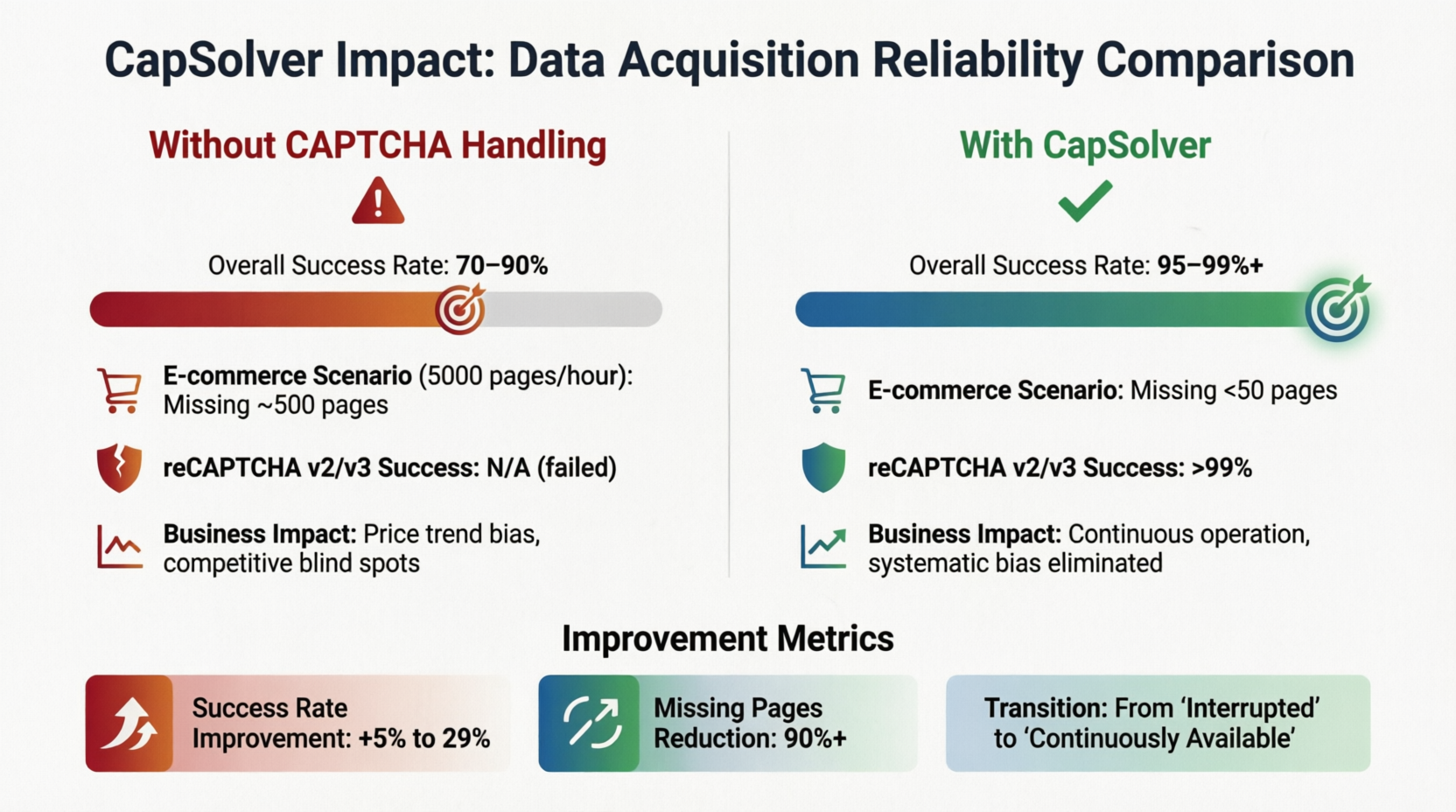
Without a CAPTCHA handling mechanism, the overall success rate fluctuates between 70%–90%. As long as the target site deploys CAPTCHA, there is a 10%–30% probability that the data flow will be blocked. In an e-commerce price monitoring system that scrapes 5,000 product pages per hour, even with a basic success rate of 90%, approximately 500 pages of data will be lost per hour, which is enough to cause directional deviations in price trend analysis and systemic blind spots in competitor strategies. However, after introducing a CAPTCHA recognition solution, the success rate jumps to over 95%–99%, and missing pages decrease to within 50. The recognition success rate for reCAPTCHA v2/v3 exceeds 99% when parameters are correctly configured. The bottom of the card summarizes the improvements: success rate increased by 5%–29%, and missing pages reduced by over 90%. “Continuity is business value” is not just a slogan in large-scale scenarios but an engineering practice confirmed by these numbers.
AI benchmark testing platforms and LLM training data collection scenarios also face this challenge: researchers need to continuously acquire diverse data, and websites hosting this data often use reCAPTCHA to prevent automated access, creating a paradox where “AI research teams are hindered by the very technology they study.” CAPTCHA recognition services provide a programmatic way to handle these challenges, ensuring uninterrupted data collection and complete benchmark testing results.
At the integration level, such solutions can work collaboratively with browser automation frameworks, proxy network services, and low-code automation platforms. Developers only need to submit the CAPTCHA type and parameters to the API, and the system returns a Token in seconds. Platforms like n8n provide dedicated nodes, allowing business personnel to configure CAPTCHA recognition directly in workflows without writing code. Developers can focus on business logic and Schema design, leaving anti-scraping confrontation to professional tools.
From an architectural perspective, CAPTCHA recognition solutions do not replace any existing components but provide a layer of “availability guarantee” for the entry point of the entire Pipeline. When CAPTCHA recognition can be automatically completed in seconds, data acquisition switches from “intermittent blind spots” to “continuous data supply,” which is the prerequisite for the stable operation of the entire AI data structured extraction chain.
3.3 Accuracy and Cost: The Ultimate Trade-off in Engineering Implementation
When pushing AI data structured extraction to a production environment, the ultimate decision variable is often not “is the accuracy good enough?” but “can the cost be afforded?” Token consumption is at the core of this problem: a moderately complex product page, even after cleaning, may consume 8,000 to 15,000 tokens. Based on the current mainstream model API pricing, the cost per extraction ranges from $0.001 to $0.01. This is almost negligible in the prototype stage, but when the extraction scale expands to millions of pages per day, the monthly cost will reach tens of thousands of dollars, at which point cost control is no longer an optimization item but an admission requirement. Currently, there are three parallel paths in the industry to reduce costs. Figure 3-4 shows their positioning and synergistic relationship in the entire parsing chain:
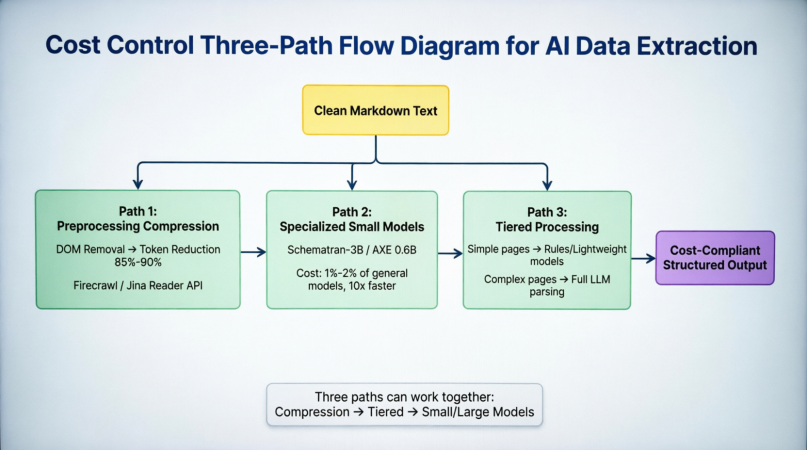
Before the cleaned Markdown enters the parsing stage, path one reduces tokens by 85%–90% through DOM elimination and main content detection at the front end. Firecrawl and Jina Reader have encapsulated this into an API, eliminating the need for developers to build their own cleaning pipelines. Path two replaces general large models with task-specific models like Schematron-3B and AXE 0.6B at the model layer, maintaining accuracy while compressing inference costs to 1%–2% and speeding up by more than 10 times. Path three uses rules or lightweight models for structurally simple pages at the scheduling layer, only handing complex pages to the full large model for parsing. This is particularly effective in scenarios like e-commerce category monitoring, where most pages within the same site have highly consistent structures, and only a few abnormal pages require full pages require full model intervention. The three paths are not mutually exclusive but can be synergistically superimposed: first compress tokens, then classify by complexity, and finally process with a task-matching model. Figure 3-5 further quantifies the three strategies from core principles, token reduction, representative solutions, and cost reduction magnitude, and includes three data quality checks:

Preprocessing compression directly reduces input volume by stripping DOM noise, achieving a token reduction of 85%–90%, corresponding to an 80%–90% cost saving. Specialized small models reduce the cost of single inference by shrinking model size, with parameters decreasing from tens of billions to the 0.6B–3B range, saving approximately 98% in inference costs. Tiered processing optimizes overall efficiency by differentially allocating computing resources, with savings depending on the proportion of simple pages. These three approaches, from “sending less,” “computing less,” and “computing cleverly,” form a complete cost reduction system covering the input layer, model layer, and scheduling layer.
The latter half shifts to quality assurance. Data quality inspection is an often-overlooked but equally crucial aspect of cost control. The cost of correcting low-quality data flowing into downstream businesses often far exceeds the investment in performing checks at the extraction stage. In a production environment, at least three automated checks should be deployed: field fill rate checks ensure that required fields in the Schema are not empty, marking abnormal records for manual review rather than direct discarding; numerical range checks validate business rules such as prices not being negative and inventory being within a reasonable range, rejecting entries that exceed thresholds; format consistency checks standardize fields like dates, currencies, and phone numbers, with regular expressions and LLM’s internalized format conversion capabilities complementing each other, automatically processing what can be converted and marking what cannot for manual intervention. The three checks maintain a dynamic balance between cost and quality, diverting abnormal records rather than discarding them, ensuring completeness while avoiding data blind spots.
This balanced strategy is also applicable on a larger scale. In actual engineering practice, pursuing 90% automated extraction accuracy combined with a formalized manual review process is often more commercially viable than attempting to achieve 100% theoretical accuracy but with implementation costs dozens of times higher. The selection of target data storage also depends on downstream usage: if used for real-time API queries and front-end display, PostgreSQL or MongoDB are suitable choices; if used for full-text search and log analysis, Elasticsearch is a better match; if used as LLM training corpus, structured JSON usually needs to be re-serialized into the format required by the training framework and stored in object storage. The goal is not to pursue a “one-size-fits-all” storage solution, but to match the most suitable engine based on data consumption methods and query patterns. This principle runs through all engineering decisions from token cost to storage selection.
Redeem Your CapSolver Bonus Code
Boost your automation budget instantly!
Use bonus code CAP26 when topping up your CapSolver account to get an extra 5% bonus on every recharge — with no limits.
Redeem it now in your CapSolver Dashboard
Conclusion
From raw HTML to structured JSON, the complete chain of AI data extraction can be summarized into five sequential stages: acquisition, cleaning, parsing, validation, and storage. Each stage solves a specific problem, and the effectiveness of each stage depends on the successful completion of the previous stage.
In this chain, the data acquisition layer plays the role of the “entry point,” determining whether the entire Pipeline operates normally or is completely idle. The four-layered defense-in-depth of modern anti-scraping systems and continuously upgraded CAPTCHA mechanisms make data acquisition the most uncontrollable and highest-risk stage in the entire chain. When content cleaning can compress HTML by more than 80%, specialized small models can perform accurate structured extraction in seconds, and Schema validation can ensure the compliance of output formats, “whether data can be stably obtained” becomes the primary problem determining project success.
This is precisely where CapSolver’s infrastructure-level value lies in the AI data extraction technology stack. It does not replace any stage in cleaning, parsing, or validation but provides a layer of continuous availability guarantee at the entry point of the entire Pipeline. When CAPTCHA recognition can be automatically completed in seconds, with a success rate consistently above 99%, data acquisition switches from intermittent interruptions to continuous output, and the computing resources and engineering investment of all subsequent stages yield meaningful returns. For businesses that rely on stable data supply, the continuity of the Pipeline itself is business value, and ensuring this continuity is the last hurdle that AI data extraction must overcome in its journey from experimentation to large-scale deployment.
More
AIJun 25, 2026
Enterprise CAPTCHA Solving for AI Agent Teams
Learn how enterprise AI agent teams can implement scalable, reliable CAPTCHA solving infrastructure to keep automation workflows running without interruption.

AIJun 25, 2026
The Headless Browser CAPTCHA Layer for Agents
Explore how headless browsers and CAPTCHA-solving layers enable reliable automation for AI agents, overcoming bot detection and ensuring efficient web interaction.


