什么是AI抓取?定义、优势、应用场景。

Ethan Collins
Pattern Recognition Specialist

TL;DR:
- AI爬虫 使用机器学习和自然语言处理来自动化数据提取,克服了传统基于规则方法的脆弱性。
- 它在处理非结构化数据、绕过复杂的反机器人措施以及适应网站布局变化方面表现出色,而无需手动更新。
- 主要优势包括99.5%的提取准确率、降低维护成本以及将原始网络内容转化为可操作知识的能力。
- 集成专门工具如CapSolver 对于在现代AI爬虫工作流中解决高级CAPTCHAs(reCAPTCHA、Cloudflare)至关重要。
引言
数字环境正以前所未有的速度发展,我们获取信息的方法必须跟上步伐。AI爬虫代表了数据收集的下一代技术,它超越了简单的脚本,转向了能够像人类一样理解网络的智能系统。对于2026年的企业来说,大规模提取高质量数据已不再是奢侈品,而是核心的竞争力。本文探讨了AI驱动的提取如何取代传统方法,其成功背后的技术机制,以及如何创建AI代理网络爬虫以保持领先。无论您是数据科学家还是企业领导者,了解这一转变对于驾驭数据经济的未来至关重要。
什么是AI爬虫?
AI爬虫是使用人工智能(特别是机器学习(ML)和自然语言处理(NLP))从数字来源自动提取数据的过程。与依赖固定CSS选择器或XPath表达式的传统网络爬虫不同,AI爬虫可以解释页面的视觉和文本上下文。这使其能够识别“价格”或“作者”,而不管底层HTML的结构如何。
根据最近的 市场增长报告,全球网络爬虫市场预计到2025年将达到123.4亿美元。这一增长主要由对大型语言模型(LLMs)高质量训练数据的需求推动。AI爬虫不仅收集数据,还通过理解实体之间的关系、执行情感分析和实时清理数据来收集知识。
AI爬虫如何工作?
AI驱动的提取机制涉及一种复杂的多层方法,它模仿人类浏览行为,同时利用巨大的计算能力。
| 层 | 功能 | 关键技术 |
|---|---|---|
| 数据获取 | 导航网站,处理JavaScript并管理代理。 | Playwright、Puppeteer、无头Chrome |
| 解析 | 使用上下文识别相关字段(标题、价格、评论)。 | LLMs(GPT-4、Claude)、计算机视觉 |
| 适应性 | 在布局更改时通过重新映射数据点实现自我修复。 | 强化学习、模式识别 |
| 安全导航层 | 解决CAPTCHAs和速率限制等安全挑战。 | CapSolver、AI驱动的浏览器指纹 |
在典型的流程中,AI代理会接收自然语言提示。然后导航到目标URL,使用计算机视觉“看到”页面布局,并利用NLP提取特定信息。如果遇到障碍,它可以将AI浏览器与验证码求解器结合以保持数据流的无缝性。
AI爬虫与传统网络爬虫
从传统方法向AI驱动方法的转变通常被比作从刚性的装配线转向灵活的机器人系统。
传统爬虫基于“如果-那么”逻辑。如果开发人员告诉脚本在特定的<div>标签中查找价格,而网站所有者将其更改为<span>,爬虫就会崩溃。这会导致高维护成本和频繁的停机。
然而,AI爬虫使用语义理解。它知道美元符号后跟数字很可能是价格,而不管使用的HTML标签是什么。这就是为什么AI驱动的工具在提取速度上比手动规则设置提高了30-40%,如 Scrapingdog的2025年趋势报告 所述。
对比总结
| 特征 | 传统网络爬虫 | AI爬虫 |
|---|---|---|
| 逻辑基础 | 硬编码规则(CSS/XPath) | 语义与视觉理解 |
| 维护 | 高(布局更改时会崩溃) | 低(具备自我修复能力) |
| 数据质量 | 需要手动清理 | 自动化标准化与清理 |
| 复杂性 | 难以处理动态/非结构化数据 | 擅长处理图像、PDF和JS密集型网站 |
| 成功率 | 一般(容易被阻止) | 高(模仿人类行为) |
AI爬虫的优势
将AI引入您的数据管道可以带来超越简单自动化的变革性优势。
- 无与伦比的韧性:AI爬虫可以在无需人工干预的情况下适应小的网站更新。这种“自我修复”特性确保即使目标网站频繁重新设计,您的数据流也能保持稳定。
- 处理非结构化数据:网络上大部分有价值的信息都是非结构化的——比如社交媒体评论、论坛帖子或视频字幕。AI可以掌握MCP(模型上下文协议),将这些原始信息直接输入分析工具。
- 超越反机器人机制:现代网站使用高级行为分析来阻止机器人。AI爬虫可以模仿人类的鼠标移动、打字速度和浏览模式。面对挑战时,它们可以在AI爬虫工作流中集成验证码求解使用CapSolver等服务,以确保全天候可用性。
- 规模化成本效益:虽然AI系统的初始设置可能更高,但长期来看,节省的开发人员修复损坏爬虫的时间成本是巨大的。
AI爬虫的常见用例
AI爬虫正在各个行业中被用于推动创新和效率。智能提取的多功能性使组织能够解决以前难以克服的数据挑战。
电子商务情报与动态定价
在在线零售的激烈竞争中,价格每分钟都在变化。AI爬虫使零售商能够实时监控数千家全球门店的竞争对手价格、库存水平和客户情绪。除了简单的价格跟踪,AI可以分析产品描述和图像,确保即使竞争对手使用不同的命名惯例,比较也是准确的。这种精度水平允许动态定价策略,可以显著提高利润率。
高保真AI训练数据
当前的AI革命由数据推动。收集大量数据集来训练下一代LLMs需要只有AI驱动提取才能提供的高保真数据。传统爬虫往往因无法过滤掉不相关的内容而向数据集中引入“噪声”。然而,AI爬虫可以区分文章的核心内容和周围的广告或导航链接,确保训练数据干净且上下文相关。
金融市场监管分析与替代数据
对冲基金和金融机构越来越多地转向替代数据以获得优势。这包括从新闻网站、监管文件、社交媒体趋势甚至以表格形式表示的卫星图像数据中爬取信息。AI爬虫可以同时处理这些多样化来源,识别主流市场趋势之前出现的新兴趋势。通过实时分析金融新闻的情感,AI代理可以为交易员提供几秒钟内的可操作见解。
房地产与潜在客户生成
房地产行业严重依赖来自多个平台的最新列表。AI爬虫可以聚合这些列表,对数据进行标准化(例如,转换面积或货币),并自动识别被低估的房产。同样,对于B2B销售,AI可以从专业网络和公司目录中分析职位名称、公司增长模式和最近的新闻提及,以识别和筛选潜在客户,创建高度针对性的销售管道。
技术实现:构建稳健的管道
要真正利用AI爬虫,必须了解稳健数据管道的架构。它从选择合适的环境开始。现代开发人员通常更喜欢容器化解决方案,这些解决方案可以随着目标URL数量的增加而水平扩展。
无头浏览器的作用
Playwright和Puppeteer等工具是获取层的主力军。它们允许AI代理像人类一样与网站互动——点击按钮、滚动无限流,并等待异步JavaScript加载。然而,大规模运行这些浏览器是资源密集型的。AI优化可以通过确定哪些页面需要完整的浏览器渲染,哪些可以通过更快、更轻的HTTP请求获取来帮助。
在边缘集成智能
最先进的AI爬虫设置在“边缘”执行数据提取和清理。这意味着而不是将原始HTML发送回中央服务器进行处理,AI代理在本地执行提取。这减少了延迟和带宽成本。通过使用轻量级LLM或专用NLP模型,这些代理可以直接从浏览器环境中交付结构化JSON数据。
管理安全挑战
如前所述,“安全导航层”至关重要。管道的强度取决于其最薄弱的环节。如果您的AI代理被Cloudflare挑战阻止,整个工作流就会停止。这就是为什么与CapSolver等服务进行稳健集成是不可或缺的。它为您的AI代理提供了通过安全检查点所需的“凭证”,而不会触发警报。最佳实践包括轮换用户代理、智能管理会话Cookie,并使用高质量的住宅代理来隐藏爬虫的足迹。
通过CapSolver克服安全障碍
AI爬虫最大的障碍之一是反机器人防御的日益复杂化。网站现在使用reCAPTCHA v3、Cloudflare Turnstile和AWS WAF来保护其数据。这就是像CapSolver这样的专业解决方案变得不可或缺的原因。通过提供在毫秒内解决这些挑战的AI驱动API,CapSolver让您的AI爬虫专注于它们最擅长的事情:提取价值。集成用于验证码求解的AI-LLM确保您的自动化代理永远不会被“验证你是人类”的墙阻挡。
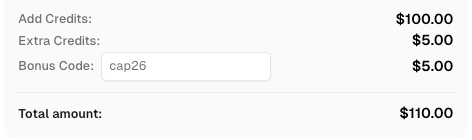
在CapSolver注册时使用代码
CAP26以获得额外积分!
结论
AI爬虫不仅仅是一种趋势;它是与网络数据互动的必然进化。通过结合LLM的语义力量和CapSolver等工具的可靠性,组织可以构建比以往更快、更智能、更具弹性的数据管道。随着我们进入2026年,使用传统脚本和利用AI的人之间的差距只会扩大。现在是升级基础设施并拥抱智能数据提取未来的时候了。
常见问题
1. AI爬虫合法吗?
对于公开可用的数据,网络爬虫通常是合法的,但必须遵守网站的使用条款和数据隐私法,如GDPR。最近的裁决,如Meta vs. Bright Data 2024案,强调了遵守合同限制的重要性。
2. AI爬虫如何处理验证码?
AI爬虫通常与第三方API如CapSolver集成,这些API使用机器学习模型自动解决复杂的挑战,如reCAPTCHA和Cloudflare Turnstile。
3. 我需要编程知识才能使用AI爬虫吗?
虽然一些技术知识有帮助,但许多现代AI爬虫工具提供无代码或低代码界面,您可以用普通英语描述您的需求。
4. 爬虫和爬虫的主要区别是什么?
爬虫(如Googlebot)在互联网上导航以索引页面,而爬虫从这些页面中提取特定数据点。AI通过使导航和提取更“人性化”来增强两者。
5. AI爬虫能处理图像和PDF吗?
是的,AI爬虫使用计算机视觉和OCR(光学字符识别)从非文本格式中提取文本和数据,而传统爬虫无法做到这一点。


