Scrapy 与 Selenium:哪个更适合您的网络爬虫项目?

Sora Fujimoto
AI Solutions Architect

简要总结
Scrapy和Selenium是两种流行的网络爬虫工具,适用于不同的使用场景。Scrapy是一个快速、轻量且可扩展的Python框架,非常适合大规模静态网站的爬取。另一方面,Selenium通过自动化真实浏览器来爬取需要用户交互的动态JavaScript密集型页面。正确的选择取决于项目的复杂性、性能要求和交互需求,这两种工具都可能遇到CAPTCHA挑战,这些挑战可以通过CapSolver等服务解决。
引言
网络爬虫是一种从互联网上收集数据的重要技术,近年来在开发者、研究人员和企业中越来越受欢迎。用于网络爬虫的最常用工具之一是Scrapy和Selenium。每种工具都有其优缺点,适合不同类型项目。在本文中,我们将比较Scrapy和Selenium,以帮助您确定哪种工具最适合您的网络爬虫需求。
什么是Scrapy
Scrapy是一个强大且快速的开源网络爬虫框架,用Python编写。它旨在爬取网页并从中提取结构化数据。Scrapy高效、可扩展且可定制,是大规模网络爬虫项目的绝佳选择。
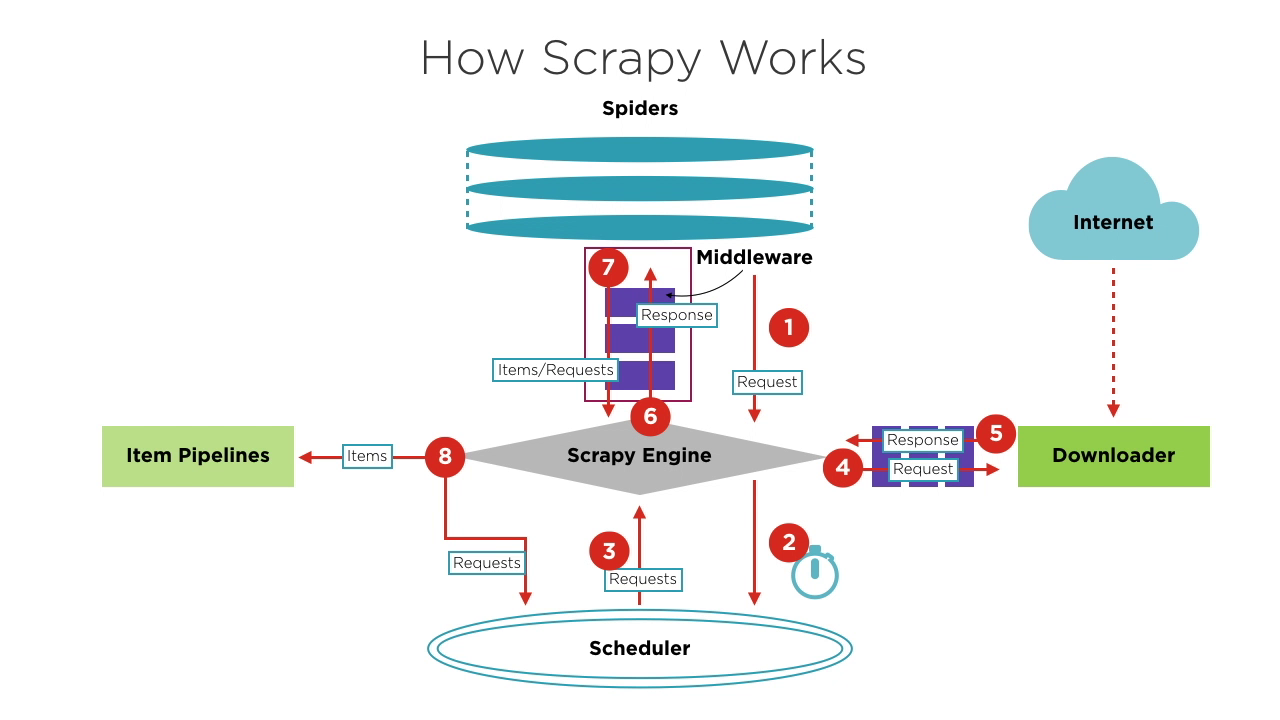
Scrapy的组件
- Scrapy引擎:框架的核心,管理系统内的数据流和事件。它就像大脑,处理数据传输和逻辑处理。
- 调度器:接收来自引擎的请求,将它们排队,并将它们送回引擎供下载器执行。它维护调度逻辑,如FIFO(先进先出)、LIFO(后进先出)和优先级队列。
- 爬虫:定义了爬取和解析页面的逻辑。每个爬虫负责处理响应,生成项目,并将新的请求发送到引擎。
- 下载器:处理向服务器发送请求和接收响应,然后将响应返回到引擎。
- 项目管道:处理爬虫提取的项目,执行诸如数据清理、验证和存储等任务。
- 中间件:
- 下载器中间件:位于引擎和下载器之间,处理请求和响应。
- 爬虫中间件:位于引擎和爬虫之间,处理项目、请求和响应。
反复失败解决烦人的验证码?发现CapSolver人工智能自动网页解锁技术,轻松解决验证码!
立即提升您的自动化预算!
在充值CapSolver账户时使用优惠码CAPN,每次充值可额外获得5%的奖励——无限制。
现在在您的CapSolver仪表板中兑换
.
Scrapy项目的基本工作流程
-
在启动爬取项目时,引擎根据要爬取的网站找到处理该网站的爬虫。爬虫生成一个或多个初始请求,对应需要爬取的页面,并将它们发送到引擎。
-
引擎从爬虫获取这些请求,然后将它们传递给调度器以等待调度。
-
引擎向调度器请求下一个要处理的请求。此时,调度器根据其调度逻辑选择一个合适的请求并将其发送到引擎。
-
引擎将调度器的请求转发给下载器进行下载执行。发送请求到下载器的过程会经过许多预定义的下载器中间件的处理。
-
下载器将请求发送到目标服务器,接收相应的响应,然后将其返回到引擎。将响应返回到引擎的过程也会经过许多预定义的下载器中间件的处理。
-
引擎从下载器接收到的响应包含目标网站的内容。引擎会将此响应发送到相应的爬虫进行处理。将响应发送到爬虫的过程会经过预定义的爬虫中间件的处理。
-
爬虫处理响应,解析其内容。此时,爬虫将生成一个或多个爬取结果项目或一个或多个对应后续目标页面的请求,然后将这些项目或请求发送回引擎进行处理。发送项目或请求到引擎的过程会经过预定义的爬虫中间件的处理。
-
引擎将爬虫发送的一个或多个项目转发到预定义的项目管道,进行一系列数据处理或存储操作。它将爬虫发送的一个或多个请求转发到调度器,等待下一次调度。
步骤2到8会重复进行,直到调度器中没有更多的请求。此时,引擎将关闭爬虫,整个爬取过程结束。
从整体上看,每个组件只专注于一个功能,组件之间的耦合度非常低,非常容易扩展。引擎将各个组件结合起来,使每个组件能够各司其职,相互协作,共同完成爬取工作。此外,通过Scrapy对异步处理的支持,可以最大限度地利用网络带宽,提高数据爬取和处理的效率。
什么是Selenium?
Selenium是一个开源的网页自动化工具,允许您以编程方式控制网页浏览器。虽然它主要用于测试网页应用程序,但Selenium也因其能够与传统方法难以爬取的JavaScript密集型网站进行交互而受到欢迎。需要注意的是,Selenium只能测试网页应用程序。我们不能使用Selenium测试任何桌面(软件)应用程序或移动应用程序。
Selenium的核心是Selenium WebDriver,它提供了一个编程接口,允许开发人员编写代码来控制浏览器行为和交互。该工具在网页开发和测试中非常受欢迎,因为它支持多种浏览器,并且可以在不同的操作系统上运行。Selenium WebDriver允许开发人员在浏览器中模拟用户操作,例如点击按钮、填写表单和导航页面。
Selenium WebDriver功能丰富,是网页自动化测试的理想选择。
Selenium WebDriver的关键功能
-
浏览器控制:Selenium WebDriver支持多种主流浏览器,包括Chrome、Firefox、Safari、Edge和Internet Explorer。它可以启动和控制这些浏览器,执行打开网页、点击元素、输入文本和截屏等操作。
-
跨平台兼容性:Selenium WebDriver可以在不同的操作系统上运行,包括Windows、macOS和Linux。这使其在多平台测试中非常有用,使开发人员能够确保他们的应用程序在各种环境中表现一致。
-
编程语言支持:Selenium WebDriver支持多种编程语言,包括Java、Python、C#、Ruby和JavaScript。开发人员可以选择他们熟悉的语言编写自动化测试脚本,从而提高开发和测试效率。
-
网页元素交互:Selenium WebDriver提供了一个丰富的API来定位和操作网页元素。它支持通过ID、类名、标签名、CSS选择器、XPath等多种方法定位元素。开发人员可以使用这些API实现点击、输入、选择和拖放等操作。
Scrapy和Selenium的比较
| 特性 | Scrapy | Selenium |
|---|---|---|
| 目的 | 仅用于网页爬取 | 网页爬取和网页测试 |
| 语言支持 | 仅支持Python | Java、Python、C#、Ruby、JavaScript等 |
| 执行速度 | 快 | 较慢 |
| 可扩展性 | 高 | 有限 |
| 异步支持 | 是 | 否 |
| 动态渲染 | 否 | 是 |
| 浏览器交互 | 否 | 是 |
| 内存资源消耗 | 低 | 高 |
如何选择Scrapy和Selenium
-
选择Scrapy 如果:
- 您的目标是静态网页,无需动态渲染。
- 您需要优化资源消耗和执行速度。
- 您需要大量的数据处理和自定义中间件。
-
选择Selenium 如果:
- 您的目标网站涉及动态内容并需要交互。
- 执行效率和资源消耗不是主要考虑因素。
无论选择Scrapy还是Selenium,都取决于具体的使用场景,比较各种工具的优缺点,选择最适合您的。当然,如果您编程技能足够强大,甚至可以同时结合Scrapy和Selenium使用。
Scrapy和Selenium的挑战
无论使用Scrapy还是Selenium,您可能会遇到同样的问题:机器人挑战。机器人挑战被广泛用于区分计算机和人类,防止恶意机器人访问网站,保护数据不被爬取。常见的机器人挑战包括captcha、reCaptcha、captcha、captcha、Cloudflare Turnstile、captcha、captcha WAF等。它们使用复杂的图像和难以理解的JavaScript挑战来判断您是否是机器人。有些挑战甚至对人类来说都很难通过。
俗话说,“各有所长”。CapSolver的出现使这个问题变得简单。CapSolver使用基于AI的自动网页解锁技术,可以在几秒钟内帮助您解决各种机器人挑战。无论您遇到什么样的图像或问题挑战,都可以自信地交给CapSolver。如果失败,您不会被收费。
CapSolver提供了一个浏览器扩展,可以在基于Selenium的数据爬取过程中自动解决CAPTCHA挑战。它还提供了一个API方法来解决CAPTCHAs并获取令牌,使您能够轻松处理Scrapy中的各种挑战。所有这些工作只需几秒钟即可完成。有关更多信息,请参阅CapSolver文档。
结论
选择Scrapy还是Selenium取决于您的项目需求。Scrapy非常适合高效地爬取静态网站,而Selenium在处理动态、JavaScript密集型页面方面表现出色。请考虑具体要求,如速度、资源使用和交互水平。对于克服CAPTCHA等挑战,CapSolver等工具提供了高效的解决方案,使爬取过程更加顺畅。最终,正确的选择确保了成功的和高效的爬取项目。
常见问题
1. Scrapy和Selenium可以在一个项目中一起使用吗?
可以。一种常见方法是使用Selenium处理JavaScript渲染或复杂交互(如登录流程),然后将渲染后的HTML或提取的URL传递给Scrapy进行高速、大规模爬取和数据提取。这种混合模型结合了Selenium的灵活性和Scrapy的性能。
2. Scrapy适合现代JavaScript密集型网站吗?
默认情况下,Scrapy不执行JavaScript,这使其不适合依赖客户端渲染的网站。然而,可以使用Playwright、Splash或Selenium等工具扩展Scrapy,以在必要时处理JavaScript内容。
3. 哪种工具在大规模爬取中更节省资源?
Scrapy比Selenium更节省资源。它使用异步网络,不需要启动浏览器,因此更适合高容量、大规模的爬取任务。Selenium消耗更多CPU和内存,因为它控制真实浏览器,这限制了可扩展性。


