如何将 DrissionPage 与 CapSolver 集成以实现无缝验证码解决

Ethan Collins
Pattern Recognition Specialist

1. 介绍
网页自动化已成为数据收集、测试和各种业务操作中不可或缺的一部分。然而,现代网站部署了复杂的反机器人措施和验证码,这可能会阻止即使是最精心设计的自动化脚本。
DrissionPage 和 CapSolver 的结合为这一挑战提供了一个强大的解决方案:
- DrissionPage:一个基于 Python 的网页自动化工具,无需 WebDriver 即可控制 Chromium 浏览器,结合浏览器自动化与 HTTP 请求
- CapSolver:一个基于 AI 的验证码解决服务,可以处理 Cloudflare Turnstile、reCAPTCHA 等
这两个工具一起使网页自动化更加顺畅,能够绕过 WebDriver 检测和验证码挑战。
1.1. 集成目标
本指南将帮助您实现三个核心目标:
- 避免 WebDriver 检测 - 使用 DrissionPage 的原生浏览器控制,无需 Selenium/WebDriver 标志
- 自动解决验证码 - 集成 CapSolver 的 API 以无需人工干预地处理验证码挑战
- 保持类人行为 - 结合操作链与智能验证码解决
2. 什么是 DrissionPage?
DrissionPage 是一个结合浏览器控制和 HTTP 请求功能的基于 Python 的网页自动化工具。与 Selenium 不同,它使用自开发的内核,不依赖 WebDriver,因此更难被检测到。
2.1. 核心功能
- 无需 WebDriver - 原生控制 Chromium 浏览器,无需 chromedriver
- 双模式运行 - 将浏览器自动化(d 模式)与 HTTP 请求(s 模式)结合
- 简化元素定位 - 直观的语法用于查找元素
- 跨 iframe 导航 - 在不切换 iframe 的情况下定位元素
- 多标签支持 - 同时操作多个标签
- 操作链 - 将鼠标和键盘操作串联在一起
- 内置等待机制 - 不稳定网络的自动重试机制
2.2. 安装
bash
# 安装 DrissionPage
pip install DrissionPage
# 安装 requests 库用于 CapSolver API
pip install requests2.3. 基本用法
python
from DrissionPage import ChromiumPage
# 创建浏览器实例
page = ChromiumPage()
# 导航到 URL
page.get('https://wikipedia.org')
# 查找并操作元素
page('#search-input').input('Hello World')
page('#submit-btn').click()3. 什么是 CapSolver?
CapSolver 是一个基于 AI 的自动验证码解决服务,支持多种验证码类型。它提供了一个简单的 API,允许您提交验证码挑战并在几秒钟内收到解决方案。
3.1. 支持的验证码类型
- Cloudflare Turnstile - 最常见的现代反机器人挑战
- Cloudflare 挑战
- reCAPTCHA v2 - 图像版和不可见版
- reCAPTCHA v3 - 基于评分的验证
- AWS WAF - 亚马逊网络服务验证码
- 以及更多...
3.2. 开始使用 CapSolver
- 在 capsolver.com 注册
- 向账户充值
- 从仪表板获取您的 API 密钥
3.3. API 端点
- 服务器 A:
https://api.capsolver.com - 服务器 B:
https://api-stable.capsolver.com
4. 集成前的挑战
在将 DrissionPage 与 CapSolver 结合之前,网页自动化面临几个痛点:
| 挑战 | 影响 |
|---|---|
| WebDriver 检测 | Selenium 脚本立即被阻止 |
| 验证码挑战 | 需要人工解决,破坏自动化 |
| iframe 复杂性 | 难以与嵌套内容交互 |
| 多标签操作 | 需要复杂的标签切换逻辑 |
DrissionPage + CapSolver 集成在一个工作流程中解决了所有这些挑战。
5. 集成方法
5.1. API 集成(推荐)
API 集成方法为您提供对验证码解决过程的完全控制,并适用于任何验证码类型。
5.1.1. 设置要求
bash
pip install DrissionPage requests5.1.2. 核心集成模式
python
import time
import requests
from DrissionPage import ChromiumPage
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def create_task(task_payload: dict) -> str:
"""创建验证码解决任务并返回任务 ID。"""
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": task_payload
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"CapSolver 错误: {result.get('errorDescription')}")
return result["taskId"]
def get_task_result(task_id: str, max_attempts: int = 120) -> dict:
"""轮询任务结果直到解决或超时。"""
for _ in range(max_attempts):
response = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
)
result = response.json()
if result.get("status") == "ready":
return result["solution"]
elif result.get("status") == "failed":
raise Exception(f"任务失败: {result.get('errorDescription')}")
time.sleep(1)
raise TimeoutError("验证码解决超时")
def solve_captcha(task_payload: dict) -> dict:
"""完成验证码解决工作流程。"""
task_id = create_task(task_payload)
return get_task_result(task_id)5.2. 浏览器扩展
您也可以使用 CapSolver 浏览器扩展与 DrissionPage 集成,以实现更少干预的方法。
5.2.1. 安装步骤
- 从 capsolver.com/en/extension 下载 CapSolver 扩展
- 解压扩展文件
- 在扩展的
config.js文件中配置您的 API 密钥:
javascript
// 在扩展文件夹中,编辑: assets/config.js
var defined = {
apiKey: "YOUR_CAPSOLVER_API_KEY", // 替换为您的实际 API 密钥
enabledForBlacklistControl: false,
blackUrlList: [],
enabledForRecaptcha: true,
enabledForRecaptchaV3: true,
enabledForTurnstile: true,
// ...其他设置
}- 加载到 DrissionPage 中:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.add_extension('/path/to/capsolver-extension')
page = ChromiumPage(co)
# 扩展会自动检测并解决验证码注意: 扩展必须在配置了有效的 API 密钥后才能自动解决验证码。
6. 代码示例
6.1. 解决 Cloudflare Turnstile
Cloudflare Turnstile 是最常见的验证码挑战之一。以下是解决方法:
python
import time
import requests
from DrissionPage import ChromiumPage
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_turnstile(site_key: str, page_url: str) -> str:
"""解决 Cloudflare Turnstile 并返回令牌。"""
# 创建任务
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"错误: {result.get('errorDescription')}")
task_id = result["taskId"]
# 轮询结果
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["token"]
elif result.get("status") == "failed":
raise Exception(f"失败: {result.get('errorDescription')}")
time.sleep(1)
def main():
target_url = "https://your-target-site.com"
turnstile_site_key = "0x4XXXXXXXXXXXXXXXXX" # 在页面源代码中找到
# 创建浏览器实例
page = ChromiumPage()
page.get(target_url)
# 等待 Turnstile 加载
page.wait.ele_displayed('input[name="cf-turnstile-response"]', timeout=10)
# 解决验证码
token = solve_turnstile(turnstile_site_key, target_url)
print(f"获取到 Turnstile 令牌: {token[:50]}...")
# 使用 JavaScript 注入令牌
page.run_js(f'''
document.querySelector('input[name="cf-turnstile-response"]').value = "{token}";
// 如果存在回调函数,也触发它
const callback = document.querySelector('[data-callback]');
if (callback) {{
const callbackName = callback.getAttribute('data-callback');
if (window[callbackName]) {{
window[callbackName]('{token}');
}}
}}
''')
# 提交表单
page('button[type="submit"]').click()
page.wait.load_start()
print("成功绕过 Turnstile!")
if __name__ == "__main__":
main()6.2. 解决 reCAPTCHA v2(自动检测站点密钥)
此示例自动从页面中检测站点密钥 - 无需手动配置:
python
import time
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_recaptcha_v2(site_key: str, page_url: str) -> str:
"""解决 reCAPTCHA v2 并返回令牌。"""
# 创建任务
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"错误: {result.get('errorDescription')}")
task_id = result["taskId"]
print(f"任务已创建: {task_id}")
# 轮询结果
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
elif result.get("status") == "failed":
raise Exception(f"失败: {result.get('errorDescription')}")
time.sleep(1)
def main():
# 只需提供 URL - 站点密钥将自动检测
target_url = "https://www.google.com/recaptcha/api2/demo"
# 配置浏览器
co = ChromiumOptions()
co.set_argument('--disable-blink-features=AutomationControlled')
print("启动浏览器...")
page = ChromiumPage(co)
try:
page.get(target_url)
time.sleep(2)
# 自动检测页面中的站点密钥
recaptcha_div = page('.g-recaptcha')
if not recaptcha_div:
print("页面上未找到 reCAPTCHA!")
return
site_key = recaptcha_div.attr('data-sitekey')
print(f"自动检测到站点密钥: {site_key}")
# 解决验证码
print("解决 reCAPTCHA v2...")
token = solve_recaptcha_v2(site_key, target_url)
print(f"获取到令牌: {token[:50]}...")
# 注入令牌
page.run_js(f'''
var responseField = document.getElementById('g-recaptcha-response');
responseField.style.display = 'block';
responseField.value = '{token}';
''')
print("令牌已注入!")
# 提交表单
submit_btn = page('#recaptcha-demo-submit') or page('input[type="submit"]') or page('button[type="submit"]')
if submit_btn:
submit_btn.click()
time.sleep(3)
print("表单已提交!")
print(f"当前 URL: {page.url}")
print("SUCCESS!")
finally:
page.quit()
if __name__ == "__main__":
main()自己测试一下:
bash
python recaptcha_demo.py这将打开 Google 的 reCAPTCHA 演示页面,自动检测站点密钥,解决验证码并提交表单。
6.3. 解决 reCAPTCHA v3
reCAPTCHA v3 是基于评分的,不需要用户交互。您需要指定 action 参数。
python
import time
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_recaptcha_v3(
site_key: str,
page_url: str,
action: str = "verify",
min_score: float = 0.7
) -> str:
"""使用指定的 action 和最小分数解决 reCAPTCHA v3。"""
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
"pageAction": action,
"minScore": min_score
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"错误: {result.get('errorDescription')}")
task_id = result["taskId"]
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
elif result.get("status") == "failed":
raise Exception(f"失败: {result.get('errorDescription')}")
time.sleep(1)
def main():
target_url = "https://your-target-site.com"
recaptcha_v3_key = "6LcXXXXXXXXXXXXXXXXXXXXXXXXX"
# 为 v3 设置无头浏览器
co = ChromiumOptions()
co.headless()
page = ChromiumPage(co)
page.get(target_url)
# 以 "search" 动作解决 reCAPTCHA v3
print("解决 reCAPTCHA v3...")
token = solve_recaptcha_v3(
recaptcha_v3_key,
target_url,
action="search",
min_score=0.9 # 请求高分
)
# 使用令牌执行回调
page.run_js(f'''
// 如果有回调函数,用令牌调用它
if (typeof onRecaptchaSuccess === 'function') {{
onRecaptchaSuccess('{token}');
}}
// 或设置隐藏字段的值
var responseField = document.querySelector('[name="g-recaptcha-response"]');
if (responseField) {{
responseField.value = '{token}';
}}
''')
print("已绕过reCAPTCHA v3!")
if __name__ == "__main__":
main()6.4. 使用动作链实现人类行为
DrissionPage的动作链提供自然的鼠标移动和键盘交互:
python
import time
import random
from DrissionPage import ChromiumPage
from DrissionPage.common import Keys, Actions
def human_delay():
"""模拟人类行为的随机延迟。"""
time.sleep(random.uniform(0.5, 1.5))
def main():
page = ChromiumPage()
page.get('https://your-target-site.com/form')
# 使用动作链进行人类行为交互
ac = Actions(page)
# 自然移动到输入字段,然后点击并输入
ac.move_to('input[name="email"]').click()
human_delay()
# 慢速输入,模拟人类行为
for char in "user@email.com":
ac.type(char)
time.sleep(random.uniform(0.05, 0.15))
human_delay()
# 移动到密码字段
ac.move_to('input[name="password"]').click()
human_delay()
# 输入密码
page('input[name="password"]').input("mypassword123")
# 解决CAPTCHA后,自然移动并点击提交
ac.move_to('button[type="submit"]')
human_delay()
ac.click()
if __name__ == "__main__":
main()7. 最佳实践
7.1. 浏览器配置
配置DrissionPage以更像普通浏览器:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.set_argument('--disable-blink-features=AutomationControlled')
co.set_argument('--no-sandbox')
co.set_user_agent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
# 设置常见分辨率
co.set_argument('--window-size=1920,1080')
page = ChromiumPage(co)7.2. 无痕模式和无头模式
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.incognito() # 使用无痕模式
co.headless() # 无头模式(适用于v3 CAPTCHA)
page = ChromiumPage(co)7.3. 速率限制
通过添加随机延迟避免触发速率限制:
python
import random
import time
def human_delay(min_sec=1.0, max_sec=3.0):
"""模拟人类行为的随机延迟。"""
time.sleep(random.uniform(min_sec, max_sec))
# 在操作之间使用
page('#button1').click()
human_delay()
page('#input1').input('text')7.4. 错误处理
始终为CAPTCHA求解实现适当的错误处理:
python
def solve_with_retry(task_payload: dict, max_retries: int = 3) -> dict:
"""带重试逻辑的CAPTCHA求解。"""
for attempt in range(max_retries):
try:
return solve_captcha(task_payload)
except TimeoutError:
if attempt < max_retries - 1:
print(f"超时,正在重试... ({attempt + 1}/{max_retries})")
time.sleep(5)
else:
raise
except Exception as e:
if "balance" in str(e).lower():
raise # 不重试余额错误
if attempt < max_retries - 1:
time.sleep(2)
else:
raise7.5. 代理支持
使用代理与DrissionPage进行IP轮换:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.set_proxy('http://username:password@proxy.example.com:8080')
page = ChromiumPage(co)8. 结论
DrissionPage 和 CapSolver 的集成创建了一个强大的网页自动化工具包:
- DrissionPage 处理浏览器自动化而不使用WebDriver检测签名
- CapSolver 使用AI驱动的求解能力处理CAPTCHA
- 两者结合 实现了看似完全人类的无缝自动化
无论你是构建网络爬虫、自动化测试系统还是数据收集管道,这种组合都能提供所需的可靠性和隐蔽性。
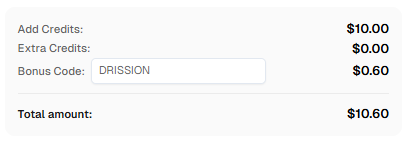
提示:在 CapSolver 注册时使用代码
DRISSION可获得额外积分!
9. 常见问题
9.1. 为什么选择DrissionPage而不是Selenium?
DrissionPage不使用WebDriver,这意味着:
- 无需下载/更新chromedriver
- 避免常见的WebDriver检测签名
- 更简单的API并内置等待
- 更好的性能和资源使用
- 原生支持跨iframe元素定位
9.2. 哪些CAPTCHA类型与该集成效果最好?
CapSolver支持所有主要的CAPTCHA类型。Cloudflare Turnstile和reCAPTCHA v2/v3的成功率最高。该集成与CapSolver支持的任何CAPTCHA都能无缝配合。
9.3. 能否在无头模式下使用?
可以!DrissionPage支持无头模式。对于reCAPTCHA v3和基于令牌的CAPTCHA,无头模式运行完美。对于v2可见CAPTCHA,使用有头模式可能效果更好。
9.4. 如何找到CAPTCHA的站点密钥?
在页面源代码中查找:
- Turnstile:
data-sitekey属性或cf-turnstile元素 - reCAPTCHA:
g-recaptchadiv上的data-sitekey属性
9.5. 如果CAPTCHA求解失败怎么办?
常见解决方案:
- 验证API密钥和余额
- 确保站点密钥正确
- 检查页面URL是否与CAPTCHA出现的页面匹配
- 对于v3,尝试调整action参数和最小分数
- 实现带延迟的重试逻辑
9.6. DrissionPage能否处理shadow DOM?
可以!DrissionPage通过ChromiumShadowElement类原生支持shadow DOM元素。


