如何通过CapSolver集成解决CrewAI中的验证码问题

Emma Foster
Machine Learning Engineer
TL;DR: CrewAI工作流经常遇到验证码;集成CapSolver可以让自动化脚本高效地解决它们。

简介
在使用CrewAI自动化任务时,例如网络爬虫或浏览,验证码很容易阻止你的工作流。这些挑战在访问受保护的网站时很常见,甚至会中断设计良好的自动化脚本。
CapSolver提供了一种可靠的方式来处理验证码,使CrewAI能够在不进行人工干预的情况下继续其任务。通过集成CapSolver,您可以简化自动化浏览和数据收集,同时遵守网站的保护措施。
什么是CrewAI?
CrewAI 是一个轻量级、快速的Python框架,用于构建自主AI代理系统。CrewAI完全从零开始构建,完全独立于LangChain或其他代理框架,提供了高易用性和细粒度的自定义能力。
CrewAI的关键功能
- 多代理协作:创建可以自主协作的AI代理团队,实现灵活的问题解决和专业角色分配
- 事件驱动的工作流(Flows):通过细粒度路径管理、状态一致性和条件分支实现精确的执行控制
- 独立设计:无外部框架依赖,为速度而设计,资源需求最小
- 适用于生产环境:设计符合企业级可靠性和可扩展性标准
- 广泛的社区:通过社区培训有超过100,000名认证开发者
核心架构
CrewAI基于两种互补的范式运行:
| 组件 | 描述 |
|---|---|
| Crews | 自主协作的多代理团队,通过专业角色实现灵活的问题解决 |
| Flows | 事件驱动的工作流,为复杂的业务逻辑提供精确的执行控制 |
什么是CapSolver?
CapSolver 是一个领先的验证码解决服务,提供AI驱动的解决方案来绕过各种验证码挑战。CapSolver支持多种验证码类型,并具有闪电般的响应速度,可以无缝集成到自动化工作流中。
支持的验证码类型
- reCAPTCHA v2(图片和隐形)
- reCAPTCHA v3
- Cloudflare Turnstile
- Cloudflare Challenge(5秒)
- AWS WAF
- 以及更多...
为什么将CapSolver与CrewAI集成?
在构建与网站交互的CrewAI代理时——无论是用于数据收集、自动化测试还是内容聚合——验证码挑战会成为一个显著的障碍。以下是集成的重要性:
- 不间断的代理工作流:代理可以在无需人工干预的情况下完成任务
- 可扩展的自动化:在并发代理操作中处理多个验证码挑战
- 成本效益:仅对成功解决的验证码付费
- 高成功率:所有支持的验证码类型都具有行业领先的准确性
安装
首先,安装所需的包:
bash
pip install crewai
pip install 'crewai[tools]'
pip install requests为CrewAI创建自定义CapSolver工具
CrewAI允许您创建自定义工具,代理可以使用这些工具来完成任务。以下是创建CapSolver工具的方法,用于处理验证码挑战:
基本CapSolver工具实现
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class CaptchaSolverInput(BaseModel):
"""验证码解决工具的输入模式。"""
website_url: str = Field(..., description="带有验证码的网站的URL")
website_key: str = Field(..., description="验证码的站点密钥")
captcha_type: str = Field(default="ReCaptchaV2TaskProxyLess", description="要解决的验证码类型")
class CaptchaSolverTool(BaseTool):
name: str = "captcha_solver"
description: str = "使用CapSolver API解决验证码挑战。支持reCAPTCHA v2、v3、Turnstile等。"
args_schema: Type[BaseModel] = CaptchaSolverInput
def _run(self, website_url: str, website_key: str, captcha_type: str = "ReCaptchaV2TaskProxyLess") -> str:
# 创建任务
create_task_url = "https://api.capsolver.com/createTask"
task_payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": captcha_type,
"websiteURL": website_url,
"websiteKey": website_key
}
}
response = requests.post(create_task_url, json=task_payload)
result = response.json()
if result.get("errorId") != 0:
return f"创建任务时出错: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 轮询结果
get_result_url = "https://api.capsolver.com/getTaskResult"
for _ in range(60): # 最多60次尝试
time.sleep(2)
result_payload = {
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
response = requests.post(get_result_url, json=result_payload)
result = response.json()
if result.get("status") == "ready":
solution = result.get("solution", {})
return solution.get("gRecaptchaResponse") or solution.get("token")
elif result.get("status") == "failed":
return f"任务失败: {result.get('errorDescription')}"
return "等待验证码解决方案超时"解决不同类型的验证码
reCAPTCHA v2 解决器
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class ReCaptchaV2Input(BaseModel):
"""reCAPTCHA v2 解决器的输入模式。"""
website_url: str = Field(..., description="带有reCAPTCHA v2的网站的URL")
website_key: str = Field(..., description="reCAPTCHA的站点密钥")
class ReCaptchaV2Tool(BaseTool):
name: str = "recaptcha_v2_solver"
description: str = "使用CapSolver解决reCAPTCHA v2挑战"
args_schema: Type[BaseModel] = ReCaptchaV2Input
def _run(self, website_url: str, website_key: str) -> str:
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key
}
}
return self._solve_captcha(payload)
def _solve_captcha(self, payload: dict) -> str:
# 创建任务
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
return f"错误: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 轮询结果
for attempt in range(60):
time.sleep(2)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
if result.get("status") == "failed":
return f"失败: {result.get('errorDescription')}"
return "等待解决方案超时"reCAPTCHA v3 解决器
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class ReCaptchaV3Input(BaseModel):
"""reCAPTCHA v3 解决器的输入模式。"""
website_url: str = Field(..., description="带有reCAPTCHA v3的网站的URL")
website_key: str = Field(..., description="reCAPTCHA的站点密钥")
page_action: str = Field(default="submit", description="reCAPTCHA v3的动作参数")
class ReCaptchaV3Tool(BaseTool):
name: str = "recaptcha_v3_solver"
description: str = "使用基于分数验证的CapSolver解决reCAPTCHA v3挑战"
args_schema: Type[BaseModel] = ReCaptchaV3Input
def _run(
self,
website_url: str,
website_key: str,
page_action: str = "submit"
) -> str:
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key,
"pageAction": page_action
}
}
# 创建任务
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
return f"错误: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 轮询结果
for attempt in range(60):
time.sleep(2)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
if result.get("status") == "failed":
return f"失败: {result.get('errorDescription')}"
return "等待解决方案超时"Cloudflare Turnstile 解决器
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class TurnstileInput(BaseModel):
"""Turnstile 解决器的输入模式。"""
website_url: str = Field(..., description="带有Turnstile的网站的URL")
website_key: str = Field(..., description="Turnstile小部件的站点密钥")
class TurnstileTool(BaseTool):
name: str = "turnstile_solver"
description: str = "解决Cloudflare Turnstile挑战"
args_schema: Type[BaseModel] = TurnstileInput
def _run(self, website_url: str, website_key: str) -> str:
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key
}
}
# 创建任务
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
return f"错误: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 轮询结果
for attempt in range(60):
time.sleep(2)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return result["solution"]["token"]
if result.get("status") == "failed":
return f"失败: {result.get('errorDescription')}"
return "等待解决方案超时"Cloudflare Challenge(5秒)解决器
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class CloudflareChallengeInput(BaseModel):
"""Cloudflare Challenge 解决器的输入模式。"""
website_url: str = Field(..., description="受保护页面的URL")
proxy: str = Field(..., description="代理格式: http://user:pass@ip:port")
class CloudflareChallengeTool(BaseTool):
name: str = "cloudflare_challenge_solver"
description: str = "解决Cloudflare 5秒挑战页面"
args_schema: Type[BaseModel] = CloudflareChallengeInput
def _run(self, website_url: str, proxy: str) -> dict:
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiCloudflareTask",
"websiteURL": website_url,
"proxy": proxy
}
}
# 创建任务
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
return f"错误: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 询结果
for attempt in range(60):
time.sleep(3)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return {
"cookies": result["solution"]["cookies"],
"user_agent": result["solution"]["userAgent"]
}
if result.get("status") == "failed":
return f"失败: {result.get('errorDescription')}"
return "等待解决方案超时"如何提交验证码令牌
每种验证码类型需要不同的提交方法:
reCAPTCHA v2/v3 - 令牌注入
对于reCAPTCHA,将令牌注入到隐藏的文本区域并提交表单:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
def submit_recaptcha_token(driver, token: str):
"""注入reCAPTCHA令牌并提交"""
# 使隐藏的文本区域可见并设置令牌
recaptcha_response = driver.find_element(By.ID, "g-recaptcha-response")
driver.execute_script("arguments[0].style.display = 'block';", recaptcha_response)
recaptcha_response.clear()
recaptcha_response.send_keys(token)
# 提交表单
form = driver.find_element(By.TAG_NAME, "form")
form.submit()Turnstile - 令牌注入
对于Turnstile,将令牌设置在隐藏的输入中:
python
def submit_turnstile_token(driver, token: str):
"""注入Turnstile令牌并提交"""
# 在隐藏的输入中设置令牌
turnstile_input = driver.find_element(By.NAME, "cf-turnstile-response")
driver.execute_script("arguments[0].value = arguments[1];", turnstile_input, token)
# 提交表单
form = driver.find_element(By.TAG_NAME, "form")
form.submit()Cloudflare Challenge - 使用 Cookies
对于Cloudflare Challenge(5秒),CapSolver返回的是cookies和user-agent,而不是令牌。在您的请求中使用这些:
python
import requests
def use_cookies_for_cloudflare(challenge_cookies: dict, user_agent: str, url: str):
"""使用Cloudflare的cookies和user-agent进行请求"""
session = requests.Session()
session.cookies.update(challenge_cookies)
session.headers.update({"User-Agent": user_agent})
response = session.get(url)
print(response.text)import requests
def access_cloudflare_protected_page(url: str, cf_solution: dict):
"""
使用 Cloudflare 挑战解决方案访问受保护的页面。
cf_solution 包含 CapSolver 提供的 'cookies' 和 'user_agent'。
"""
# 使用解决的 cookies 创建会话
session = requests.Session()
# 设置 CapSolver 解决方案中的 cookies
for cookie in cf_solution["cookies"]:
session.cookies.set(cookie["name"], cookie["value"])
# 设置用于解决的用户代理
headers = {
"User-Agent": cf_solution["user_agent"]
}
# 现在可以访问受保护的页面
response = session.get(url, headers=headers)
return response.text### 完整的爬虫示例
```python
import requests
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
def solve_recaptcha(website_url: str, website_key: str) -> str:
"""从 CapSolver 获取 reCAPTCHA 令牌"""
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"错误: {result.get('errorDescription')}")
task_id = result.get("taskId")
for _ in range(60):
time.sleep(2)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
if result.get("status") == "failed":
raise Exception(f"失败: {result.get('errorDescription')}")
raise Exception("超时")
def scrape_with_recaptcha(target_url: str, site_key: str):
"""完整流程: 解决 reCAPTCHA → 提交 → 爬取"""
driver = webdriver.Chrome()
driver.get(target_url)
try:
# 1. 解决 CAPTCHA
token = solve_recaptcha(target_url, site_key)
# 2. 注入令牌
recaptcha_response = driver.find_element(By.ID, "g-recaptcha-response")
driver.execute_script("arguments[0].style.display = 'block';", recaptcha_response)
recaptcha_response.clear()
recaptcha_response.send_keys(token)
# 3. 提交表单
driver.find_element(By.TAG_NAME, "form").submit()
# 4. 爬取内容
time.sleep(3) # 等待页面加载
return driver.page_source
finally:
driver.quit()使用 CapSolver 浏览器扩展
在需要在 CrewAI 中进行浏览器自动化的场景中,可以使用 CapSolver 浏览器扩展:
-
下载扩展程序:从 capsolver.com 获取 CapSolver 扩展
-
使用 Selenium/Playwright 配置:在浏览器自动化工具中加载扩展
-
自动解决模式:扩展会自动检测并解决 CAPTCHAs
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 配置 Chrome 以使用 CapSolver 扩展
chrome_options = Options()
chrome_options.add_extension("path/to/capsolver-extension.crx")
driver = webdriver.Chrome(options=chrome_options)
# 扩展将自动处理 CAPTCHAs
driver.get("https://example.com/protected-page")最佳实践
1. 错误处理
python
def solve_with_retry(self, payload: dict, max_retries: int = 3) -> str:
for attempt in range(max_retries):
try:
result = self._solve_captcha(payload)
if result:
return result
except Exception as e:
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt) # 指数退避2. 余额管理
python
def check_balance() -> float:
response = requests.post(
"https://api.capsolver.com/getBalance",
json={"clientKey": CAPSOLVER_API_KEY}
)
return response.json().get("balance", 0)3. 缓存解决方案
对于需要重复访问的页面,可以适当缓存 CAPTCHA 令牌:
python
from functools import lru_cache
from datetime import datetime, timedelta
captcha_cache = {}
def get_cached_token(website_url: str, website_key: str) -> str:
cache_key = f"{website_url}:{website_key}"
if cache_key in captcha_cache:
token, timestamp = captcha_cache[cache_key]
if datetime.now() - timestamp < timedelta(minutes=2):
return token
# 解决新的 CAPTCHA
new_token = solve_captcha(website_url, website_key)
captcha_cache[cache_key] = (new_token, datetime.now())
return new_token结论
将 CapSolver 与 CrewAI 集成可以释放自主 AI 代理在基于网络任务中的全部潜力。通过将 CrewAI 强大的多代理编排能力与 CapSolver 行业领先的 CAPTCHA 解决能力结合,开发者可以构建能够处理最复杂网络保护机制的稳健自动化解决方案。
无论您是构建数据提取管道、自动化测试框架还是智能网络代理,CrewAI + CapSolver 的组合都提供了生产环境所需的可靠性和可扩展性。
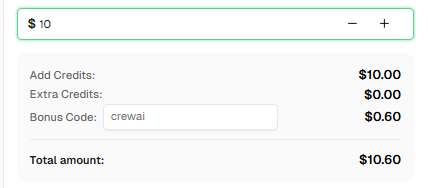
准备好了吗? 注册 CapSolver 并使用优惠码 CREWAI 在每次充值时获得额外 6% 的奖励!
常见问题
CrewAI 是什么?
CrewAI 是一个轻量级、快速的 Python 框架,用于构建自主 AI 代理系统。它使开发者能够创建协作完成复杂任务的 AI 代理团队,支持自主决策和精确的工作流控制。
CapSolver 如何与 CrewAI 集成?
CapSolver 通过自定义工具与 CrewAI 集成。您创建一个封装 CapSolver API 的工具,使您的 AI 代理在遇到网络操作中的 CAPTCHA 挑战时能够自动解决。
CapSolver 能解决哪些类型的 CAPTCHA?
CapSolver 支持多种 CAPTCHA 类型,包括 reCAPTCHA v2、reCAPTCHA v3、Cloudflare Turnstile、Cloudflare Challenge、AWS WAF、GeeTest 等。
CapSolver 的费用是多少?
CapSolver 根据解决的 CAPTCHA 类型和数量提供具有竞争力的定价。访问 capsolver.com 获取当前定价详情。使用代码 CREWAI 在首次充值时获得 6% 的奖励。
我可以将 CapSolver 与其他 Python 框架一起使用吗?
是的!CapSolver 提供 REST API,可以与任何 Python 框架集成,包括 Scrapy、Selenium、Playwright 等。
CrewAI 是否免费使用?
是的,CrewAI 是开源的,采用 MIT 许可证发布。该框架可免费使用,但您可能需要承担 LLM API 调用(如 OpenAI)和 CAPTCHA 解决服务(如 CapSolver)的费用。
如何找到 CAPTCHA 网站密钥?
网站密钥通常在页面的 HTML 源代码中找到。查找:
- reCAPTCHA:
data-sitekey属性或grecaptcha.render()调用 - :
data-sitekey属性 - Turnstile: Turnstile 小部件中的
data-sitekey属性



