如何在浏览器4中通过CapSolver集成解决验证码

Lucas Mitchell
Automation Engineer

对于网络自动化,Browser4(来自PulsarRPA)已成为一种闪电般的快速、协程安全的浏览器引擎,专为AI驱动的数据提取而设计。其能力支持每台机器每天10万至20万次复杂页面访问,Browser4专为大规模应用而构建。然而,当从受保护的网站提取数据时,验证码挑战成为主要障碍。
CapSolver 为Browser4的自动化功能提供了完美的补充,使您的代理能够无缝地通过验证码保护的页面。这种集成结合了Browser4的高吞吐量浏览器自动化与行业领先的验证码解决能力。
什么是Browser4?
Browser4 是一个高性能、协程安全的浏览器自动化框架,使用Kotlin构建。它专为需要自主代理功能、极端吞吐量以及结合LLM、机器学习和选择器方法的混合数据提取的AI应用而设计。
Browser4 的关键特性
- 极端吞吐量:每台机器每天10万至20万次复杂页面访问
- 协程安全:使用Kotlin协程实现高效的并行处理
- AI驱动的代理:能够进行推理并执行多步骤任务的自主浏览器代理
- 混合提取:结合LLM智能、机器学习算法和CSS/XPath选择器
- X-SQL查询:扩展的SQL语法用于复杂数据提取
- 反机器人功能:配置文件轮换、代理支持和弹性调度
核心API方法
| 方法 | 描述 |
|---|---|
session.open(url) |
加载页面并返回 PageSnapshot |
session.parse(page) |
将快照转换为内存中的文档 |
driver.selectFirstTextOrNull(selector) |
从实时DOM中检索文本 |
driver.evaluate(script) |
在浏览器中执行JavaScript |
session.extract(document, fieldMap) |
将CSS选择器映射到结构化字段 |
什么是CapSolver?
CapSolver 是一家领先的验证码解决服务,提供AI驱动的解决方案,用于绕过各种验证码挑战。凭借对多种验证码类型的支持和闪电般的响应时间,CapSolver可无缝集成到自动化工作流中。
支持的验证码类型
为什么将CapSolver与Browser4集成?
当构建与受保护网站交互的Browser4自动化时——无论是用于数据提取、价格监控还是市场研究——验证码挑战都会成为主要障碍。以下是集成的重要性:
- 不间断的高吞吐量提取:在不被验证码阻止的情况下保持每天10万+的页面访问量
- 可扩展的操作:在并行协程执行中处理验证码
- 无缝的工作流程:将验证码解决作为提取流程的一部分
- 成本效益高:仅对成功解决的验证码付费
- 高成功率:对所有支持的验证码类型具有行业领先的准确性
安装
先决条件
- Java 17 或更高版本
- Maven 3.6+ 或 Gradle
- 一个 CapSolver API 密钥

添加依赖项
Maven (pom.xml):
xml
<dependencies>
<!-- Browser4/PulsarRPA -->
<dependency>
<groupId>ai.platon.pulsar</groupId>
<artifactId>pulsar-boot</artifactId>
<version>2.2.0</version>
</dependency>
<!-- HTTP Client for CapSolver -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- JSON 解析 -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
<!-- Kotlin 协程 -->
<dependency>
<groupId>org.jetbrains.kotlinx</groupId>
<artifactId>kotlinx-coroutines-core</artifactId>
<version>1.8.0</version>
</dependency>
</dependencies>Gradle (build.gradle.kts):
kotlin
dependencies {
implementation("ai.platon.pulsar:pulsar-boot:2.2.0")
implementation("com.squareup.okhttp3:okhttp:4.12.0")
implementation("com.google.code.gson:gson:2.10.1")
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.8.0")
}环境设置
创建一个 application.properties 文件:
properties
# CapSolver 配置
CAPSOLVER_API_KEY=your_capsolver_api_key
# LLM 配置(可选,用于AI提取)
OPENROUTER_API_KEY=your_openrouter_api_key
# 代理配置(可选)
PROXY_ROTATION_URL=your_proxy_url为Browser4创建CapSolver服务
以下是一个可重复使用的Kotlin服务,用于将CapSolver与Browser4集成:
基本CapSolver服务
kotlin
import com.google.gson.Gson
import com.google.gson.JsonObject
import okhttp3.MediaType.Companion.toMediaType
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.RequestBody.Companion.toRequestBody
import kotlinx.coroutines.delay
import java.util.concurrent.TimeUnit
data class TaskResult(
val gRecaptchaResponse: String? = null,
val token: String? = null,
val cookies: List<Map<String, String>>? = null,
val userAgent: String? = null
)
class CapSolverService(private val apiKey: String) {
private val client = OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(30, TimeUnit.SECONDS)
.build()
private val gson = Gson()
private val baseUrl = "https://api.capsolver.com"
private val jsonMediaType = "application/json".toMediaType()
private suspend fun createTask(taskData: Map<String, Any>): String {
val payload = mapOf(
"clientKey" to apiKey,
"task" to taskData
)
val request = Request.Builder()
.url("$baseUrl/createTask")
.post(gson.toJson(payload).toRequestBody(jsonMediaType))
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
if (result.get("errorId").asInt != 0) {
throw Exception("CapSolver error: ${result.get("errorDescription").asString}")
}
return result.get("taskId").asString
}
private suspend fun getTaskResult(taskId: String, maxAttempts: Int = 60): TaskResult {
val payload = mapOf(
"clientKey" to apiKey,
"taskId" to taskId
)
repeat(maxAttempts) {
delay(2000)
val request = Request.Builder()
.url("$baseUrl/getTaskResult")
.post(gson.toJson(payload).toRequestBody(jsonMediaType))
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
when (result.get("status")?.asString) {
"ready" -> {
val solution = result.getAsJsonObject("solution")
return TaskResult(
gRecaptchaResponse = solution.get("gRecaptchaResponse")?.asString,
token = solution.get("token")?.asString,
userAgent = solution.get("userAgent")?.asString
)
}
"failed" -> throw Exception("Task failed: ${result.get("errorDescription")?.asString}")
}
}
throw Exception("Timeout waiting for CAPTCHA solution")
}
suspend fun solveReCaptchaV2(websiteUrl: String, websiteKey: String): String {
val taskId = createTask(mapOf(
"type" to "ReCaptchaV2TaskProxyLess",
"websiteURL" to websiteUrl,
"websiteKey" to websiteKey
))
val result = getTaskResult(taskId)
return result.gRecaptchaResponse ?: throw Exception("No gRecaptchaResponse in solution")
}
suspend fun solveReCaptchaV3(
websiteUrl: String,
websiteKey: String,
pageAction: String = "submit"
): String {
val taskId = createTask(mapOf(
"type" to "ReCaptchaV3TaskProxyLess",
"websiteURL" to websiteUrl,
"websiteKey" to websiteKey,
"pageAction" to pageAction
))
val result = getTaskResult(taskId)
return result.gRecaptchaResponse ?: throw Exception("No gRecaptchaResponse in solution")
}
suspend fun solveTurnstile(
websiteUrl: String,
websiteKey: String,
action: String? = null,
cdata: String? = null
): String {
val taskData = mutableMapOf(
"type" to "AntiTurnstileTaskProxyLess",
"websiteURL" to websiteUrl,
"websiteKey" to websiteKey
)
// 添加可选元数据
if (action != null || cdata != null) {
val metadata = mutableMapOf<String, String>()
action?.let { metadata["action"] = it }
cdata?.let { metadata["cdata"] = it }
taskData["metadata"] = metadata
}
val taskId = createTask(taskData)
val result = getTaskResult(taskId)
return result.token ?: throw Exception("No token in solution")
}
suspend fun checkBalance(): Double {
val payload = mapOf("clientKey" to apiKey)
val request = Request.Builder()
.url("$baseUrl/getBalance")
.post(gson.toJson(payload).toRequestBody(jsonMediaType))
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
return result.get("balance")?.asDouble ?: 0.0
}
}解决不同类型的验证码
使用Browser4的reCAPTCHA v2
kotlin
import ai.platon.pulsar.context.PulsarContexts
import ai.platon.pulsar.skeleton.session.PulsarSession
import kotlinx.coroutines.runBlocking
class ReCaptchaV2Extractor(
private val capSolver: CapSolverService
) {
suspend fun extractWithCaptcha(targetUrl: String, siteKey: String): Map<String, Any?> {
println("解决 reCAPTCHA v2...")
// 首先解决验证码
val token = capSolver.solveReCaptchaV2(targetUrl, siteKey)
println("验证码已解决,令牌长度: ${token.length}")
// 创建会话并打开页面
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// 使用 value 属性将令牌注入隐藏的文本区域(安全)
driver?.evaluate("""
(function() {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = arguments[0];
})('$token');
""")
// 提交表单
driver?.evaluate("document.querySelector('form').submit();")
// 等待导航
Thread.sleep(3000)
// 从结果页面提取数据
val document = session.parse(page)
mapOf(
"title" to document.selectFirstTextOrNull("h1"),
"content" to document.selectFirstTextOrNull(".content"),
"success" to (document.body().text().contains("success", ignoreCase = true))
)
}
}
fun main() = runBlocking {
val apiKey = System.getenv("CAPSOLVER_API_KEY") ?: "your_api_key"
val capSolver = CapSolverService(apiKey)
val extractor = ReCaptchaV2Extractor(capSolver)
val result = extractor.extractWithCaptcha(
targetUrl = "https://example.com/protected-page",
siteKey = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC"
)
println("提取结果: $result")
}使用Browser4的reCAPTCHA v3
kotlin
class ReCaptchaV3Extractor(
private val capSolver: CapSolverService
) {
suspend fun extractWithCaptchaV3(
targetUrl: String,
siteKey: String,
action: String = "submit"
): Map<String, Any?> {
println("使用动作: $action 解决 reCAPTCHA v3")
// 使用自定义页面动作解决 reCAPTCHA v3
val token = capSolver.solveReCaptchaV3(
websiteUrl = targetUrl,
websiteKey = siteKey,
pageAction = action
)
println("令牌获取成功")
// 创建会话并打开页面
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// 将令牌注入隐藏输入(使用安全的值赋值)
driver?.evaluate("""
(function(tokenValue) {
var input = document.querySelector('input[name="g-recaptcha-response"]');
if (input) {
input.value = tokenValue;
} else {
var hidden = document.createElement('input');
hidden.type = 'hidden';
hidden.name = 'g-recaptcha-response';
hidden.value = tokenValue;
var form = document.querySelector('form');
if (form) form.appendChild(hidden);
}
})('$token');
""")
// 点击提交按钮
driver?.evaluate("document.querySelector('#submit-btn').click();")
Thread.sleep(3000)
val document = session.parse(page)
mapOf(
"result" to document.selectFirstTextOrNull(".result-data"),
"status" to "success"
)
}
}使用Browser4的Cloudflare Turnstile
kotlin
class TurnstileExtractor(
private val capSolver: CapSolverService
) {
suspend fun extractWithTurnstile(targetUrl: String, siteKey: String): Map<String, Any?> {
println("解决 Cloudflare Turnstile...")
// 使用可选元数据(action 和 cdata)解决
val token = capSolver.solveTurnstile(targetUrl, siteKey)
println("Turnstile 已解决,令牌长度: ${token.length}")
// 创建会话并打开页面
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// 将令牌注入隐藏输入
driver?.evaluate("""
(function(tokenValue) {
var input = document.querySelector('input[name="cf-turnstile-response"]');
if (input) {
input.value = tokenValue;
} else {
var hidden = document.createElement('input');
hidden.type = 'hidden';
hidden.name = 'cf-turnstile-response';
hidden.value = tokenValue;
var form = document.querySelector('form');
if (form) form.appendChild(hidden);
}
})('$token');
""")
// 提交表单
driver?.evaluate("document.querySelector('form').submit();")
// 等待导航
Thread.sleep(3000)
// 从结果页面提取数据
val document = session.parse(page)
mapOf(
"result" to document.selectFirstTextOrNull(".result-data"),
"status" to "success"
)
}
}val token = capSolver.solveTurnstile(
targetUrl,
siteKey,
action = "login", // optional
cdata = "0000-1111-2222-3333-example" // optional
)
println("Turnstile solved!")
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// Inject Turnstile token (using safe value assignment)
driver?.evaluate("""
(function(tokenValue) {
var input = document.querySelector('input[name="cf-turnstile-response"]');
if (input) input.value = tokenValue;
})('$token');
""")
// Submit
driver?.evaluate("document.querySelector('form').submit();")
Thread.sleep(3000)
val document = session.parse(page)
mapOf(
"title" to document.selectFirstTextOrNull("title"),
"content" to document.selectFirstTextOrNull("body")?.take(500)
)
}}
---
## 与 Browser4 X-SQL 的集成
Browser4 的 X-SQL 提供了强大的提取功能。以下是将其与 CAPTCHA 解决方案结合的方法:
```kotlin
class XSqlCaptchaExtractor(
private val capSolver: CapSolverService
) {
suspend fun extractProductsWithCaptcha(
targetUrl: String,
siteKey: String
): List<Map<String, Any?>> {
// 预先解决 CAPTCHA
val token = capSolver.solveReCaptchaV2(targetUrl, siteKey)
// 创建会话并建立已认证会话
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
driver?.evaluate("""
(function(tokenValue) {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = tokenValue;
document.querySelector('form').submit();
})('$token');
""")
Thread.sleep(3000)
// 现在解析页面并提取产品数据
val document = session.parse(page)
// 使用内置的会话方法提取产品数据
val products = mutableListOf<Map<String, Any?>>()
val productElements = document.select(".product-item")
for ((index, element) in productElements.withIndex()) {
if (index >= 50) break // LIMIT 50
products.add(mapOf(
"name" to element.selectFirstTextOrNull(".product-name"),
"price" to element.selectFirstTextOrNull(".price")?.let {
"""(\d+\.?\d*)""".toRegex().find(it)?.groupValues?.get(1)?.toDoubleOrNull() ?: 0.0
},
"rating" to element.selectFirstTextOrNull(".rating")
))
}
return products.map { row ->
mapOf(
"name" to row["name"],
"price" to row["price"],
"rating" to row["rating"],
"image_url" to row["image_url"]
)
}
}
}预认证模式
对于需要在访问内容前解决 CAPTCHA 的网站,请使用预认证工作流:
kotlin
import okhttp3.Cookie
import okhttp3.CookieJar
import okhttp3.HttpUrl
class PreAuthenticator(
private val capSolver: CapSolverService
) {
data class AuthSession(
val cookies: Map<String, String>,
val userAgent: String?
)
suspend fun authenticateWithCaptcha(
loginUrl: String,
siteKey: String
): AuthSession {
// 解决 CAPTCHA
val captchaToken = capSolver.solveReCaptchaV2(loginUrl, siteKey)
// 提交 CAPTCHA 以获取会话 cookies
val client = OkHttpClient.Builder()
.cookieJar(object : CookieJar {
private val cookies = mutableListOf<Cookie>()
override fun saveFromResponse(url: HttpUrl, cookieList: List<Cookie>) {
cookies.addAll(cookieList)
}
override fun loadForRequest(url: HttpUrl): List<Cookie> = cookies
})
.build()
val formBody = okhttp3.FormBody.Builder()
.add("g-recaptcha-response", captchaToken)
.build()
val request = Request.Builder()
.url(loginUrl)
.post(formBody)
.build()
val response = client.newCall(request).execute()
// 从响应中提取 cookies
val responseCookies = response.headers("Set-Cookie")
.associate { cookie ->
val parts = cookie.split(";")[0].split("=", limit = 2)
parts[0] to (parts.getOrNull(1) ?: "")
}
return AuthSession(
cookies = responseCookies,
userAgent = response.request.header("User-Agent")
)
}
}
class AuthenticatedExtractor(
private val preAuth: PreAuthenticator,
private val capSolver: CapSolverService
) {
suspend fun extractWithAuth(
loginUrl: String,
targetUrl: String,
siteKey: String
): Map<String, Any?> {
// 预认证
val authSession = preAuth.authenticateWithCaptcha(loginUrl, siteKey)
println("使用 ${authSession.cookies.size} 个 cookies 建立了会话")
// 创建 Browser4 会话
val session = PulsarContexts.createSession()
// 配置会话 cookies
val cookieScript = authSession.cookies.entries.joinToString(";") { (k, v) ->
"$k=$v"
}
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// 设置 cookies
driver?.evaluate("document.cookie = '$cookieScript';")
// 重新加载以使用已认证会话
driver?.evaluate("location.reload();")
Thread.sleep(2000)
// 提取数据
val document = session.parse(page)
return mapOf(
"authenticated" to true,
"content" to document.selectFirstTextOrNull(".protected-content"),
"userData" to document.selectFirstTextOrNull(".user-profile")
)
}
}使用 OpenRouter 的 LLM 提取增强
Browser4 的 AI 能力可以通过 OpenRouter 进行增强,OpenRouter 是一个统一的 API 网关,用于访问各种 LLM 模型。这可以实现智能内容提取,适应不同的页面结构。
OpenRouter 服务
kotlin
import com.google.gson.Gson
import com.google.gson.JsonObject
import okhttp3.MediaType.Companion.toMediaType
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.RequestBody.Companion.toRequestBody
import java.util.concurrent.TimeUnit
data class ChatMessage(val role: String, val content: String)
data class ChatCompletion(val content: String, val model: String, val usage: TokenUsage)
data class TokenUsage(val promptTokens: Int, val completionTokens: Int, val totalTokens: Int)
class OpenRouterService(private val apiKey: String) {
private val client = OkHttpClient.Builder()
.connectTimeout(60, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.build()
private val gson = Gson()
private val baseUrl = "https://openrouter.ai/api/v1"
private val jsonMediaType = "application/json".toMediaType()
fun chat(
messages: List<ChatMessage>,
model: String = "openai/gpt-4o-mini"
): ChatCompletion {
val payload = mapOf(
"model" to model,
"messages" to messages.map { mapOf("role" to it.role, "content" to it.content) }
)
val request = Request.Builder()
.url("$baseUrl/chat/completions")
.header("Authorization", "Bearer $apiKey")
.post(gson.toJson(payload).toRequestBody(jsonMediaType))
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
val choice = result.getAsJsonArray("choices")?.get(0)?.asJsonObject
val content = choice?.getAsJsonObject("message")?.get("content")?.asString ?: ""
val usage = result.getAsJsonObject("usage")
return ChatCompletion(
content = content,
model = result.get("model")?.asString ?: model,
usage = TokenUsage(
promptTokens = usage?.get("prompt_tokens")?.asInt ?: 0,
completionTokens = usage?.get("completion_tokens")?.asInt ?: 0,
totalTokens = usage?.get("total_tokens")?.asInt ?: 0
)
)
}
fun extractStructuredData(html: String, schema: String): String {
val prompt = """
从以下 HTML 内容中提取以下数据。
仅返回符合此模式的 JSON: $schema
HTML:
${html.take(4000)}
""".trimIndent()
return chat(listOf(ChatMessage("user", prompt))).content
}
fun listModels(): List<String> {
val request = Request.Builder()
.url("$baseUrl/models")
.header("Authorization", "Bearer $apiKey")
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
return result.getAsJsonArray("data")?.mapNotNull {
it.asJsonObject.get("id")?.asString
} ?: emptyList()
}
}结合 CAPTCHA 解决方案的 LLM 提取
将 CAPTCHA 解决方案与智能内容提取结合:
kotlin
class SmartExtractor(
private val capSolver: CapSolverService,
private val openRouter: OpenRouterService
) {
suspend fun extractWithAI(
targetUrl: String,
siteKey: String?,
extractionPrompt: String
): Map<String, Any?> {
// 第一步:如果需要,解决 CAPTCHA
val captchaToken = siteKey?.let {
println("解决 CAPTCHA...")
capSolver.solveReCaptchaV2(targetUrl, it)
}
// 第二步:创建会话并打开页面
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
captchaToken?.let { token ->
driver?.evaluate("""
(function(tokenValue) {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = tokenValue;
var form = document.querySelector('form');
if (form) form.submit();
})('$token');
""")
Thread.sleep(3000)
}
// 第三步:提取页面内容
val document = session.parse(page)
val pageContent = document.body().text().take(8000)
// 第四步:使用 LLM 提取结构化数据
val llmResponse = openRouter.chat(listOf(
ChatMessage("system", "你是一个数据提取助手。从网页中提取结构化数据。"),
ChatMessage("user", """
$extractionPrompt
页面内容:
$pageContent
""".trimIndent())
))
println("LLM 使用了 ${llmResponse.usage.totalTokens} 个 token")
return mapOf(
"url" to targetUrl,
"captchaSolved" to (captchaToken != null),
"extractedData" to llmResponse.content,
"tokensUsed" to llmResponse.usage.totalTokens
)
}
}
// 使用示例
fun main() = runBlocking {
val capSolver = CapSolverService(System.getenv("CAPSOLVER_API_KEY")!!)
val openRouter = OpenRouterService(System.getenv("OPENROUTER_API_KEY")!!)
val extractor = SmartExtractor(capSolver, openRouter)
val result = extractor.extractWithAI(
targetUrl = "https://example.com/products",
siteKey = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC",
extractionPrompt = """
提取所有产品,包括:
- 名称
- 价格(数字格式)
- 可用性(in_stock/out_of_stock)
- 评分(1-5)
以 JSON 数组形式返回。
""".trimIndent()
)
println("提取结果: ${result["extractedData"]}")
}自适应选择器生成
使用 LLM 为未知页面结构生成 CSS 选择器:
kotlin
class AdaptiveExtractor(
private val capSolver: CapSolverService,
private val openRouter: OpenRouterService
) {
suspend fun extractWithAdaptiveSelectors(
targetUrl: String,
siteKey: String?,
dataFields: List<String>
): Map<String, Any?> {
// 首先解决 CAPTCHA
val token = siteKey?.let { capSolver.solveReCaptchaV2(targetUrl, it) }
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
token?.let { t ->
driver?.evaluate("""
(function(tokenValue) {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = tokenValue;
})('$t');
""")
}
// 获取页面 HTML 结构
val htmlSample = driver?.evaluate("document.body.innerHTML")?.toString()?.take(5000) ?: ""
// 让 LLM 生成选择器
val selectorPrompt = """
分析此 HTML 并为以下字段提供 CSS 选择器:${dataFields.joinToString(", ")}
HTML 样本:
$htmlSample
返回 JSON 格式:{"fieldName": "css-selector", ...}
""".trimIndent()
val selectorsJson = openRouter.chat(listOf(ChatMessage("user", selectorPrompt))).content
val selectors = Gson().fromJson(selectorsJson, Map::class.java) as Map<String, String>
// 使用生成的选择器进行提取
val document = session.parse(page)
val extractedData = selectors.mapValues { (_, selector) ->
document.selectFirstTextOrNull(selector)
}
return mapOf(
"url" to targetUrl,
"selectors" to selectors,
"data" to extractedData
)
}
}使用协程的并行提取
Browser4 的协程安全设计支持高效的并行 CAPTCHA 处理:
kotlin
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.Channel
data class ExtractionJob(
val url: String,
val siteKey: String?
)
data class ExtractionResult(
val url: String,
val data: Map<String, Any?>?,
val captchaSolved: Boolean,
val error: String?,
val duration: Long
)
class ParallelExtractor(
private val capSolver: CapSolverService,
private val concurrency: Int = 5
) {
suspend fun extractAll(jobs: List<ExtractionJob>): List<ExtractionResult> = coroutineScope {
val channel = Channel<ExtractionJob>(Channel.UNLIMITED)
val results = mutableListOf<ExtractionResult>()
// 将所有任务发送到通道
jobs.forEach { channel.send(it) }
channel.close()
// 以有限并发处理
val workers = (1..concurrency).map { workerId ->
async {
val workerResults = mutableListOf<ExtractionResult>()
// 每个worker创建自己的session以保证线程安全
val workerSession = PulsarContexts.createSession()
for (job in channel) {
val startTime = System.currentTimeMillis()
var captchaSolved = false
try {
// 如果提供了站点密钥则解决CAPTCHA
val token = job.siteKey?.let {
captchaSolved = true
capSolver.solveReCaptchaV2(job.url, it)
}
// 提取数据
val page = workerSession.open(job.url)
token?.let { t ->
val driver = workerSession.getOrCreateBoundDriver()
driver?.evaluate("""
(function(tokenValue) {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = tokenValue;
})('$t');
""")
}
val document = workerSession.parse(page)
workerResults.add(ExtractionResult(
url = job.url,
data = mapOf(
"title" to document.selectFirstTextOrNull("title"),
"h1" to document.selectFirstTextOrNull("h1")
),
captchaSolved = captchaSolved,
error = null,
duration = System.currentTimeMillis() - startTime
))
} catch (e: Exception) {
workerResults.add(ExtractionResult(
url = job.url,
data = null,
captchaSolved = captchaSolved,
error = e.message,
duration = System.currentTimeMillis() - startTime
))
}
}
workerResults
}
}
workers.awaitAll().flatten()
}
}
// 使用示例
fun main() = runBlocking {
val capSolver = CapSolverService(System.getenv("CAPSOLVER_API_KEY")!!)
val extractor = ParallelExtractor(capSolver, concurrency = 5)
val jobs = listOf(
ExtractionJob("https://site1.com/data", "6Lc..."),
ExtractionJob("https://site2.com/data", null),
ExtractionJob("https://site3.com/data", "6Lc..."),
)
val results = extractor.extractAll(jobs)
val solved = results.count { it.captchaSolved }
println("完成${results.size}次提取,解决$solved个CAPTCHA")
results.forEach { r ->
println("${r.url}: ${r.duration}ms - ${r.error ?: "成功"}")
}
}最佳实践
1. 带重试的错误处理
kotlin
suspend fun <T> withRetry(
maxRetries: Int = 3,
initialDelay: Long = 1000,
block: suspend () -> T
): T {
var lastException: Exception? = null
repeat(maxRetries) { attempt ->
try {
return block()
} catch (e: Exception) {
lastException = e
println("尝试${attempt + 1}失败: ${e.message}")
delay(initialDelay * (attempt + 1))
}
}
throw lastException ?: Exception("最大重试次数已用尽")
}
// 使用示例
val token = withRetry(maxRetries = 3) {
capSolver.solveReCaptchaV2(url, siteKey)
}2. 余额管理
kotlin
suspend fun ensureSufficientBalance(
capSolver: CapSolverService,
minBalance: Double = 1.0
) {
val balance = capSolver.checkBalance()
if (balance < minBalance) {
throw Exception("CapSolver余额不足: $${"%.2f".format(balance)}. 请充值。")
}
println("CapSolver余额: $${"%.2f".format(balance)}")
}3. 令牌缓存
kotlin
class TokenCache(private val ttlMs: Long = 90_000) {
private data class CachedToken(val token: String, val timestamp: Long)
private val cache = mutableMapOf<String, CachedToken>()
private fun getKey(domain: String, siteKey: String) = "$domain:$siteKey"
fun get(domain: String, siteKey: String): String? {
val key = getKey(domain, siteKey)
val cached = cache[key] ?: return null
if (System.currentTimeMillis() - cached.timestamp > ttlMs) {
cache.remove(key)
return null
}
return cached.token
}
fun set(domain: String, siteKey: String, token: String) {
val key = getKey(domain, siteKey)
cache[key] = CachedToken(token, System.currentTimeMillis())
}
}
// 使用缓存的示例
class CachedCapSolver(
private val capSolver: CapSolverService,
private val cache: TokenCache = TokenCache()
) {
suspend fun solveReCaptchaV2Cached(websiteUrl: String, websiteKey: String): String {
val domain = java.net.URL(websiteUrl).host
cache.get(domain, websiteKey)?.let {
println("使用缓存令牌")
return it
}
val token = capSolver.solveReCaptchaV2(websiteUrl, websiteKey)
cache.set(domain, websiteKey, token)
return token
}
}配置选项
| 设置 | 描述 | 默认值 |
|---|---|---|
CAPSOLVER_API_KEY |
你的CapSolver API密钥 | - |
OPENROUTER_API_KEY |
OpenRouter API密钥用于LLM功能 | - |
PROXY_ROTATION_URL |
代理轮换服务URL | - |
Browser4使用application.properties进行额外配置 |
结论
将CapSolver与Browser4集成创建了一个强大的高吞吐量网络数据提取解决方案。Browser4的协程安全架构和极致性能,结合CapSolver可靠的CAPTCHA解决能力,使大规模数据提取成为可能。
关键集成模式:
- 直接令牌注入:通过JavaScript评估注入解决的令牌
- 预认证:在提取前通过解决CAPTCHA建立会话
- 并行处理:利用协程进行并发CAPTCHA处理
- X-SQL集成:将CAPTCHA解决与Browser4强大的查询语言结合
无论您是构建价格监控系统、市场研究流程还是数据聚合平台,Browser4 + CapSolver组合都提供了生产环境所需的可靠性和可扩展性。
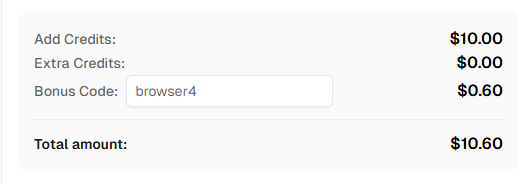
准备开始? 注册CapSolver 并使用优惠码 BROWSER4 获取首次充值6%的额外奖励!
常见问题
什么是Browser4?
Browser4是PulsarRPA开发的高性能协程安全浏览器自动化框架。它用Kotlin编写,专为AI驱动的数据提取设计,支持每台机器每天10万到20万次复杂页面访问。
CapSolver如何与Browser4集成?
CapSolver通过服务类与Browser4集成,该类通过CapSolver API解决CAPTCHA。然后使用Browser4的JavaScript评估功能(driver.evaluate())将解决的令牌注入页面。
CapSolver可以解决哪些类型的CAPTCHA?
CapSolver支持reCAPTCHA v2、reCAPTCHA v3、Cloudflare Turnstile、Cloudflare Challenge(5秒)、AWS WAF、GeeTest v3/v4等。
CapSolver的价格是多少?
CapSolver根据解决的CAPTCHA类型和数量提供具有竞争力的定价。访问capsolver.com查看当前定价。使用代码BROWSER4可获得6%的折扣。
Browser4使用哪种编程语言?
Browser4用Kotlin编写,运行在JVM(Java 17+)上。也可以从Java应用程序中使用。
Browser4能处理并行CAPTCHA解决吗?
可以!Browser4的协程安全设计支持高效的并行处理。结合CapSolver的API,您可以在不同的提取任务中同时解决多个CAPTCHA。
如何找到CAPTCHA站点密钥?
站点密钥通常在页面的HTML源代码中找到:
- reCAPTCHA:
.g-recaptcha元素的data-sitekey属性 - Turnstile:
.cf-turnstile元素的data-sitekey属性 - 或检查网络请求中的API调用



