







CapSolver Blogger
How to use CapSolver
-
合规声明: 本博客提供的信息仅供参考。CapSolver 致力于遵守所有适用的法律和法规。严禁以非法、欺诈或滥用活动使用 CapSolver 网络,任何此类行为将受到调查。我们的验证码解决方案在确保 100% 合规的同时,帮助解决公共数据爬取过程中的验证码难题。我们鼓励负责任地使用我们的服务。如需更多信息,请访问我们的服务条款和隐私政策。
更多

如何处理网页爬虫拦截:实用的方法
学习如何有效处理网络爬虫障碍。探索实用的方法、反爬虫检测的技术洞察以及可靠的数据采集方案。

Ethan Collins
03-Apr-2026
优化验证码识别接口响应时间以实现更快的自动化
学习如何优化CAPTCHA解决API的响应时间,以实现更快更可靠的自动化。本指南涵盖CAPTCHA复杂度、API性能和轮询策略等关键因素,并提供使用CapSolver实现10秒内解决时间的实用技巧。

Emma Foster
03-Apr-2026
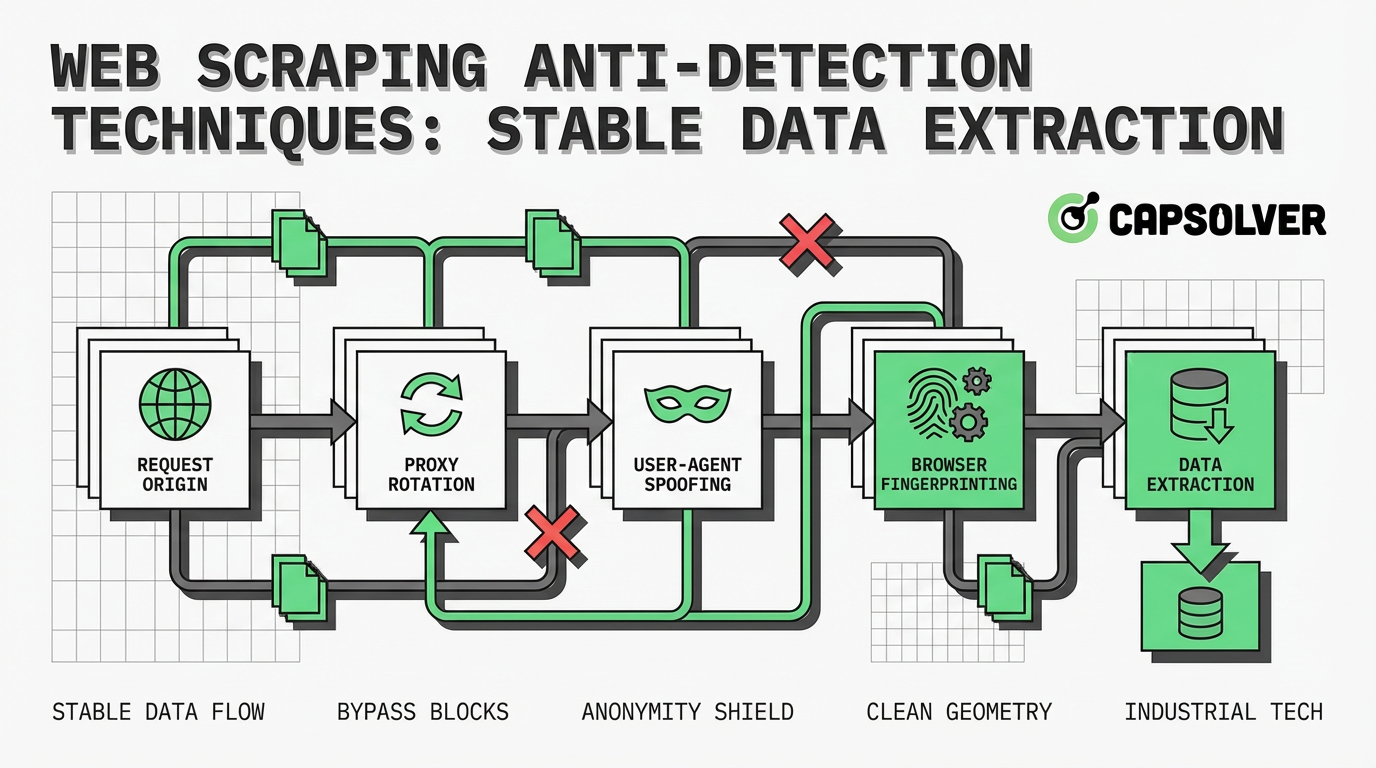
网络爬虫反检测技术:稳定的数据提取
掌握网络爬虫反检测技术,确保稳定的数据提取。学习如何通过IP轮换、头部优化、浏览器指纹识别以及验证码破解方法来避免被检测。

Anh Tuan
03-Apr-2026
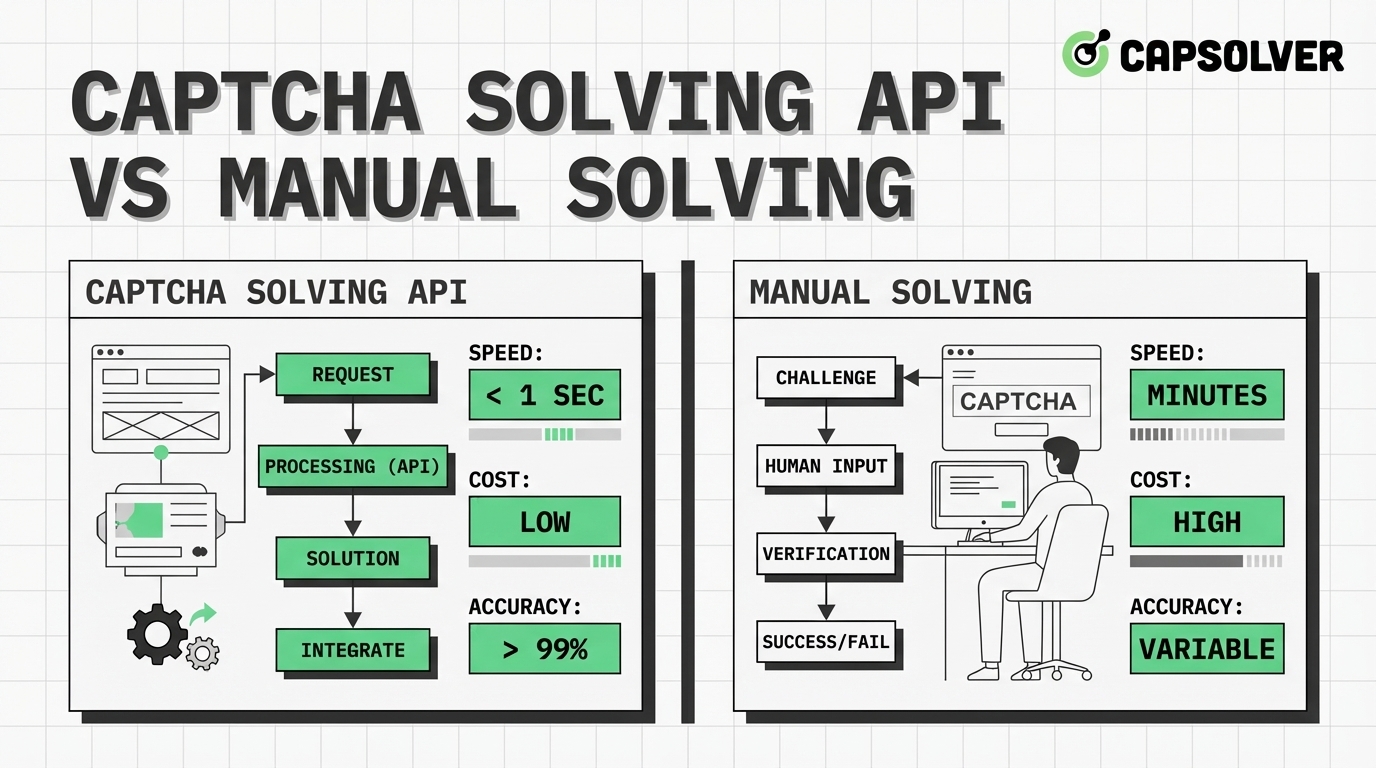
验证码识别API与人工解决:成本与效率(2026)
比较CAPTCHA求解API与手动解决。了解成本、速度和效率。发现为什么像CapSolver这样的AI驱动的API是自动化最佳选择。

Adélia Cruz
03-Apr-2026
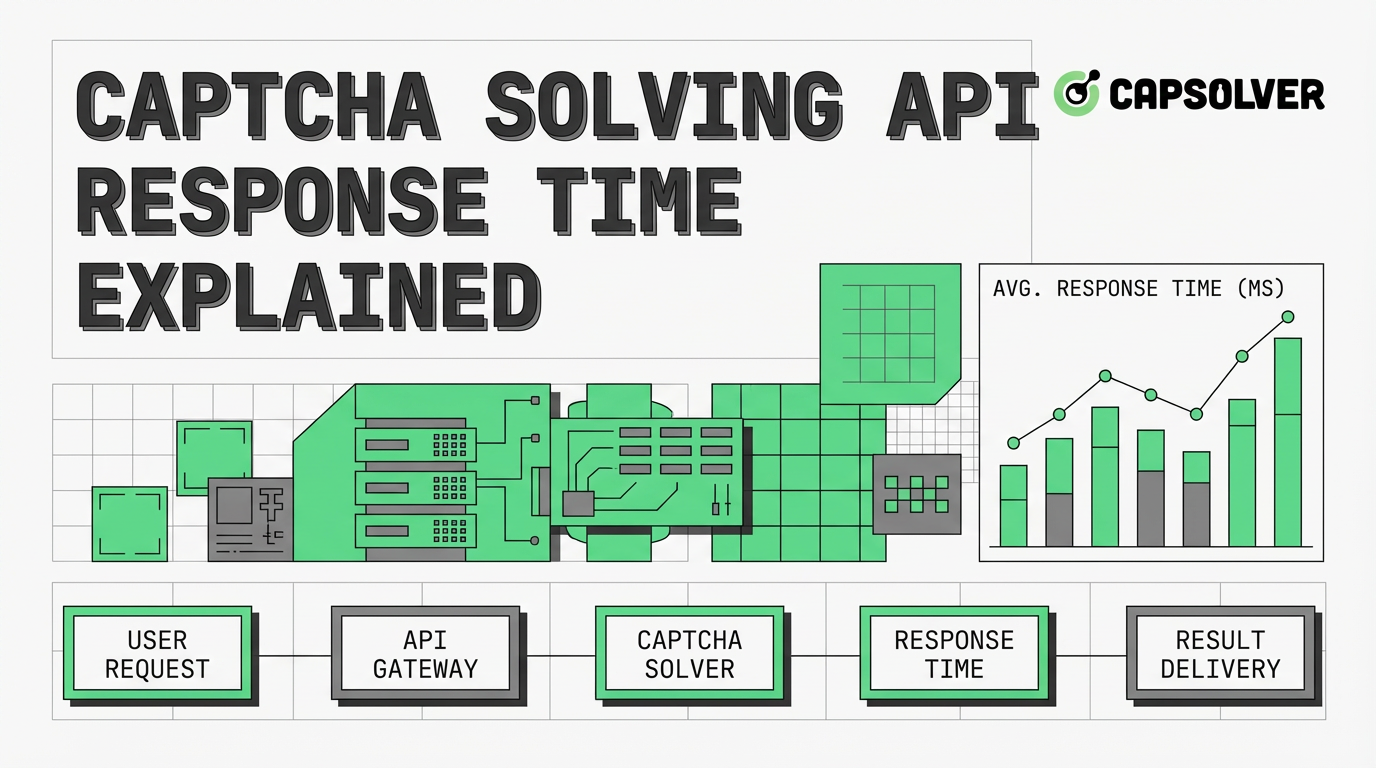
验证码解决API响应时间详解:速度与性能因素
了解CAPTCHA求解API的响应时间、其对自动化的影响以及影响速度的关键因素。学习如何优化性能,并利用如CapSolver之类的高效解决方案实现快速CAPTCHA解决。
Emma Foster
03-Apr-2026
如何选择验证码识别API?2026年选购指南及对比
学习如何为网络爬虫和AI代理选择验证码解决API。比较准确性、速度和成本,以找到最适合您需求的自动化解决方案。

Aloísio Vítor
02-Apr-2026