搜索API与知识供应链:人工智能数据基础设施指南

Ethan Collins
Pattern Recognition Specialist
总结
- 搜索API工具对于快速发现很有用,但它们无法满足生产AI系统的全部需求。
- 知识供应链包括发现、提取、验证、存储、编排和监控。
- SERP API有助于收集排名后的搜索结果,而网络爬虫API有助于收集页面级内容。
- 强大的网络数据基础设施依赖于数据的新鲜度、来源质量、可审计性和政策意识的采集。
- AI数据管道应将检索与解析、增强、治理和下游模型使用连接起来。
- 对于经过批准的自动化,当验证步骤中断采集流程时,团队可能还需要可靠性层。
简介
简短的答案很简单。搜索API是一个检索接口,而知识供应链是AI数据基础设施的操作模型。本文面向需要当前网络数据但又不失去质量或合规性控制的AI工程师、技术创始人、SEO团队和数据平台构建者。如果您在搜索接口、SERP API和更广泛的网络数据基础设施堆栈之间进行选择,正确的决定取决于风险、新鲜度和下游使用。核心价值是实用的清晰度。您将看到每个选项的适用场景、局限性以及如何设计更可靠的AI数据管道。
搜索API和知识供应链简介
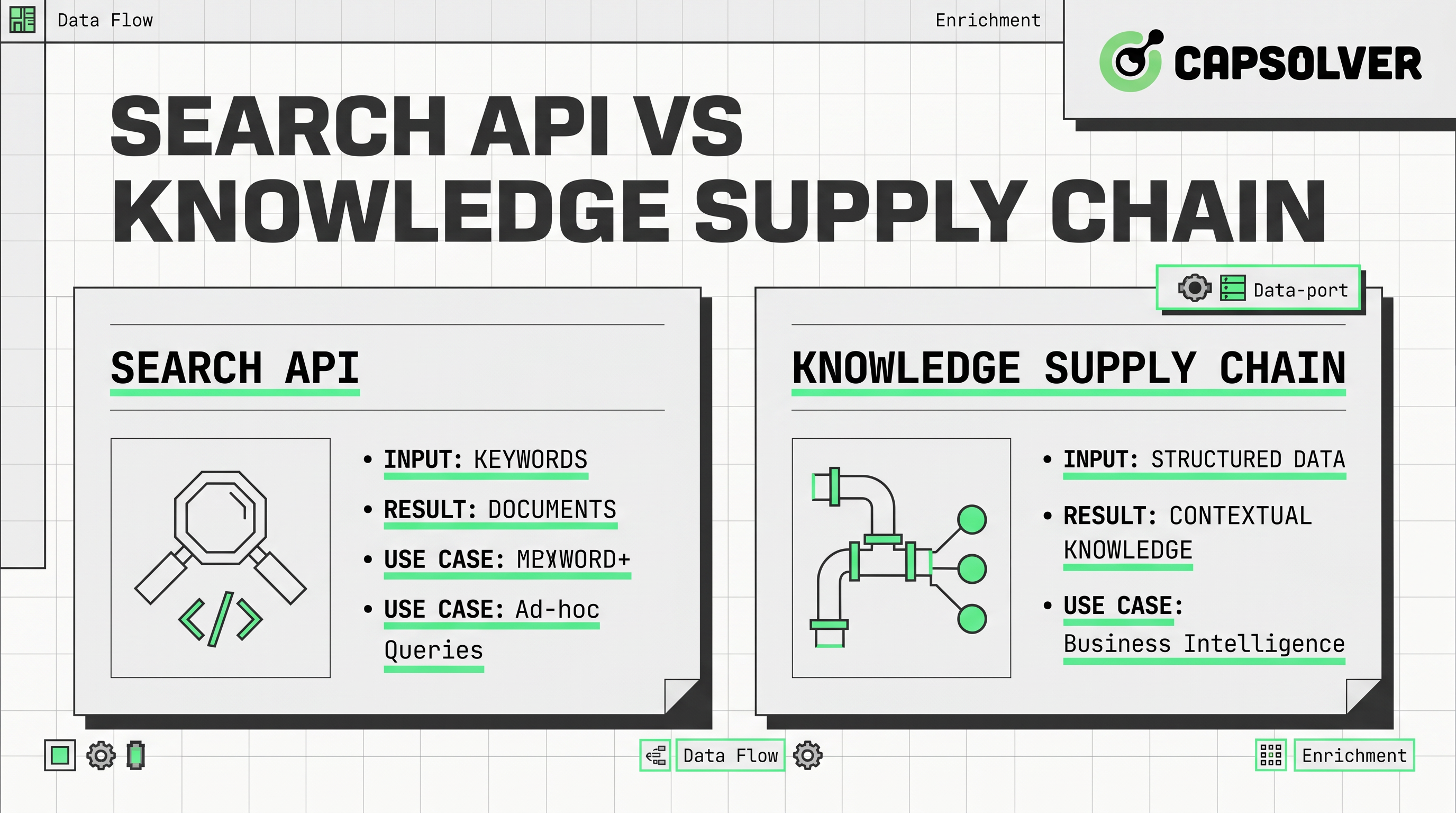
主要区别在于架构。搜索API通常接受查询并从索引中返回排名链接、摘要或总结结果。这使得这些工具在团队需要快速答案、轻量级增强或早期原型时具有吸引力。
知识供应链在设计上更广泛。它将AI的数据获取视为从源发现到收集、验证、存储、转换和交付的连续流程。该模型与代理系统、市场情报工具和必须支持可重复决策的检索层更为契合。
这种差异很重要,因为AI系统会根据接收到的内容进行操作。NIST人工智能风险管理框架指出,可信AI依赖于设计、开发、使用和评估实践,而不仅仅是模型输出。实际上,这意味着检索层是风险面的一部分。
另一个原因是政策。Google搜索中心指出,robots.txt主要用于管理爬虫流量,并不是隐藏内容的通用方法。这个提醒对任何构建网络数据基础设施的团队都很重要。合规性始于第一次请求之前。
搜索API在数据检索系统中的工作原理
最简单的描述是这样的。搜索API位于发现层。它将文本查询转换为可为聊天机器人、代码助手或研究助手提供输入的排名结果。
大多数搜索工具优化速度和开发人员的便利性。这通常意味着索引数据、缓存结果或预构建的相关性层。对于低风险任务来说,这已经足够。支持机器人、SEO创意工具或原型代理通常会从这种检索端点中受益,因为系统在需要深度证据之前需要方向。
SERP API更狭窄。它专注于搜索引擎结果页面和相关结果元素。这对于排名跟踪、查询监控和竞争性SEO研究很有用。然而,SERP API仍然反映的是搜索层,而不是完整的内容层。如果您需要实际的页面文本、结构化字段或历史比较,通常需要另一个步骤。
这就是人们将发现与知识混淆的地方。发现告诉您去哪里查找。知识需要获取、解析并检查实际存在的内容。搜索端点有助于第一部分。它不会完成整个AI数据管道。
人工智能架构中的知识供应链是什么
更准确的定义是操作性的。知识供应链是将开放网络中的数据转化为模型、代理和分析师可操作上下文的系统。
供应链的概念出现在最近的行业文章中,但许多文章止步于比喻。实用版本有六个层次。首先是通过搜索接口、SERP API、订阅源、站点地图或已知来源进行发现。其次是通过网络爬虫API、浏览器自动化或直接源连接进行提取。第三是规范化,将HTML、JSON、PDF和元数据转换为一致的记录。第四是验证,检查新鲜度、重复性、所有权和来源质量。第五是存储和索引以供检索。第六是编排,其中AI数据管道将结果发送到RAG系统、评估器或代理工具。
模型上下文协议在这里提供了一个有用的线索。MCP文档将其定义为连接AI应用程序与数据源、工具和工作流的开放标准。它不会取代搜索层,但它说明了为什么知识供应链必须包含超越检索的接口。
简而言之,搜索API是一个工具。知识供应链是一个系统。
搜索API和知识供应链之间的关键区别
最清晰的答案在于操作约束。搜索API通常优化为快速查找。知识供应链优化为在实际工作负载下的数据质量。
对比摘要
| 维度 | 搜索API | SERP API | 知识供应链 |
|---|---|---|---|
| 主要任务 | 基于查询的发现 | 搜索结果收集 | AI的端到端数据采集 |
| 典型输出 | 链接、摘要、总结 | 排名的SERP元素 | 完整内容、元数据、历史、验证 |
| 适合 | 原型、助手、轻量级研究 | SEO监控、结果跟踪 | 代理、情报系统、生产AI |
| 新鲜度控制 | 有限且依赖提供者 | 在搜索层中为中等 | 与直接采集结合时为高 |
| 证据深度 | 低到中等 | 低到中等 | 高 |
| 治理适配 | 有限 | 中等 | 强 |
| 在AI数据管道中的角色 | 第一步 | 带有SERP重点的第一步 | 多阶段操作系统 |
当前文章中的竞争差距是实践指导。许多帖子解释了为什么搜索工具快速,或者为什么知识供应链听起来有战略意义。更少的帖子解释了在一个真实的网络数据基础设施中,一个在哪里结束,另一个在哪里开始。这个边界决定了系统可靠性。
第二个区别是可审计性。当模型仅从摘要中回答时,团队通常无法检查源转换路径。当知识供应链存储页面内容、时间戳、提取日志和质量检查时,同样的答案更容易审查和改进。
第三个区别是失败成本。如果发现API返回过时的摘要,原型聊天应用可能仍然感觉可接受。如果同样的问题影响定价情报或政策监控,成本可能会高得多。
AI代理和数据基础设施的用例
最适合通过用例来理解。当系统需要快速定位时,搜索API表现良好。代理可以使用此检索层在更深入的检索开始前找到候选URL、最近提及或主题聚类。
当任务是面向搜索时,SERP API表现良好。SEO团队使用SERP API进行排名监控、付费和自然结果分析以及区域查询测试。输出是有用的,但仍然是一个证据层。
当任务是面向操作时,知识供应链更好。价格监控、潜在客户情报、政策跟踪、目录增强、采购研究和新闻验证都需要超越排名结果的内容。它们需要提取、时间戳、模式控制和可靠的AI数据管道。
这也是内部工具重要的地方。构建代理的团队可能会将AI代理框架、最佳数据提取工具和扩展数据收集用于LLM训练整合到一个堆栈中。当你将发现、提取和编排分开而不是将每个上游输入视为同一工具类别时,这些组件更容易评估。
对网络爬虫和数据工程工具的影响
最大的教训是,仅检索无法产生可信数据。网络爬虫API很重要,因为它将链接转换为可用记录。数据工程层很重要,因为原始页面内容不一致、嘈杂且经常重复。
这就是合规采集设计重要的原因。尊重robots指南、速率限制、访问政策和合同限制。 Google的爬虫指南明确指出,流量管理和爬行行为是网络正常运行环境的一部分。良好的网络数据基础设施应减少服务器负担,记录源规则并保留审计跟踪。
从工具角度来看,堆栈通常如下所示。发现API或SERP API识别目标。网络爬虫API或浏览器工具收集内容。AI数据管道解析、增强并存储记录。评估工具评分新鲜度和源信任度。然后代理框架或RAG系统使用结果。
操作可靠性也值得现实的说明。一些经过批准的自动化流程会遇到中断采集或监控的验证步骤。在这种情况下,团队有时会添加支持服务,如为什么网络自动化在验证码上不断失败或价格监控AI代理以保持授权工作流的稳定。如果这是您堆栈的一部分,CapSolver是相关的,因为它为这些场景提供了经过记录的API模式。
讨论CapSolver最安全的方式是紧贴其官方文档。下面的示例反映了CapSolver的API指南中记录的createTask请求格式,只能在批准的自动化环境中使用。
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey": "YOUR_API_KEY",
"appId": "APP_ID",
"task": {
"type": "ImageToTextTask",
"body": "BASE64 image"
}
}该示例不是知识供应链的核心。它是支持性的可靠性组件。主要观点保持不变。发现、采集和治理应一起设计。
领取您的CapSolver优惠码
立即提升您的自动化预算!
在充值CapSolver账户时使用优惠码 CAP26,每次充值可额外获得 5% 的奖金 —— 无限制。
现在在您的 CapSolver仪表板 中领取
结论
实际结论很简单。搜索API帮助系统找到信息,而知识供应链帮助系统信任、重用和操作它。如果您的工作负载是探索性的,这个检索层可能足够。如果您的工作负载影响产品、收入或合规性,您需要具有提取、验证和存储的更广泛的网络数据基础设施。
对于大多数团队,胜利的设计是混合型的。使用发现API或SERP API进行发现。使用网络爬虫API进行内容采集。然后将两者连接到具有明确源政策、监控和审查的AI数据管道中。这是AI数据采集最持久的路径。
如果您正在计划下一步,通过层级审计您的当前堆栈。询问发现在哪里结束,证据从哪里开始,治理记录在哪里。这个练习通常会揭示您是否需要更快的接口、更深入的管道,或者两者都需要。
常见问题
搜索API和SERP API是一样的吗?
不。搜索API是一个广泛的检索接口,而SERP API专注于搜索引擎结果页面和相关结果元素。
这种检索接口在AI应用中何时足够?
它通常足以原型、内部助手、低风险研究任务和管道中的早期发现步骤。
什么使知识供应链更适合生产AI?
知识供应链增加了提取、规范化、验证、存储和编排。这些层提高了新鲜度、可审计性和重用性。
网络爬虫API在这个模型中处于什么位置?
网络爬虫API位于发现之后。它将URL和源页面转换为AI数据管道可以处理的结构化内容。
为什么在关于AI数据基础设施的文章中提到CapSolver?
因为一些经过批准的自动化工作流在发现后会遇到验证中断。在这种狭窄的背景下,CapSolver可以作为更广泛、政策意识系统中的一个组件,支持操作连续性。