基于大模型的人工智能验证码:为什么它更适合企业场景

Ethan Collins
Pattern Recognition Specialist

AI视觉识别能力正在重新定义CAPTCHA技术。许多人仍将CAPTCHA视为一个简单的"组件",但在实际的自动化处理环境中,它已演变为AI视觉技术与验证机制之间的持续升级。
一、CAPTCHA演进:从OCR到AI视觉识别
1. 第一代:OCR时代(2000-2010)
技术背景
早期互联网面临的核心问题包括垃圾信息和自动化程序滥用。reCAPTCHA作为开创性系统出现,其设计哲学简单:利用人类在视觉识别中的优势,创建机器难以克服的障碍。
典型实现
- 扭曲的英文字符字符串(4-6位数字)
- 添加干扰线、噪声、背景纹理
- 色彩对比干扰
自动化识别技术演进
| 阶段 | 技术方法 | 识别效率 |
|---|---|---|
| 2003-2005 | 传统OCR(Tesseract)+ 规则修正 | 30-50% |
| 2005-2008 | 图像预处理(去噪、二值化、分割)+ SVM | 60-80% |
| 2008-2010 | 卷积神经网络(LeNet-5改进版) | 90%+ |
里程碑事件
2008年发表在Science上的研究显示文本型CAPTCHA的机器识别率迅速提升。这直接催生了第二代CAPTCHA的诞生。
核心洞察:固定字符集 + 有限的扭曲规则 = 可收集的数据集 = 容易被自动系统识别。
2. 第二代:行为+图像挑战(2010-2020)
范式转变
CAPTCHA设计师意识到单纯增加识别难度也会负面影响真实用户体验。有必要引入"人类独有能力"——语义理解和行为模式。
三大商业系统的分析
reCAPTCHA(谷歌)
- v2(2014):"我不是机器人"复选框 + 不可见的风险分析
- 核心技术:风险分析引擎,基于100+信号(Cookie、设备历史、细微的鼠标移动、页面交互时间)
- 图像挑战:从街景中提取的真实场景(交通灯、人行横道、公交车),通过众包标注同时训练自动驾驶模型
GCaptcha(Intuition Machines)
- 差异化定位:隐私优先,声称不追踪用户个人数据
- 技术特点:分布式验证架构,挑战图片来自客户端自己的数据集,形成"验证即标注"的商业模式
- 验证设计:动态难度调整,根据自动化处理压力实时切换挑战类型
GeeTest
- 核心创新:滑块验证 + 拼图还原,将"识别"转化为"操作"
- 行为数据收集:轨迹坐标序列(通常50-200个点)、速度曲线、加速度变化、触控事件(移动端)
- 风控维度:不仅判断通过/失败,还输出"人类置信度评分"用于业务级决策
自动化处理技术发展
| 自动化类型 | 技术方法 | 验证器的响应 |
|---|---|---|
| 自动图像识别 | 目标检测(YOLO/Faster R-CNN)+ 语义分割 | 动态图像生成,对抗样本 |
| 滑块轨迹模拟 | 物理引擎模拟(贝塞尔曲线,噪声注入) | 时间序列分析,生物识别 |
| 众包平台处理 | 众包平台(成本0.5-2美元/千次) | 速率限制,相关性分析,声誉系统 |
| 浏览器自动化 | Selenium, Puppeteer, Playwright | 浏览器指纹检测,自动化特征识别 |
核心挑战
第二代系统的根本假设是自动化程序无法大规模模拟人类行为。然而随着深度学习的发展,这一假设正受到挑战:
- 轨迹生成:GAN可以学习真实用户鼠标移动的动态特征
- 图像理解:视觉变换器(ViT)在ImageNet上的突破使机器视觉接近人类水平。
- 浏览器指纹:自动化框架指纹的随机化技术日益复杂
核心洞察:任何固定挑战,无论设计多么巧妙,本质上都是"有标准答案的考试"。只要有标准答案,就能被收集、学习并最终被自动化程序处理。
二、AI视觉识别技术的发展与挑战
1. 自动识别工业化系统
现代CAPTCHA自动化识别已形成高度专业化的技术栈完整工业体系:
数据层
- 采集系统:分布式爬虫集群,24/7从目标站点抓取挑战
- 标注工厂:低成本数据标注团队,或半自动化标注工具(SAM辅助)
- 数据增强:旋转、裁剪、色彩变换、对抗噪声以扩展训练集多样性
模型层
| 任务类型 | 模型架构 | 开源实现参考 |
|---|---|---|
| 字符识别 | CRNN + CTC | PaddleOCR, EasyOCR |
| 目标检测 | YOLOv8, RT-DETR | Ultralytics |
| 图像分类 | ViT, ConvNeXt | Hugging Face Transformers |
| 滑块轨迹 | Seq2Seq, Diffusion Model | 社区开源解决方案 |
| 多模态理解 | CLIP, LLaVA | OpenAI CLIP, 阿里巴巴Qwen-VL |
工程层
- 推理优化:TensorRT, ONNX Runtime, OpenVINO实现毫秒级响应
- 服务架构:Kubernetes编排,自动扩缩容,支持高并发请求
- 自动化绕过:浏览器指纹随机化,IP代理池,行为节奏模拟
OpenClaw现象分析
近期流行的OpenClaw项目代表了"AI视觉识别工具民主化"的趋势:
- 低门槛:预训练模型 + 配置文件可针对特定目标
- 模块化:数据采集、模型训练、推理服务和结果提交的解耦
- 社区驱动:共享识别样本、模型权重和迭代技术方案
对企业的冲击:过去需要专业安全团队实现的自动化识别,现在普通开发者可以快速采用。这显著提高了CAPTCHA验证机制的技术要求。
2. 验证机制:从"静态挑战"到"动态风险控制"
范式转变:行为建模的崛起
企业级CAPTCHA系统的核心转变是从"验证答案正确性"到"评估行为真实性"。这类似于金融风控从"规则引擎"到"机器学习评分卡"的演变。
多维行为指纹系统
| 数据采集维度 | 技术指标 | AI分析方法 |
|---|---|---|
| 鼠标动力学 | 轨迹点密度、速度曲线、加速度分布、角度变化 | LSTM/Transformer时间序列建模,与真实用户基线分布比较 |
| 键盘交互 | 键按下间隔(Keydown-Keyup)、键组合模式、修正行为(退格频率) | 节奏分析,检测自动化工具的均匀间隔特征 |
| 触控事件(移动端) | 压力值、接触面积、滑动惯性、多点触控模式 | 生物识别,区分人手与机械臂/模拟器 |
| 视觉注意力 | 眼动追踪(如允许)、页面滚动模式、元素聚焦时间 | 注意力热力图分析,检测非人类浏览模式 |
| 认知反应时间 | 从挑战呈现到首次交互的延迟、决策时间分布 | 统计检验,自动化工具通常过快或过慢 |
| 环境上下文 | 设备姿态(陀螺仪)、电池状态、网络延迟波动 | 异常检测,识别虚拟机/模拟器/云手机 |
大模型的关键作用
传统规则引擎难以处理高维、非线性行为序列。大模型(尤其是Transformer架构)带来突破:
- 表征学习:将原始行为序列编码为低维嵌入以捕捉深层模式
- 迁移学习:使用大量无监督行为数据预训练,微调小样本适应新场景
- 多模态融合:统一处理图像、时间序列和分类特征实现端到端优化
三、为何大模型CAPTCHA视觉识别更适合企业场景
数据飞轮:在数据主导的时代,企业独特的竞争优势
自动化识别器 vs 验证器数据对比
| 数据类型 | 可用于自动化识别器 | 实际由企业验证器拥有 | 战略价值 |
|---|---|---|---|
| 成功识别案例 | ✅ 有限样本(需要昂贵收集) | ✅ 大量失败案例(自动化识别日志) | 训练"自动化模式识别"模型 |
| 真实用户行为 | ❌ 难以大规模获取 | ✅ 全业务流量 | 构建"人类行为基线" |
| 自动化工具指纹 | ❌ 被动发现 | ✅ 主动检测 + 蜂巢收集 | 识别自动化框架特征 |
| 时间序列相关数据 | ❌ 单点视角 | ✅ 跨业务线的全局视角 | 相关性分析,识别有组织的自动化行为 |
持续学习循环
[生产流量] → [行为数据采集] → [特征工程] → [模型推理] → [风险评分]
↑ ↓
[模型更新] ← [性能评估] ← [标注反馈] ← [业务决策]
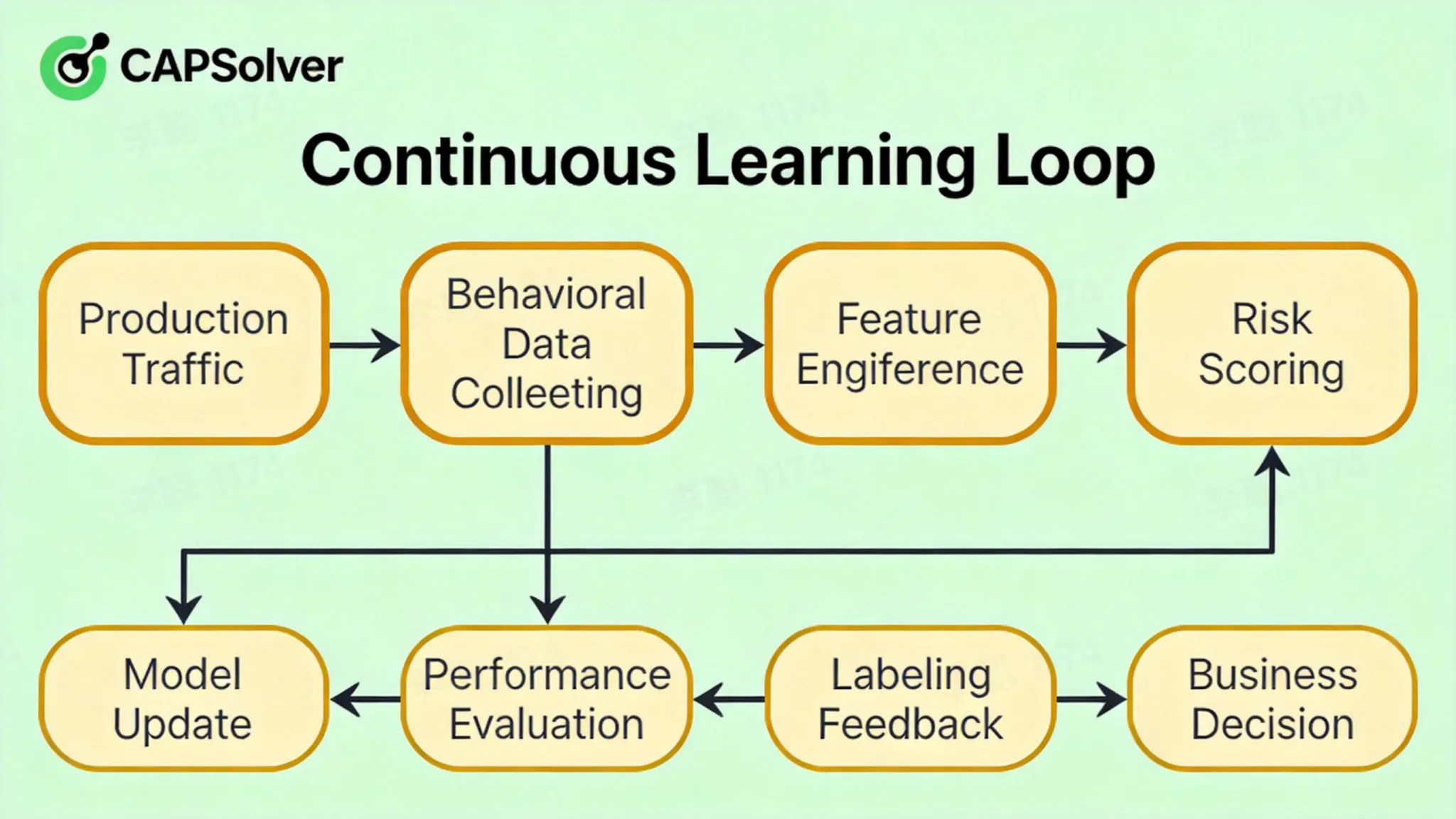
- 在线学习:实时用新数据微调模型参数,无需完全重新训练
- 主动学习:智能选择高价值样本进行人工标注,优化标注ROI
- 对抗训练:通过自动化识别样本作为负例增强鲁棒性
与业务风控的深度整合
| 整合场景 | 技术实现 | 业务价值 |
|---|---|---|
| 登录防护 | CAPTCHA评分 + 设备指纹 + IP信誉 → 统一风险评分 | 精准拦截自动化登录,减少误报 |
| 注册反欺诈 | 异常验证行为 → 触发手机/邮件二次验证 | 识别批量注册,保护用户池质量 |
| 营销活动 | 限时抢购场景,实时人机识别 → 动态限速 | 防止自动化抢购,保护真实用户权益 |
| 支付安全 | 高风险操作前强制验证 + 行为审查 | 阻断自动化欺诈交易,减少资产损失 |
了解更多现代自动化的见解,请参阅我们的指南为什么网络自动化在CAPTCHA上持续失败
四、私有化部署演进路径
从实验到生产的典型旅程
第一阶段:概念验证(PoC,1-2个月)
- 场景:安全团队评估现有CAPTCHA的漏洞,或业务投诉验证体验差
- 行动:使用OpenClaw等工具模拟自动化识别,量化识别成本和成功率
- 输出:自动化识别可行性报告,初步ROI估算
第二阶段:试点部署(Pilot,3-6个月)
- 技术栈:开源模型(YOLO + ResNet) + 自建标注团队
- 核心挑战:
- 模型泛化能力差,新自动化类型出现时快速失效
- 推理延迟高,影响用户体验
- 缺乏行为分析维度,仅依赖图像识别
- 关键决策:是否投入资源构建MLOps平台或购买商业解决方案
第三阶段:规模化生产(Production,6-12个月)
- 架构升级:
- 推理层:Triton Inference Server + TensorRT,GPU利用率优化
- 数据层:实时特征存储(Redis/Flink) + 离线数据湖(Iceberg/Delta Lake)
- 训练层:Kubeflow/MLflow用于管理实验和模型版本
- 组织发展:建立专门的AI安全团队(算法工程师 + 后端工程师 + 安全分析师)
第四阶段:平台运营(Platform,1-2年)
- 能力输出:CAPTCHA服务作为内部安全中间件,支持多个业务线
- 生态整合:与威胁情报、SOC(安全运营中心)、SIEM系统联动
- 持续验证:建立红队/蓝队验证机制,定期模拟APT级自动化识别演练
五、企业级与非企业级:全面对比
| 对比维度 | 非企业级解决方案(OpenClaw / 传统OCR) | 企业级CAPTCHA AI视觉识别 |
|---|---|---|
| 部署复杂度 | ✅ 简单,Docker一键启动 | ❌ 复杂,需MLOps平台支持 |
| 初始成本 | ✅ 低,单块GPU足够 | ❌ 高,需集群 + 标注团队 |
| 模型更新 | ❌ 固定权重,易被自动化识别针对 | ✅ 在线学习,持续进化 |
| 行为分析 | ❌ 纯图像识别,无行为维度 | ✅ 多模态融合,精准人机区分 |
| 风控联动 | ❌ 孤立系统,无上下文感知 | ✅ 深度集成WAF、设备指纹 |
| 高可用性 | ❌ 单一部署点,无SLA保证 | ✅ 多活架构,弹性扩展 |
| 安全合规支持 | ❌ 审计日志薄弱,隐私合规 | ✅ GDPR/CCPA适配,完整审计 |
| 适用场景 | 小中型企业,内部测试,短期项目 | 大规模生产,金融,电商,政务 |
VI. 未来形态:AI风险控制基础设施
技术演进趋势
| 演进方向 | 当前状态 | 未来3-5年 |
|---|---|---|
| 验证方式 | 被动挑战(用户需执行操作) | 隐形验证码,基于背景行为分析 |
| 模型架构 | 专用小模型(CNN/LSTM) | 多模态大模型(GPT-4V类架构微调) |
| 挑战生成 | 固定题库+有限变化 | 生成式AI实时合成(每人一个问题,每个问题不同) |
| 决策逻辑 | 二元分类(人/机器) | 连续风险评分+动态策略编排 |
| 验证模式 | 单点验证 | 联邦学习协作,行业级自动化识别智能共享 |
生成式验证码的想象空间
使用扩散模型或GANs实时生成验证内容:
- 优势: 无需预存题库,自动识别器无法提前收集训练数据
- 挑战: 生成质量控制(避免人类难以识别的样本),推理成本优化
- 前沿研究: 行业传闻称类似reCAPTCHA v4的系统可能采用生成技术。
VII. 对技术决策者的建议
| 时间维度 | 行动项 | 关键里程碑 | 目标 |
|---|---|---|---|
| 短期(1-3个月) | 自动识别表面评估 | 完成OpenClaw模拟自动识别,量化当前CAPTCHA MTBF | 建立风险意识,确保资源投入 |
| 监控系统建设 | 部署自动识别检测规则,识别自动流量特征 | 从"被动响应"到"可见识别" | |
| 中期(3-12个月) | 数据基础设施 | 构建行为数据采集管道,积累1000万+标注样本 | 拥有训练生产级模型的数据基础 |
| 模型迭代与上线 | 首次深度学习模型A/B测试,验证识别防御效果 | 验证技术可行性,建立团队信心 | |
| 长期(1-2年) | 平台化 | CAPTCHA服务SLA达到99.99%,支持10万QPS | 成为公司核心安全基础设施 |
| AI安全策略 | 整合到统一风险控制平台,关联反欺诈 | 形成多维AI验证系统 |
VIII. CapSolver的AI视觉识别能力
作为专注于提供高效稳定AI视觉识别服务的技术提供商,CapSolver在图像CAPTCHA识别和定制求解器训练方面具有显著优势:
- 支持多种图像类CAPTCHA: CapSolver对主流和复杂图像CAPTCHA的识别算法进行了深度优化,支持包括但不限于图像分类和目标检测等类型。
- 快速适应新CAPTCHA: 基于先进的大视觉模型技术,CapSolver可实现少样本学习和快速微调,帮助企业快速应对市场上出现的新CAPTCHA挑战。
- 企业级API和高并发处理能力: CapSolver提供稳定、高可用的企业级API接口,支持高并发请求,确保毫秒级响应,满足企业大规模自动化数据采集需求。
- 定制求解器训练: 针对企业特定的视觉识别需求,CapSolver提供定制化模型训练服务,帮助企业构建专属的高精度CAPTCHA识别解决方案。
IX. 进一步阅读与行业参考
| 资源类型 | 推荐内容 | 价值 |
|---|---|---|
| 开源项目 | OpenClaw & CapSolver | 理解自动化识别技术栈 |
| 行业报告 | Gartner 欺诈检测市场指南 | 商业解决方案选择参考 |
X. 结论
随着AI技术的快速发展,CAPTCHA识别已不再是一个简单的技术挑战,而是企业获取公共数据和确保数字时代业务连续性的关键能力。AI视觉大模型凭借其卓越的复杂场景理解能力、强大的泛化能力和高效的模型扩展性,为企业级自动化识别提供了前所未有的解决方案。CapSolver凭借在AI视觉识别领域的深厚积累和企业级服务能力,致力于成为您的可信赖伙伴,帮助企业高效合规地应对各种CAPTCHA挑战,专注于创造核心业务价值。
XI. 常见问题(FAQ)
Q1: 大型视觉模型(LVMs)在CAPTCHA识别中与传统CNN有何不同?
A1: 与依赖局部特征提取的传统CNN不同,LVMs采用如Vision Transformers(ViT)等架构来捕捉全局上下文和语义含义。这使它们能够以更高的准确率理解和泛化到新的、未见过的CAPTCHA样式,且需要极少的额外训练。
Q2: 在基于AI的CAPTCHA求解器中,"少样本学习"是什么意思?
A2: 少样本学习指的是预训练AI模型使用极少量的标记示例适应新任务(如新类型的CAPTCHA)。这是大模型的核心优势,使企业能快速应对不断演变的验证机制。
Q3: CapSolver支持哪些类型的图像CAPTCHA?
A3: CapSolver对主流和复杂图像CAPTCHA的识别算法进行了深度优化,支持包括但不限于图像分类和目标检测等类型。
查看图像解决方案:Imagetotext & VisionEngine
Q4: CapSolver如何确保识别的准确性和稳定性?
A4: CapSolver基于先进的大视觉模型技术,通过持续学习循环和在线学习机制不断优化模型性能。此外,我们提供企业级API和高并发架构,确保毫秒级响应和99.9%的可用性。
Q5: CapSolver的服务是否支持私有化部署?
A5: CapSolver提供灵活的部署选项,包括云服务和私有化部署,以满足不同企业的安全和合规需求。私有化部署方案可根据企业的具体架构和资源进行定制。


