Cách giải thách thức Cloudflare trong Crawl4AI với tích hợp CapSolver

Anh Tuan
Data Science Expert
Giới thiệu
Challenge Cloudflare là một cơ chế chống bot tinh vi thường bao gồm các kiểm tra phức tạp, bao gồm cả việc phân tích vân tay trình duyệt và xác minh User-Agent, để phân biệt người dùng hợp lệ với lưu lượng tự động. Các thử thách này có thể làm gián đoạn đáng kể các nỗ lực quét dữ liệu web và trích xuất dữ liệu, khiến các công cụ quét gặp khó khăn trong việc truy cập các trang web mục tiêu. Việc vượt qua Challenge Cloudflare đòi hỏi một giải pháp mạnh mẽ và linh hoạt có thể mô phỏng hành vi của trình duyệt thực tế.
Bài viết này cung cấp hướng dẫn toàn diện về cách tích hợp Crawl4AI, một công cụ quét web tiên tiến, với CapSolver, một dịch vụ giải pháp CAPTCHA và chống bot hàng đầu, để vượt qua các biện pháp bảo vệ Challenge Cloudflare một cách hiệu quả. Chúng tôi sẽ tập trung vào phương pháp tích hợp dựa trên API, cung cấp các ví dụ mã chi tiết và giải thích để đảm bảo các nhiệm vụ tự động hóa web của bạn có thể tiếp tục mà không bị gián đoạn.
Hiểu về Challenge Cloudflare và các thách thức trong trích xuất dữ liệu web
Challenge Cloudflare được thiết kế để mạnh mẽ hơn so với các CAPTCHA thông thường, thường sử dụng kết hợp nhiều kỹ thuật để xác định và chặn bot:
- Phân tích vân tay trình duyệt: Phân tích các đặc điểm độc đáo của trình duyệt để phát hiện tự động hóa.
- Xác minh User-Agent: Yêu cầu các chuỗi User-Agent cụ thể và nhất quán phù hợp với phiên bản trình duyệt thực tế.
- Thực thi JavaScript: Thực thi JavaScript phức tạp ở nền để xác minh khả năng trình duyệt và tương tác giống như người dùng.
- Quản lý cookie: Thiết lập và xác minh các cookie cụ thể như một phần của quy trình giải quyết thử thách.
CapSolver cung cấp loại nhiệm vụ AntiCloudflareTask, được thiết kế đặc biệt để giải quyết các thử thách phức tạp này bằng cách cung cấp các token, cookie cần thiết và thậm chí đề xuất các User-Agent cụ thể. Khi tích hợp với Crawl4AI, điều này cho phép các công cụ quét của bạn vượt qua các trang web được bảo vệ bởi Cloudflare một cách thành công.
Phương pháp tích hợp: Tích hợp API của CapSolver với Crawl4AI
Phương pháp tích hợp API là rất quan trọng để xử lý Challenge Cloudflare, vì nó cho phép kiểm soát chính xác các cấu hình trình duyệt và chèn các token và cookie cần thiết. Phương pháp này bao gồm việc sử dụng CapSolver để lấy giải pháp thử thách (token, cookie và User-Agent) và sau đó cấu hình Crawl4AI để sử dụng các tham số này.
Cách hoạt động:
- Lấy giải pháp Challenge Cloudflare: Trước khi khởi chạy công cụ quét, gọi API của CapSolver bằng SDK của họ, chỉ định loại nhiệm vụ
AntiCloudflareTask. Bạn cần cung cấpwebsiteURL, mộtproxy(nếu có), vàuserAgentphù hợp với phiên bản trình duyệt mà CapSolver sử dụng để giải quyết. - Cấu hình trình duyệt Crawl4AI: Sử dụng giải pháp trả về bởi CapSolver (bao gồm
token,cookiesvàuserAgentđược đề xuất) để cấu hìnhBrowserConfigcủa Crawl4AI. Điều này đảm bảo rằng phiên bản trình duyệt của Crawl4AI mô phỏng môi trường đã được sử dụng để giải quyết thử thách. - Khởi chạy công cụ quét: Crawl4AI sau đó chạy với trình duyệt được cấu hình đặc biệt, bao gồm các cookie và User-Agent cần thiết, cho phép nó vượt qua Challenge Cloudflare.
- Tiếp tục hoạt động: Sau khi vượt qua thành công Challenge Cloudflare, Crawl4AI có thể tiếp tục thực hiện các nhiệm vụ trích xuất dữ liệu trên trang web mục tiêu.
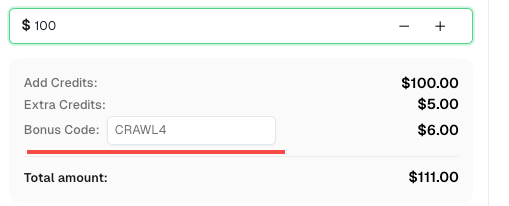
💡 Ưu đãi độc quyền cho người dùng tích hợp Crawl4AI:
Để kỷ niệm sự tích hợp này, chúng tôi đang cung cấp mã ưu đãi 6% —CRAWL4cho tất cả người dùng CapSolver đăng ký thông qua hướng dẫn này.
Chỉ cần nhập mã trong quá trình nạp tiền trên Bảng điều khiển để nhận thêm 6% tín dụng ngay lập tức.
Ví dụ mã: Tích hợp API để giải quyết Challenge Cloudflare
Mã Python sau đây minh họa cách tích hợp API của CapSolver với Crawl4AI để giải quyết Challenge Cloudflare. Ví dụ này nhắm đến một trang bài viết tin tức được bảo vệ bởi Cloudflare.
python
import asyncio
import time
import capsolver
from crawl4ai import *
# TODO: thiết lập cấu hình của bạn
api_key = "CAP-XXX" # khóa API của bạn từ CapSolver
site_url = "https://www.tempo.co/hukum/polisi-diduga-salah-tangkap-pelajar-di-magelang-yang-dituduh-perusuh-demo-2070572" # URL trang web mục tiêu
captcha_type = "AntiCloudflareTask" # loại CAPTCHA mục tiêu
api_proxy = "http://127.0.0.1:13120"
capsolver.api_key = api_key
user_data_dir = "./crawl4ai_/browser-profile/Default1493"
# hoặc
cdp_url = "ws://localhost:xxxx"
async def main():
print("bắt đầu giải token")
start_time = time.time()
# lấy token Cloudflare bằng SDK CapSolver
solution = capsolver.solve({
"type": captcha_type,
"websiteURL": site_url,
"proxy": api_proxy,
"userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"
})
token_time = time.time()
print(f"giải token: {token_time - start_time:.2f} s")
# thiết lập cookie
cookies = solution.get("cookies", [])
if isinstance(cookies, dict):
cookies_array = []
for name, value in cookies.items():
cookies_array.append({
"name": name,
"value": value,
"url": site_url,
})
cookies = cookies_array
elif not isinstance(cookies, list):
cookies = []
token = solution["token"]
print("token thử thách:", token)
browser_config = BrowserConfig(
verbose=True,
headless=False,
use_persistent_context=True,
user_data_dir=user_data_dir,
# cdp_url=cdp_url,
user_agent=solution["userAgent"],
cookies=cookies,
)
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url=site_url,
cache_mode=CacheMode.BYPASS,
session_id="session_captcha_test"
)
print(result.markdown[:500])
if __name__ == "__main__":
asyncio.run(main())Phân tích mã:
- Gọi SDK CapSolver: Phương thức
capsolver.solvelà trung tâm ở đây, sử dụng loại nhiệm vụAntiCloudflareTask. Nó yêu cầuwebsiteURL,proxyvàuserAgentcụ thể. CapSolver xử lý thử thách và trả về một đối tượngsolutionchứatoken,cookiesvàuserAgentđã được sử dụng để giải thử thách. - Cấu hình trình duyệt:
BrowserConfigcủa Crawl4AI được thiết lập cẩn thận bằng thông tin từ giải pháp của CapSolver. Điều này bao gồmuser_agentvàcookiesđể đảm bảo phiên bản trình duyệt của Crawl4AI hoàn toàn phù hợp với điều kiện mà thử thách Cloudflare đã được giải.user_data_dircũng được chỉ định để duy trì một hồ sơ trình duyệt nhất quán. - Thực thi công cụ quét: Crawl4AI sau đó thực hiện phương thức
arunvớibrowser_configđược cấu hình cẩn thận, cho phép nó truy cập URL mục tiêu mà không kích hoạt lại thử thách Cloudflare.
Kết luận
Việc vượt qua thử thách Cloudflare trong trích xuất dữ liệu web là một nhiệm vụ phức tạp đòi hỏi một cách tiếp cận tinh vi. Việc tích hợp Crawl4AI với CapSolver mang lại một giải pháp mạnh mẽ và hiệu quả, giúp các nhà phát triển dễ dàng vượt qua các biện pháp bảo vệ bot tiên tiến. Bằng cách sử dụng nhiệm vụ chuyên dụng AntiCloudflareTask của CapSolver để lấy token, cookie và User-Agent cần thiết, sau đó cấu hình trình duyệt của Crawl4AI để phù hợp với các tham số này, bạn có thể đảm bảo tính ổn định và thành công trong các hoạt động trích xuất dữ liệu web của mình.
Sự kết hợp này giữa khả năng quét tiên tiến của Crawl4AI và công nghệ chống bot mạnh mẽ của CapSolver đánh dấu một bước tiến quan trọng trong việc trích xuất dữ liệu web tự động, cho phép bạn tập trung vào việc thu thập dữ liệu quý giá mà không bị cản trở bởi các biện pháp bảo vệ của Cloudflare.
Câu hỏi thường gặp (FAQ)
Câu hỏi 1: Cloudflare Challenge là gì và tại sao nó được sử dụng?
Trả lời 1: Cloudflare Challenge là một cơ chế chống bot tiên tiến được thiết kế để xác minh xem người truy cập là người thật hay một đoạn mã tự động. Nó sử dụng nhiều kỹ thuật như phân tích vân tay trình duyệt, xác minh User-Agent và thực thi JavaScript để bảo vệ các trang web khỏi bot độc hại, cuộc tấn công DDoS và các mối đe dọa khác.
Câu hỏi 2: Tại sao Cloudflare Challenge đặc biệt khó khăn với các công cụ quét web?
Trả lời 2: Cloudflare Challenge khó khăn với các công cụ quét vì nó vượt xa các CAPTCHA đơn giản. Nó phân tích đặc điểm trình duyệt, yêu cầu chuỗi User-Agent nhất quán, thực thi JavaScript phức tạp và quản lý cookie cụ thể. Việc phát hiện tinh vi này khiến các công cụ tự động gặp khó khăn trong việc mô phỏng tương tác của người dùng thật mà không có các giải pháp chuyên dụng.
Câu hỏi 3: CapSolver giúp vượt qua Cloudflare Challenge như thế nào?
Trả lời 3: CapSolver cung cấp một loại nhiệm vụ chuyên dụng, AntiCloudflareTask, để giải quyết các thử thách Cloudflare. Nó xử lý thử thách và trả về một giải pháp bao gồm token, cookie cần thiết và User-Agent được đề xuất. Thông tin này sau đó được sử dụng để cấu hình Crawl4AI để vượt qua thử thách một cách thành công.
Câu hỏi 4: Những yếu tố chính khi tích hợp Crawl4AI và CapSolver để vượt qua Cloudflare Challenge là gì?
Trả lời 4: Các yếu tố quan trọng bao gồm đảm bảo rằng userAgent được sử dụng trong cấu hình Crawl4AI phù hợp với userAgent do CapSolver cung cấp, xử lý và chèn chính xác cookies trả về bởi CapSolver, và cung cấp proxy nếu hoạt động quét của bạn yêu cầu. Các bước này đảm bảo rằng môi trường trình duyệt của Crawl4AI phản ánh chính xác các điều kiện mà thử thách đã được giải quyết.
Tài liệu tham khảo
Xem thêm
CloudflareMar 26, 2026
Khắc phục Lỗi 1005 Cloudflare: Hướng dẫn Gỡ mã web và Giải pháp
Học cách khắc phục lỗi Cloudflare Error 1005 bị từ chối truy cập khi quét dữ liệu. Khám phá các giải pháp như proxy nhà ở, dấu vân tay trình duyệt và CapSolver cho CAPTCHA. Tối ưu hóa việc trích xuất dữ liệu.

CloudflareMar 17, 2026
Làm thế nào để điều hướng Cloudflare Turnstile với Playwright Stealth trong luồng công việc AI
Khám phá cách xử lý hiệu quả Cloudflare Turnstile trong các quy trình AI bằng các kỹ thuật che giấu của Playwright và CapSolver để giải captcha đáng tin cậy. Học các chiến lược tích hợp thực tế và các phương pháp tốt nhất để tự động hóa không gián đoạn.

