Thu thập dữ liệu web trên Linux: Công cụ, Cài đặt và Hướng dẫn thực hành

Anh Tuan
Data Science Expert
TL;DR
- Linux là nền tảng chủ đạo cho trích xuất dữ liệu web trong sản xuất nhờ tính ổn định, lịch trình cron và chi phí tài nguyên thấp.
- Các công cụ trích xuất dữ liệu Python cơ bản — Requests, BeautifulSoup, Scrapy và Playwright — mỗi công cụ phục vụ các trường hợp sử dụng khác nhau.
- Quay vòng proxy là yếu tố thiết yếu cho việc trích xuất dữ liệu quy mô lớn để tránh bị giới hạn tốc độ theo IP.
- Thách thức CAPTCHA là trở ngại phổ biến trong các luồng tự động; API của CapSolver giải quyết chúng một cách lập trình trong 1–5 giây.
- Một luồng trích xuất dữ liệu hoàn chỉnh trên Linux kết hợp lịch trình (cron), lưu trữ (SQLite/PostgreSQL), quản lý proxy và xử lý CAPTCHA.
- Luôn trích xuất dữ liệu một cách có trách nhiệm: tuân thủ
robots.txt, giới hạn tốc độ yêu cầu và tuân thủ các luật bảo vệ dữ liệu có liên quan.
Giới thiệu
Linux là nền tảng được lựa chọn bởi các nhà phát triển thực hiện trích xuất dữ liệu web quy mô lớn. Tính ổn định, lịch trình cron tích hợp, chi phí tài nguyên thấp và hệ sinh thái Python trưởng thành khiến nó trở nên thực tế hơn rất nhiều so với Windows hoặc macOS cho các luồng trích xuất dữ liệu tự động chạy lâu dài. Hướng dẫn này sẽ đi qua các bước thiết lập môi trường, lựa chọn công cụ, cấu hình proxy, xử lý CAPTCHA và kiến trúc luồng trích xuất — một tài liệu tham khảo thực tế cho các nhà phát triển xây dựng trích xuất dữ liệu trên Linux vào năm 2025.
Tại sao Linux là nền tảng được ưa chuộng cho trích xuất dữ liệu web
Linux điều khiển hơn 80% máy chủ web trên toàn thế giới, theo thống kê hệ điều hành máy chủ của W3Techs. Sự thống trị này không phải là tình cờ — Linux cung cấp một loạt khả năng tích hợp giúp nó trở thành môi trường lý tưởng nhất cho trích xuất dữ liệu web trên Linux ở mọi quy mô.
Ưu điểm chính cho các công việc trích xuất dữ liệu:
- Lịch trình cron — tự động hóa các tập lệnh trích xuất ở bất kỳ khoảng thời gian nào mà không cần công cụ bên thứ ba.
- Chi phí bộ nhớ thấp — chạy trình duyệt không giao diện và nhiều công nhân cùng lúc trên phần cứng vừa và nhỏ.
- Quản lý gói —
apt,pipvàcondagiúp quản lý phụ thuộc sạch sẽ và tái tạo được. - Truy cập SSH — quản lý các máy chủ trích xuất từ xa mà không cần giao diện đồ họa.
- Tính ổn định — các công việc chạy lâu dài ít có khả năng bị gián đoạn bởi các sự kiện hệ điều hành.
- Công cụ CLI bản địa —
wget,curl,grep,sedvàawkxử lý các nhiệm vụ trích xuất nhẹ trực tiếp từ terminal, như được mô tả trong hướng dẫn trích xuất dữ liệu web của Linux.com.
Hầu hết các nhà cung cấp VPS đám mây — AWS EC2, DigitalOcean, Linode — mặc định sử dụng Ubuntu hoặc Debian, khiến Linux trở thành mục tiêu triển khai tự nhiên cho bất kỳ luồng trích xuất dữ liệu nghiêm túc nào.
Thiết lập Môi trường Trích xuất Dữ liệu trên Linux
Trước khi viết bất kỳ dòng code nào, hãy thiết lập một môi trường sạch sẽ và tách biệt.
Bước 1 — Cài đặt Python và pip
Hầu hết các phân phối Linux hiện đại đều đi kèm với Python 3. Kiểm tra phiên bản của bạn:
bash
python3 --version
pip3 --versionNếu pip không có sẵn:
bash
sudo apt update && sudo apt install python3-pip -yBước 2 — Tạo Môi trường Ảo
Cách ly các phụ thuộc giúp tránh xung đột phiên bản giữa các dự án:
bash
python3 -m venv scraper-env
source scraper-env/bin/activateBước 3 — Cài đặt Thư viện Trích xuất Dữ liệu Chính
bash
pip install requests beautifulsoup4 scrapy playwright lxml
playwright install chromiumBước 4 — Cài đặt Công cụ Hỗ trợ
bash
pip install pandas sqlalchemy psycopg2-binary fake-useragentBộ cơ sở này bao gồm trích xuất trang tĩnh, xử lý JavaScript và lưu trữ dữ liệu — ba trụ cột của bất kỳ quy trình trích xuất dữ liệu web trên Linux nào.
Các Công cụ Trích xuất Dữ liệu Python: Chọn Công cụ Phù hợp
Việc chọn công cụ phù hợp phụ thuộc vào độ phức tạp của trang web mục tiêu và yêu cầu về tốc độ. Bảng dưới đây tóm tắt các công cụ trích xuất dữ liệu Python chính được sử dụng trong môi trường Linux.
Tóm tắt So sánh
| Công cụ | Tốt nhất cho | Xử lý JavaScript | Tốc độ | Khó khăn học tập |
|---|---|---|---|---|
| Requests | Yêu cầu HTTP đơn giản, trang tĩnh | ✗ | Nhanh | Thấp |
| BeautifulSoup | Phân tích HTML/XML (kết hợp với Requests) | ✗ | Nhanh | Thấp |
| Scrapy | Crawl quy mô lớn, định kỳ | ✗ (thông qua plugin) | Rất nhanh | Trung bình |
| Playwright | Trang JS động, nặng | ✓ | Trung bình | Trung bình |
| Selenium | Tự động hóa cũ, trang JS | ✓ | Chậm | Trung bình |
Requests + BeautifulSoup là điểm bắt đầu tiêu chuẩn cho trích xuất dữ liệu web trên Linux. Nó xử lý phần lớn các trang tĩnh với thiết lập tối thiểu và là con đường nhanh nhất để tạo một scraper hoạt động.
Scrapy là lựa chọn đúng đắn cho các luồng trích xuất dữ liệu quy mô lớn, sản xuất. Nó xử lý cookie, phiên đăng nhập, nén, xác thực, bộ nhớ đệm và robots.txt ngay từ đầu, và kiến trúc middleware của nó hỗ trợ quay vòng proxy và xử lý CAPTCHA tùy chỉnh. Scrapy là một trong những khung phần mềm trích xuất dữ liệu Python được sử dụng rộng rãi nhất, với hơn 52.000 ngôi sao trên GitHub tính đến năm 2025 (Scrapy trên GitHub). Để hiểu rõ hơn về cách các công cụ này so sánh trong các tình huống thực tế, xem các công cụ trích xuất dữ liệu được giải thích.
Playwright là sự thay thế hiện đại cho Selenium khi xử lý JavaScript là cần thiết. Nó chạy Chromium không giao diện trực tiếp trên Linux, hỗ trợ thực thi bất đồng bộ và nhanh hơn đáng kể cho nội dung động. Để so sánh chi tiết hơn về các phương pháp tự động hóa trình duyệt, nodriver so với các công cụ tự động hóa trình duyệt truyền thống phân tích kỹ hơn các ưu và nhược điểm.
Sử dụng Proxy trong Trích xuất Dữ liệu Web trên Linux
Quay vòng proxy là yếu tố thiết yếu cho bất kỳ thiết lập trích xuất dữ liệu web trên Linux nào. Nếu không có nó, IP của scraper của bạn sẽ bị giới hạn tốc độ hoặc chặn sau một số yêu cầu tương đối nhỏ. Proxy nhà ở tĩnh — các địa chỉ IP được cấp bởi ISP — đặc biệt hiệu quả vì chúng mô phỏng hành vi người dùng thực tế, giảm khả năng bị phát hiện, như được nêu trong hướng dẫn về trích xuất dữ liệu có đạo đức của Linux Security.
Các Loại Proxy
| Loại | Rủi ro phát hiện | Chi phí | Tốt nhất cho |
|---|---|---|---|
| Datacenter | Cao | Thấp | Các mục tiêu nhạy cảm với tốc độ, bảo vệ thấp |
| Residential | Thấp | Trung bình | Các trang có phát hiện bot trung bình |
| Residential quay vòng | Rất thấp | Cao hơn | Các luồng quy mô lớn, liên tục |
Cấu hình Proxy trong Python Requests
python
import requests
proxies = {
"http": "http://username:password@proxy-host:port",
"https": "http://username:password@proxy-host:port",
}
response = requests.get("https://example.com", proxies=proxies)
print(response.status_code)Cấu hình Proxy trong Scrapy
Trong settings.py:
python
ROTATING_PROXY_LIST = [
"http://proxy1:port",
"http://proxy2:port",
]Sử dụng middleware scrapy-rotating-proxies để quản lý tự động nhóm proxy.
Các Nguyên tắc Tốt
- Quay vòng chuỗi user-agent cùng với quay vòng IP bằng
fake-useragent. - Thêm khoảng thời gian ngẫu nhiên giữa các yêu cầu:
time.sleep(random.uniform(1, 3)). - Giám sát sức khỏe proxy và tự động loại bỏ các IP lỗi khỏi nhóm của bạn.
- Sử dụng proxy HTTPS cho các trang yêu cầu kiểm tra TLS.
Đối với danh sách được tổng hợp các nhà cung cấp proxy hoạt động tốt với trích xuất dữ liệu web trên Linux, dịch vụ proxy tốt nhất cho trích xuất dữ liệu là điểm bắt đầu hữu ích.
Xử lý CAPTCHA trong Luồng Trích xuất Dữ liệu
Thách thức CAPTCHA là trở ngại phổ biến nhất trong trích xuất dữ liệu sản xuất trên Linux. Các trang web triển khai reCAPTCHA v2/v3, hCaptcha, Cloudflare Turnstile và các thách thức khác nhằm làm gián đoạn các luồng trích xuất dữ liệu tự động. reCAPTCHA v2 chỉ riêng nó được sử dụng bởi hơn 5 triệu trang web trên toàn cầu, theo hướng dẫn tích hợp reCAPTCHA v2 của CapSolver.
Giải quyết CAPTCHA thủ công không khả thi về quy mô. Giải pháp thực tế là tích hợp một API giải CAPTCHA lập trình trực tiếp vào quy trình trích xuất của bạn. CapSolver là một dịch vụ dựa trên AI giải quyết reCAPTCHA, hCaptcha, Cloudflare Turnstile, GeeTest, AWS WAF và các loại thách thức khác thông qua API REST, thường trả về một mã xác thực hợp lệ trong 1–5 giây — không cần can thiệp của con người.
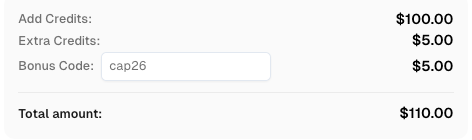
Nhận Mã Khuyến mãi của CapSolver
Tăng ngân sách tự động hóa của bạn ngay lập tức!
Sử dụng mã khuyến mãi CAP26 khi nạp tiền tài khoản CapSolver để nhận thêm 5% khuyến mãi cho mỗi lần nạp — không có giới hạn.
Nhận mã khuyến mãi ngay bây giờ trong Bảng điều khiển CapSolver
Cách CapSolver Hoạt động
- Scraper của bạn phát hiện một CAPTCHA trên trang đích.
- Bạn gửi URL trang và khóa trang đến endpoint
createTaskcủa CapSolver. - Mô hình AI của CapSolver giải quyết thách thức và trả về một mã xác thực.
- Bạn chèn mã xác thực vào trường gửi biểu mẫu hoặc tiêu đề yêu cầu.
- Scraper tiếp tục mà không bị gián đoạn.
Ví dụ Tích hợp Python (reCAPTCHA v2 — Không Proxy)
Ví dụ sau dựa trên tài liệu API chính thức của CapSolver:
python
import requests
import time
# Mã API của bạn
API_KEY = "YOUR_CAPSOLVER_API_KEY"
WEBSITE_URL = "https://example.com"
WEBSITE_KEY = "YOUR_RECAPTCHA_SITE_KEY"
def create_task():
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": WEBSITE_URL,
"websiteKey": WEBSITE_KEY,
}
}
response = requests.post(
"https://api.capsolver.com/createTask",
json=payload
)
return response.json().get("taskId")
def get_task_result(task_id):
payload = {
"clientKey": API_KEY,
"taskId": task_id,
}
while True:
response = requests.post(
"https://api.capsolver.com/getTaskResult",
json=payload
)
result = response.json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
time.sleep(2)
task_id = create_task()
token = get_task_result(task_id)
print("Mã CAPTCHA:", token)Mã này sau đó được chèn vào trường g-recaptcha-response của biểu mẫu, cho phép scraper của bạn vượt qua rào cản CAPTCHA. Đối với các nhiệm vụ dựa trên proxy, hãy chuyển đổi loại nhiệm vụ sang ReCaptchaV2Task và thêm thông tin proxy của bạn vào payload.
CapSolver hỗ trợ hai chế độ nhiệm vụ:
ReCaptchaV2TaskProxyLess— sử dụng cơ sở hạ tầng của riêng CapSolver; cài đặt đơn giản hơn.ReCaptchaV2Task— sử dụng proxy của bạn; tốt hơn cho các trang có giới hạn địa lý nghiêm ngặt.
Đối với danh sách đầy đủ các loại nhiệm vụ được hỗ trợ — bao gồm reCAPTCHA v3, Cloudflare Turnstile và AWS WAF — xem tài liệu loại nhiệm vụ CapSolver.
Xây Dựng Một Luồng Trích xuất Dữ liệu Hoàn chỉnh trên Linux
Một thiết lập trích xuất dữ liệu web trên Linux sẵn sàng sản xuất không chỉ là một tập lệnh đơn lẻ. Đó là một luồng với các giai đoạn riêng biệt, có thể kết hợp.
Kiến trúc Luồng
[Bộ lập lịch: cron]
→ [Scraper: Scrapy / Playwright]
→ [Lớp Proxy: nhà ở quay vòng]
→ [Trình xử lý CAPTCHA: API CapSolver]
→ [Parser: BeautifulSoup / lxml]
→ [Lưu trữ: SQLite / PostgreSQL]
→ [Xuất: CSV / JSON / REST API]Lập lịch với Cron
Chỉnh sửa crontab để chạy một công việc trích xuất mỗi giờ:
bash
crontab -eThêm dòng sau:
0 * * * * /home/user/scraper-env/bin/python /home/user/scraper/run.py >> /home/user/scraper/logs/scrape.log 2>&1Lưu trữ Dữ liệu Trích xuất
Đối với các dự án nhỏ, SQLite là đủ:
python
import sqlite3
conn = sqlite3.connect("data.db")
cursor = conn.cursor()
cursor.execute(
"CREATE TABLE IF NOT EXISTS products (name TEXT, price TEXT, url TEXT)"
)
cursor.execute(
"INSERT INTO products VALUES (?, ?, ?)", (name, price, url)
)
conn.commit()
conn.close()Đối với các luồng lớn hơn, PostgreSQL với SQLAlchemy cung cấp khả năng đồng thời và hiệu suất truy vấn tốt hơn.
Ghi nhật ký và Xử lý Lỗi
Luôn ghi nhật ký hoạt động trích xuất. Sử dụng module logging tích hợp của Python:
python
import logging
logging.basicConfig(
filename="scrape.log",
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s"
)
logging.info("Trích xuất bắt đầu")Ghi nhật ký có cấu trúc giúp dễ dàng hơn rất nhiều trong việc gỡ lỗi các sự cố trong các công việc trích xuất dữ liệu web trên Linux chạy lâu — đặc biệt khi có lỗi proxy và thời gian chờ CAPTCHA.
Tuân thủ và Trích xuất Dữ liệu Có trách nhiệm
Trích xuất dữ liệu web trên Linux là một khả năng mạnh mẽ, nhưng nó phải được sử dụng một cách có trách nhiệm.
- Kiểm tra
robots.txt— luôn xemhttps://example.com/robots.txttrước khi trích xuất. Tuân thủ các chỉ thịDisallow. - Giới hạn tốc độ — không tấn công máy chủ. Thêm khoảng thời gian chờ giữa các yêu cầu để tránh làm giảm hiệu suất trang web.
- Điều khoản dịch vụ — xem xét điều khoản dịch vụ của trang đích. Một số trang cấm thu thập dữ liệu tự động.
- Dữ liệu cá nhân — tránh thu thập thông tin cá nhân (PII) mà không có cơ sở pháp lý theo các quy định có liên quan như GDPR.
- Quyền sở hữu trí tuệ — nội dung được trích xuất có thể được bảo vệ bởi quyền sở hữu trí tuệ. Sử dụng dữ liệu để phân tích, không phải công bố lại.
Trích xuất dữ liệu có trách nhiệm không chỉ là yếu tố đạo đức — mà ngày càng trở thành một yếu tố pháp lý. Các khuôn khổ về thu thập dữ liệu tự động tiếp tục phát triển, và việc tích hợp tuân thủ vào luồng của bạn từ đầu sẽ rẻ hơn nhiều so với việc bổ sung sau này.
Kết luận
Trích xuất dữ liệu web trên Linux mang lại cho các nhà phát triển một nền tảng ổn định, có thể lập trình và chi phí hiệu quả cho việc trích xuất dữ liệu ở mọi quy mô. Sự kết hợp giữa các công cụ trích xuất Python như Scrapy và Playwright, lớp proxy được cấu hình tốt và dịch vụ giải CAPTCHA lập trình bao phủ toàn bộ các thách thức bạn sẽ gặp phải trong sản xuất. Bắt đầu với môi trường ảo sạch sẽ, chọn công cụ dựa trên độ phức tạp của trang đích và xây dựng luồng của bạn từng bước — bao gồm lịch trình, lưu trữ và xử lý lỗi.
Nếu các thách thức CAPTCHA đang cản trở quy trình quét của bạn, bắt đầu với CapSolver và tích hợp giải CAPTCHA được hỗ trợ bởi AI vào dòng chảy của bạn trong vài phút.
Câu hỏi thường gặp
Câu hỏi 1: Thư viện Python nào tốt nhất cho việc quét web trên Linux?
Điều này phụ thuộc vào trường hợp sử dụng. Đối với các trang web tĩnh, Requests kết hợp với BeautifulSoup là lựa chọn nhanh nhất và đơn giản nhất. Đối với các cuộc quét quy mô lớn và lặp lại, Scrapy là tiêu chuẩn ngành. Đối với các trang web có nhiều JavaScript, Playwright là lựa chọn được khuyến nghị trên Linux.
Câu hỏi 2: Làm thế nào để chạy bộ quét web tự động trên Linux?
Sử dụng cron jobs. Chỉnh sửa crontab của bạn bằng crontab -e và thêm một dòng chỉ định lịch trình và đường dẫn đến tập lệnh Python của bạn. Điều này sẽ chạy bộ quét của bạn ở bất kỳ khoảng thời gian nào mà không cần can thiệp thủ công.
Câu hỏi 3: Làm thế nào để xử lý CAPTCHA trong dòng chảy quét web?
Tích hợp một API giải CAPTCHA như CapSolver. Bộ quét của bạn gửi URL trang web và khóa trang đến API, nhận được token đã được giải và chèn nó vào yêu cầu. Quy trình này được tự động hóa hoàn toàn và chỉ thêm vài giây độ trễ mỗi lần gặp CAPTCHA.
Câu hỏi 4: Proxy có cần thiết cho việc quét web trên Linux không?
Đối với các nhiệm vụ quét nhỏ và không thường xuyên, proxy có thể không cần thiết. Đối với các quy trình trích xuất dữ liệu quy mô lớn hoặc liên tục, proxy quay vòng là cần thiết để tránh bị hạn chế tốc độ hoặc chặn do IP.
Câu hỏi 5: Việc quét web trên Linux có hợp pháp không?
Việc quét web nói chung là hợp pháp khi áp dụng cho dữ liệu công khai. Tuy nhiên, bạn phải tuân thủ robots.txt của trang đích, điều khoản dịch vụ và các luật bảo vệ dữ liệu có liên quan. Việc quét dữ liệu cá nhân hoặc nội dung có bản quyền mà không có sự cho phép có thể gây rủi ro pháp lý.
Xem thêm
AIJun 23, 2026
SDK giải CAPTCHA tích hợp sẵn cho Tác nhân AI
Hướng dẫn dành cho nhà phát triển về SDK giải CAPTCHA bản địa cho các tác nhân AI, với các giới hạn bao bọc, ví dụ chính thức, kiểm tra phiên làm việc và xử lý lỗi.
AIJun 23, 2026
Chọn dịch vụ giải mã CAPTCHA cho tự động hóa agent
Một danh sách kiểm tra kỹ thuật cho người mua thực tế để lựa chọn dịch vụ giải CAPTCHA cho tự động hóa bằng trợ lý trong quy trình được kiểm soát và tài liệu hóa.