How to Solve Web Scraping Challenges with Scrapy and Playwright in 2026

Lucas Mitchell
Automation Engineer

TL;DR
- Scrapy-Playwright integrates Scrapy with Playwright, enabling scraping of JavaScript-heavy websites.
- Key benefits: JavaScript rendering, headless browsing, advanced interactions (clicks, forms), asynchronous operations for faster scraping.
- Setup: Install Scrapy, Scrapy-Playwright, and Playwright browsers; configure settings to enable Playwright.
- Basic usage: Create spiders that use
playwright=TrueandPageCoroutineto wait for dynamic content before parsing. - Captcha handling: Integrate CapSolver via a browser extension to solve captchas automatically in scraping workflows.
- Advanced features: Multi-page scraping, multiple browser contexts, middleware integration, custom headers, and parallel scraping.
- Best practices: Optimize Playwright usage, reuse browser contexts, handle timeouts, respect robots.txt, implement throttling, secure API keys, and monitor scraping activity.
What is Scrapy-Playwright?
Scrapy-Playwright is a middleware that integrates Scrapy, a fast and powerful web scraping framework for Python, with Playwright, a browser automation library. This combination allows Scrapy to handle JavaScript-heavy websites by leveraging Playwright's ability to render dynamic content, interact with web pages, and manage browser contexts seamlessly.
Why Use Scrapy-Playwright?
While Scrapy is excellent for scraping static websites, many modern websites rely heavily on JavaScript to render content dynamically. Traditional Scrapy spiders can struggle with these sites, often missing critical data or failing to navigate complex page structures. Scrapy-Playwright bridges this gap by enabling Scrapy to control a headless browser, ensuring that all dynamic content is fully loaded and accessible for scraping.
Benefits of Using Scrapy-Playwright
- JavaScript Rendering: Easily scrape websites that load content dynamically using JavaScript.
- Headless Browsing: Perform scraping tasks without a visible browser, optimizing performance.
- Advanced Interactions: Handle complex interactions like clicking buttons, filling forms, and navigating through pages.
- Asynchronous Operations: Benefit from Playwright's asynchronous capabilities to speed up scraping tasks.
Installation
To get started with Scrapy-Playwright, you'll need to install both Scrapy and Playwright. Here's how you can set up your environment:
-
Install Scrapy:
bashpip install scrapy -
Install Scrapy-Playwright:
bashpip install scrapy-playwright -
Install Playwright Browsers:
After installing Playwright, you need to install the necessary browser binaries.
bashplaywright install
Getting Started
Setting Up a New Scrapy Project
First, create a new Scrapy project if you haven't already:
bash
scrapy startproject myproject
cd myprojectConfiguring Playwright
Next, you'll need to enable Playwright in your Scrapy project's settings. Open settings.py and add the following configurations:
python
# settings.py
# Enable the Playwright downloader middleware
DOWNLOADER_MIDDLEWARES = {
'scrapy_playwright.middleware.ScrapyPlaywrightDownloadHandler': 543,
}
# Specify the download handler for HTTP and HTTPS
DOWNLOAD_HANDLERS = {
'http': 'scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler',
'https': 'scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler',
}
# Enable Playwright settings
TWISTED_REACTOR = 'twisted.internet.asyncioreactor.AsyncioSelectorReactor'
# Playwright settings (optional)
PLAYWRIGHT_BROWSER_TYPE = 'chromium' # Can be 'chromium', 'firefox', or 'webkit'
PLAYWRIGHT_LAUNCH_OPTIONS = {
'headless': True,
}Basic Usage
Creating a Spider
With the setup complete, let's create a simple spider that uses Playwright to scrape a JavaScript-rendered website. For illustration, we'll scrape a hypothetical site that loads content dynamically.
Create a new spider file dynamic_spider.py inside the spiders directory:
python
# spiders/dynamic_spider.py
import scrapy
from scrapy_playwright.page import PageCoroutine
class DynamicSpider(scrapy.Spider):
name = "dynamic"
start_urls = ["https://example.com/dynamic"]
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(
url,
meta={
"playwright": True,
"playwright_page_coroutines": [
PageCoroutine("wait_for_selector", "div.content"),
],
},
)
async def parse(self, response):
# Extract data after JavaScript has rendered the content
for item in response.css("div.content"):
yield {
"title": item.css("h2::text").get(),
"description": item.css("p::text").get(),
}
# Handle pagination or additional interactions if necessaryHandling JavaScript-Rendered Content
In the example above:
playwright: True: Informs Scrapy to use Playwright for this request.playwright_page_coroutines: Specifies actions to perform with Playwright. Here, it waits for a selectordiv.contentto ensure the dynamic content has loaded before parsing.- Asynchronous
parseMethod: Leverages async capabilities to handle the response effectively.
Solving Captchas with CapSolver
One of the significant challenges in web scraping is dealing with captchas, which are designed to prevent automated access. CapSolver is a robust solution that provides captcha-solving services, including integrations with browser automation tools like Playwright. In this section, we'll explore how to integrate CapSolver with Scrapy-Playwright to handle captchas seamlessly.
What is CapSolver?
CapSolver is a captcha-solving service that automates the process of solving various types of captchas, including reCAPTCHA. By integrating CapSolver with your scraping workflow, you can bypass captcha challenges and maintain the flow of your scraping tasks without manual intervention.
Integrating CapSolver with Scrapy-Playwright
To integrate CapSolver with Scrapy-Playwright, you'll need to:
- Obtain the CapSolver Browser Extension: CapSolver provides a browser extension that automates captcha solving within browser contexts.
- Configure Playwright to Load the CapSolver Extension: When launching the Playwright browser, load the CapSolver extension to enable captcha solving.
- Modify Scrapy Requests to Use the Customized Playwright Context: Ensure that your Scrapy requests utilize the Playwright context with the CapSolver extension loaded.
Example Implementation in Python
Below is a step-by-step guide to integrating CapSolver with Scrapy-Playwright, complete with example code.
1. Obtain the CapSolver Browser Extension
First, download the CapSolver browser extension and place it in your project directory. Assume the extension is located at CapSolver.Browser.Extension.
2. Configure the Extension:
- Locate the configuration file
./assets/config.jsonin the CapSolver extension directory. - Set the option
enabledForcaptchatotrueand adjust thecaptchaModetotokenfor automatic solving.
Example config.json:
json
{
"enabledForcaptcha": true,
"captchaMode": "token"
// other settings remain the same
}3. Update Scrapy Settings to Load the Extension
Modify your settings.py to configure Playwright to load the CapSolver extension. You'll need to specify the path to the extension and pass the necessary arguments to Playwright.
python
# settings.py
import os
from pathlib import Path
# Existing Playwright settings
PLAYWRIGHT_BROWSER_TYPE = 'chromium'
PLAYWRIGHT_LAUNCH_OPTIONS = {
'headless': False, # Must be False to load extensions
'args': [
'--disable-extensions-except={}'.format(os.path.abspath('CapSolver.Browser.Extension')),
'--load-extension={}'.format(os.path.abspath('CapSolver.Browser.Extension')),
],
}
# Ensure that the Twisted reactor is set
TWISTED_REACTOR = 'twisted.internet.asyncioreactor.AsyncioSelectorReactor'Note: Loading browser extensions requires the browser to run in non-headless mode. Therefore, set 'headless': False.
3. Create a Spider That Handles Captchas
Create a new spider or modify an existing one to interact with captchas using the CapSolver extension.
python
# spiders/captcha_spider.py
import scrapy
from scrapy_playwright.page import PageCoroutine
import asyncio
class CaptchaSpider(scrapy.Spider):
name = "captcha_spider"
start_urls = ["https://site.example/captcha-protected"]
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(
url,
meta={
"playwright": True,
"playwright_page_coroutines": [
PageCoroutine("wait_for_selector", "iframe[src*='captcha']"),
PageCoroutine("wait_for_timeout", 1000), # Wait for extension to process
],
"playwright_context": "default",
},
callback=self.parse_captcha
)
async def parse_captcha(self, response):
page = response.meta["playwright_page"]
# Locate the captcha checkbox or frame and interact accordingly
try:
# Wait for the captcha iframe to be available
await page.wait_for_selector("iframe[src*='captcha']", timeout=10000)
frames = page.frames
captcha_frame = None
for frame in frames:
if 'captcha' in frame.url:
captcha_frame = frame
break
if captcha_frame:
# Click the captcha checkbox
await captcha_frame.click("div#checkbox")
# Wait for captcha to be solved by CapSolver
await page.wait_for_selector("div.captcha-success", timeout=60000) # Adjust selector as needed
self.logger.info("Captcha solved successfully.")
else:
self.logger.warning("captcha iframe not found.")
except Exception as e:
self.logger.error(f"Error handling captcha: {e}")
# Proceed with parsing the page after captcha is solved
for item in response.css("div.content"):
yield {
"title": item.css("h2::text").get(),
"description": item.css("p::text").get(),
}
# Handle pagination or additional interactions if necessary4. Running the Spider
Ensure that all dependencies are installed and run your spider using:
bash
scrapy crawl captcha_spiderAdvanced Features
Once you're comfortable with the basics, Scrapy-Playwright offers several advanced features to enhance your scraping projects.
Handling Multiple Pages
Scraping multiple pages or navigating through a website can be streamlined using Playwright's navigation capabilities.
python
# spiders/multi_page_spider.py
import scrapy
from scrapy_playwright.page import PageCoroutine
class MultiPageSpider(scrapy.Spider):
name = "multipage"
start_urls = ["https://example.com/start"]
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(
url,
meta={
"playwright": True,
"playwright_page_coroutines": [
PageCoroutine("wait_for_selector", "div.list"),
PageCoroutine("evaluate", "window.scrollTo(0, document.body.scrollHeight)"),
],
},
)
async def parse(self, response):
# Extract data from the first page
for item in response.css("div.list-item"):
yield {
"name": item.css("span.name::text").get(),
"price": item.css("span.price::text").get(),
}
# Navigate to the next page
next_page = response.css("a.next::attr(href)").get()
if next_page:
yield scrapy.Request(
response.urljoin(next_page),
callback=self.parse,
meta={
"playwright": True,
"playwright_page_coroutines": [
PageCoroutine("wait_for_selector", "div.list"),
],
},
)Using Playwright Contexts
Playwright allows the creation of multiple browser contexts, which can be useful for handling sessions, cookies, or parallel scraping tasks.
python
# settings.py
PLAYWRIGHT_CONTEXTS = {
"default": {
"viewport": {"width": 1280, "height": 800},
"user_agent": "CustomUserAgent/1.0",
},
"mobile": {
"viewport": {"width": 375, "height": 667},
"user_agent": "MobileUserAgent/1.0",
"is_mobile": True,
},
}In your spider, specify the context:
python
# spiders/context_spider.py
import scrapy
class ContextSpider(scrapy.Spider):
name = "context"
start_urls = ["https://example.com"]
def start_requests(self):
yield scrapy.Request(
self.start_urls[0],
meta={
"playwright": True,
"playwright_context": "mobile",
},
)
async def parse(self, response):
# Your parsing logic here
passIntegrating with Middleware
Scrapy-Playwright can be integrated with other middlewares to enhance functionality, such as handling retries, proxy management, or custom headers.
python
# settings.py
DOWNLOADER_MIDDLEWARES.update({
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy_playwright.middleware.ScrapyPlaywrightDownloadHandler': 543,
})
# Example of setting custom headers
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'MyCustomAgent/1.0',
'Accept-Language': 'en-US,en;q=0.9',
}Best Practices
To make the most out of Scrapy-Playwright and CapSolver, consider the following best practices:
- Optimize Playwright Usage: Only use Playwright for requests that require JavaScript rendering to save resources.
- Manage Browser Contexts: Reuse browser contexts where possible to improve performance and reduce overhead.
- Handle Timeouts Gracefully: Set appropriate timeouts and error handling to manage slow-loading pages.
- Respect Robots.txt and Terms of Service: Always ensure your scraping activities comply with the target website's policies.
- Implement Throttling and Delays: Prevent overloading the target server by implementing polite scraping practices.
- Secure Your CapSolver API Keys: Store sensitive information like API keys securely and avoid hardcoding them in your scripts.
- Monitor and Log Scraping Activity: Keep track of your scraping operations to quickly identify and resolve issues.
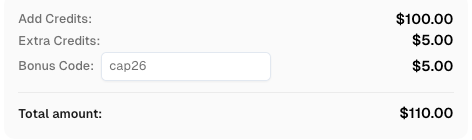
Bonus Code
Use code
CAP26when signing up at CapSolver to receive bonus credits!
Conclusion
Scrapy-Playwright is a game-changer for web scraping, bridging the gap between static and dynamic content extraction. By leveraging the power of Scrapy's robust framework and Playwright's advanced browser automation, you can tackle even the most challenging scraping tasks with ease. Furthermore, integrating CapSolver allows you to overcome captcha challenges, ensuring uninterrupted data collection from even the most guarded websites.
Whether you're scraping e-commerce sites, social media platforms, or any JavaScript-heavy website, Scrapy-Playwright combined with CapSolver provides the tools you need to succeed. By following best practices and leveraging these powerful integrations, you can build efficient, reliable, and scalable web scraping solutions tailored to your specific needs.
Ready to elevate your scraping projects? Dive into Scrapy-Playwright and CapSolver, and unlock new possibilities for data collection and automation.
FAQs
1. Do I need Playwright for all Scrapy projects?
No. Only use Playwright for pages that rely on JavaScript to load content. For static pages, traditional Scrapy spiders are faster and more resource-efficient.
2. Can Scrapy-Playwright bypass captchas automatically?
Yes. By integrating CapSolver with the Playwright browser extension, captchas can be solved automatically, allowing uninterrupted scraping.
3. Is it possible to scrape multiple pages or use mobile browser settings?
Yes. Scrapy-Playwright supports multiple page navigation, and you can define multiple Playwright contexts (e.g., mobile, desktop) to simulate different devices or sessions.
More
CloudflareJun 12, 2026
Playwright Blocked by Cloudflare Turnstile: Causes & Fix
A Playwright-specific Turnstile guide covering traces, locator timing, actionability, network events, parameters, and server-side validation.

AIJun 11, 2026
Solving CAPTCHA Blocking Issues in Cursor Agents
A field guide for Cursor agent CAPTCHA blocks, including loop control, browser state, MCP boundaries, proxy hygiene, and measured remediation.


