AIスクラピングとは何ですか? 定義、利点、利用ケース。

Sora Fujimoto
AI Solutions Architect

TL;DR:
- AIスクリーピングは、機械学習と自然言語処理(NLP)を用いてデータ抽出を自動化し、従来のルールベースの方法の脆さを克服します。
- 未構造化データの処理に優れ、複雑なアンチボット対策を回避し、ウェブサイトのレイアウト変更に手動更新なしで対応できます。
- 主な利点には、99.5%の抽出精度、メンテナンスコストの削減、および生のウェブコンテンツを行動可能な知識に変換する能力が含まれます。
- 現代のAIスクリーピングワークフローで高度なCAPTCHA(reCAPTCHA、Cloudflare)を解決するには、専門的なツールであるCapSolverの統合が不可欠です。
イントロダクション
デジタル環境は過去にないスピードで進化しており、情報収集に使用する方法もそれに追従する必要があります。AIスクリーピングは、単純なスクリプトを超えた、ウェブを人間のように理解する知的なシステムに進化したデータ収集の次世代です。2026年のビジネスにおいて、スケールで高品質なデータを抽出できる能力は、もはや贅沢ではなく、核心的な競争力の必要条件です。この記事では、AI駆動型抽出が従来の方法を置き換える理由、その成功の技術的メカニズム、そしてAIエージェントウェブスクリーパーを作成する方法について探ります。データサイエンティストであろうとビジネスリーダーであろうと、データ経済の未来を navigating するためにはこの変化を理解することが不可欠です。
AIスクリーピングとは?
AIスクリーピングは、人工知能(特に機械学習(ML)と自然言語処理(NLP))を用いて、デジタルソースからデータを自動的に抽出するプロセスです。従来のウェブスクリーピングが固定されたCSSセレクターやXPath式に依存しているのに対し、AIスクリーピングはページの視覚的およびテキスト的な文脈を解釈します。これにより、下層のHTML構造がどうであれ、「価格」や「著者」を識別できます。
グローバルなウェブスクリーピング市場は、最近のMarket Growth Reportsによると、2025年までに123億4000万ドルに達すると予測されています。この成長は、大規模言語モデル(LLM)の高品質なトレーニングデータへの需要によって主に推進されています。AIスクリーピングは単にデータを収集するだけでなく、エンティティ間の関係を理解し、感情分析を行い、リアルタイムでデータをクリーニングすることで知識を収集します。
AIスクリーピングの仕組み
AI駆動型抽出のメカニズムは、人間のブラウジング行動を模倣しながら、膨大な計算力を利用する複雑なマルチレイヤー構造です。
| レイヤー | 機能 | 主な技術 |
|---|---|---|
| データ取得 | ウェブサイトをナビゲートし、JavaScriptを処理し、プロキシを管理します。 | Playwright、Puppeteer、Headless Chrome |
| 解釈 | コンテキストを使用して関連するフィールド(タイトル、価格、レビュー)を識別します。 | LLM(GPT-4、Claude)、コンピュータビジョン |
| 適応性 | レイアウト変更時にデータポイントを再マッピングすることで自己修復します。 | 強化学習、パターン認識 |
| セキュリティナビゲーションレイヤー | CAPTCHAやレートリミットなどのセキュリティ課題を解決します。 | CapSolver、AI駆動型ブラウザファINGERPRINTING |
典型的なワークフローでは、AIエージェントが自然言語のプロンプトを受け取り、ターゲットURLに移動し、コンピュータビジョンを使用してページレイアウトを「見る」、NLPを使用して特定の情報を抽出します。障害に遭遇した場合、AIブラウザとCAPTCHAソルバーを統合することで、データフローをスムーズに維持できます。
AIスクリーピング vs 従来のウェブスクリーピング
従来の方法からAI駆動型方法への移行は、厳密なアセンブリラインから柔軟なロボットシステムへの移行に例えられます。
従来のスクリーピングは「もし-なら」論理に基づいています。開発者がスクリプトに特定の<div>タグ内で価格を探すように指示した場合、ウェブサイトのオーナーがそのタグを<span>に変更すると、スクリーパーは動作しなくなります。これにより、高いメンテナンスコストと頻繁なダウンタイムが生じます。
一方、AIスクリーピングは意味的理解を使用します。HTMLタグが何であれ、ドル記号に続く数字が価格である可能性が高いと知っています。この耐性のため、Scrapingdogの2025年のトレンドレポートによると、AI駆動型ツールは手動ルール設定に比べて30〜40%の抽出速度の向上を達成しています。
比較要約
| 特徴 | 従来のウェブスクリーピング | AIスクリーピング |
|---|---|---|
| 論理の基盤 | 硬コードされたルール(CSS/XPath) | 意味的および視覚的理解 |
| メンテナンス | 高い(レイアウト変更で破損) | 低い(自己修復機能) |
| データ品質 | 手動クリーニングが必要 | 自動正規化とクリーニング |
| 複雑性 | ダイナミック/非構造化データで苦労 | イメージ、PDF、JS重視サイトで優れています |
| 成功確率 | 中程度(簡単にブロックされる) | 高い(人間の行動を模倣) |
AIスクリーピングの主な利点
データパイプラインにAIを導入することで、単なる自動化を越えた変革的な利点が得られます。
- 類を見ない耐性: AIスクリーパーは、人間の介入なしで小さなウェブサイトの更新に適応できます。この「自己修復」の特性により、ターゲットサイトが頻繁に再設計されても、データフローが安定したままになります。
- 非構造化データの処理: ウェブ上の価値ある情報の大部分は非構造化されています—ソーシャルメディアのコメント、フォーラムの投稿、ビデオの字幕など。AIはMaster MCP(モデルコンテキストプロトコル)を活用して、この生データを分析ツールに直接送信できます。
- 優れたアンチボット回避: 現代のウェブサイトは、ボットをブロックするために高度な行動分析を使用しています。AIスクリーパーは、マウスの動き、タイピング速度、ブラウジングパターンを模倣できます。課題に直面した場合、AIスクリーピングワークフローにCAPTCHA解決を統合することで、24/7の可用性を確保できます。
- スケールでのコスト効率: AIシステムの初期設定は高額かもしれませんが、破損したスクリーパーを修正するために必要な開発者時間の長期的な節約は非常に大きいです。
AIスクリーピングの一般的な利用ケース
AIスクリーピングは、さまざまな業界でイノベーションと効率を推進するために利用されています。知的な抽出の多様性により、以前は乗り越えがたいとされていたデータ課題に組織が取り組めるようになります。
エコマースのインテリジェンスと動的価格設定
オンライン小売業界では、価格は毎分変化します。AIスクリーピングにより、小売業者は数千ものグローバルな店舗で競合価格、在庫、顧客の感情をリアルタイムでモニタリングできます。単なる価格追跡を超えて、AIは製品の説明文や画像を分析して、競合が異なる命名規則を使用していても比較が正確であることを保証します。この精度により、利益率を大幅に向上させる動的価格戦略が可能になります。
高精度のAIトレーニングデータ
現在のAIブームはデータによって推進されています。次の世代のLLMをトレーニングするための大量のデータを収集するには、AI駆動型抽出のみが提供できる高精度なデータが必要です。従来のスクリーパーは、不要なノイズをデータセットに導入する可能性があります。AIスクリーパーは、記事のコアコンテンツと周囲の広告やナビゲーションリンクを区別できるため、トレーニングデータがクリーンで文脈的に関連性があることを保証します。
金融市場分析と代替データ
ヘッジファンドや金融機関は、競争優位を得るために代替データにますます依存しています。これは、ニュースサイト、規制文書、ソーシャルメディアのトレンド、さらにはテーブル形式で表された衛星画像データのスクリーピングを含みます。AIスクリーピングは、これらの多様なソースを同時に処理し、主流になる前に emerging マーケットトレンドを識別します。金融ニュースのリアルタイムでの感情分析により、AIエージェントは数秒でトレーダーに行動可能なインサイトを提供します。
不動産とリード生成
不動産業界は、複数のプラットフォームからの最新リストに大きく依存しています。AIスクリーピングは、これらのリストを集約し、データを正規化(平方フィートや通貨の変換など)し、自動的に価値が見込まれる不動産を特定できます。同様に、B2B販売において、AIは職務タイトル、企業の成長パターン、最近のニュースの言及を分析して、プロフェッショナルネットワークや企業ディレクトリから潜在的なリードを特定・評価し、非常にターゲットの絞られた販売パイプラインを作成できます。
技術的実装:信頼性のあるパイプラインの構築
AIスクリーピングを本当に活用するには、信頼性のあるデータパイプラインのアーキテクチャを理解する必要があります。これは、ターゲットURLの数が増えるにつれて水平にスケーラブルなコンテナ化されたソリューションを選ぶことから始まります。
ヘッドレスブラウザの役割
PlaywrightやPuppeteerなどのツールは、取得レイヤーの作業の中心です。これらはAIエージェントがウェブサイトと人間のようにインタラクティブにできるようにします—ボタンをクリックし、無限のフィードをスクロールし、非同期JavaScriptがロードされるのを待つことができます。しかし、これらのブラウザをスケールして実行することはリソースを大量に消費します。AI最適化により、どのページが完全なブラウザレンダリングを必要とし、どのページが高速で軽量なHTTPリクエストで取得できるかを判断できます。
エッジでの知能の統合
最も高度なAIスクリーピングのセットアップでは、データ抽出とクリーニングを「エッジ」で行います。これは、生のHTMLを中央サーバーに送信して処理する代わりに、AIエージェントがローカルで抽出を行うことを意味します。これにより、レイテンシーと帯域幅コストが削減されます。軽量なLLMや専門的なNLPモデルを使用することで、これらのエージェントはブラウザ環境から直接構造化されたJSONデータを提供できます。
セキュリティ課題の管理
前述したように、「セキュリティナビゲーションレイヤー」は不可欠です。パイプラインの強さはその最も弱いリンクに依存します。AIエージェントがCloudflareのチャレンジでブロックされると、全体のワークフローは停止します。このため、CapSolverなどのサービスとの堅牢な統合は必須です。これは、AIエージェントがセキュリティチェックポイントを通過するための「資格証明書」を提供します。ベストプラクティスとしては、ユーザーエージェントのローテーション、セッションクッキーの知的管理、スクリーパーのフットプリントを隠すために高品質な住宅プロキシの使用が含まれます。
CapSolverでセキュリティ障壁を乗り越える
AIスクリーピングにおける最大の課題の一つは、アンチボット防御の複雑さの増加です。ウェブサイトは現在、reCAPTCHA v3、Cloudflare Turnstile、AWS WAFを使用してデータを保護しています。これは、CapSolverのような専門的なソリューションが不可欠になる理由です。ミリ秒単位でこれらの課題を解決するAI駆動型APIを提供することで、AIスクリーパーは最も得意とする価値抽出に集中できます。AI-LLMによるCAPTCHA解決を統合することで、自動化されたエージェントが「Verify you are human」という壁に詰まることがありません。
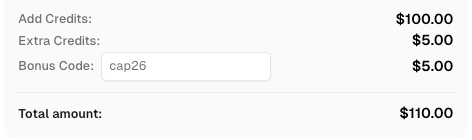
CapSolverに登録する際、コード
CAP26を使用してボーナスクレジットを取得してください!
結論
AIスクリーピングはトレンドではなく、ウェブデータとどのように関係するかの必然的な進化です。CapSolverのような信頼性の高いツールとLLMの意味的力の組み合わせにより、組織はこれまでになく速く、賢く、耐性のあるデータパイプラインを構築できます。2026年が進むにつれて、従来のスクリプトを使用する人とAIを活用する人の間のギャップはさらに広がるでしょう。今こそ、インフラをアップグレードし、知的なデータ抽出の未来を受け入れる時です。
FAQ
1. AIスクリーピングは合法ですか?
公開されているデータのスクリーピングは一般的に合法ですが、ウェブサイトの利用規約とGDPRなどのデータプライバールールに準拠する必要があります。最近の判例、例えばMeta vs. Bright Data 2024では、契約上の制限を尊重することが重要であることが強調されています。
2. AIスクリーピングはCAPTCHAをどう処理しますか?
AIスクリーパーは、CapSolverなどのサードパーティAPIと統合し、reCAPTCHAやCloudflare Turnstileなどの複雑な課題を自動的に解決する機械学習モデルを使用します。
3. AIスクリーピングを使用するにはプログラミングの知識が必要ですか?
ある程度の技術的知識は役立ちますが、多くの現代的なAIスクリーピングツールは、プレーンテキストで要件を記述できるノーコードまたはローコードインターフェースを提供しています。
4. クラウラーとスクリーパーの主な違いは何ですか?
クラウダー(例: Googlebot)はページをインデックスするためにウェブをナビゲートし、スクリーパーはそのページから特定のデータポイントを抽出します。AIは両方をより「人間らしい」方法で強化します。
5. AIスクリーピングは画像やPDFを処理できますか?
はい、AIスクリーパーはコンピュータビジョンとOCR(光学文字認識)を使用して、非テキスト形式からテキストとデータを抽出します。従来のスクリーパーはこれができません。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
