ウェブスクリーニングにおけるキャプチャの解決 | セレニウムとパイソンによるウェブスクリーニング

Sora Fujimoto
AI Solutions Architect
インターネットから必要なデータを手動でブラウズしたりコピー&ペーストしたりすることなく、簡単に取得できます。それがウェブスクレイピングの魅力です。データアナリスト、マーケットリサーチャー、または開発者であっても、ウェブスクレイピングは自動化されたデータ収集の新しい世界を開きます。
データ駆動型の時代において、情報は力です。しかし、数百乃至数千のウェブページから情報を手動で抽出するのは、時間のかかるだけでなく、エラーも起こりやすい作業です。幸い、ウェブスクレイピングは効率的で正確な解決策を提供し、インターネットから必要なデータを自動化して抽出することができ、これにより効率とデータ品質が大幅に向上します。
目次
ウェブスクレイピングとは何か?
ウェブスクレイピングは、プログラムを書くことでウェブページから情報を自動的に抽出する技術です。この技術は、データ分析、マーケットリサーチ、競合情報、コンテンツ集約など多くの分野で広く応用されています。ウェブスクレイピングにより、手動操作に頼らずに短時間で多数のウェブページからデータを収集・統合することが可能です。
ウェブスクレイピングのプロセスには通常以下のステップが含まれます:
- HTTPリクエストを送信: 目的のウェブサイトにリクエストをプログラム的に送信し、ウェブページのHTMLソースコードを取得します。Pythonのrequestsライブラリなど、一般的なツールはこれを簡単に実行できます。
- HTMLコンテンツの解析: HTMLソースコードを取得した後、必要なデータを抽出するために解析する必要があります。BeautifulSoupやlxmlなどのHTMLパーサーを使用してHTML構造を処理できます。
- データの抽出: 解析されたHTML構造に基づいて、特定のコンテンツを検索して抽出します。例えば、記事のタイトル、価格情報、画像リンクなどです。一般的な方法にはXPathやCSSセレクターを使用する方法があります。
- データの保存: 抽出されたデータを、データベース、CSVファイル、JSONファイルなどの適切な保存媒体に保存し、後の分析や処理に備えます。
Seleniumなどのツールを使用することで、ユーザーのブラウザ操作をシミュレートし、いくつかのアンチクローラー機構を回避して、ウェブスクレイピングタスクをより効率的に完了できます。
CapSolverのボーナスコードを引き換える
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAPN を使用すると、毎回 5%のボーナス を獲得できます — 制限なし。
CapSolverダッシュボードで今すぐ引き換えてください
.
Seleniumで始める
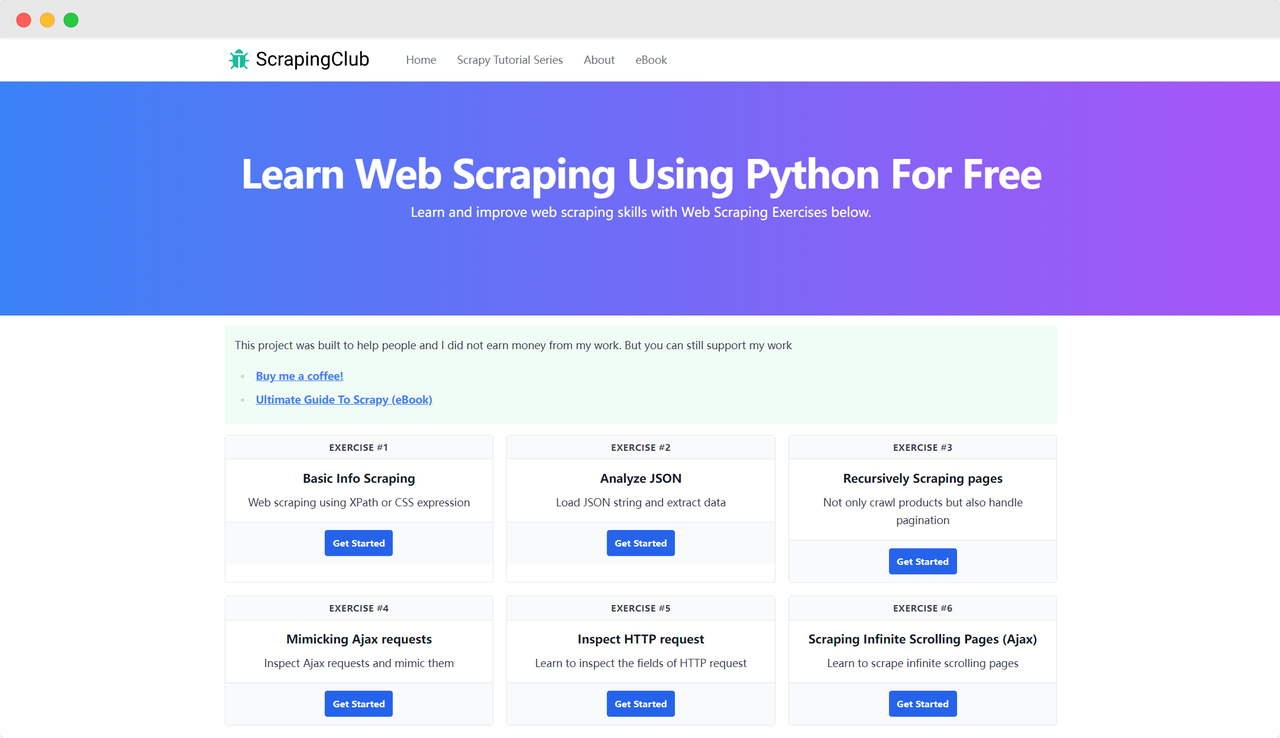
ScrapingClubを例にし、Seleniumを使用して演習1を完了します。
準備
まず、ローカルマシンにPythonがインストールされていることを確認する必要があります。Pythonのバージョンを確認するには、ターミナルで次のコマンドを入力してください:
bash
python --versionPythonのバージョンが3以上であることを確認してください。インストールされていない場合やバージョンが古い場合は、Python公式サイトから最新バージョンをダウンロードしてください。次に、以下のコマンドでseleniumライブラリをインストールする必要があります:
bash
pip install seleniumライブラリのインポート
python
from selenium import webdriverページにアクセスする
Seleniumを使ってGoogle Chromeを操作してページにアクセスするのは簡単です。Chromeオプションオブジェクトを初期化した後、get()メソッドを使用してターゲットページにアクセスできます:
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()起動パラメータ
Chromeオプションには、データ取得の効率を向上させる多くの起動パラメータを追加できます。パラメータの完全なリストは公式サイトで確認できます: Chromiumコマンドラインスイッチ一覧。以下に一般的に使用されるパラメータを示します:
| パラメータ | 目的 |
|---|---|
| --user-agent="" | リクエストヘッダーのUser-Agentを設定 |
| --window-size=xxx,xxx | ブラウザの解像度を設定 |
| --start-maximized | 最大化された解像度で実行 |
| --headless | ヘッドレスモードで実行 |
| --incognito | シークレットモードで実行 |
| --disable-gpu | GPUハードウェアアクセラレーションを無効化 |
例: ヘッドレスモードで実行する
python
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()ページ要素の検索
データをスクレイピングするには、DOM内の対応するHTML要素を見つける必要があります。Seleniumはページ上の要素を検索するための2つの主要な方法を提供します:
find_element: 条件に合致する単一の要素を検索します。find_elements: 条件に合致するすべての要素を検索します。
これらのメソッドは8つの異なる方法でHTML要素を検索できます:
| メソッド | 意味 | HTML例 | Selenium例 |
|---|---|---|---|
| By.ID | 要素IDで検索 | <form id="loginForm">...</form> |
driver.find_element(By.ID, 'loginForm') |
| By.NAME | 要素名で検索 | <input name="username" type="text" /> |
driver.find_element(By.NAME, 'username') |
| By.XPATH | XPathで検索 | <p><code>My code</code></p> |
driver.find_element(By.XPATH, "//p/code") |
| By.LINK_TEXT | リンクテキストで検索 | <a href="continue.html">Continue</a> |
driver.find_element(By.LINK_TEXT, 'Continue') |
| By.PARTIAL_LINK_TEXT | 部分的なリンクテキストで検索 | <a href="continue.html">Continue</a> |
driver.find_element(By.PARTIAL_LINK_TEXT, 'Conti') |
| By.TAG_NAME | タグ名で検索 | <h1>Welcome</h1> |
driver.find_element(By.TAG_NAME, 'h1') |
| By.CLASS_NAME | クラス名で検索 | <p class="content">Welcome</p> |
driver.find_element(By.CLASS_NAME, 'content') |
| By.CSS_SELECTOR | CSSセレクターで検索 | <p class="content">Welcome</p> |
driver.find_element(By.CSS_SELECTOR, 'p.content') |
ScrapingClubのページに戻り、演習1の「Get Started」ボタン要素を検索するコードを書きます:
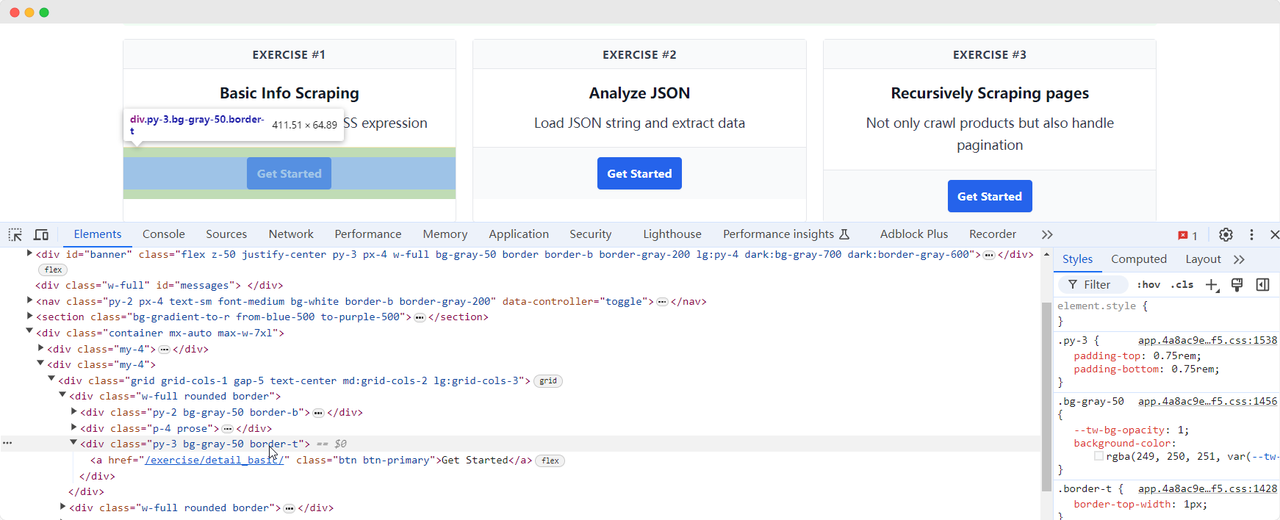
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
time.sleep(5)
driver.quit()要素とのインタラクション
「Get Started」ボタン要素を検索した後、次のページに進むためにボタンをクリックする必要があります。これは要素とのインタラクションです。Seleniumはいくつかのメソッドを提供し、アクションをシミュレートします:
click(): 要素をクリック;clear(): 要素の内容をクリア;send_keys(*value: str): キーボード入力をシミュレート;submit(): フォームを送信;screenshot(filename): ページのスクリーンショットを保存。
より詳細なインタラクションについては、公式ドキュメントを参照してください: WebDriver API。ScrapingClubの演習コードを引き続き改善し、クリックインタラクションを追加します:
python
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
time.sleep(5)
driver.quit()データ抽出
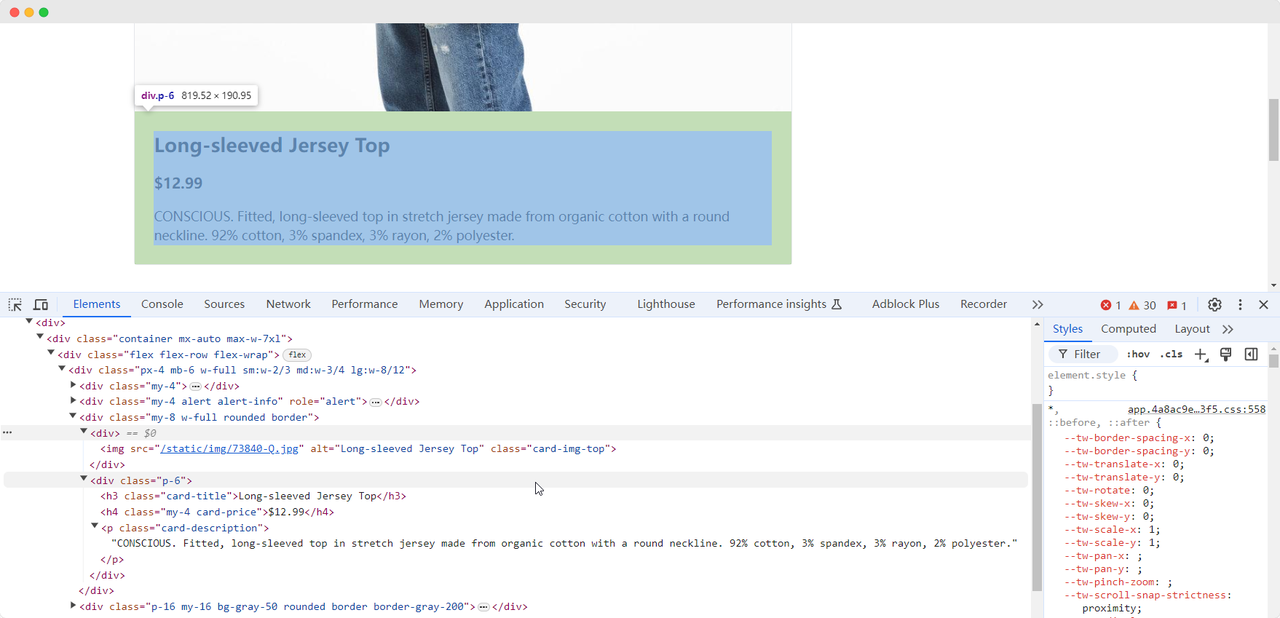
最初の演習ページに到達した後、製品の画像、名前、価格、説明情報を収集する必要があります。これらの要素を検索し、抽出するにはさまざまな方法を使用できます:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'製品名: {product_name}')
print(f'製品画像: {product_image}')
print(f'製品価格: {product_price}')
print(f'製品説明: {product_description}')
driver.quit()このコードは次の内容を出力します:
製品名: Long-sleeved Jersey Top
製品画像: https://scrapingclub.com/static/img/73840-Q.jpg
製品価格: $12.99
製品説明: CONSCIOUS. 伸縮性のあるオーガニックコットン製の長袖セーターで、ラウンドネック。92%コットン、3%スパンドレックス、3%レーヨン、2%ポリエステル。要素の読み込みを待つ
ネットワークの問題や他の理由により、Seleniumが実行を終了したときに要素がまだ読み込まれていない場合があります。これにより、データ収集が失敗することがあります。この問題を解決するには、特定の要素が完全に読み込まれるまで待機するように設定できます。以下に例を示します:
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
# 製品画像要素が完全に読み込まれるのを待つ
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.card-img-top')))
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'製品名: {product_name}')
print(f'製品画像: {product_image}')
print(f'製品価格: {product_price}')
print(f'製品説明: {product_description}')
driver.quit()アンチスクレイピング保護を回避する
ScrapingClubの演習は簡単に完了できます。しかし、実際のデータ収集シナリオでは、データ取得がそれほど簡単ではありません。一部のウェブサイトはアンチスクレイピング技術を使用しており、スクリプトをボットとして検出し、収集をブロックする可能性があります。最も一般的な状況はCAPTCHAチャレンジです
これらのCAPTCHAチャレンジを解決するには、機械学習、逆エンジニアリング、ブラウザのファイントラッキング対策に関する豊富な経験が必要です。これは多くの時間を要します。幸い、今ではすべての作業を自分で行う必要はありません。CapSolverは、すべてのチャレンジを回避するための完全なソリューションを提供します。CapSolverは、Seleniumを使用してデータを収集する際に自動的にCAPTCHAチャレンジを解決するブラウザ拡張機能を提供しています。さらに、CAPTCHAを解決し、トークンを取得するためのAPIメソッドも提供しており、すべてが数秒で完了します。詳細はCapSolverドキュメントを参照してください。
結論
製品の詳細を抽出し、複雑なアンチスクレイピング対策を乗り越えることから、Seleniumを使用したウェブスクレイピングは自動化されたデータ収集の広大な領域を開きます。ウェブの進化し続ける環境を歩む中で、CapSolverなどのツールは、よりスムーズなデータ抽出の道を開き、かつて formidable だった課題を過去のものにします。したがって、データ愛好家であっても、熟練した開発者であっても、これらの技術を活用することで効率を向上させ、データ駆動型の洞察が簡単に得られる世界を開くことができます。
FAQ
1. ウェブスクレイピングはどのような目的で使用されますか?
ウェブスクレイピングは、ウェブページから自動的に情報を抽出するために使用されます。これは開発者、アナリスト、および企業が、手動でのコピーなしで商品データ、価格、記事、画像、レビュー、およびその他のオンライン情報を一括して収集できるようにし、効率とデータの正確性を大幅に向上させます。
2. なぜrequestsやBeautifulSoupではなくSeleniumを使用するのですか?
requestsやBeautifulSoupは静的ウェブページに適していますが、多くの現代的なウェブサイトはJavaScriptでコンテンツを読み込みます。Seleniumは本物のブラウザをシミュレートし、動的ページのスクレイピング、ボタンのクリック、スクロール、要素とのインタラクション、および簡単なスクレイピング防止策の回避を可能にします—複雑なシナリオに最適です。
3. ログインやユーザー操作を必要とするウェブサイトをSeleniumでスクレイピングできますか?
はい。Seleniumはボタンのクリック、テキストの入力、ページのナビゲーション、クッキーまたはセッションの管理などのインタラクションを実行でき、ログインフォームやユーザー作業の裏にあるページのスクレイピングに適しています。
4. データをスクレイピングする際、CAPTCHAをどう対処すればいいですか?
CAPTCHAはSeleniumスクリプトを停止する可能性のある一般的なボット防止メカニズムです。手動で解く代わりに、APIやブラウザ拡張経由で自動CAPTCHA解決を提供するCapSolverなどのソリューションを統合できます。これにより、スクレイピングプロセスを妨げずに続けられます。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
