ウェブスクレイピング on Linux: ツール、設定と実践ガイド

Sora Fujimoto
AI Solutions Architect
TL;DR
- Linuxは、安定性、cronスケジューリング、低オーバーヘッドのため、本格的なウェブスクレイピングの主要なプラットフォームです。
- カーネルPythonスクレイピングツール—Requests、BeautifulSoup、Scrapy、Playwright—はそれぞれ異なる使用シナリオに適しています。
- 大規模なデータ抽出にはプロキシローテーションが不可欠です。IPベースのレートリミットを回避するためです。
- CAPTCHAチャレンジは自動化されたパイプラインの一般的な障害物です。CapSolverのAPIは1〜5秒でプログラム的に解決します。
- Linuxでの完全なデータ抽出パイプラインは、スケジューリング(cron)、ストレージ(SQLite/PostgreSQL)、プロキシ管理、CAPTCHA処理を組み合わせたものです。
- 常に責任を持ってスクレイピングしてください:
robots.txtを尊重し、リクエストのレートリミットを守り、適用可能なデータ保護法に準拠してください。
はじめに
Linuxは、大規模なウェブスクレイピングを実行する開発者にとって最適なプラットフォームです。ネイティブなcronスケジューリング、最小限のリソースオーバーヘッド、そして成熟したPythonエコシステムにより、長期にわたる自動化されたデータ抽出パイプラインにはWindowsやmacOSよりもはるかに実用的です。このガイドでは、2025年のLinuxでのウェブスクレイピングを構築するための環境設定、ツール選択、プロキシ設定、CAPTCHA処理、パイプラインアーキテクチャについて説明します。
なぜLinuxがウェブスクレイピングの最適なプラットフォームなのか
W3Techsのサーバーオペレーティングシステム統計によると、世界中のウェブサーバーの80%以上をLinuxが駆動しています。この支配的な地位は偶然ではありません。Linuxは、あらゆる規模のウェブスクレイピングに最適なネイティブな機能を備えています。
スクレイピング作業における主な利点:
- cronスケジューリング — 第三者ツールなしで任意の間隔でスクレイピングスクリプトを自動化できます。
- 低メモリ使用量 — 低スペックのハードウェアでヘッドレスブラウザと複数のワーカーを同時に実行できます。
- パッケージ管理 —
apt、pip、condaで依存関係管理をクリーンで再現可能な状態に保つことができます。 - SSHアクセス — グラフィカルインターフェースなしでリモートスクレイピングサーバーを管理できます。
- 安定性 — 長時間実行されるジョブは、OSレベルのイベントによって中断される可能性がはるかに低くなります。
- ネイティブなCLIツール —
wget、curl、grep、sed、awkは、Linux.comのウェブスクレイピングガイドに記載されているように、ターミナルから直接軽量なスクレイピングタスクを処理できます。
AWS EC2、DigitalOcean、Linodeなどの多くのクラウドVPSプロバイダーはUbuntuやDebianをデフォルトとしているため、Linuxは本格的なデータ抽出パイプラインにとって自然なデプロイメントターゲットです。
Linuxスクレイピング環境のセットアップ
一度もスクレイピングコードを書く前に、クリーンで隔離された環境をセットアップしてください。
ステップ1 — Pythonとpipのインストール
現代の多くのLinuxディストリビューションはPython 3を標準で提供しています。バージョンを確認してください:
bash
python3 --version
pip3 --versionpipが見つからない場合:
bash
sudo apt update && sudo apt install python3-pip -yステップ2 — 仮想環境の作成
依存関係の隔離により、プロジェクト間でのバージョンの競合を防ぎます:
bash
python3 -m venv scraper-env
source scraper-env/bin/activateステップ3 — コアスクレイピングライブラリのインストール
bash
pip install requests beautifulsoup4 scrapy playwright lxml
playwright install chromiumステップ4 — サポートツールのインストール
bash
pip install pandas sqlalchemy psycopg2-binary fake-useragentこのベースラインは静的ページスクレイピング、JavaScriptレンダリング、データストレージをカバーしており、あらゆるLinuxでのウェブスクレイピングワークフローの3本柱です。
Pythonスクレイピングツール: どれを選ぶべきか
適切なツールの選択は、ターゲットサイトの複雑さとスループットの要件に依存します。以下の表は、Linux環境で使用される主要なPythonスクレイピングツールの要約です。
比較要約
| ツール | 最適な用途 | JavaScriptレンダリング | 速度 | 学習曲線 |
|---|---|---|---|---|
| Requests | 簡単なHTTPリクエスト、静的ページ | ✗ | 速い | 低い |
| BeautifulSoup | HTML/XMLの解析(Requestsと併用) | ✗ | 速い | 低い |
| Scrapy | 大規模で繰り返しのクロール | ✗(プラグイン経由) | 非常に速い | 中程度 |
| Playwright | 動的なJavaScript重視ページ | ✓ | 中程度 | 中程度 |
| Selenium | 旧式の自動化、JavaScriptページ | ✓ | 遅い | 中程度 |
Requests + BeautifulSoupは、Linuxでのウェブスクレイピングの標準的なエントリポイントです。最小限の設定で静的ページの大部分を処理でき、ゼロから作業可能なスクレイパーへの最速の道です。
Scrapyは、本格的な定期的なデータ抽出パイプラインに最適です。クッキー、セッション、圧縮、認証、キャッシュ、robots.txtを標準で処理し、ミドルウェアアーキテクチャによりカスタムプロキシローテーションとCAPTCHA処理をサポートします。Scrapyは2025年現在、GitHubで52,000以上のスターを獲得しており、広く採用されているPythonスクレイピングフレームワークの一つです(Scrapy on GitHub)。実際のシナリオでのこれらのツールの比較については、ウェブスクレイピングツールの説明を参照してください。
Playwrightは、JavaScriptレンダリングが必要な場合のSeleniumの現代的な代替です。Linux上でネイティブにヘッドレスChromiumを実行し、非同期実行をサポートし、動的コンテンツに対してははるかに高速です。ブラウザ自動化のアプローチの詳細な比較については、nodriver vs 伝統的なブラウザ自動化ツールをご覧ください。
Linuxウェブスクレイピングにおけるプロキシの使用
Linuxでの本格的なウェブスクレイピングにはプロキシローテーションが不可欠です。これがないと、比較的少ないリクエスト数でスクレイパーのIPアドレスがレートリミットまたはブロックされる可能性があります。ISPによって割り当てられた静的住宅プロキシは、本物のユーザー行動をシミュレートするため、検出される可能性を減らすために特に効果的です。これは、Linux Securityのエチカルスクレイピングに関するガイドに記載されています。
プロキシの種類
| タイプ | 検出リスク | コスト | 最適な用途 |
|---|---|---|---|
| データセンター | 高 | 低 | スピードに敏感で保護が少ないターゲット |
| 住宅 | 低 | 中程度 | 中程度のボット検出を持つサイト |
| ローテーション住宅 | 非常に低 | 高 | 大量かつ継続的なパイプライン |
Python Requestsでのプロキシ設定
python
import requests
proxies = {
"http": "http://username:password@proxy-host:port",
"https": "http://username:password@proxy-host:port",
}
response = requests.get("https://example.com", proxies=proxies)
print(response.status_code)Scrapyでのプロキシ設定
settings.pyで:
python
ROTATING_PROXY_LIST = [
"http://proxy1:port",
"http://proxy2:port",
]自動プール管理にはscrapy-rotating-proxiesミドルウェアを使用してください。
最適な実践方法
fake-useragentを用いてIPローテーションとともにユーザーエージェント文字列をローテーションしてください。- リクエスト間にランダムな遅延を追加:
time.sleep(random.uniform(1, 3))。 - プロキシの健全性を監視し、自動的に動作しないIPをプールから削除してください。
- TLS検査を強制するサイトではHTTPSプロキシを使用してください。
Linuxでのウェブスクレイピングと互換性のあるプロキシプロバイダーの一覧については、ウェブスクレイピングに最適なプロキシサービスが役立ちます。
データ抽出パイプラインでのCAPTCHA処理
CAPTCHAチャレンジは、Linuxでの本格的なウェブスクレイピングにおいて最も一般的な障害物です。サイトはreCAPTCHA v2/v3、hCaptcha、Cloudflare Turnstile、その他のチャレンジを特に自動化されたデータ抽出パイプラインを妨げるために導入しています。CapSolverのreCAPTCHA v2インテグレーションガイドによると、reCAPTCHA v2は世界中で500万以上のウェブサイトで使用されています。
CAPTCHAを手動で解決するのはスケーラブルではありません。実用的な解決策は、スクレイピングワークフローに直接プログラム可能なCAPTCHA解決APIを統合することです。CapSolverは、reCAPTCHA、hCaptcha、Cloudflare Turnstile、GeeTest、AWS WAF、その他のチャレンジタイプをREST API経由で解決するAI駆動のサービスです。通常、1〜5秒で有効なトークンを返します—人間の介入なしで。
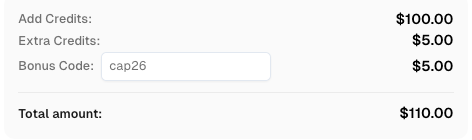
CapSolverのボーナスコードを取得する
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、毎回チャージするたびに 5%のボーナス を受け取れます—制限なし。
今すぐCapSolverダッシュボードでボーナスコードを取得してください。
CapSolverの仕組み
- スクレイパーがターゲットページでCAPTCHAを検出します。
- サイトURLとサイトキーをCapSolverの
createTaskエンドポイントに送信します。 - CapSolverのAIモデルがチャレンジを解決し、トークンを返します。
- トークンをフォーム送信またはリクエストヘッダーに挿入します。
- スクレイパーは中断することなく継続します。
Python統合例(reCAPTCHA v2 — プロキシなし)
以下の例はCapSolverの公式APIドキュメントに基づいています:
python
import requests
import time
# あなたのCapSolver APIキー
API_KEY = "YOUR_CAPSOLVER_API_KEY"
WEBSITE_URL = "https://example.com"
WEBSITE_KEY = "YOUR_RECAPTCHA_SITE_KEY"
def create_task():
payload = {
"clientKey": API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": WEBSITE_URL,
"websiteKey": WEBSITE_KEY,
}
}
response = requests.post(
"https://api.capsolver.com/createTask",
json=payload
)
return response.json().get("taskId")
def get_task_result(task_id):
payload = {
"clientKey": API_KEY,
"taskId": task_id,
}
while True:
response = requests.post(
"https://api.capsolver.com/getTaskResult",
json=payload
)
result = response.json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
time.sleep(2)
task_id = create_task()
token = get_task_result(task_id)
print("CAPTCHAトークン:", token)このトークンは、フォームのg-recaptcha-responseフィールドに挿入され、スクレイパーがCAPTCHAゲートを通過できるようになります。プロキシベースのタスクの場合、タスクタイプをReCaptchaV2Taskに切り替えて、ペイロードにプロキシ情報を追加してください。
CapSolverは2つのタスクモードをサポートしています:
ReCaptchaV2TaskProxyLess— CapSolverの独自インフラを使用; 設定が簡単。ReCaptchaV2Task— 自分のプロキシを使用; 严格的な地理制限があるサイトに最適。
reCAPTCHA v3、Cloudflare Turnstile、AWS WAFを含むサポートされているタスクタイプの完全なリストについては、CapSolverタスクタイプドキュメントをご覧ください。
Linuxでの完全なデータ抽出パイプラインの構築
Linuxでの本格的なウェブスクレイピング設定は、単一のスクリプトよりも複数のステージを組み合わせたパイプラインです。
パイプラインアーキテクチャ
[スケジューラー: cron]
→ [スクレイパー: Scrapy / Playwright]
→ [プロキシレイヤー: ローテーション住宅]
→ [CAPTCHAハンドラー: CapSolver API]
→ [パーサー: BeautifulSoup / lxml]
→ [ストレージ: SQLite / PostgreSQL]
→ [エクスポート: CSV / JSON / REST API]cronでのスケジューリング
毎時間にスクレイピングジョブを実行するようにcrontabを編集してください:
bash
crontab -e以下の行を追加してください:
0 * * * * /home/user/scraper-env/bin/python /home/user/scraper/run.py >> /home/user/scraper/logs/scrape.log 2>&1抽出されたデータの保存
小規模なプロジェクトにはSQLiteが十分です:
python
import sqlite3
conn = sqlite3.connect("data.db")
cursor = conn.cursor()
cursor.execute(
"CREATE TABLE IF NOT EXISTS products (name TEXT, price TEXT, url TEXT)"
)
cursor.execute(
"INSERT INTO products VALUES (?, ?, ?)", (name, price, url)
)
conn.commit()
conn.close()より大規模なパイプラインには、SQLAlchemyを使用したPostgreSQLが、より良い並行性とクエリパフォーマンスを提供します。
ロギングとエラー処理
常にスクレイピング活動をロギングしてください。Pythonの組み込みloggingモジュールを使用してください:
python
import logging
logging.basicConfig(
filename="scrape.log",
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s"
)
logging.info("スクレイピングを開始")構造化されたロギングにより、長時間実行されるLinuxでのウェブスクレイピングジョブでプロキシエラーとCAPTCHAタイムアウトを含む失敗のデバッグがはるかに簡単になります。
コンプライアンスと責任あるスクレイピング
Linuxでのウェブスクレイピングは強力な機能ですが、責任を持って使用する必要があります。
robots.txtを確認してください — スクレイピングする前に常にhttps://example.com/robots.txtを確認してください。Disallowディレクティブを尊重してください。- レートリミット — サーバーを過負荷にしないでください。リクエスト間に遅延を追加して、サイトのパフォーマンスを低下させないでください。
- 利用規約 — ターゲットサイトの利用規約を確認してください。一部のサイトでは自動データ収集が明確に禁止されています。
- 個人データ — あらゆる適用可能な規制(例: GDPR)に基づく法的根拠なしに個人識別情報を収集しないでください。
- コピーライト — 抽出されたコンテンツは著作権で保護されている可能性があります。データを分析に使用し、再公開には使用しないでください。
責任あるスクレイピングは倫理的な考慮だけでなく、法的な考慮でもあります。自動化されたデータ収集に関するフレームワークは進化し続けており、パイプラインの初期段階からコンプライアンスを組み込むことは、後で後付けするよりもはるかにコストが低くなります。
結論
Linuxでのウェブスクレイピングは、あらゆる規模のデータ抽出に安定性、スクリプタビリティ、コスト効率の良い基盤を提供します。ScrapyとPlaywrightなどのPythonスクレイピングツール、適切に設定されたプロキシレイヤー、プログラム可能なCAPTCHA解決サービスの組み合わせにより、本格的な環境で遭遇するあらゆる課題をカバーできます。クリーンな仮想環境から始め、ターゲットサイトの複雑さに基づいてツールを選択し、スケジューリング、ストレージ、エラー処理を含めてパイプラインを段階的に構築してください。
CAPTCHAチャレンジがスクリーピングワークフローを妨げている場合、CapSolverで始めましょう そして、AIを活用したCAPTCHA解決を数分でパイプラインに統合してください。
FAQ
Q1: Linuxでのウェブスクレイピングに最適なPythonライブラリはどれですか?
用途によります。静的ページの場合、RequestsとBeautifulSoupの組み合わせが最も高速で簡単なオプションです。大規模で繰り返しのスクレイピングが必要な場合、Scrapyが業界標準です。JavaScriptが豊富なページの場合、LinuxではPlaywrightが推奨されます。
Q2: Linuxでウェブスクレイパーを自動的に実行するにはどうすればよいですか?
cronジョブを使用してください。crontab -eでカrontabを編集し、スケジュールとPythonスクリプトのパスを指定する行を追加します。これにより、手動の介入なしに任意の間隔でスクレイパーが実行されます。
Q3: ウェブスクレイピングパイプラインでCAPTCHAをどう処理すればよいですか?
CapSolverなどのCAPTCHA解決APIを統合してください。スクレイパーはサイトURLとサイトキーをAPIに送信し、解決されたトークンを受け取り、リクエストに挿入します。このプロセスは完全に自動化されており、CAPTCHAに遭遇するたびに数秒の遅延しかかかりません。
Q4: Linuxでのウェブスクレイピングでプロキシは必須ですか?
小規模で頻度の低いスクレイピングタスクの場合、プロキシは必要ないかもしれません。大規模または継続的なデータ抽出パイプラインの場合、IPベースのレート制限やブロックを回避するためにローテーティングプロキシが不可欠です。
Q5: Linuxでのウェブスクレイピングは合法ですか?
公開されているデータに対して適用される限り、ウェブスクレイピング自体は一般的に合法です。ターゲットサイトのrobots.txt、利用規約、および関連するデータ保護法を尊重する必要があります。許可なく個人データや著作権のあるコンテンツをスクレイピングすると法的リスクがあります。