Scrapy と Selenium: あなたのウェブスクレイピングプロジェクトにどちらが最適か

Nikolai Smirnov
Software Development Lead

TL;DR
ScrapyとSeleniumは、それぞれ異なる使用ケースに適した人気のあるウェブスクレイピングツールです。Scrapyは、静的ウェブサイトの大規模なスクレイピングに最適な高速で軽量でスケーラブルなPythonフレームワークです。一方、Seleniumは実際のブラウザを自動化し、ユーザーの操作が必要な動的でJavaScriptが豊富なページのスクレイピングに優れています。正しい選択は、プロジェクトの複雑さ、パフォーマンス要件、および操作の必要性に依存します。どちらのツールもCapSolverなどのサービスを介してCAPTCHAチャレンジに直面する可能性があります。
イントロダクション
ウェブスクレイピングは、インターネットからデータを収集するための重要な技術であり、開発者、研究者、および企業にとってますます人気があります。ウェブスクレイピングに最も一般的に使用されるツールの2つはScrapyとSeleniumです。それぞれに強みと弱みがあり、異なる種類のプロジェクトに適しています。この記事では、ScrapyとSeleniumを比較し、あなたのウェブスクレイピングのニーズに最適なツールを決定するお手伝いをします。
Scrapyとは何か
Scrapyは、Pythonで書かれた強力で高速なオープンソースのウェブクローリングフレームワークです。これは、ウェブページをスクレイピングし、それらから構造化されたデータを抽出することを目的としています。Scrapyは非常に効率的で、スケーラブルでカスタマイズ可能であり、大規模なウェブスクレイピングプロジェクトに最適な選択肢です。
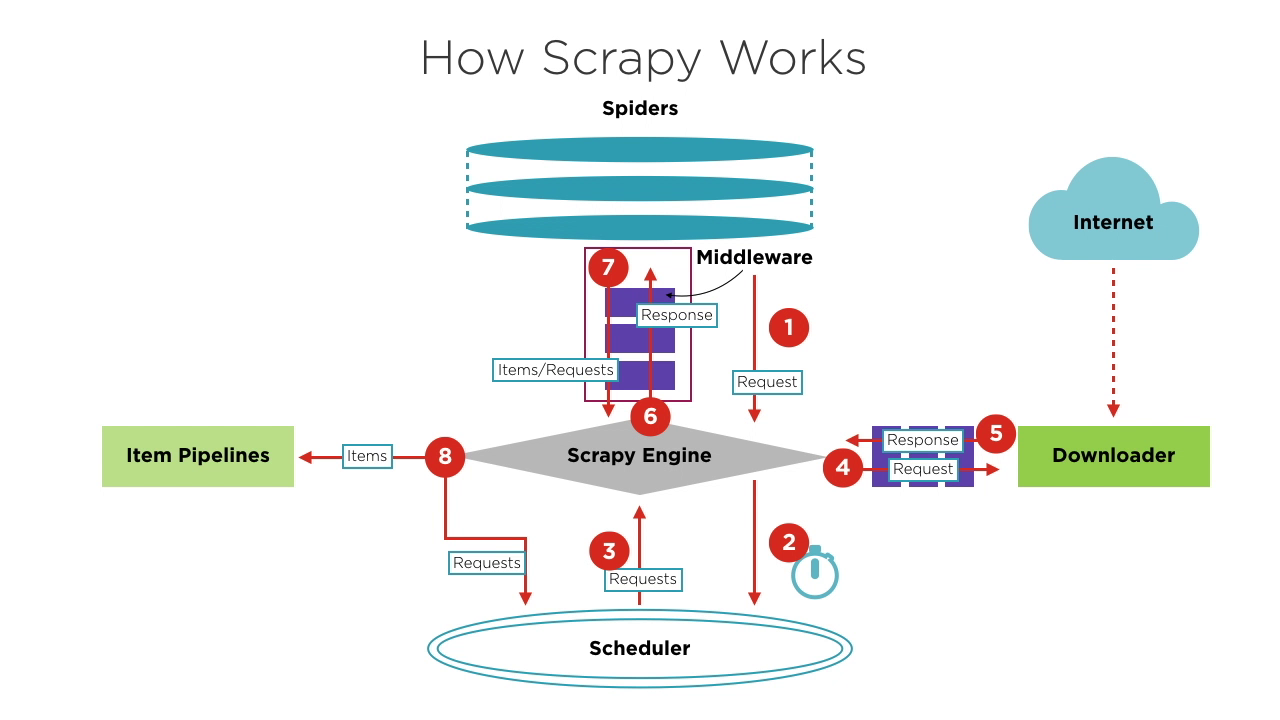
Scrapyのコンポーネント
- Scrapy Engine: フレームワークのコアで、システム内のデータフローとイベントを管理します。脳のようなもので、データ転送と論理処理を担当します。
- Scheduler: エンジンからリクエストを受け取り、キューに格納し、ダウンローダーが実行するようにエンジンに戻します。スケジューリングロジック(FIFO(先入れ先出し)、LIFO(後入れ先出し)、優先度キューなど)を維持します。
- Spiders: スクレイピングとページの解析のロジックを定義します。各スパイダーは、レスポンスの処理、アイテムの生成、エンジンに送信する新しいリクエストを担当します。
- Downloader: サーバーにリクエストを送信し、レスポンスを受信します。その後、エンジンに返します。
- Item Pipelines: スパイダーによって抽出されたアイテムを処理し、データのクリーニング、検証、保存などのタスクを実行します。
- Middlewares:
- Downloader Middlewares: エンジンとダウンローダーの間に配置され、リクエストとレスポンスを処理します。
- Spider Middlewares: エンジンとスパイダーの間に配置され、アイテム、リクエスト、およびレスポンスを処理します。
繰り返し失敗する煩わしいCAPTCHAを完全に解決することができない問題に悩んでいませんか?CapSolverのAIを駆使した自動ウェブアンロック技術で、スムーズな自動CAPTCHA解決を体験してください!
自動化予算を即座に増やす!
CapSolverアカウントにチャージする際にボーナスコードCAPNを使用すると、毎回のチャージで5%のボーナスが追加されます—制限なし。
今すぐCapSolverダッシュボードで交換してください。
.
Scrapyプロジェクトの基本的なワークフロー
-
クローリングプロジェクトを開始する際、エンジンはクロール対象のサイトに基づいて対応するスパイダーを見つけてきます。スパイダーは、クロールする必要があるページに対応する1つ以上の初期リクエストを生成し、それをエンジンに送信します。
-
エンジンはスパイダーからこれらのリクエストを取得し、スケジューラーに送信してスケジューリングを待ちます。
-
エンジンは次の処理するリクエストをスケジューラーに要求します。この時点で、スケジューラーはスケジューリングロジックに基づいて適切なリクエストを選択し、エンジンに送信します。
-
エンジンはスケジューラーからリクエストをダウンローダーに転送してダウンロードを実行します。リクエストをダウンローダーに送信するプロセスは、多くの事前に定義されたダウンローダーミドルウェアの処理を通ります。
-
ダウンローダーはリクエストを対象のサーバーに送信し、対応するレスポンスを受信してエンジンに返します。レスポンスをエンジンに返すプロセスも、多くの事前に定義されたダウンローダーミドルウェアの処理を通ります。
-
エンジンがダウンローダーから受け取ったレスポンスには、対象サイトのコンテンツが含まれています。エンジンはこのレスポンスを対応するスパイダーに送信します。レスポンスをスパイダーに送信するプロセスは、事前に定義されたスパイダーミドルウェアの処理を通ります。
-
スパイダーはレスポンスを処理し、コンテンツを解析します。この時点で、スパイダーは1つ以上のクロール結果のアイテムまたは後続のクロール対象ページに対応する1つ以上のリクエストを生成します。その後、これらのアイテムまたはリクエストをエンジンに送信します。アイテムまたはリクエストをエンジンに送信するプロセスは、事前に定義されたスパイダーミドルウェアの処理を通ります。
-
エンジンはスパイダーから戻された1つ以上のアイテムを事前に定義されたアイテムパイプラインに転送し、一連のデータ処理または保存操作を実行します。スパイダーから戻された1つ以上のリクエストは、スケジューラーに転送され、次のスケジューリングを待ちます。
ステップ2からステップ8は、スケジューラーにリクエストがなくなるまで繰り返されます。この時点で、エンジンはスパイダーを終了し、すべてのクローリングプロセスが終了します。
全体的に見れば、各コンポーネントは1つの機能に焦点を当てており、コンポーネント間の結合は非常に低く、拡張が非常に簡単です。エンジンはさまざまなコンポーネントを組み合わせ、それぞれのコンポーネントが各自の役割を果たし、協力してクローリング作業を完了します。さらに、Scrapyの非同期処理のサポートにより、ネットワーク帯域を最大限に活用し、データクローリングと処理の効率を向上させることができます。
Seleniumとは何か?
Seleniumは、ウェブブラウザをプログラム的に制御できるオープンソースのウェブ自動化ツールです。主にウェブアプリケーションのテストに使用されますが、伝統的な方法ではスクレイピングが難しいJavaScriptが豊富なウェブサイトをスクレイピングするためにも人気があります。Seleniumはウェブアプリケーションのみをテストできる点に注意してください。デスクトップ(ソフトウェア)アプリケーションやモバイルアプリケーションをテストすることはできません。
SeleniumのコアはSelenium WebDriverであり、開発者がブラウザの動作と相互作用を制御するためのプログラミングインターフェースを提供します。このツールは、複数のブラウザをサポートし、異なるオペレーティングシステムで動作できるため、ウェブ開発とテストで非常に人気があります。Selenium WebDriverは、ブラウザでユーザーの操作をシミュレートできるようにします。例えば、ボタンのクリック、フォームの入力、ページのナビゲーションなどが可能です。
Selenium WebDriverは豊富な機能を備えており、ウェブ自動化テストに最適な選択肢です。
Selenium WebDriverの主な特徴
-
ブラウザ制御: Selenium WebDriverは、Chrome、Firefox、Safari、Edge、およびInternet Explorerなどの主要なブラウザをサポートしています。これらのブラウザを起動し、操作し、ウェブページを開く、要素をクリックする、テキストを入力する、スクリーンショットを撮るなどの操作が可能です。
-
クロスプラットフォーム互換性: Selenium WebDriverは、Windows、macOS、Linuxなどの異なるオペレーティングシステムで動作します。これは、マルチプラットフォームでのテストに非常に役立ち、開発者がアプリケーションがさまざまな環境で一貫して動作することを保証できます。
-
プログラミング言語サポート: Selenium WebDriverは、Java、Python、C#、Ruby、JavaScriptなどの複数のプログラミング言語をサポートしています。開発者は、慣れ親しんだ言語を使って自動テストスクリプトを書くことができ、開発とテストの効率を向上させます。
-
ウェブ要素の操作: Selenium WebDriverは、ウェブページの要素を検索および操作する豊富なAPIを提供します。ID、クラス名、タグ名、CSSセレクター、XPathなど、さまざまな方法で要素を検索できます。開発者はこれらのAPIを使用して、クリック、入力、選択、ドラッグアンドドロップなどの操作を実装できます。
ScrapyとSeleniumの比較
| 特徴 | Scrapy | Selenium |
|---|---|---|
| 目的 | ウェブスクレイピングのみ | ウェブスクレイピングとウェブテスト |
| 言語サポート | Pythonのみ | Java、Python、C#、Ruby、JavaScriptなど |
| 実行速度 | 高速 | 遅い |
| 拡張性 | 高い | 限られている |
| 非同期サポート | はい | いいえ |
| 動的レンダリング | いいえ | はい |
| ブラウザの操作 | いいえ | はい |
| メモリリソースの消費 | 低い | 高い |
ScrapyとSeleniumの選択
-
静的ウェブページで動的レンダリングが不要な場合、Scrapyを選択してください。
-
リソースの消費と実行速度を最適化する必要がある場合、Scrapyを選択してください。
-
膨大なデータ処理とカスタムミドルウェアが必要な場合、Scrapyを選択してください。
-
動的なコンテンツを含み、インタラクションが必要なターゲットウェブサイトの場合、Seleniumを選択してください。
-
実行効率とリソースの消費がそれほど心配しない場合、Seleniumを選択してください。
ScrapyとSeleniumのどちらを使用するかは、特定のアプリケーションシナリオに依存します。さまざまな選択肢の利点と欠点を比較し、自分に最も適したものを選ぶ必要があります。もちろん、プログラミングスキルが十分であれば、ScrapyとSeleniumを同時に使用することも可能です。
ScrapyとSeleniumの課題
ScrapyまたはSeleniumを使用する場合、同じ問題に直面する可能性があります。ボットチャレンジは、コンピュータと人間を区別し、ウェブサイトへの悪意のあるボットアクセスを防止し、データのスクレイピングを保護するために広く使用されています。一般的なボットチャレンジにはcaptcha、reCaptcha、captcha、captcha、Cloudflare Turnstile、captcha、captcha WAFなどがあります。これらは、複雑な画像や読みにくいJavaScriptチャレンジを使用して、あなたがボットかどうかを判断します。一部のチャレンジは、人間にとっても難しい場合があります。
「それぞれが自分の専門分野を持っています。」CapSolverの登場により、この問題は簡単になりました。CapSolverは、AIベースの自動ウェブアンロック技術を使用し、数秒でさまざまなボットチャレンジを解決するお手伝いをします。どんな画像や質問のチャレンジに遭遇しても、自信を持ってCapSolverに任せてください。失敗した場合は、料金はかかりません。
CapSolverは、Seleniumベースのデータスクレイピングプロセス中にCAPTCHAチャレンジを自動的に解決するブラウザ拡張機能を提供しています。また、CAPTCHAを解決し、トークンを取得するAPI方法も提供しており、Scrapyでさまざまなチャレンジを簡単に処理できます。すべての作業はわずか数秒で完了します。詳細については、CapSolverドキュメンテーションを参照してください。
結論
ScrapyとSeleniumの選択は、プロジェクトのニーズに依存します。Scrapyは静的サイトを効率的にスクレイピングするのに最適で、Seleniumは動的でJavaScriptが豊富なページで優れています。速度、リソースの使用、およびインタラクションのレベルなどの特定の要件を考慮してください。CAPTCHAなどの課題を乗り越えるために、CapSolverなどのツールが効率的なソリューションを提供し、スクレイピングプロセスをスムーズにします。最終的には、適切な選択が成功し、効率的なスクレイピングプロジェクトを確保します。
よくある質問
1. ScrapyとSeleniumは1つのプロジェクトで一緒に使用できますか?
はい。一般的なアプローチは、JavaScriptのレンダリングや複雑なインタラクション(ログインフローなど)をSeleniumで処理し、レンダリングされたHTMLまたは抽出されたURLをScrapyに渡して高速で大規模なクローリングとデータ抽出を行うことです。このハイブリッドモデルは、Seleniumの柔軟性とScrapyのパフォーマンスを組み合わせたものです。
2. Scrapyは現代のJavaScriptが豊富なウェブサイトに適していますか?
デフォルトでは、ScrapyはJavaScriptを実行しないので、クライアントサイドレンダリングに依存しているサイトには適していません。ただし、必要に応じてPlaywright、Splash、またはSeleniumなどのツールを使用してJavaScriptコンテンツを処理できるように拡張できます。
3. 大規模なスクレイピングにおいて、どちらのツールがよりリソース効率的ですか?
ScrapyはSeleniumよりもはるかにリソース効率的です。非同期ネットワーキングを使用し、ブラウザを起動する必要がないため、高ボリュームで大規模なスクレイピングタスクに適しています。Seleniumは実際のブラウザを制御するため、CPUとメモリを多く消費し、拡張性が制限されます。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。

Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
