DrissionPageをCapSolverと統合する方法:シームレスなCAPTCHA解決のため

Sora Fujimoto
AI Solutions Architect

1. はじめに
Webオートメーションはデータ収集、テスト、およびさまざまなビジネス操作において不可欠となっています。しかし、現代のウェブサイトは自動化スクリプトを妨げる高度なアンチボット対策とCAPTCHAを導入しており、最も丁寧に作成されたスクリプトでも停止することがあります。
DrissionPageとCapSolverの組み合わせは、この課題に対する強力な解決策を提供します。
- DrissionPage: WebDriverを必要とせず、Chromiumブラウザを制御するPythonベースのウェブオートメーションツール。ブラウザオートメーションとHTTPリクエストを組み合わせたものです。
- CapSolver: AIを駆動するCAPTCHA解決サービスで、Cloudflare Turnstile、reCAPTCHAなどに対応しています。
これらのツールを組み合わせることで、WebDriver検出とCAPTCHAの課題を回避したシームレスなウェブオートメーションが可能になります。
1.1. 統合目的
このガイドでは、以下の3つのコアゴールを達成するお手伝いをします。
- WebDriver検出を回避する - Selenium/WebDriverシグネチャなしでDrissionPageのネイティブブラウザ制御を使用する
- CAPTCHAを自動的に解決する - CapSolverのAPIを統合して、手動介入なしでCAPTCHAチャレンジを処理する
- 人間のような挙動を維持する - アクションチェーンと知的CAPTCHA解決を組み合わせる
2. DrissionPageとは?
DrissionPageは、ブラウザ制御とHTTPリクエスト機能を組み合わせたPythonベースのウェブオートメーションツールです。Seleniumとは異なり、WebDriverに依存せず、独自のカーネルを使用しているため、検出が難しいです。
2.1. 主な特徴
- WebDriver不要 - chromedriverなしでChromiumブラウザをネイティブに制御
- 二モード動作 - ブラウザオートメーション(dモード)とHTTPリクエスト(sモード)を組み合わせる
- 要素の検索が簡略化 - 直感的な構文で要素を検索
- クロス-iframeナビゲーション - フレームの切り替えなしにiframe間の要素を検索
- マルチタブサポート - 複数のタブを同時に操作
- アクションチェーン - マウスとキーボードのアクションを連鎖させる
- ビルトイン待機 - 不安定なネットワーク用の自動リトライメカニズム
2.2. インストール
bash
# DrissionPageのインストール
pip install DrissionPage
# CapSolver API用のrequestsライブラリのインストール
pip install requests2.3. 基本的な使い方
python
from DrissionPage import ChromiumPage
# ブラウザインスタンスの作成
page = ChromiumPage()
# URLに移動
page.get('https://wikipedia.org')
# 要素を検索し操作
page('#search-input').input('Hello World')
page('#submit-btn').click()3. CapSolverとは?
CapSolverは、幅広い種類のCAPTCHAをサポートするAI駆動の自動CAPTCHA解決サービスです。数秒でCAPTCHAチャレンジを送信し、解決策を受け取るシンプルなAPIを提供しています。
3.1. サポートされているCAPTCHAタイプ
- Cloudflare Turnstile - 最も一般的な現代のアンチボットチャレンジ
- Cloudflareチャレンジ
- reCAPTCHA v2 - イメージベースと非表示バージョン
- reCAPTCHA v3 - スコアベースの検証
- AWS WAF - アマゾンウェブサービスのCAPTCHA
- その他多くの種類...
3.2. CapSolverの使い方
- capsolver.comに登録
- アカウントに資金を追加
- ダッシュボードからAPIキーを取得
3.3. APIエンドポイント
- サーバーA:
https://api.capsolver.com - サーバーB:
https://api-stable.capsolver.com
4. 統合前の課題
DrissionPageとCapSolverを組み合わせる前に、ウェブオートメーションにはいくつかの問題点がありました。
| 課題 | 影響 |
|---|---|
| WebDriver検出 | Seleniumスクリプトが即座にブロックされる |
| CAPTCHAチャレンジ | 手動解決が必要で、オートメーションが中断される |
| iframeの複雑さ | ネストされたコンテンツと操作が難しい |
| マルチタブ操作 | 複雑なタブ切り替えロジックが必要 |
DrissionPage + CapSolverの統合は、これらの課題を一度に解決します。
5. 統合方法
5.1. API統合(推奨)
API統合アプローチは、CAPTCHA解決プロセスの完全な制御を提供し、あらゆる種類のCAPTCHAに対応しています。
5.1.1. 設定要件
bash
pip install DrissionPage requests5.1.2. コア統合パターン
python
import time
import requests
from DrissionPage import ChromiumPage
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def create_task(task_payload: dict) -> str:
"""CAPTCHA解決タスクを作成し、タスクIDを返します。"""
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": task_payload
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"CapSolverエラー: {result.get('errorDescription')}")
return result["taskId"]
def get_task_result(task_id: str, max_attempts: int = 120) -> dict:
"""タスク結果をポーリングし、解決またはタイムアウトまで待機します。"""
for _ in range(max_attempts):
response = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
)
result = response.json()
if result.get("status") == "ready":
return result["solution"]
elif result.get("status") == "failed":
raise Exception(f"タスク失敗: {result.get('errorDescription')}")
time.sleep(1)
raise TimeoutError("CAPTCHA解決がタイムアウトしました")
def solve_captcha(task_payload: dict) -> dict:
"""CAPTCHA解決ワークフローを完了します。"""
task_id = create_task(task_payload)
return get_task_result(task_id)5.2. ブラウザ拡張機能
DrissionPageでCapSolverのブラウザ拡張機能を使用することもできます。より手間の少ないアプローチが可能です。
5.2.1. インストール手順
- capsolver.com/en/extensionからCapSolver拡張機能をダウンロード
- 拡張機能のファイルを抽出
- 拡張機能の
config.jsファイルでAPIキーを設定してください:
javascript
// 拡張機能フォルダ内で編集: assets/config.js
var defined = {
apiKey: "YOUR_CAPSOLVER_API_KEY", // 実際のAPIキーに置き換えてください
enabledForBlacklistControl: false,
blackUrlList: [],
enabledForRecaptcha: true,
enabledForRecaptchaV3: true,
enabledForTurnstile: true,
// ... 他の設定
}- DrissionPageにロード:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.add_extension('/path/to/capsolver-extension')
page = ChromiumPage(co)
# 拡張機能が自動的にCAPTCHAを検出および解決します注意: 拡張機能は、自動的にCAPTCHAを解決する前に有効なAPIキーを設定する必要があります。
6. コード例
6.1. Cloudflare Turnstileの解決
Cloudflare Turnstileは最も一般的なCAPTCHAチャレンジの一つです。以下に解決方法を示します:
python
import time
import requests
from DrissionPage import ChromiumPage
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_turnstile(site_key: str, page_url: str) -> str:
"""Cloudflare Turnstileを解決し、トークンを返します。"""
# タスクを作成
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"エラー: {result.get('errorDescription')}")
task_id = result["taskId"]
# 結果をポーリング
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["token"]
elif result.get("status") == "failed":
raise Exception(f"失敗: {result.get('errorDescription')}")
time.sleep(1)
def main():
target_url = "https://your-target-site.com"
turnstile_site_key = "0x4XXXXXXXXXXXXXXXXX" # ページソースで確認してください
# ブラウザインスタンスの作成
page = ChromiumPage()
page.get(target_url)
# Turnstileが読み込まれるのを待つ
page.wait.ele_displayed('input[name="cf-turnstile-response"]', timeout=10)
# CAPTCHAを解決
token = solve_turnstile(turnstile_site_key, target_url)
print(f"Turnstileトークンを取得: {token[:50]}...")
# JavaScriptを使用してトークンをインジェクト
page.run_js(f'''
document.querySelector('input[name="cf-turnstile-response"]').value = "{token}";
// あればコールバックをトリガー
const callback = document.querySelector('[data-callback]');
if (callback) {{
const callbackName = callback.getAttribute('data-callback');
if (window[callbackName]) {{
window[callbackName]('{token}');
}}
}}
''')
# フォームを送信
page('button[type="submit"]').click()
page.wait.load_start()
print("Turnstileを成功裏にバイパスしました!")
if __name__ == "__main__":
main()6.2. reCAPTCHA v2の解決(自動検出サイトキー)
この例では、ページからサイトキーを自動検出するため、手動の設定は必要ありません:
python
import time
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_recaptcha_v2(site_key: str, page_url: str) -> str:
"""reCAPTCHA v2を解決し、トークンを返します。"""
# タスクを作成
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"エラー: {result.get('errorDescription')}")
task_id = result["taskId"]
print(f"タスクを作成: {task_id}")
# 結果をポーリング
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
elif result.get("status") == "failed":
raise Exception(f"失敗: {result.get('errorDescription')}")
time.sleep(1)
def main():
# URLを指定するだけ - サイトキーは自動検出されます
target_url = "https://www.google.com/recaptcha/api2/demo"
# ブラウザを設定
co = ChromiumOptions()
co.set_argument('--disable-blink-features=AutomationControlled')
print("ブラウザを起動中...")
page = ChromiumPage(co)
try:
page.get(target_url)
time.sleep(2)
# ページからサイトキーを自動検出
recaptcha_div = page('.g-recaptcha')
if not recaptcha_div:
print("ページにreCAPTCHAが見つかりません!")
return
site_key = recaptcha_div.attr('data-sitekey')
print(f"自動検出されたサイトキー: {site_key}")
# CAPTCHAを解決
print("reCAPTCHA v2を解決中...")
token = solve_recaptcha_v2(site_key, target_url)
print(f"トークンを取得: {token[:50]}...")
# トークンをインジェクト
page.run_js(f'''
var responseField = document.getElementById('g-recaptcha-response');
responseField.style.display = 'block';
responseField.value = '{token}';
''')
print("トークンをインジェクトしました!")
# フォームを送信
submit_btn = page('#recaptcha-demo-submit') or page('input[type="submit"]') or page('button[type="submit"]')
if submit_btn:
submit_btn.click()
time.sleep(3)
print("フォームを送信しました!")
print(f"現在のURL: {page.url}")
print("SUCCESS!")
finally:
page.quit()
if __name__ == "__main__":
main()自分でテストしてみましょう:
bash
python recaptcha_demo.pyこれはGoogleのreCAPTCHAデモページを開き、サイトキーを自動検出してCAPTCHAを解決し、フォームを送信します。
6.3. reCAPTCHA v3の解決
reCAPTCHA v3はスコアベースで、ユーザーの操作は必要ありません。actionパラメータを指定する必要があります。
python
import time
import requests
from DrissionPage import ChromiumPage, ChromiumOptions
CAPSOLVER_API_KEY = "YOUR_API_KEY"
CAPSOLVER_API = "https://api.capsolver.com"
def solve_recaptcha_v3(
site_key: str,
page_url: str,
action: str = "verify",
min_score: float = 0.7
) -> str:
"""指定されたactionと最小スコアでreCAPTCHA v3を解決します。"""
response = requests.post(
f"{CAPSOLVER_API}/createTask",
json={
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": page_url,
"websiteKey": site_key,
"pageAction": action,
"minScore": min_score
}
}
)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"エラー: {result.get('errorDescription')}")
task_id = result["taskId"]
while True:
result = requests.post(
f"{CAPSOLVER_API}/getTaskResult",
json={
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
elif result.get("status") == "failed":
raise Exception(f"失敗: {result.get('errorDescription')}")
time.sleep(1)
def main():
target_url = "https://your-target-site.com"
recaptcha_v3_key = "6LcXXXXXXXXXXXXXXXXXXXXXXXXX"
# v3用のヘッドレスブラウザを設定
co = ChromiumOptions()
co.headless()
page = ChromiumPage(co)
page.get(target_url)
# "search"アクションでreCAPTCHA v3を解決
print("reCAPTCHA v3を解決中...")
token = solve_recaptcha_v3(
recaptcha_v3_key,
target_url,
action="search",
min_score=0.9 # 高スコアを要求
)
# トークンでコールバックを実行
page.run_js(f'''
// コールバック関数があれば、トークンで呼び出します
if (typeof onRecaptchaSuccess === 'function') {{
onRecaptchaSuccess('{token}');
}}
''')
print("コールバックを実行しました!")
print(f"現在のURL: {page.url}")
print("SUCCESS!")
if __name__ == "__main__":
main()}}
// または隠しフィールドの値を設定
var responseField = document.querySelector('[name="g-recaptcha-response"]');
if (responseField) {{
responseField.value = '{token}';
}}
''')
print("reCAPTCHA v3をを回避しました!")if name == "main":
main()
### 6.4. 人間のような動作を再現するためのアクションチェーンの使用
DrissionPageのアクションチェーンは、自然なマウスの動きとキーボード操作を提供します:
```python
import time
import random
from DrissionPage import ChromiumPage
from DrissionPage.common import Keys, Actions
def human_delay():
"""人間のような動作を再現するためのランダムな延."""
time.sleep(random.uniform(0.5, 1.5))
def main():
page = ChromiumPage()
page.get('https://your-target-site.com/form')
# アクションチェーンを使用して人間らしい操作を実行
ac = Actions(page)
# 入力フィールドに自然に移動し、クリックして入力
ac.move_to('input[name="email"]').click()
human_delay()
# 人間のようにゆっくり入力
for char in "user@email.com":
ac.type(char)
time.sleep(random.uniform(0.05, 0.15))
human_delay()
# パスワードフィールドに移動
ac.move_to('input[name="password"]').click()
human_delay()
# パスワードを入力
page('input[name="password"]').input("mypassword123")
# CAPTCHAを解決した後、自然な動きで送信ボタンをクリック
ac.move_to('button[type="submit"]')
human_delay()
ac.click()
if __name__ == "__main__":
main()7. 最適な実践方法
7.1. ブラウザの設定
DrissionPageを通常のブラウザのように見せるために設定します:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.set_argument('--disable-blink-features=AutomationControlled')
co.set_argument('--no-sandbox')
co.set_user_agent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
# 一般的な解像度にウィンドウサイズを設定
co.set_argument('--window-size=1920,1080')
page = ChromiumPage(co)7.2. シークレットモードとヘッドレスモード
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.incognito() # シークレットモードを使用
co.headless() # ヘッドレスモードを (v3 CAPTCHA用)
page = ChromiumPage(co)7.3. レートリミットの設定
レートリミットを回避するためにランダムな遅延を追加します:
python
import random
import time
def human_delay(min_sec=1.0, max_sec=3.0):
"""人間のような動作を再現するためのランダム遅延."""
time.sleep(random.uniform(min_sec, max_sec))
# アクションの間に使用
page('#button1').click()
human_delay()
page('#input1').input('text')7.4. エラー処理
CAPTCHA解決にに適切なエラー処理を実装してください:
python
def solve_with_retry(task_payload: dict, max_retries: int = 3) -> dict:
"""リトライロジックを含むCAPTCHA解決."""
for attempt in range(max_retries):
try:
return solve_captcha(task_payload)
except TimeoutError:
if attempt < max_retries - 1:
print(f"タイムアウトしました、リトライします... ({attempt + 1}/{max_retries})")
time.sleep(5)
else:
raise
except Exception as e:
if "balance" in str(e).lower():
raise # バランスエラーはリトライしない
if attempt < max_retries - 1:
time.sleep(2)
else:
raise7.5. プロキシのサポート
IPのローテーションのためにプロキシを使用します:
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.set_proxy('http://username:password@proxy.example.com:8080')
page = ChromiumPage(co)8. 結論
DrissionPageとCapSolverの統合は、ウェブ自動化のための強力なツールキットを提供します:
- DrissionPageはWebDriverの検出シグネチャなしでブラウザ自動化を処理
- CapSolverはAI駆動の解決でCAPTCHAを処理
- 両者を組み合わせることで、完全に人間のような自動化が可能になります
ウェブスクレイピング、自動テストシステム、またはデータ収集パイプラインを構築する際、この統合により信頼性と隠密性が得られます。
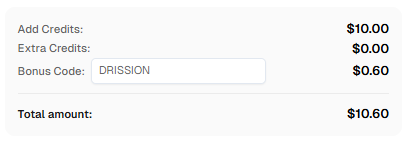
ボーナス: CapSolverで登録する際にコードコード
DRISSIONを使用すると、ボーナスクレジットが受けられます!
9. 質問と回答
9.1. SeleniumよりもDrissionPageを選ぶ択する理由は?
?
DrissionPageはWebDriverを使用しないため、:
- chromedriverのダウンロード/更新が必要ない
- 一般的なWebDriver検出シグネチャを回避
- ウェイトを内蔵したシンプルなAPI
- よりパフォーマンスが良くリリソース使用がが少ない
- クロスフレーム要素のネイティブサポート
9.2. この統合で最も効果的なCAPTCHAタイプは?
CapSolverはすべての主要なCAPTCHAタイプをサポートしています。Cloudflare TurnstileとreCAPTCHA v2/v3が最も高い成功率を誇ります。CapSolverがサポートするすべてのCAPTCHAとシームレスに動作します。
9.3. ヘッドレスモードで使用できますか?
はい!DrissionPageはヘッドレスモードをサポートしています。reCAPTCHA v3やトークンベースのCAPTCHAでは、ヘッドレスモードで動作します。v2の可視CAPTCHAでは、ヘッドモードの方がより良い結果を得られる場合があります。
9.4. CAPTCHAのサイトキーを見つける方法は?
ページソースを確認してください:
- Turnstile:
data-sitekey属性またはcf-turnstile要素 - reCAPTCHA:
g-recaptchaのdata-sitekey属性
9.5. CAPTCHA解決が失敗した場合の対処法は?
一般的な解決策は:
- APIキーと残高を確認
- サイトキーが正しいか確認
- ページURLがCAPTCHAが表示される場所と一致しているか確認
- v3の場合、アクションパラメーターや最小スコアを調整してみる
- タイムアウト後にリトライロジックを実装
9.6. DrissionPageはShadow DOMを処理できますか?
はい!DrissionPageはChromiumShadowElementクラスを通じてShadow DOM要素のネイティブサポートを備えています。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
