CrewAIでCAPTCHAを解く方法とCapSolverとの統合

Sora Fujimoto
AI Solutions Architect
TL;DR: CrewAIのワークフローはCaptchaに遭遇することが多く、CapSolverを統合することで自動スクリプトが効率的に解決できます。

はじめに
CrewAIでタスクを自動化する際、例えばWebスクレイピングやブラウジングを行う場合、CAPTCHAがワークフローを妨げる可能性があります。これらのチャレンジは、保護されたウェブサイトにアクセスする際に一般的であり、設計がしっかりした自動化スクリプトでも中断されることがあります。
CapSolverは、CrewAIが手動の介入なしにタスクを続けるために、CAPTCHAを処理する信頼性の高い方法を提供します。CapSolverを統合することで、自動ブラウジングとデータ収集をスムーズにし、ウェブサイトの保護に準拠したままにできます。
CrewAIとは?
CrewAIは、自律型AIエージェントシステムを構築するための軽量で高速なPythonフレームワークです。LangChainや他のエージェントフレームワークに依存せず、完全に新規に構築されたCrewAIは、高レベルの使いやすさと細かいカスタマイズの可能性を提供します。
CrewAIの主な特徴
- マルチエージェント協働: 特定の役割を持つ自律的なAIエージェントチームを構築し、自然な意思決定と動的なタスク委譲を可能にします
- イベント駆動型ワークフロー(フロー): 細かいパス管理、状態の一貫性、条件付き分岐を備えた正確な実行制御
- スタンドアローン設計: 外部フレームワークの依存関係なし、最小限のリソース要件で高速に設計されています
- 本番環境対応: 企業向けの信頼性とスケーラビリティの基準に合わせて設計されています
- 豊富なコミュニティ: コミュニティトレーニングを通じて10万人以上の認定開発者
コアアーキテクチャ
CrewAIは、2つの補完的なパラダイムに基づいて動作します。
| コンポーネント | 説明 |
|---|---|
| Crews | 自律的に協働するAIエージェントチームで、専門的な役割を持つ柔軟な問題解決を可能にします |
| Flows | 複雑なビジネスロジックの正確な実行制御を提供するイベント駆動型ワークフロー |
CapSolverとは?
CapSolverは、さまざまなCAPTCHAチャレンジを回避するためのAI駆動のソリューションを提供するリーディングCAPTCHAソルバーサービスです。複数のCAPTCHAタイプをサポートし、高速な応答時間を提供し、自動化ワークフローにシームレスに統合できます。
サポートされているCAPTCHAタイプ
- reCAPTCHA v2(画像および非表示)
- reCAPTCHA v3
- Cloudflare Turnstile
- Cloudflareチャレンジ(5秒)
- AWS WAF
- その他多数...
CrewAIにCapSolverを統合する理由
ウェブサイトとやり取りするCrewAIエージェントを構築する際、データ収集、自動テスト、コンテンツ集約などを行う場合、CAPTCHAチャレンジは大きな障害になります。統合が重要である理由は以下の通りです:
- エージェントワークフローの中断なし: エージェントは手動の介入なしでタスクを完了できます
- スケーラブルな自動化: 同時に動作するエージェント操作で複数のCAPTCHAチャレンジを処理できます
- コスト効率が良い: 成功したCAPTCHAのみに料金が発生します
- 高い成功確率: サポートされているすべてのCAPTCHAタイプで業界トップクラスの正確性
インストール
まず、必要なパッケージをインストールしてください:
bash
pip install crewai
pip install 'crewai[tools]'
pip install requestsCrewAI用のカスタムCapSolverツールの作成
CrewAIでは、エージェントがタスクを完了するために使用できるカスタムツールを作成できます。CAPTCHAチャレンジを処理するCapSolverツールの作成方法は以下の通りです:
基本的なCapSolverツールの実装
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class CaptchaSolverInput(BaseModel):
"""CaptchaSolverツールの入力スキーマ。"""
website_url: str = Field(..., description="CAPTCHAのあるウェブサイトのURL")
website_key: str = Field(..., description="CAPTCHAのサイトキー")
captcha_type: str = Field(default="ReCaptchaV2TaskProxyLess", description="解決するCAPTCHAのタイプ")
class CaptchaSolverTool(BaseTool):
name: str = "captcha_solver"
description: str = "CapSolver APIを使用してCAPTCHAチャレンジを解決します。reCAPTCHA v2、v3、Turnstileなどに対応しています。"
args_schema: Type[BaseModel] = CaptchaSolverInput
def _run(self, website_url: str, website_key: str, captcha_type: str = "ReCaptchaV2TaskProxyLess") -> str:
# タスクの作成
create_task_url = "https://api.capsolver.com/createTask"
task_payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": captcha_type,
"websiteURL": website_url,
"websiteKey": website_key
}
}
response = requests.post(create_task_url, json=task_payload)
result = response.json()
if result.get("errorId") != 0:
return f"タスク作成エラー: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 結果のポーリング
get_result_url = "https://api.capsolver.com/getTaskResult"
for _ in range(60): # 最大60回の試行
time.sleep(2)
result_payload = {
"clientKey": CAPSOLVER_API_KEY,
"taskId": task_id
}
response = requests.post(get_result_url, json=result_payload)
result = response.json()
if result.get("status") == "ready":
solution = result.get("solution", {})
return solution.get("gRecaptchaResponse") or solution.get("token")
elif result.get("status") == "failed":
return f"タスク失敗: {result.get('errorDescription')}"
return "CAPTCHA解決を待っている間にタイムアウト"異なるCAPTCHAタイプの解決
reCAPTCHA v2ソルバー
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class ReCaptchaV2Input(BaseModel):
"""reCAPTCHA v2ソルバーの入力スキーマ。"""
website_url: str = Field(..., description="reCAPTCHA v2のあるウェブサイトのURL")
website_key: str = Field(..., description="reCAPTCHAのサイトキー")
class ReCaptchaV2Tool(BaseTool):
name: str = "recaptcha_v2_solver"
description: str = "CapSolverを使用してreCAPTCHA v2チャレンジを解決します"
args_schema: Type[BaseModel] = ReCaptchaV2Input
def _run(self, website_url: str, website_key: str) -> str:
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key
}
}
return self._solve_captcha(payload)
def _solve_captcha(self, payload: dict) -> str:
# タスクの作成
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
return f"エラー: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 結果のポーリング
for attempt in range(60):
time.sleep(2)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
if result.get("status") == "failed":
return f"失敗: {result.get('errorDescription')}"
return "解決を待っている間にタイムアウト"reCAPTCHA v3ソルバー
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class ReCaptchaV3Input(BaseModel):
"""reCAPTCHA v3ソルバーの入力スキーマ。"""
website_url: str = Field(..., description="reCAPTCHA v3のあるウェブサイトのURL")
website_key: str = Field(..., description="reCAPTCHAのサイトキー")
page_action: str = Field(default="submit", description="reCAPTCHA v3のアクションパラメータ")
class ReCaptchaV3Tool(BaseTool):
name: str = "recaptcha_v3_solver"
description: str = "スコアベースの検証でreCAPTCHA v3チャレンジを解決します"
args_schema: Type[BaseModel] = ReCaptchaV3Input
def _run(
self,
website_url: str,
website_key: str,
page_action: str = "submit"
) -> str:
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV3TaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key,
"pageAction": page_action
}
}
# タスクの作成
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
return f"エラー: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 結果のポーリング
for attempt in range(60):
time.sleep(2)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
if result.get("status") == "failed":
return f"失敗: {result.get('errorDescription')}"
return "解決を待っている間にタイムアウト"Cloudflare Turnstileソルバー
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class TurnstileInput(BaseModel):
"""Turnstileソルバーの入力スキーマ。"""
website_url: str = Field(..., description="TurnstileのあるウェブサイトのURL")
website_key: str = Field(..., description="Turnstileウィジェットのサイトキー")
class TurnstileTool(BaseTool):
name: str = "turnstile_solver"
description: str = "Cloudflare Turnstileチャレンジを解決します"
args_schema: Type[BaseModel] = TurnstileInput
def _run(self, website_url: str, website_key: str) -> str:
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiTurnstileTaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key
}
}
# タスクの作成
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
return f"エラー: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 結果のポーリング
for attempt in range(60):
time.sleep(2)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return result["solution"]["token"]
if result.get("status") == "failed":
return f"失敗: {result.get('errorDescription')}"
return "解決を待っている間にタイムアウト"Cloudflareチャレンジ(5秒)ソルバー
python
import requests
import time
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
class CloudflareChallengeInput(BaseModel):
"""Cloudflare Challengeソルバーの入力スキーマ。"""
website_url: str = Field(..., description="保護されたページのURL")
proxy: str = Field(..., description="プロキシの形式: http://user:pass@ip:port")
class CloudflareChallengeTool(BaseTool):
name: str = "cloudflare_challenge_solver"
description: str = "Cloudflare 5秒チャレンジページを解決します"
args_schema: Type[BaseModel] = CloudflareChallengeInput
def _run(self, website_url: str, proxy: str) -> dict:
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "AntiCloudflareTask",
"websiteURL": website_url,
"proxy": proxy
}
}
# タスクの作成
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
return f"エラー: {result.get('errorDescription')}"
task_id = result.get("taskId")
# 結果のポーリング
for attempt in range(60):
time.sleep(3)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return {
"cookies": result["solution"]["cookies"],
"user_agent": result["solution"]["userAgent"]
}
if result.get("status") == "failed":
return f"失敗: {result.get('errorDescription')}"
return "解決を待っている間にタイムアウト"import requests
def access_cloudflare_protected_page(url: str, cf_solution: dict):
"""
Cloudflareチャレンジの解決方法を使用して保護されたページにアクセスします。
cf_solutionには、CapSolverから取得した'cookies'と'user_agent'が含まれます。
"""
# 解決済みのクッキーを使用してセッションを作成
session = requests.Session()
# CapSolverの解決結果からクッキーを設定
for cookie in cf_solution["cookies"]:
session.cookies.set(cookie["name"], cookie["value"])
# 解決に使用されたUser-Agentを設定
headers = {
"User-Agent": cf_solution["user_agent"]
}
# これで保護されたページにアクセスできます
response = session.get(url, headers=headers)
return response.text### 完全なスクレイピング例
```python
import requests
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
CAPSOLVER_API_KEY = "YOUR_CAPSOLVER_API_KEY"
def solve_recaptcha(website_url: str, website_key: str) -> str:
"""CapSolverからreCAPTCHAトークンを取得します"""
payload = {
"clientKey": CAPSOLVER_API_KEY,
"task": {
"type": "ReCaptchaV2TaskProxyLess",
"websiteURL": website_url,
"websiteKey": website_key
}
}
response = requests.post("https://api.capsolver.com/createTask", json=payload)
result = response.json()
if result.get("errorId") != 0:
raise Exception(f"エラー: {result.get('errorDescription')}")
task_id = result.get("taskId")
for _ in range(60):
time.sleep(2)
result = requests.post(
"https://api.capsolver.com/getTaskResult",
json={"clientKey": CAPSOLVER_API_KEY, "taskId": task_id}
).json()
if result.get("status") == "ready":
return result["solution"]["gRecaptchaResponse"]
if result.get("status") == "failed":
raise Exception(f"失敗: {result.get('errorDescription')}")
raise Exception("タイムアウト")
def scrape_with_recaptcha(target_url: str, site_key: str):
"""フルフロー: reCAPTCHAを解決 → 送信 → スクレイピング"""
driver = webdriver.Chrome()
driver.get(target_url)
try:
# 1. CAPTCHAを解決
token = solve_recaptcha(target_url, site_key)
# 2. トークンを挿入
recaptcha_response = driver.find_element(By.ID, "g-recaptcha-response")
driver.execute_script("arguments[0].style.display = 'block';", recaptcha_response)
recaptcha_response.clear()
recaptcha_response.send_keys(token)
# 3. フォームを送信
driver.find_element(By.TAG_NAME, "form").submit()
# 4. コンテンツをスクレイピング
time.sleep(3) # ページ読み込みを待つ
return driver.page_source
finally:
driver.quit()CapSolverブラウザ拡張機能の使用方法
CrewAIでのブラウザ自動化が必要なシナリオでは、CapSolverブラウザ拡張機能を使用できます。
-
拡張機能をダウンロード: capsolver.com からCapSolver拡張機能を取得してください
-
Selenium/Playwrightで設定: ブラウザ自動化ツールに拡張機能をロードしてください
-
自動解決モード: 拡張機能は自動的にCAPTCHAを検出および解決します
python
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# CapSolver拡張機能を設定
chrome_options = Options()
chrome_options.add_extension("path/to/capsolver-extension.crx")
driver = webdriver.Chrome(options=chrome_options)
# 拡張機能が自動的にCAPTCHAを処理します
driver.get("https://example.com/protected-page")最適な実践方法
1. エラー処理
python
def solve_with_retry(self, payload: dict, max_retries: int = 3) -> str:
for attempt in range(max_retries):
try:
result = self._solve_captcha(payload)
if result:
return result
except Exception as e:
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt) # 指数バックオフ2. 残高管理
python
def check_balance() -> float:
response = requests.post(
"https://api.capsolver.com/getBalance",
json={"clientKey": CAPSOLVER_API_KEY}
)
return response.json().get("balance", 0)3. 解決結果のキャッシュ
同じページに繰り返しアクセスする場合、適切なタイミングでCAPTCHAトークンをキャッシュします:
python
from functools import lru_cache
from datetime import datetime, timedelta
captcha_cache = {}
def get_cached_token(website_url: str, website_key: str) -> str:
cache_key = f"{website_url}:{website_key}"
if cache_key in captcha_cache:
token, timestamp = captcha_cache[cache_key]
if datetime.now() - timestamp < timedelta(minutes=2):
return token
# 新しいCAPTCHAを解決
new_token = solve_captcha(website_url, website_key)
captcha_cache[cache_key] = (new_token, datetime.now())
return new_token結論
CrewAIにCapSolverを統合することで、ウェブベースのタスクにおける自律型AIエージェントの完全な潜在能力を引き出すことができます。CrewAIの強力なマルチエージェントオーケストレーションとCapSolverの業界をリードするCAPTCHA解決能力を組み合わせることで、開発者は最も困難なウェブ保護メカニズムを扱う堅牢な自動化ソリューションを構築できます。
データ抽出パイプライン、自動テストフレームワーク、知能型ウェブエージェントの構築など、さまざまな用途においてCrewAI + CapSolverの組み合わせは、本番環境で必要な信頼性とスケーラビリティを提供します。
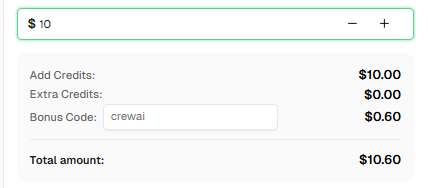
さっそく始めましょうか? CapSolverに登録する そして、毎回の充電で追加の6%ボーナスを受けるためにボーナスコード CREWAI を使用してください!
Q&A
CrewAIとは何ですか?
CrewAIは、自律型AIエージェントシステムを構築するための軽量で高速なPythonフレームワークです。開発者が複雑なタスクを完了するために協力するAIエージェントのクルーを作成できるようにし、自律的な意思決定と正確なワークフロー制御のサポートを提供します。
CapSolverはCrewAIとどのように統合されますか?
CapSolverはカスタムツールを通じてCrewAIと統合されます。CapSolver APIをラップするツールを作成することで、AIエージェントがウェブ操作中にCAPTCHAチャレンジに遭遇したときに自動的に解決できるようにします。
CapSolverが解決できるCAPTCHAの種類は?
CapSolverはreCAPTCHA v2、reCAPTCHA v3、Cloudflare Turnstile、Cloudflare Challenge、AWS WAF、GeeTestなど、幅広いCAPTCHAタイプをサポートしています。
CapSolverの料金はどのくらいですか?
CapSolverは解決するCAPTCHAの種類と量に基づいて競争力のある料金を提供しています。最新の料金詳細についてはcapsolver.comをご覧ください。最初の充電で6%のボーナスを受けるためにコード CREWAI を使用してください。
他のPythonフレームワークとCapSolverを使用できますか?
はい!CapSolverは任意のPythonフレームワークと統合可能なREST APIを提供しています。Scrapy、Selenium、Playwrightなどにも対応しています。
CrewAIは無料で使用できますか?
はい、CrewAIはMITライセンスでオープンソースとしてリリースされています。フレームワークは無料で使用できますが、LLM APIコール(例: OpenAI)やCAPTCHA解決サービス(例: CapSolver)のコストが発生する場合があります。
CAPTCHAのサイトキーを見つける方法は?
サイトキーは通常、ページのHTMLソースに含まれています。以下を検索してください:
- reCAPTCHA:
data-sitekey属性またはgrecaptcha.render()呼び出し - :
data-sitekey属性 - Turnstile: Turnstileウィジェット内の
data-sitekey属性
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
