Captchaをブラウザ4で解く方法とCapSolverの統合

Sora Fujimoto
AI Solutions Architect

Webオートメーションにおいて、Browser4(PulsarRPAから)は、AI駆動型データ抽出に最適な、高速でコルーチンセーフなブラウザエンジンとして登場しました。1台のマシンで1日あたり10万〜20万件の複雑なページアクセスをサポートするこのブラウザエンジンは、大規模な処理に最適です。しかし、保護されたウェブサイトからデータを抽出する際、CAPTCHAチャレンジが大きな障壁となります。
CapSolverは、Browser4の自動化機能に理想的な補完を提供し、エージェントがCAPTCHA保護されたページをスムーズにナビゲートできるようにします。この統合により、Browser4の高スループットブラウザ自動化と業界をリードするCAPTCHA解決が組み合わされます。
Browser4とは何ですか?
Browser4は、Kotlinで構築された高性能でコルーチンセーフなブラウザ自動化フレームワークです。AIアプリケーションに自律的なエージェント機能、極限のスループット、LLM、機械学習、セレクタベースのアプローチを組み合わせたハイブリッドデータ抽出を必要とするものに設計されています。
Browser4の主な特徴
- 極限のスループット: 1台のマシンで1日あたり10万〜20万件の複雑なページアクセス
- コルーチンセーフ: 効率的な並列処理のためのKotlinコルーチンで構築
- AI駆動エージェント: 複数ステップのタスクを実行できる自律的なブラウザエージェント
- ハイブリッド抽出: LLMの知能、機械学習アルゴリズム、CSS/XPathセレクタを組み合わせた抽出
- X-SQLクエリ: 複雑なデータ抽出用の拡張SQL構文
- アンチボット機能: プロフィールローテーション、プロキシサポート、耐障害性のあるスケジューリング
コアAPIメソッド
| メソッド | 説明 |
|---|---|
session.open(url) |
ページを読み込み、PageSnapshotを返します |
session.parse(page) |
スナップショットをメモリ内ドキュメントに変換します |
driver.selectFirstTextOrNull(selector) |
ライブDOMからテキストを取得します |
driver.evaluate(script) |
ブラウザでJavaScriptを実行します |
session.extract(document, fieldMap) |
CSSセレクタを構造化されたフィールドにマップします |
CapSolverとは何ですか?
CapSolverは、さまざまなCAPTCHAチャレンジを回避するAI駆動型ソリューションを提供するリーディングなCAPTCHA解決サービスです。複数のCAPTCHAタイプをサポートし、高速な応答時間を実現し、自動化ワークフローにシームレスに統合できます。
サポートされているCAPTCHAタイプ
Browser4とCapSolverを統合する理由
保護されたウェブサイトとやり取りするBrowser4の自動化を構築する際、データ抽出、価格モニタリング、市場調査など、さまざまな用途においてCAPTCHAチャレンジが大きな障害となります。統合の重要性について以下に説明します。
- 中断のない高スループット抽出: CAPTCHAブロックなしで1日あたり10万件以上のページアクセスを維持
- スケーラブルな運用: コルーチンの並列実行でCAPTCHAを処理
- シームレスなワークフロー: 抽出パイプラインの一環としてCAPTCHAを解決
- コスト効率: 成功したCAPTCHAのみに支払い
- 高い成功確率: サポートされているすべてのCAPTCHAタイプで業界をリードする精度
インストール
前提条件
- Java 17以上
- Maven 3.6以上またはGradle
- CapSolver APIキー

依存関係の追加
Maven (pom.xml):
xml
<dependencies>
<!-- Browser4/PulsarRPA -->
<dependency>
<groupId>ai.platon.pulsar</groupId>
<artifactId>pulsar-boot</artifactId>
<version>2.2.0</version>
</dependency>
<!-- CapSolver用HTTPクライアント -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- JSONパーサー -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
<!-- Kotlinコルーチン -->
<dependency>
<groupId>org.jetbrains.kotlinx</groupId>
<artifactId>kotlinx-coroutines-core</artifactId>
<version>1.8.0</version>
</dependency>
</dependencies>Gradle (build.gradle.kts):
kotlin
dependencies {
implementation("ai.platon.pulsar:pulsar-boot:2.2.0")
implementation("com.squareup.okhttp3:okhttp:4.12.0")
implementation("com.google.code.gson:gson:2.10.1")
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.8.0")
}環境設定
application.propertiesファイルを作成します:
properties
# CapSolver設定
CAPSOLVER_API_KEY=your_capsolver_api_key
# LLM設定 (オプション、AI抽出用)
OPENROUTER_API_KEY=your_openrouter_api_key
# プロキシ設定 (オプション)
PROXY_ROTATION_URL=your_proxy_urlBrowser4用のCapSolverサービスの作成
Browser4に統合された再利用可能なKotlinサービスを以下に示します。
基本的なCapSolverサービス
kotlin
import com.google.gson.Gson
import com.google.gson.JsonObject
import okhttp3.MediaType.Companion.toMediaType
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.RequestBody.Companion.toRequestBody
import kotlinx.coroutines.delay
import java.util.concurrent.TimeUnit
data class TaskResult(
val gRecaptchaResponse: String? = null,
val token: String? = null,
val cookies: List<Map<String, String>>? = null,
val userAgent: String? = null
)
class CapSolverService(private val apiKey: String) {
private val client = OkHttpClient.Builder()
.connectTimeout(30, TimeUnit.SECONDS)
.readTimeout(30, TimeUnit.SECONDS)
.build()
private val gson = Gson()
private val baseUrl = "https://api.capsolver.com"
private val jsonMediaType = "application/json".toMediaType()
private suspend fun createTask(taskData: Map<String, Any>): String {
val payload = mapOf(
"clientKey" to apiKey,
"task" to taskData
)
val request = Request.Builder()
.url("$baseUrl/createTask")
.post(gson.toJson(payload).toRequestBody(jsonMediaType))
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
if (result.get("errorId").asInt != 0) {
throw Exception("CapSolverエラー: ${result.get("errorDescription").asString}")
}
return result.get("taskId").asString
}
private suspend fun getTaskResult(taskId: String, maxAttempts: Int = 60): TaskResult {
val payload = mapOf(
"clientKey" to apiKey,
"taskId" to taskId
)
repeat(maxAttempts) {
delay(2000)
val request = Request.Builder()
.url("$baseUrl/getTaskResult")
.post(gson.toJson(payload).toRequestBody(jsonMediaType))
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
when (result.get("status")?.asString) {
"ready" -> {
val solution = result.getAsJsonObject("solution")
return TaskResult(
gRecaptchaResponse = solution.get("gRecaptchaResponse")?.asString,
token = solution.get("token")?.asString,
userAgent = solution.get("userAgent")?.asString
)
}
"failed" -> throw Exception("タスク失敗: ${result.get("errorDescription")?.asString}")
}
}
throw Exception("CAPTCHAの解決を待つタイムアウト")
}
suspend fun solveReCaptchaV2(websiteUrl: String, websiteKey: String): String {
val taskId = createTask(mapOf(
"type" to "ReCaptchaV2TaskProxyLess",
"websiteURL" to websiteUrl,
"websiteKey" to websiteKey
))
val result = getTaskResult(taskId)
return result.gRecaptchaResponse ?: throw Exception("解決にgRecaptchaResponseがありません")
}
suspend fun solveReCaptchaV3(
websiteUrl: String,
websiteKey: String,
pageAction: String = "submit"
): String {
val taskId = createTask(mapOf(
"type" to "ReCaptchaV3TaskProxyLess",
"websiteURL" to websiteUrl,
"websiteKey" to websiteKey,
"pageAction" to pageAction
))
val result = getTaskResult(taskId)
return result.gRecaptchaResponse ?: throw Exception("解決にgRecaptchaResponseがありません")
}
suspend fun solveTurnstile(
websiteUrl: String,
websiteKey: String,
action: String? = null,
cdata: String? = null
): String {
val taskData = mutableMapOf(
"type" to "AntiTurnstileTaskProxyLess",
"websiteURL" to websiteUrl,
"websiteKey" to websiteKey
)
// オプションのメタデータを追加
if (action != null || cdata != null) {
val metadata = mutableMapOf<String, String>()
action?.let { metadata["action"] = it }
cdata?.let { metadata["cdata"] = it }
taskData["metadata"] = metadata
}
val taskId = createTask(taskData)
val result = getTaskResult(taskId)
return result.token ?: throw Exception("解決にトークンがありません")
}
suspend fun checkBalance(): Double {
val payload = mapOf("clientKey" to apiKey)
val request = Request.Builder()
.url("$baseUrl/getBalance")
.post(gson.toJson(payload).toRequestBody(jsonMediaType))
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
return result.get("balance")?.asDouble ?: 0.0
}
}異なるCAPTCHAタイプの解決
Browser4でのreCAPTCHA v2
kotlin
import ai.platon.pulsar.context.PulsarContexts
import ai.platon.pulsar.skeleton.session.PulsarSession
import kotlinx.coroutines.runBlocking
class ReCaptchaV2Extractor(
private val capSolver: CapSolverService
) {
suspend fun extractWithCaptcha(targetUrl: String, siteKey: String): Map<String, Any?> {
println("reCAPTCHA v2を解決中...")
// まずCAPTCHAを解決します
val token = capSolver.solveReCaptchaV2(targetUrl, siteKey)
println("CAPTCHAが解決されました、トークンの長さ: ${token.length}")
// セッションを作成し、ページを開きます
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// 安全な値の割り当てを使用して、トークンを隠しテキストエリアに注入します
driver?.evaluate("""
(function() {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = arguments[0];
})('$token');
""")
// フォームを送信します
driver?.evaluate("document.querySelector('form').submit();")
// ナビゲーションを待機します
Thread.sleep(3000)
// 結果ページからデータを抽出します
val document = session.parse(page)
mapOf(
"title" to document.selectFirstTextOrNull("h1"),
"content" to document.selectFirstTextOrNull(".content"),
"success" to (document.body().text().contains("success", ignoreCase = true))
)
}
}
fun main() = runBlocking {
val apiKey = System.getenv("CAPSOLVER_API_KEY") ?: "your_api_key"
val capSolver = CapSolverService(apiKey)
val extractor = ReCaptchaV2Extractor(capSolver)
val result = extractor.extractWithCaptcha(
targetUrl = "https://example.com/protected-page",
siteKey = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC"
)
println("抽出結果: $result")
}Browser4でのreCAPTCHA v3
kotlin
class ReCaptchaV3Extractor(
private val capSolver: CapSolverService
) {
suspend fun extractWithCaptchaV3(
targetUrl: String,
siteKey: String,
action: String = "submit"
): Map<String, Any?> {
println("アクション: $actionでreCAPTCHA v3を解決中")
// カスタムページアクションでreCAPTCHA v3を解決します
val token = capSolver.solveReCaptchaV3(
websiteUrl = targetUrl,
websiteKey = siteKey,
pageAction = action
)
println("トークンを取得しました")
// セッションを作成し、ページを開きます
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// 安全な値の割り当てを使用してトークンを隠し入力に注入します
driver?.evaluate("""
(function(tokenValue) {
var input = document.querySelector('input[name="g-recaptcha-response"]');
if (input) {
input.value = tokenValue;
} else {
var hidden = document.createElement('input');
hidden.type = 'hidden';
hidden.name = 'g-recaptcha-response';
hidden.value = tokenValue;
var form = document.querySelector('form');
if (form) form.appendChild(hidden);
}
})('$token');
""")
// 送信ボタンをクリックします
driver?.evaluate("document.querySelector('#submit-btn').click();")
Thread.sleep(3000)
val document = session.parse(page)
mapOf(
"result" to document.selectFirstTextOrNull(".result-data"),
"status" to "success"
)
}
}Browser4でのCloudflare Turnstile
kotlin
class TurnstileExtractor(
private val capSolver: CapSolverService
) {
suspend fun extractWithTurnstile(targetUrl: String, siteKey: String): Map<String, Any?> {
println("Cloudflare Turnstileを解決中...")
// オプションのメタデータ(actionとcdata)で解決します
val taskId = createTask(mapOf(
"type" to "AntiTurnstileTaskProxyLess",
"websiteURL" to targetUrl,
"websiteKey" to siteKey
))
val result = getTaskResult(taskId)
return TaskResult(
token = result.token ?: throw Exception("解決にトークンがありません")
)
}
}val token = capSolver.solveTurnstile(
targetUrl,
siteKey,
action = "login", // オプション
cdata = "0000-1111-2222-3333-example" // オプション
)
println("Turnstileが解決されました!")
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// Turnstileトークンを注入(安全な値の割り当てを使用)
driver?.evaluate("""
(function(tokenValue) {
var input = document.querySelector('input[name="cf-turnstile-response"]');
if (input) input.value = tokenValue;
})('$token');
""")
// 送信
driver?.evaluate("document.querySelector('form').submit();")
Thread.sleep(3000)
val document = session.parse(page)
mapOf(
"title" to document.selectFirstTextOrNull("title"),
"content" to document.selectFirstTextOrNull("body")?.take(500)
)
}}
---
## Browser4 X-SQLとの統合
Browser4のX-SQLは強力な抽出機能を提供します。CAPTCHA解決と組み合わせる方法を以下に示します。
```kotlin
class XSqlCaptchaExtractor(
private val capSolver: CapSolverService
) {
suspend fun extractProductsWithCaptcha(
targetUrl: String,
siteKey: String
): List<Map<String, Any?>> {
// CAPTCHAを事前に解決
val token = capSolver.solveReCaptchaV2(targetUrl, siteKey)
// セッションを作成し、認証済みセッションを確立
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
driver?.evaluate("""
(function(tokenValue) {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = tokenValue;
document.querySelector('form').submit();
})('$token');
""")
Thread.sleep(3000)
// 今やページを解析し、製品データを抽出
val document = session.parse(page)
// 内蔵セッションメソッドを使用して製品データを抽出
val products = mutableListOf<Map<String, Any?>>()
val productElements = document.select(".product-item")
for ((index, element) in productElements.withIndex()) {
if (index >= 50) break // LIMIT 50
products.add(mapOf(
"name" to element.selectFirstTextOrNull(".product-name"),
"price" to element.selectFirstTextOrNull(".price")?.let {
"""(\d+\.?\d*)""".toRegex().find(it)?.groupValues?.get(1)?.toDoubleOrNull() ?: 0.0
},
"rating" to element.selectFirstTextOrNull(".rating")
))
}
return products.map { row ->
mapOf(
"name" to row["name"],
"price" to row["price"],
"rating" to row["rating"],
"image_url" to row["image_url"]
)
}
}
}事前認証パターン
コンテンツにアクセスする前にCAPTCHAを必要とするサイトでは、事前認証ワークフローを使用してください。
kotlin
import okhttp3.Cookie
import okhttp3.CookieJar
import okhttp3.HttpUrl
class PreAuthenticator(
private val capSolver: CapSolverService
) {
data class AuthSession(
val cookies: Map<String, String>,
val userAgent: String?
)
suspend fun authenticateWithCaptcha(
loginUrl: String,
siteKey: String
): AuthSession {
// CAPTCHAを解決
val captchaToken = capSolver.solveReCaptchaV2(loginUrl, siteKey)
// CAPTCHAを送信してセッションクッキーを取得
val client = OkHttpClient.Builder()
.cookieJar(object : CookieJar {
private val cookies = mutableListOf<Cookie>()
override fun saveFromResponse(url: HttpUrl, cookieList: List<Cookie>) {
cookies.addAll(cookieList)
}
override fun loadForRequest(url: HttpUrl): List<Cookie> = cookies
})
.build()
val formBody = okhttp3.FormBody.Builder()
.add("g-recaptcha-response", captchaToken)
.build()
val request = Request.Builder()
.url(loginUrl)
.post(formBody)
.build()
val response = client.newCall(request).execute()
// レスポンスからクッキーを抽出
val responseCookies = response.headers("Set-Cookie")
.associate { cookie ->
val parts = cookie.split(";")[0].split("=", limit = 2)
parts[0] to (parts.getOrNull(1) ?: "")
}
return AuthSession(
cookies = responseCookies,
userAgent = response.request.header("User-Agent")
)
}
}
class AuthenticatedExtractor(
private val preAuth: PreAuthenticator,
private val capSolver: CapSolverService
) {
suspend fun extractWithAuth(
loginUrl: String,
targetUrl: String,
siteKey: String
): Map<String, Any?> {
// 事前認証
val authSession = preAuth.authenticateWithCaptcha(loginUrl, siteKey)
println("セッションが確立されました。${authSession.cookies.size}個のクッキーがあります")
// Browser4セッションを作成
val session = PulsarContexts.createSession()
// セッションにクッキーを設定
val cookieScript = authSession.cookies.entries.joinToString(";") { (k, v) ->
"$k=$v"
}
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
// クッキーを設定
driver?.evaluate("document.cookie = '$cookieScript';")
// 認証済みセッションで再読み込み
driver?.evaluate("location.reload();")
Thread.sleep(2000)
// データを抽出
val document = session.parse(page)
return mapOf(
"authenticated" to true,
"content" to document.selectFirstTextOrNull(".protected-content"),
"userData" to document.selectFirstTextOrNull(".user-profile")
)
}
}LLM対応抽出のOpenRouter統合
Browser4のAI機能は、OpenRouterを介して強化され、さまざまなLLMモデルにアクセスするための統一APIゲートウェイとして機能します。これにより、ページ構造に応じて適応する知的コンテンツ抽出が可能になります。
OpenRouterサービス
kotlin
import com.google.gson.Gson
import com.google.gson.JsonObject
import okhttp3.MediaType.Companion.toMediaType
import okhttp3.OkHttpClient
import okhttp3.Request
import okhttp3.RequestBody.Companion.toRequestBody
import java.util.concurrent.TimeUnit
data class ChatMessage(val role: String, val content: String)
data class ChatCompletion(val content: String, val model: String, val usage: TokenUsage)
data class TokenUsage(val promptTokens: Int, val completionTokens: Int, val totalTokens: Int)
class OpenRouterService(private val apiKey: String) {
private val client = OkHttpClient.Builder()
.connectTimeout(60, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.build()
private val gson = Gson()
private val baseUrl = "https://openrouter.ai/api/v1"
private val jsonMediaType = "application/json".toMediaType()
fun chat(
messages: List<ChatMessage>,
model: String = "openai/gpt-4o-mini"
): ChatCompletion {
val payload = mapOf(
"model" to model,
"messages" to messages.map { mapOf("role" to it.role, "content" to it.content) }
)
val request = Request.Builder()
.url("$baseUrl/chat/completions")
.header("Authorization", "Bearer $apiKey")
.post(gson.toJson(payload).toRequestBody(jsonMediaType))
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
val choice = result.getAsJsonArray("choices")?.get(0)?.asJsonObject
val content = choice?.getAsJsonObject("message")?.get("content")?.asString ?: ""
val usage = result.getAsJsonObject("usage")
return ChatCompletion(
content = content,
model = result.get("model")?.asString ?: model,
usage = TokenUsage(
promptTokens = usage?.get("prompt_tokens")?.asInt ?: 0,
completionTokens = usage?.get("completion_tokens")?.asInt ?: 0,
totalTokens = usage?.get("total_tokens")?.asInt ?: 0
)
)
}
fun extractStructuredData(html: String, schema: String): String {
val prompt = """
次のHTMLコンテンツからデータを抽出してください。
以下のスキーマに一致する有効なJSONを返してください: $schema
HTML:
${html.take(4000)}
""".trimIndent()
return chat(listOf(ChatMessage("user", prompt))).content
}
fun listModels(): List<String> {
val request = Request.Builder()
.url("$baseUrl/models")
.header("Authorization", "Bearer $apiKey")
.build()
val response = client.newCall(request).execute()
val result = gson.fromJson(response.body?.string(), JsonObject::class.java)
return result.getAsJsonArray("data")?.mapNotNull {
it.asJsonObject.get("id")?.asString
} ?: emptyList()
}
}CAPTCHA解決とLLMによる抽出の統合
CAPTCHA解決と知的コンテンツ抽出を組み合わせます。
kotlin
class SmartExtractor(
private val capSolver: CapSolverService,
private val openRouter: OpenRouterService
) {
suspend fun extractWithAI(
targetUrl: String,
siteKey: String?,
extractionPrompt: String
): Map<String, Any?> {
// ステップ1: 必要に応じてCAPTCHAを解決
val captchaToken = siteKey?.let {
println("CAPTCHAを解決中...")
capSolver.solveReCaptchaV2(targetUrl, it)
}
// ステップ2: セッションを作成し、ページを開く
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
captchaToken?.let { token ->
driver?.evaluate("""
(function(tokenValue) {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = tokenValue;
var form = document.querySelector('form');
if (form) form.submit();
})('$token');
""")
Thread.sleep(3000)
}
// ステップ3: ページコンテンツを抽出
val document = session.parse(page)
val pageContent = document.body().text().take(8000)
// ステップ4: LLMを使用して構造化データを抽出
val llmResponse = openRouter.chat(listOf(
ChatMessage("system", "あなたはデータ抽出アシスタントです。ウェブページから構造化データを抽出してください。"),
ChatMessage("user", """
$extractionPrompt
ページコンテンツ:
$pageContent
""".trimIndent())
))
println("LLMが${llmResponse.usage.totalTokens}トークンを使用しました")
return mapOf(
"url" to targetUrl,
"captchaSolved" to (captchaToken != null),
"extractedData" to llmResponse.content,
"tokensUsed" to llmResponse.usage.totalTokens
)
}
}
// 使用例
fun main() = runBlocking {
val capSolver = CapSolverService(System.getenv("CAPSOLVER_API_KEY")!!)
val openRouter = OpenRouterService(System.getenv("OPENROUTER_API_KEY")!!)
val extractor = SmartExtractor(capSolver, openRouter)
val result = extractor.extractWithAI(
targetUrl = "https://example.com/products",
siteKey = "6LcxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxABC",
extractionPrompt = """
次の製品をすべて抽出してください:
- 名前
- 価格(数値として)
- 在庫状況(在庫あり/在庫切れ)
- 評価(1-5)
JSON配列として返してください。
""".trimIndent()
)
println("抽出結果: ${result["extractedData"]}")
}逆引きセレクタ生成
LLMを使用して、未知のページ構造用のCSSセレクタを生成します。
kotlin
class AdaptiveExtractor(
private val capSolver: CapSolverService,
private val openRouter: OpenRouterService
) {
suspend fun extractWithAdaptiveSelectors(
targetUrl: String,
siteKey: String?,
dataFields: List<String>
): Map<String, Any?> {
// まずCAPTCHAを解決
val token = siteKey?.let { capSolver.solveReCaptchaV2(targetUrl, it) }
val session = PulsarContexts.createSession()
val page = session.open(targetUrl)
val driver = session.getOrCreateBoundDriver()
token?.let { t ->
driver?.evaluate("""
(function(tokenValue) {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = tokenValue;
})('$t');
""")
}
// ページHTML構造を取得
val htmlSample = driver?.evaluate("document.body.innerHTML")?.toString()?.take(5000) ?: ""
// LLMにセレクタを生成させる
val selectorPrompt = """
次のHTMLを分析し、これらのフィールドに該当するCSSセレクタを提供してください: ${dataFields.joinToString(", ")}
HTMLサンプル:
$htmlSample
以下のJSON形式で返してください: {"fieldName": "css-selector", ...}
""".trimIndent()
val selectorsJson = openRouter.chat(listOf(ChatMessage("user", selectorPrompt))).content
val selectors = Gson().fromJson(selectorsJson, Map::class.java) as Map<String, String>
// 生成されたセレクタを使用して抽出
val document = session.parse(page)
val extractedData = selectors.mapValues { (_, selector) ->
document.selectFirstTextOrNull(selector)
}
return mapOf(
"url" to targetUrl,
"selectors" to selectors,
"data" to extractedData
)
}
}コルーチンによる並列抽出
Browser4のコルーチン対応設計により、効率的な並列CAPTCHA処理が可能です。
kotlin
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.Channel
data class ExtractionJob(
val url: String,
val siteKey: String?
)
data class ExtractionResult(
val url: String,
val data: Map<String, Any?>?,
val captchaSolved: Boolean,
val error: String?,
val duration: Long
)
class ParallelExtractor(
private val capSolver: CapSolverService,
private val concurrency: Int = 5
) {
suspend fun extractAll(jobs: List<ExtractionJob>): List<ExtractionResult> = coroutineScope {
val channel = Channel<ExtractionJob>(Channel.UNLIMITED)
val results = mutableListOf<ExtractionResult>()
// すべてのジョブをチャネルに送信
jobs.forEach { channel.send(it) }
channel.close()
// 並列処理で処理
val workers = (1..concurrency).map { workerId ->
async {
val workerResults = mutableListOf<ExtractionResult>()
// 各ワーカーはスレッドセーフのため独自のセッションを作成
val workerSession = PulsarContexts.createSession()
for (job in channel) {
val startTime = System.currentTimeMillis()
var captchaSolved = false
try {
// サイトキーが提供されている場合CAPTCHAを解決
val token = job.siteKey?.let {
captchaSolved = true
capSolver.solveReCaptchaV2(job.url, it)
}
// データを抽出
val page = workerSession.open(job.url)
token?.let { t ->
val driver = workerSession.getOrCreateBoundDriver()
driver?.evaluate("""
(function(tokenValue) {
var el = document.querySelector('#g-recaptcha-response');
if (el) el.value = tokenValue;
})('$t');
""")
}
val document = workerSession.parse(page)
workerResults.add(ExtractionResult(
url = job.url,
data = mapOf(
"title" to document.selectFirstTextOrNull("title"),
"h1" to document.selectFirstTextOrNull("h1")
),
captchaSolved = captchaSolved,
error = null,
duration = System.currentTimeMillis() - startTime
))
} catch (e: Exception) {
workerResults.add(ExtractionResult(
url = job.url,
data = null,
captchaSolved = captchaSolved,
error = e.message,
duration = System.currentTimeMillis() - startTime
))
}
}
workerResults
}
}
workers.awaitAll().flatten()
}
}
// 使用例
fun main() = runBlocking {
val capSolver = CapSolverService(System.getenv("CAPSOLVER_API_KEY")!!)
val extractor = ParallelExtractor(capSolver, concurrency = 5)
val jobs = listOf(
ExtractionJob("https://site1.com/data", "6Lc..."),
ExtractionJob("https://site2.com/data", null),
ExtractionJob("https://site3.com/data", "6Lc..."),
)
val results = extractor.extractAll(jobs)
val solved = results.count { it.captchaSolved }
println("完了した${results.size}件の抽出、${solved}件のCAPTCHAを解決")
results.forEach { r ->
println("${r.url}: ${r.duration}ms - ${r.error ?: "成功"}")
}
}最適な実践方法
1. エラー処理とリトライ
kotlin
suspend fun <T> withRetry(
maxRetries: Int = 3,
initialDelay: Long = 1000,
block: suspend () -> T
): T {
var lastException: Exception? = null
repeat(maxRetries) { attempt ->
try {
return block()
} catch (e: Exception) {
lastException = e
println("試行${attempt + 1}が失敗: ${e.message}")
delay(initialDelay * (attempt + 1))
}
}
throw lastException ?: Exception("最大リトライ回数に達しました")
}
// 使用例
val token = withRetry(maxRetries = 3) {
capSolver.solveReCaptchaV2(url, siteKey)
}2. バランス管理
kotlin
suspend fun ensureSufficientBalance(
capSolver: CapSolverService,
minBalance: Double = 1.0
) {
val balance = capSolver.checkBalance()
if (balance < minBalance) {
throw Exception("CapSolverの残高が不足しています: $${"%.2f".format(balance)}. 再充電してください。")
}
println("CapSolverの残高: $${"%.2f".format(balance)}")
}3. トークンキャッシュ
kotlin
class TokenCache(private val ttlMs: Long = 90_000) {
private data class CachedToken(val token: String, val timestamp: Long)
private val cache = mutableMapOf<String, CachedToken>()
private fun getKey(domain: String, siteKey: String) = "$domain:$siteKey"
fun get(domain: String, siteKey: String): String? {
val key = getKey(domain, siteKey)
val cached = cache[key] ?: return null
if (System.currentTimeMillis() - cached.timestamp > ttlMs) {
cache.remove(key)
return null
}
return cached.token
}
fun set(domain: String, siteKey: String, token: String) {
val key = getKey(domain, siteKey)
cache[key] = CachedToken(token, System.currentTimeMillis())
}
}
// キャッシュを使用する例
class CachedCapSolver(
private val capSolver: CapSolverService,
private val cache: TokenCache = TokenCache()
) {
suspend fun solveReCaptchaV2Cached(websiteUrl: String, websiteKey: String): String {
val domain = java.net.URL(websiteUrl).host
cache.get(domain, websiteKey)?.let {
println("キャッシュされたトークンを使用")
return it
}
val token = capSolver.solveReCaptchaV2(websiteUrl, websiteKey)
cache.set(domain, websiteKey, token)
return token
}
}設定オプション
| 設定 | 説明 | デフォルト |
|---|---|---|
CAPSOLVER_API_KEY |
CapSolverのAPIキー | - |
OPENROUTER_API_KEY |
LLM機能用のOpenRouter APIキー | - |
PROXY_ROTATION_URL |
プロキシローテーションサービスのURL | - |
Browser4は追加の設定にapplication.propertiesを使用します |
結論
CapSolverをBrowser4に統合することで、高スループットのウェブデータ抽出が可能になります。Browser4のコルーチンセーフなアーキテクチャと極限のパフォーマンス能力、CapSolverの信頼性のあるCAPTCHA解決機能を組み合わせることで、スケーラブルな抽出が実現できます。
キーパターン:
- トークンの直接挿入: JavaScript評価を通じて解決されたトークンを挿入
- 事前認証: 抽出前にセッションを確立するためにCAPTCHAを解決
- 並列処理: コルーチンを使って同時CAPTCHA処理を活用
- X-SQL統合: CAPTCHA解決をBrowser4の強力なクエリ言語と組み合わせ
価格モニタリングシステム、市場研究パイプライン、データ集約プラットフォームの構築にかかわらず、Browser4 + CapSolverの組み合わせは、本番環境で必要な信頼性とスケーラビリティを提供します。
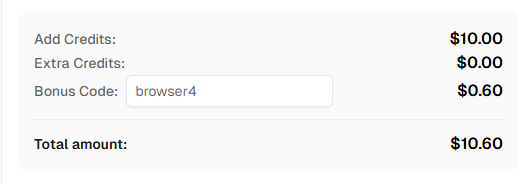
開始する準備はできましたか? CapSolverに登録 そして、初回チャージで6%のボーナスを獲得するためのボーナスコード BROWSER4 を使ってください!
質問と回答
Browser4とは何ですか?
Browser4は、PulsarRPAから提供される高パフォーマンスでコルーチンセーフなブラウザ自動化フレームワークです。Kotlinで構築され、AI駆動のデータ抽出をサポートし、1台のマシンで1日あたり10万〜20万件の複雑なページアクセスを処理できます。
CapSolverはBrowser4とどのように統合されますか?
CapSolverは、CapSolver APIを介してCAPTCHAを解決するサービスクラスを通じてBrowser4に統合されます。解決されたトークンは、Browser4のJavaScript評価機能(driver.evaluate())を使用してページに挿入されます。
CapSolverが解決できるCAPTCHAの種類は何ですか?
CapSolverはreCAPTCHA v2、reCAPTCHA v3、Cloudflare Turnstile、Cloudflare Challenge(5秒)、AWS WAF、GeeTest v3/v4など、多くの種類のCAPTCHAをサポートしています。
CapSolverの料金はどのくらいですか?
CapSolverは、解決するCAPTCHAの種類とボリュームに基づいて競争力のある料金を提供しています。現在の料金についてはcapsolver.comを参照してください。ボーナスコード BROWSER4 を使用すると6%のボーナスが得られます。
Browser4はどのプログラミング言語で構築されていますか?
Browser4はKotlinで構築され、JVM(Java 17以上)で動作します。Javaアプリケーションからも使用できます。
Browser4は並列CAPTCHA解決を処理できますか?
はい!Browser4のコルーチンセーフな設計により、効率的な並列処理が可能です。CapSolverのAPIと組み合わせることで、異なる抽出ジョブで複数のCAPTCHAを同時に解決できます。
CAPTCHAのサイトキーを見つける方法は?
サイトキーは通常、ページのHTMLソースにあります:
- reCAPTCHA:
.g-recaptcha要素のdata-sitekey属性 - Turnstile:
.cf-turnstile要素のdata-sitekey属性 - または、API呼び出しでキーパラメータを確認
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
