信頼性の高いデータ抽出のための最高のJavaウェブスクラピングライブラリ

Sora Fujimoto
AI Solutions Architect

TL;DR
- Javaのウェブスクレイピングライブラリは、人気ではなくページの種類によって選ぶべきです。
- jsoupは静的HTMLの解析とセレクターに基づく抽出に最適です。
- Selenium Javaスクレイピングは、実際のブラウザ操作が必要なページに適しています。
- Playwright for Javaは、現代のJavaScript重視のワークフローに強みがあります。
- HtmlUnitは、フルブラウザなしで軽量なブラウザ風のタスクに適しています。
- Apache Nutchは、企業向けクローリングとインデックス作成に適しています。
- CAPTCHA、スケール、操作が主な要件の場合は、ウェブスクレイピングAPIがより良い選択です。
イントロダクション
最高のJavaウェブスクレイピングライブラリは、ターゲットページがデータをどのように提供するかに依存します。静的ページは高速な解析が必要です。動的ページはブラウザの自動化が必要です。大規模なクロールプログラムはキューイング、インデックス作成、モニタリングが必要です。CAPTCHAワークフローは、壊れやすいカスタムロジックではなく、文書化されたサービスで処理すべきです。このガイドは、jsoup、Selenium Javaスクレイピング、Playwright for Java、HtmlUnit、Apache Nutch、Javaクローラーフレームワークオプション、およびウェブスクレイピングAPIの間で開発者に選択を助けます。最小限で信頼性の高いツールを使用し、サイトのルールに従い、ワークフローを保守可能に保つことが重要です。
なぜJavaがウェブスクレイピングに使われるのか
プロジェクトが数か月ではなく数分間実行される必要がある場合、Javaは強力なスクレイピング言語です。型付きコード、安定した依存関係管理、成熟したHTTPクライアント、運用に適した観測性をサポートしています。OracleはJavaを、開発時間を短縮し、Javaモデルを通じて環境間でアプリケーションを実行する主要な開発プラットフォームとして説明しています Oracle Java。
Javaウェブスクレイピングライブラリは企業の習慣にも合います。チームはリトライ、ログ、レートリミット、テスト、アクセス制御を追加できます。Javaはプロトタイプでは最速ではないかもしれませんが、信頼性と保守性が重要になる場合に魅力的になります。
鍵はツールをコンテンツに合わせることです。パーサーはReactページをレンダリングできません。静的HTMLにはブラウザが無駄です。クローラーフレームワークは1つの製品ページには重すぎます。最高のJavaウェブスクレイピングライブラリは明確な問題を解決します。
比較サマリー
| ツール | 最適な用途 | JavaScriptの処理 | スケールの適合性 | 主な制限 |
|---|---|---|---|---|
| jsoup | 静的HTMLの解析 | なし | 中程度 | レンダリングには他のツールが必要 |
| HttpClient + jsoup | コントロールされた静的スクレイピング | なし | 中程度から高 | カスタムフェッチロジックが必要 |
| Selenium | ブラウザの自動化 | 強 | 低から中 | 高コストのランタイムと壊れやすいセレクター |
| Playwright for Java | 現代的なブラウザの自動化 | 強 | 中程度 | ブラウザランタイムの管理が必要 |
| HtmlUnit | 軽量なブラウザ風のフロー | 部分的から良好 | 中程度 | フルブラウザの代替にはならない |
| WebMagic or Gecco | Javaクローラーフレームワークプロジェクト | 限られている | 中程度 | エコシステムが小さい |
| Apache Nutch | 企業向けクローリングとインデックス作成 | 限られている | 高 | 設定と運用が複雑 |
| ウェブスクレイピングAPI | マネージドスクレイピング操作 | プロバイダーが処理 | 高 | 直接制御が少ない |
Javaの静的ウェブスクレイピングライブラリ
静的スクレイピングはパーサーから始めるべきです。最初のHTML応答に必要なデータが含まれている場合、ブラウザの自動化は正確性を向上させずにコストがかかります。このカテゴリのJavaウェブスクレイピングライブラリは高速で、テスト可能で、運用が簡単です。
jsoupによるHTMLパース
jsoupは静的HTMLの最初の選択肢として最適です。公式サイトでは、実際のHTMLとXMLのJavaHTMLパーサーとして、URLフェッチ、パース、DOMメソッド、CSSセレクター、XPathセレクターを備えていると説明しています jsoup公式ドキュメンテーション。
記事ページ、カテゴリページ、シンプルな製品ページ、テーブル、HTMLフラグメントにjsoupを使用してください。不完全なマークアップを処理する能力があります。多くのページがブラウザで読み取れるが、厳密なXMLツールには十分ではないため、これは重要です。
信頼性のあるjsoupワークフローは直接的です。明確なヘッダーでページをリクエストします。ドキュメントをパースします。安定したCSSセレクターでフィールドを選択します。保存前に空の値を検証します。このパターンはJavaウェブスクレイピングライブラリを予測可能に保ちます。
jsoupはブラウザではありません。JavaScriptを実行しません。スクリプトが実行された後にのみコンテンツが表示される場合、ネットワーク呼び出しを最初に確認してください。許可されたエンドポイントがある場合は、HTTPクライアントを使用してください。ブラウザの動作が必要な場合は、SeleniumまたはPlaywright for Javaを使用してください。
HttpClient + jsoupアプローチ
HttpClientとjsoupは、制御された静的スクレイピングに最適です。JavaのHTTPクライアントはヘッダー、タイムアウト、リダイレクト、レスポンスボディを管理できます。その後、jsoupでHTMLをパースします。この分離により、フェッチとパースがクリーンになります。
このアプローチは価格モニタリング、公開ディレクトリ、コンテンツ監査、リサーチデータセットに適しています。トレース、リトライルール、クロール遅延、プロキシ構成が必要な場合、直接的なjsoupフェッチよりも優れています。
動的ウェブスクレイピングライブラリのJava
動的ページにはブラウザの動作が必要です。スクロール、クリック、認証、またはバックグラウンドリクエスト後にコンテンツがロードされる場合があります。Selenium Javaスクレイピング、Playwright for Java、HtmlUnitはこれを異なる方法で解決します。
Seleniumによるブラウザの自動化
Seleniumは成熟し、広く文書化されています。公式プロジェクトでは、Seleniumを主要ブラウザで指示を実行するためのツールとライブラリと説明しています Seleniumドキュメンテーション。
サイトが実際のブラウザ操作を必要とする場合、Selenium Javaスクレイピングは動作します。ボタンのクリック、要素の待機、フォームの送信、レンダリングされたDOMの読み取りが可能です。すでにQAテストでSeleniumを使用しているチームにも適しています。
コストのトレードオフがあります。ブラウザセッションはCPUとメモリを消費します。インターフェースが変更されるとセレクターが壊れる可能性があります。ブラウザの正確性が速度よりも重要である場合にのみSelenium Javaスクレイピングを使用してください。
認証テストや許可された自動化でCAPTCHAが表示される場合、壊れやすいスクリプトの中に隠さないでください。まずターゲットルールを確認してください。その後、CapSolverのSelenium CAPTCHA統合などの文書化されたワークフローを使用してください。
Playwright for Java
Playwright for Javaは現代の自動化に強みがあります。公式のJavaサイトでは、Chromium、Firefox、WebKitを1つのAPIで駆動でき、Javaサポートが利用可能であると説明しています Playwright for Javaドキュメンテーション。
Playwright for Javaは頻繁な自動化を減少させます。自動待機、ブラウザコンテキスト、トレース、耐障害性のあるロケーターがワークフローを安定させます。スクリーンショット、ダウンロード、マルチページナビゲーション、信頼性のある待機が必要なJavaウェブスクレイピングライブラリプロジェクトに適しています。
ページがJavaScript重視で、繰り返し可能なブラウザコンテキストが重要である場合、Playwright for Javaを選択してください。単純なHTTPリクエストで同じデータが返される場合は避けてください。ブラウザは最後の必要層であり、最初の習慣ではありません。
許可された自動化でCAPTCHAがある場合、ワークフローを公式ガイドに接続してください。CapSolverはPlaywright CAPTCHA統合を公開しており、ランダムなスニペットをコピーするよりも安全です。
HtmlUnitによる軽量JS処理
HtmlUnitはパーサーと完全なブラウザ自動化の間の位置にあります。公式サイトでは、「Javaプログラム用のGUIレスブラウザ」と呼ばれ、ページの呼び出し、フォームの入力、リンクのクリック、クッキーの管理、多くのAJAXワークフローのJavaScriptサポートを提供しています HtmlUnitドキュメンテーション。
古いサイト、シンプルなフォームフロー、内部ツール、テストシステムにHtmlUnitを使用してください。フルブラウザ自動化よりも軽量です。中程度の作業量ではインフラストラクチャーコストを削減できます。
HtmlUnitはChrome、Firefox、WebKitの完全な代替ではありません。現代のフロントエンドフレームワークはギャップを露呈する可能性があります。視覚的なレンダリングや複雑なイベントが重要な場合、SeleniumまたはPlaywright for Javaがより安全です。
大規模クローリング用のJavaウェブスクレイピングフレームワーク
大規模なクローリングはページ抽出とは異なります。フロントイア管理、重複排除、リトライルール、礼儀の制御、パース、インデックス作成、モニタリングが必要です。スクリーパーがシステムになる場合、Javaクローラーフレームワークは役立ちます。
WebMagicとGecco
WebMagicとGeccoは中規模プロジェクトの実用的なJavaクローラーフレームワークオプションです。ダウンローダロジック、ページプロセッサ、パイプライン、データモデルを構造化します。これにより、チーム間でコードを分割しやすくなります。
公開カタログ、ドキュメントミラー、定期的なコンテンツ発見、類似ページに使用してください。レンダリングレイヤーと組み合わさない限り、非常に動的なページには不向きです。主な強みは保守性であり、主な弱みはjsoup、Selenium、またはPlaywrightほど大きなエコシステムではないことです。
Apache Nutchによる企業向けクローリング
Apache Nutchは大規模なクロールプログラムに設計されています。ホームページでは、非常に拡張可能で、スケーラブルで、成熟し、運用可能なウェブクローラーとして説明されています Apache Nutchプロジェクト。プラグ可能パース、インデックス、スコアリング、検索システムとの統合をサポートしています。
クローリングがプラットフォームの要件である場合、Apache Nutchを使用してください。検索インデックス作成、企業内発見、定期的な大規模なデータ取得に適しています。小さな1回限りのスクリーパーには不適です。設定と運用には実際のエンジニアリング時間がかかります。
Javaクローラーフレームワークをスケーリングする前に、許可されたドメイン、更新頻度、ストレージルール、リクエスト制限を定義してください。ウェブスクレイピングの合法性と主要ルールに関するCapSolverのガイドは計画に役立ちます。
JavaスクレイピングにおけるCAPTCHAの課題
CAPTCHAは技術的な問題ではなくワークフローのシグナルです。レート圧力、ログインリスク、アクセスルール、または権限の欠如を示す可能性があります。慎重に扱ってください。あなたの使用ケースが許可されていることを確認し、リクエスト量を最小限に抑え、必要なデータのみを収集してください。
Javaウェブスクレイピングライブラリは独自にCAPTCHAを解決しません。jsoupはチャレンジとインタラクティブできません。SeleniumとPlaywrightは表示できますが、有効な処理プロセスが必要です。HtmlUnitはこのタスクの適切なレイヤーではありません。
CapSolverは、正当な自動化プロセスでCAPTCHA処理が必要な場合に関連しています。例として、QAテスト、アカウント所有ワークフロー、許可されたスクレイピングがあります。公式CapSolver APIドキュメンテーションでは、タスク作成と結果取得のコアエンドポイントとしてcreateTaskとgetTaskResultがリストされています CapSolver APIドキュメンテーション。実装詳細は公式ドキュメンテーションを直接使用してください。
安全なプロセスは単純です。ターゲットを文書化し、許可を確認し、リクエストレートを制限し、必要なフィールドのみを保存してください。ウェブスクレイピングとCAPTCHAソルビングAPIに関するCapSolverのFAQは計画に役立ちます。
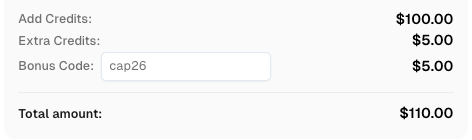
CapSolverのボーナスコードを取得する
すぐに自動化予算を増やそう!
CapSolverアカウントにチャージする際にボーナスコード CAP26 を使用すると、すべてのチャージで5%のボーナスを追加で受け取れます — 限界なし。
今すぐCapSolverダッシュボードで取得してください。
ライブラリではなくウェブスクレイピングAPIを使用するべきタイミング
操作がコードの制御よりも重要である場合、ウェブスクレイピングAPIを使用してください。Javaウェブスクレイピングライブラリは柔軟ですが、チームはブラウザランタイム、リトライ、モニタリング、パーサードリフト、CAPTCHAワークフローを管理する必要があります。
高ボリュームの収集、不安定なフロントエンド、JavaScript重視のページ、スクレイピングインフラストラクチャを持たないチームには、ウェブスクレイピングAPIが適しています。ブラウザファームの必要性を減らすこともできます。トレードオフはベンダー依存性であり、データ品質、料金、ログ、コンプライアンス条件を確認してください。
ハイブリッドモデルが最も良い場合があります。安定した静的ページにはjsoupを使用してください。小さな動的フローにはSelenium JavaスクレイピングまたはPlaywright for Javaを使用してください。クローリングが検索プラットフォームになる場合はApache Nutchを使用してください。インフラストラクチャが主要な作業量になる場合はウェブスクレイピングAPIを使用してください。CapSolverの一般的なウェブスクレイピングの課題に関するガイドは、チームが準備するのに役立ちます。
結論とCTA
最高のJavaウェブスクレイピングライブラリは、ヒットではなく、適合性でランク付けされます。jsoupは静的HTMLに最適です。HttpClientとjsoupは制御を追加します。Selenium JavaスクレイピングとPlaywright for Javaは動的ページを処理します。HtmlUnitは軽量なブラウザ風のフローをカバーします。WebMagic、Gecco、Apache Nutchはクローラーアーキテクチャをサポートします。インフラストラクチャコストが増える場合は、ウェブスクレイピングAPIを使用してください。
小さなスタートとコンプライアンスを保ちましょう。サイトのルールを読み、レートリミットを尊重し、収集を最小限に抑え、ログを保持してください。許可されたワークフローでCAPTCHAが表示される場合は、公式ドキュメンテーションと専門のプロバイダー、CapSolverを使用してください。
FAQ
最も良いJavaウェブスクレイピングライブラリは何ですか?
静的HTMLにはjsoupが最適です。JavaScript重視のページにはPlaywright for JavaまたはSeleniumがより良いです。企業向けクローリングにはApache Nutchがより良いです。
Selenium JavaスクレイピングはPlaywright for Javaよりも良いですか?
Seleniumは歴史とエコシステムサポートが広いです。Playwright for Javaは自動化の現代的な機能、例えば自動待機とブラウザコンテキストを多く提供します。
jsoupは動的ウェブサイトをスクレイピングできますか?
jsoupは返されたHTMLをパースできますが、JavaScriptを実行しません。スクリプトが実行された後にのみコンテンツが表示される場合は、ブラウザの自動化を使用してください。
Apache Nutchは小さなスクレイピングプロジェクトに適していますか?
通常はいいえです。Apache Nutchは強力ですが、大規模なクロールシステム、検索インデックス作成、企業向けデータ取得に適しています。
JavaスクレイピングでCapSolverを使用すべきタイミングはいつですか?
CapSolverは、CAPTCHA処理が許可されている正当で文書化された自動化でのみ使用してください。CapSolverの公式APIドキュメンテーションとターゲットサイトのルールに従ってください。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
