2026年の最高の代替データプロバイダー (比較対象のトッププラットフォーム)

Sora Fujimoto
AI Solutions Architect
TLDR: 代替データ市場は、コンプライアンス、AI駆動型分析、データの粒度へのシフトによって特徴付けられています。2026年における最高の代替データプロバイダーは、データソースの透明性と専門的なドメイン知識を提供する企業です。当社が選んだプラットフォームであるYipitData、FactSet、Eagle Alphaは、優れたデータ品質、リアルタイム配信、堅牢なコンプライアンスフレームワークに基づいてランク付けされており、投資家や企業インテリジェンスの専門家にとって重要な競争優位性を提供します。

現代のビジネスインテリジェンスの競争環境は、タイムリーで非伝統的な情報へのアクセスにかかっています。代替データプロバイダーは、実験的なリソースからコアな戦略的資産へと進化し、投資意思決定と市場予測を推進しています。Precedence Researchによると、市場の価値は2026年に210億ドルを超えると予測されており、その不可欠な性質を示しています。このガイドでは、トッププラットフォームの詳細な比較分析を提供し、購入意思決定に必要な実用的な洞察、強み、弱みに焦点を当てています。2026年における適切なプロバイダーの選定には、検証可能なデータソースとシームレスな統合能力の優先が求められます。
新たな必須条件:なぜ2026年はより良いデータを必要とするのか
代替データエコシステムは急速に成熟しており、プロバイダーがより高い品質とコンプライアンスの基準を満たすことを求めています。市場を形作る主なトレンドは、選ばれた代替データプロバイダーに新たなレベルの熟練を必要としています。
1. コンプライアンスとデータソースの透明性がコア機能
特に消費者プライバシー(GDPR、CCPA)に関する規制の厳格化により、規制監視が強化されています。リーディングプロバイダーは、データソースの明確で検証可能な履歴であるデータソースを主な機能として扱い、後付けではなく、主な機能として扱っています。透明なソースと適切な匿名化が欠如したデータは、重大な法的リスクをもたらします。
2. AI駆動型分析とデータ統合
非構造化データ(例: サテライト画像、ソーシャルメディアテキスト)の膨大な量により、手動分析は不可能です。代替データプロバイダーは、複数モードのデータ統合を活用して、異なるソースを組み合わせてより予測可能なシグナルを作成しています。これは、市場の感情を正確に把握するための高度な自然言語処理(NLP)を含みます。
3. 精細さとリアルタイム配信の追求
代替データの価値は、その詳細さとスピードに比例しています。投資家は、単一店舗の日次来店客数やリアルタイム製品在庫変化などのマイクロレベルのデータを求めるため、低遅延のデータパイプラインは現在、最高の代替データプロバイダー間での重要な差別化要因となっています。
最も優れた代替データプロバイダーのランク付け:詳細な基準
当社のランク付けは、単純な機能リストを越えて、各プラットフォームの実用性とリスク低減能力に焦点を当てています。以下の基準が比較分析の基盤となっています。
| ランク付け基準 | 説明 | 実用的影響 |
|---|---|---|
| データの粒度と独自性 | 詳細度(例: 個別店舗レベル)とデータセットの排他性。 | 予測モデルの精度とアルファシグナルの独自性を決定する。 |
| コンプライアンスとデータソースの透明性 | データソースの透明性とグローバルプライバールール(GDPR、CCPA)への準拠。 | 終端ユーザーの法的および評判リスクを軽減する。 |
| 統合とワークフロー | API統合のしやすさ、BIツールとの互換性、マネージドサービスの有無。 | データサイエンスチームのタイム・トゥ・インサイトと運用オーバーヘッドを削減する。 |
| リアルタイム機能 | データ更新の頻度と速度、ハイフリクエンシー戦略にとって不可欠。 | 市場動向イベントに迅速に対応するための必須条件。 |
| ドメイン専門性 | 特定のデータ垂直分野(例: イーコマース、ジオスペース)におけるプロバイダーの専門知識の深さ。 | データが専門家によってキュレーションされ検証されていることを確保する。 |
2026年の上位6社の代替データプロバイダー:詳細レビュー
以下のプラットフォームは、市場リーダーシップと特化した提供により、最高の代替データプロバイダーとして認識されています。
1. YipitData: イーコマースと取引インテリジェンスのリーダー
YipitDataは、消費者支出とイーコマースデータの基準として残っています。その強みは、電子メールの領収書と取引データを処理し、公式の決算発表よりも前に企業のパフォーマンスに関する非対称な洞察を提供することにあります。データは非常に細かく、特定のブランドや製品カテゴリへの深い掘り下げが可能です。厳格なデータクリーニングと正規化プロセスにより、高精度が保証されます。
YipitDataの考慮事項:
- 長所: 消費者支出における非対称な粒度; 決算電話の予測力が非常に高い; データ品質とクリーニングが優れている。
- 短所: 非常に高価で、小規模ファンドにはアクセス不可能; 消費者向けセクターに限定; プロセッシングのために数日遅延する場合がある。
- 最適な対象: 小売、イーコマース、テクノロジー分野に焦点を当てたヘッジファンドや機関投資家。
- 価格の洞察: カスタム、エンタープライズレベルの価格; 通常、年間で数十万ドルから始まる。
2. FactSet: 統合と集約の強みを持つプラットフォーム
FactSetは、主に金融データと分析プラットフォームとして、サードパーティの代替データを統合する強みを持っています。伝統的な金融データと代替データセットを一緒に分析できる統一された環境を提供し、大規模な機関投資家にとってワークフローを簡単にする。FactSetは主なデータ収集者ではなく、必須の集約者です。
FactSetの価値提案は、シームレスな統合です。大規模な資産運用会社や投資銀行にとって、単一でコンプライアンスに準拠したプラットフォーム内で数百のデータセットにアクセスできる能力は大きな利点です。プラットフォームのコストは高めですが、複数のベンダー関係とデータフローを管理する内部運用コストを削減することがよくあります。そのコンプライアンス基準は非常に高く、代替データプロバイダーの中で重要な差別化要因です。
3. Eagle Alpha: データマーケットプレイスとアドバイザリーの専門家
Eagle Alphaは、データ購入者とニッチなデータ販売者との間の重要な仲介者として機能します。そのコア価値は、アドバイザリーサービスであり、クライアントが複雑なデータ環境をナビゲートし、ニッチなデータセットを特定するのを支援します。ソーシャルメディアの感情からサテライト画像に至るまで、多様なデータタイプを提供する能力に長けています。
| 特徴 | 長所 | 短所 |
|---|---|---|
| マーケットプレイス | 多様なデータタイプの豊富な品揃え; データ発見とテストに理想的。 | データ品質とコンプライアンスはベンダーごとに大きく異なる。 |
| アドバイザリー | 優れた実地調査とコンプライアンスサポート; ニッチなデータの特定を支援。 | 内部リソースが必要で、複数のベンダー関係を管理する必要がある。 |
| 最適な対象 | データ発見段階の企業や、非常に専門的なニッチデータセットを求める企業。 |
4. Thinknum: ウェブデータと競合インテリジェンスの専門家
Thinknumは、公開ウェブからデータを抽出し構造化することに特化しており、求人情報、製品価格、ウェブトラフィック信号などの競合インテリジェンスメトリクスに焦点を当てています。そのプラットフォームは、新しいデータフィードの迅速な展開を設計しており、市場の変化に非常に迅速に対応できます。
Thinknumは特に競合インテリジェンスと労働市場トレンドの追跡に強みを持っています。そのプラットフォームは非常に柔軟で、公開されたソースから導かれる特定の企業メトリクスを追跡することができますが、ユーザーはそのデータが公開されたウェブソースに限定され、ウェブサイト構造の変化に敏感であることを認識する必要があります。このため、データの整合性を確保するための継続的なモニタリングが必要であり、代替データプロバイダーの中で企業戦略チームにとって動的なプレイヤーです。
5. Preqin: プライベートマーケットの権威
Preqinは、プライベート資本市場(プライベートエクイティ、ベンチャーキャピタル、不動産、インフラ)に関するデータの決定的なソースです。プライベート資産に焦点を当てていますが、ファンドパフォーマンスと取引フローに関する独自で検証済みのデータにより、長期投資家にとって重要な代替データソースとなっています。独自データの深さと品質は、特にプライベートマーケットにおいて長期的な投資戦略の信頼できる基盤を提供します。
最適な対象: プライベートエクイティファンド、ベンチャーキャピタルファンド、機関投資家のリミテッドパートナー(LP)。
価格の洞察: 高コスト、年次サブスクリプションモデル; 価格はモジュールとデータアクセスレベルに基づく。
制限: プライベートマーケットの性質上、リアルタイムではないため、パブリックエクイティ戦略には限界がある。
6. SimilarWeb: デジタルトラフィックとエンゲージメントの専門家
SimilarWebは、ウェブサイトトラフィック、モバイルアプリ使用状況、デジタルエンゲージメントメトリクスに関する包括的なデータを提供します。このデータは、パブリックおよびプライベート会社のデジタル健康状態と市場シェアを評価する上で不可欠であり、代替データプロバイダーの中で重要なプレイヤーです。
提供内容の概要:
- データの焦点: ウェブサイトトラフィック、モバイルアプリ使用状況、デジタル市場シェア。
- 長所: グローバルウェブサイトとアプリの広範なカバー; 強力な競合ベンチマーキングツール; データは頻繁に更新される。
- 短所: パネルと推定モデルに基づくデータであり、小さなサイトでは正確性に制限がある; グラニュラーアクセスのための高コスト。
データ収集エンジン: ウェブスクレイピングとCapSolver
最高の代替データプロバイダーが提供するデータの品質は、通常、公開ウェブから大量の情報を収集する能力に依存しています。このプロセスは、ウェブスクレイピングと知られており、競合インテリジェンスとイーコマースデータセットのバックボーンです。しかし、これらのデータパイプラインを維持することは、複雑なアンチボット対策とCAPTCHAに常に戦っている戦いです。
データを自社で収集するか、データフローを確保する必要があるプロバイダーのために、信頼性の高いインフラが不可欠です。ここでの役割を果たすのが、CapSolverのようなサービスです。CapSolver は、複雑なCAPTCHAとアンチボットチャレンジを自動的に解決するAI駆動型ソリューションを提供し、データ収集が安定してスケーラブルであることを保証します。このようなサービスを統合することで、データチームはブロックされることなく、リアルタイム性を維持できます。技術の裏側を理解するには、ウェブクローリングとウェブスクレイピングの比較を参照してください。
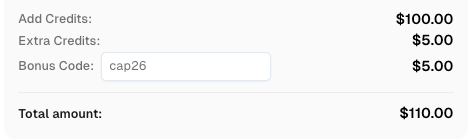
CapSolverで登録する際、コード CAP26 を使用してボーナスクレジットを取得してください!
購入ガイド: 適切な代替データプロバイダーの選定
代替データプロバイダーの中から選ぶには、特定のビジネス質問にデータを一致させる構造化されたアプローチが必要です。
ステップ1: アルファシグナルを定義する
テストしようとしている仮説を明確に述べます。小売店の来店客数を追跡していますか(ジオスペースデータ)?四半期収益を予測していますか(取引データ)?答えは必要なデータタイプを決定し、結果として最も適切なプロバイダーを決定します。
ステップ2: データソースとコンプライアンスを評価する
データがどのように収集され、匿名化され、集約されたかの詳細な説明を要求してください。プロバイダーは、すべての関連規制に準拠していることを法的保証する必要があります。この調査は、規制リスクを軽減するために不可欠です。
ステップ3: データ品質と予測力のテスト
常にプロトタイプ(POC)または歴史的なデータサンプルを要求してください。データは既存のモデルに対してテストされ、統計的に有意な予測シグナルを生成する能力を確認する必要があります。高コストのサブスクリプションにコミットする前に、これは重要なステップです。
ステップ4: 統合とサポートを評価する
全体的な所有コストを考慮してください。データのクリーニング、統合、維持に必要な努力を含みます。FactSetのようなデータサイエンティスト向けに堅牢なAPIと専門サポートを提供するプロバイダーは、内部運用コストを削減することで、より高い価格を正当化することがよくあります。
代替データプロバイダーを形作る今後のトレンド
今後、市場は2つの主要な分野で定義されるでしょう: データ統合と規制の明確化。データ統合は、サテライト画像とソーシャルメディアの感情を組み合わせるなど、異なるデータセットを統合することを意味し、これにより企業や市場のより包括的なビューが得られます。このマルチモーダルアプローチは、アルファ生成の次のフロンティアとなるでしょう。さらに、特に消費者プライバシーに関連するグローバルな規制環境は、どの代替データプロバイダーが成功して運営できるかを継続的に形作ることになります。プライバシー強化技術に早期に投資するプロバイダーは、大きな競争優位性を得ることになります。
英語のテキストを日本語に翻訳します。
代替データプロバイダーを選ぶことは重要ですが、データ収集インフラは長期的な競争優位性の源泉であることを組織は認識すべきです。独自のデータセットを構築するか、第三者のシグナルを検証するかに関わらず、2026年の安定したウェブデータ取得は不可欠です。CapSolverは、CAPTCHAやアンチボットシステムを信頼性高く処理することで、データチームがスラッピングパイプラインを途切れることなく運用できるようにし、代替データがタイムリーでコンプライアンスに合致し、スケーラブルであることを保証します。スピードやデータの新鮮さが意思決定の質に直接影響を与える環境において、堅牢なインフラはもはやオプショナルではなく、基本的なものとなっています。
結論
2026年の代替データプロバイダーの市場は、専門性、コンプライアンス、データ品質によって特徴づけられます。高品質でタイムリーかつ検証可能なデータは、組織に競争優位性を提供します。リアルタイムのパイプラインを維持し、アンチボットの課題を回避するためには、CapSolverなどのツールが不可欠であり、データ収集が安定性、スケーラビリティ、信頼性を保つことを確保します。
主なポイント
- 専門性が勝つ: 例えば、eコマース向けのYipitDataや私募市場向けのPreqinなど、最も価値のあるプロバイダーは深いドメインの専門知識を提供します。
- リスクの軽減: コンプライアンスと明確なデータの出所は、すべての信頼できる代替データプロバイダーにとって不可欠な特徴です。
- アルファのコスト: 高品質でユニークな代替データは依然として高価ですが、その予測力によってコストはしばしば正当化されます。
- インフラが重要: 安定したデータ収集は、アンチボットシステムを回避するための堅牢なツール(例: CapSolver)を必要とする場合があり、すべてのリアルタイム代替データの基盤となります。
- 将来の焦点: AI駆動のデータ統合やマルチモーダル分析に投資しているプロバイダーに注目すべきです。
よくある質問
Q: 伝統的なデータと代替データの主な違いは何ですか?
A: 伝統的なデータには財務諸表、市場価格、経済指標が含まれます。代替データは、ウェブスクレイピング、衛星画像、ソーシャルメディア、取引記録などから収集される非伝統的なデータであり、前向きでリアルタイムな視点を提供します。
Q: 購入する代替データがコンプライアンスに合致していることをどうやって確認できますか?
A: プロバイダーが匿名化、集約、同意に関する明確なポリシーを持っていることを確認する必要があります。GDPRやCCPAなどのグローバル基準に準拠しているプロバイダーを選び、データの出所に関する契約上の保証を求めることが重要です。
Q: 公開株式投資家にとって最も価値のある代替データはどれですか?
A: 取引データ(例: クレジットカードや電子メールの領収書データ)やウェブトラフィック/エンゲージメントデータ(例: SimilarWeb)が最も価値があるとされています。これは、企業の収益や市場シェアに関する早期で定量的なシグナルを提供するためです。
Q: なぜ一部の代替データプロバイダーは高価なのでしょうか?
A: 高価な理由は、スケールを確保しながら、厳格なコンプライアンスとデータの整合性を維持する上で、収集、クリーニング、構造化、検証が困難で高コストであるためです。
Q: 代替データを購入する代わりに自分で収集することはできますか?
A: はい、多くの企業がセルフサービス型のデータ収集に移行しています。これは、ウェブスクレイピングインフラ、プロキシ管理、アンチボット回避ソリューション(例: CapSolver)への大規模な投資を必要とします。データパイプラインが安定性とスケーラビリティを確保できるようにするためです。
もっと見る
Web ScrapingApr 22, 2026
Rust Web Scraping Architecture for Scalable Data Extraction
スケーラブルなRustウェブスクレイピングアーキテクチャを学びましょう。リクエスト、スクレイパー、非同期スクレイピング、ヘッドレスブラウザスクレイピング、プロキシローテーション、およびコンプライアンス対応のCAPTCHA処理で。
Web ScrapingFeb 10, 2026
データ・アズ・ア・サービス(DaaS):それは何か、そしてなぜ2026年において重要なのか
2026年のデータ・アズ・ア・サービス(DaaS)を理解する。その利点、ユースケース、およびリアルタイムの洞察と拡張性を通じて企業を変革する方法について探る。
