WebスクレイピングにおけるreCAPTCHA Enterpriseのチャレンジの解決方法

Emma Foster
Machine Learning Engineer
TL;DR
reCAPTCHA Enterpriseは、自動トラフィックを検出およびブロックするためのGoogleの高度なスコアベースのセキュリティシステムです。これは、ウェブスクリーピングプロジェクトにおいて特に困難な課題となります。従来のCAPTCHAとは異なり、ユーザーの行動を評価し、リスクスコアを割り当てます。このガイドでは、reCAPTCHA v3 Enterpriseの仕組み、enterprise.jsスクリプトを介した識別方法、およびCapSolverなどのツールの統合(プロキシをオプションで使用)について説明します。これにより、有効なトークンを信頼性高く取得し、スクリーピングワークフローを効率的でスケーラブルに保つことができます。

私は最初にウェブスクリーピングプロジェクトでreCAPTCHA Enterpriseに遭遇したとき、それがどれほど困難であるかすぐに気づきました。これらの高度なセキュリティ対策を乗り越えるのは簡単ではありませんでしたが、試行錯誤を通じて、すべてに違いをもたらす戦略を開発しました。このガイドでは、reCAPTCHA Enterpriseの課題を乗り越える私のアプローチを紹介し、スクリーピングタスクがスムーズに進行することを保証します。私が最も効果的だと感じたテクニックを順を追って説明します。
reCAPTCHA Enterpriseについて
reCAPTCHA Enterpriseは、サイトを詐欺やスクリーピングから保護するためのGoogleの高度なサービスです。適応型リスクエンジンを使用して、ユーザーの相互作用を評価し、不正アクセスを防止します。
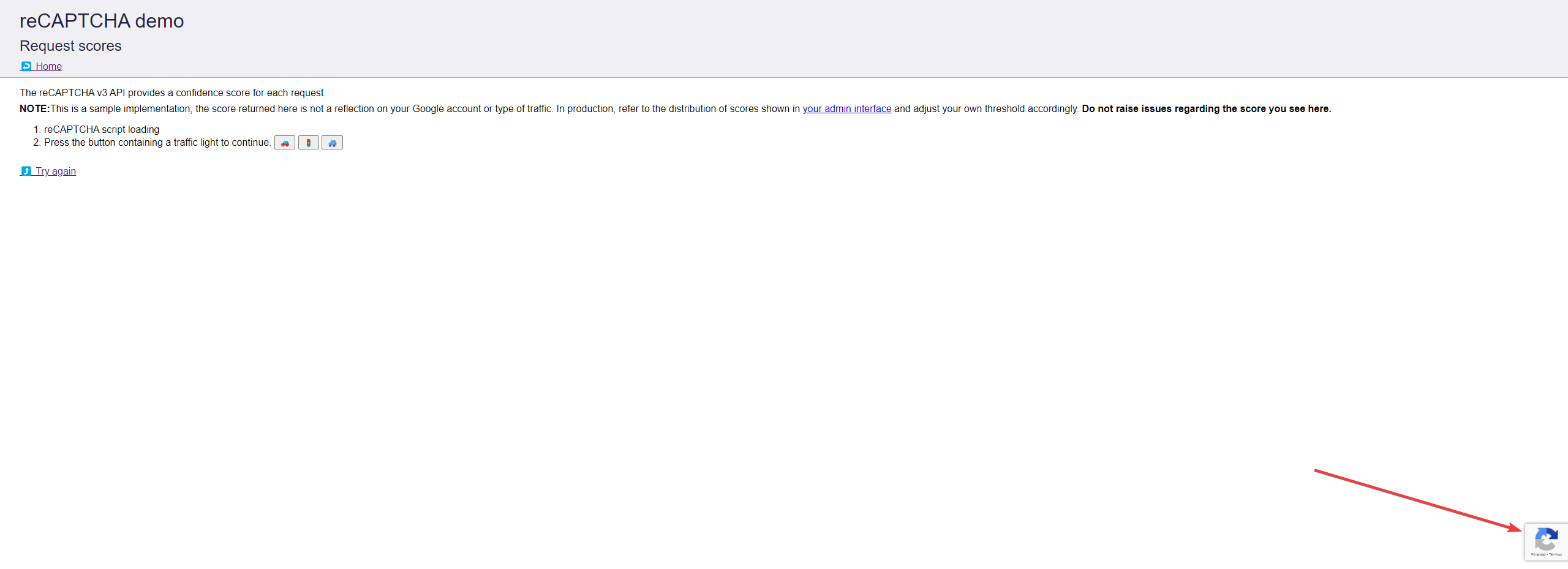
reCAPTCHA v3 Enterpriseは次のようになります:
繰り返しCAPTCHAを完全に解決できずに困っていますか?
CapsolverのAIパワードの自動ウェブアンブロック技術で、スムーズな自動CAPTCHA解決を実現しましょう!
今すぐ自動化予算を増やそう!
CapSolverアカウントにチャージする際、ボーナスコード CAPN を使用すると、毎回チャージに対して5%のボーナスを獲得できます — 限度はありません。
今すぐCapSolverダッシュボードで利用してください。
.
reCAPTCHA Enterpriseの仕組み
reCAPTCHA Enterpriseと関わりを持つ中で、ユーザーのプラットフォーム、ブラウザ環境、ナビゲーション行動などのさまざまなメトリクスを分析していることに気づきました。この分析により、0〜1の範囲でボットスコアが生成されます。スコアが0に近いほど高リスクの活動を示し、1に近いほど正当なユーザー行動を示します。
reCAPTCHA Enterpriseによるボットの検出
reCAPTCHA Enterpriseはスコアリングシステムを使用してボットのような活動を検出します。低リスクスコアのリクエストは許可され、高リスクスコアのリクエストはブロックされます。これにより、正当なユーザーのみがアクセスでき、自動スクリプトやウェブスクリーパーはサイトへのアクセスを効果的に防止されます。
reCAPTCHA EnterpriseにおけるCAPTCHAの種類
私が見た限り、reCAPTCHA Enterpriseは従来のCAPTCHA(視覚的なパズル)に依存していません。代わりに、高リスクスコアに対してさまざまな保護措置を実行します。これには、物理的なCAPTCHAの表示、IPアドレスのブロック、二要素認証の要求、ハニーポットへのリダイレクトが含まれます。必要なボットスコアに達しない自動スクリプトは、ターゲットデータに到達する前にブロックされます。
確かに!以下はそのパラグラフの改訂版です:
reCAPTCHA v3 Enterpriseのスクリプトによる識別
reCAPTCHA v3 Enterpriseの特徴的な特徴の一つは、enterprise.jsというユニークなスクリプトです。reCAPTCHA v3 Enterpriseを使用するウェブサイトは、適切な機能を確保するためにこの特定のスクリプトを含める必要があります。したがって、その存在はサービスが使用されていることを強く示唆します。
enterprise.jsスクリプトは、通常、ウェブサイトのソースコード内の<script> HTMLタグに埋め込まれています。このタグのsrc属性は、JavaScriptファイルの場所を指します。reCAPTCHA v3 Enterpriseの場合、スクリプトは次のURLのいずれかにあります:
https://recaptcha.net/recaptcha/enterprise.js
https://google.com/recaptcha/enterprise.jsウェブサイトのHTMLでは、スクリプトタグは次のようになります:
html
<script src="https://recaptcha.net/recaptcha/enterprise.js" async defer></script>または
html
<script src="https://google.com/recaptcha/enterprise.js" async defer></script>asyncとdefer属性は、スクリプトが非同期に読み込まれ、ウェブページの読み込み速度とパフォーマンスに悪影響を与えないようにするためのものです。
ウェブスクリーピングにおけるreCAPTCHA Enterpriseの課題の解決方法
私のウェブスクリーピングプロジェクトにおいて、CapSolver は、特にreCAPTCHA v3 Enterpriseに対処する際に非常に効果的なツールであることがわかりました。ここでは、reCAPTCHA v3 Enterpriseを解決するためのCapSolverの使用方法を紹介します。
前提条件
実装に取りかかる前に、以下の準備を確認してください:
- システムにPythonがインストールされていること
- CapSolverダッシュボードから取得可能なCapSolver APIキー
- プロキシ(オプションですが、より良い結果のために推奨されます)
ステップ1: 環境の設定
まず、必要なパッケージがインストールされていることを確認します。必要な主なパッケージはcapsolverです。pipを使用してインストールできます:
pip install capsolverステップ2: 解決方法の実装
では、reCAPTCHA v3 Enterpriseの課題を解決するためのCapSolverの使用方法を見てみましょう。プロキシを使用するバージョンと使用しないバージョンの2つのコードを提供します。
バージョン1: プロキシを使用する場合
reCAPTCHA v3 Enterpriseをプロキシで解決したいときに使用するPythonスクリプトは次の通りです:
python
import capsolver
from urllib.parse import urlparse
# 設定
PROXY = "http://username:password@ip:port"
capsolver.api_key = "YourApiKey"
PAGE_URL = ""
PAGE_KEY = ""
PAGE_ACTION = ""
def solve_recaptcha_v3_enterprise(url, key, pageAction):
solution = capsolver.solve({
"type": "ReCaptchaV3EnterpriseTask",
"websiteURL": url,
"websiteKey": key,
"pageAction": pageAction,
"proxy": PROXY
})
return solution
def main():
print("reCaptcha v3 Enterpriseを解決中")
solution = solve_recaptcha_v3_enterprise(PAGE_URL, PAGE_KEY, PAGE_ACTION)
print("解決結果:", solution)
token = solution["gRecaptchaResponse"]
print("トークンの解決結果:", token)
if __name__ == "__main__":
main()バージョン2: プロキシを使用しない場合
プロキシを使用したり、使用したくないシナリオでは、次の少し修正されたバージョンを使用します:
python
import capsolver
from urllib.parse import urlparse
# 設定
capsolver.api_key = "YourApiKey"
PAGE_URL = ""
PAGE_KEY = ""
PAGE_ACTION = ""
def solve_recaptcha_v3_enterprise(url, key, pageAction):
solution = capsolver.solve({
"type": "ReCaptchaV3EnterpriseTaskProxyless",
"websiteURL": url,
"websiteKey": key,
"pageAction": pageAction
})
return solution
def main():
print("reCaptcha v3 Enterpriseを解決中")
solution = solve_recaptcha_v3_enterprise(PAGE_URL, PAGE_KEY, PAGE_ACTION)
print("解決結果:", solution)
token = solution["gRecaptchaResponse"]
print("トークンの解決結果:", token)
if __name__ == "__main__":
main()キーとなる設定ポイント
これらのスクリプトを使用する際、以下の変数を必ず更新してください:
PROXY: プロキシバージョンを使用する場合、http://username:password@ip:portの形式でプロキシの詳細を更新します。capsolver.api_key: ここにCapSolverのAPIキーを挿入します。PAGE_URL: ここでreCAPTCHAを解決しているウェブサイトのURLを設定します。PAGE_KEY: ここで特定のreCAPTCHAサイトキーを更新します。PAGE_ACTION: ここでreCAPTCHAチャレンジのpageActionを設定します。
PAGE_KEYとPAGE_ACTIONの正しい値を見つけるために、私は通常、Capsolverのブログ記事を参照します。
このアプローチが機能する理由
この方法は、私のスクリーピングプロジェクトにおいて非常に効果的です。その理由は以下の通りです:
- 高い成功確率: CapSolverは一貫してreCAPTCHA v3 Enterpriseの課題を成功裏に解決する有効なトークンを提供します。
- 柔軟性: プロキシを使用できるため、リクエストを分散し、ブロックされるリスクを減らすことができます。
- シンプルさ: 直感的なAPIにより、既存のスクリプトへの統合が簡単です。
- 高速性: 解決は通常数秒で行われ、スクリーピング作業の効率を維持します。
reCAPTCHA v2 Enterpriseに関する追加情報
reCAPTCHA v2 Enterpriseの課題にも直面している場合、以下のブログ記事が役立つかもしれません。これはreCAPTCHA v2 Enterpriseを解決するための洞察と戦略を提供し、類似のCAPTCHAシステムに対処するのに役立ちます。
結論
ウェブスクリーピングの分野において、特にreCAPTCHA v3 Enterpriseを含むreCAPTCHA Enterpriseを扱うことは困難なタスクです。しかし、CapSolverなどの高度なソリューションを活用することで、このプロセスを大幅に簡略化できます。
私の経験では、スクリーピングワークフローにCapSolverを統合することで、効率を向上させ、これらの複雑なセキュリティ対策を成功裏に解決する成功率を高めることができます。プロキシを使用するか、直接的なアプローチを選ぶかに関わらず、CapSolverはreCAPTCHAの課題を効果的に扱うためのツールと柔軟性を提供します。
注意点として、CapSolverは強力な同盟者ですが、ウェブスクリーピングにおけるベストプラクティスを維持し、法的基準に準拠することが重要です。 有効なツールと倫理的な実践を組み合わせることで、正当性を損なうことなくスクリーピングの目標を達成できます。
CapSolverに関する詳細情報や、CAPTCHAの課題を乗り越えるために始める方法については、CapSolverのウェブサイトをご覧ください。
よくある質問
reCAPTCHA Enterpriseは通常のreCAPTCHAとどのように異なりますか?
reCAPTCHA Enterpriseは、ユーザーの行動や環境信号に基づいてボットスコアを割り当てる適応型リスク分析エンジンを使用しており、視覚的なチャレンジに依存するのではなく、サイトオーナーにとってより柔軟で、自動スクリプトにとってより困難なものです。
reCAPTCHA v3 Enterpriseは常に視覚的なCAPTCHAを表示しますか?
いいえ。ほとんどの場合、reCAPTCHA v3 Enterpriseはバックグラウンドで非表示に動作します。リクエストが高リスクと判断された場合のみ、視覚的なCAPTCHA、IPブロック、さらなる検証ステップなどの追加の保護がトリガーされることがあります。
ウェブサイトがreCAPTCHA v3 Enterpriseを使用しているかどうかを確認する方法はありますか?
ウェブサイトのソースコードにenterprise.jsスクリプトが存在するかどうかが信頼性の高い指標です。ページがGoogleまたはrecaptcha.netからこのスクリプトをロードしている場合、reCAPTCHA v3 Enterpriseが使用されている可能性が高いです。
reCAPTCHA Enterpriseを解決する際にプロキシの使用が推奨される理由は何ですか?
プロキシはリクエストを分散し、IPの評判やリクエスト頻度などの相関シグナルを減らすことができます。これにより、スケールアップしてreCAPTCHA Enterpriseの課題を解決する際の成功確率が向上し、ブロックされる可能性が低くなります。
もっと見る
reCAPTCHAApr 16, 2026
reCAPTCHA 無効なサイトキーまたはトークン? 原因と解決方法のガイド
「reCAPTCHA 無効なサイトキー」や「無効なreCAPTCHAトークン」のエラーに直面していますか?一般的な原因、ステップバイステップの修正手順、トラブルシューティングのヒントを確認してください。reCAPTCHAの検証失敗の問題を解決する。reCAPTCHAの検証失敗を修正する方法を学びましょう。もう一度試してください。

reCAPTCHAMar 25, 2026
reCAPTCHA v2を解く方法 PythonとAPI
PythonとAPIを使用してreCAPTCHA v2を解決する方法を学びましょう。この包括的なガイドでは、プロキシとプロキシレスな方法をカバーし、自動化に使用可能な本番環境対応のコードを提供しています。

