エージェンティックブラウザがCAPTCHAを解く方法: AI CAPTCHA 解決インフラ

Sora Fujimoto
AI Solutions Architect
私たちの前回の記事では、エージェントブラウザが受動的な「表示ツール」から能動的な「アクションエージェント」へとどのように変化するかを紹介しました。そのコアアーキテクチャである「意図理解」「環境認識」「アクション実行」についても検討しました。しかし、これらのデジタルエージェントが現実世界のウェブをナビゲートする際には、 formidable gatekeeper としてCAPTCHAが存在します。この記事では、これらのエージェントが中断することなく、積極的に作業を遂行できるようにする「目には見えないエンジン」、つまりCAPTCHA解決インフラについて焦点を当てます。AIにとってCAPTCHAが最大の障害である理由と、CapSolverのような専門的なサービスが、次世代のウェブ自動化に必要なインフラストラクチャを提供する方法について探ります。
第1章: 「目には見えないエンジン」— CAPTCHA解決インフラストラクチャ
このようなシナリオを想像してください: エージェントブラウザに人気のコンサートチケットを入手してほしいと依頼します。正確にウェブサイトを開き、購入ボタンを特定し、「Buy Now」をクリックしようとした瞬間に、スライドパズルやぼやけた交通標識の画像が突然表示されます。あなたのデジタルアシスタントは即座にロックされてしまいます。インターネットの黎明期に生まれた「チューリングテスト」として知られるCAPTCHAは、今ではAIエージェントにとって最も直接的で最も厄介な敵となっています。
1.1 CAPTCHAがAIエージェントにとって最大の障害である理由
CAPTCHAは「Completely Automated Public Turing Test to Tell Computers and Humans Apart」の略語です。もともとの目的は単純でした: ボットを排除し、人間だけを許可すること。しかしAIが進化するにつれて、CAPTCHAも継続的に進化し、単純な歪んだ文字から複雑なスライダー、画像選択タスク、行動分析システムにまで進化しました。それらはもはや単なる文字認識問題ではありません。

従来の自動化スクリプトにとって、CAPTCHAはほぼ死の宣告です。しかしエージェントブラウザにとっても、3つの主な理由から同様に深刻な課題となっています:
-
認識の難易度の急激な増加: 最も高度なマルチモーダルモデルでも、重く歪んだテキストやぼやけた画像オブジェクト、複雑な背景に隠されたスライダーのギャップを信頼性高く認識することは困難です。AIは単に「間違った認識」をし、1つのミスが全体のワークフローを破綻させることもあります。
-
階層的なアンチボットインセンティブメカニズム: 現代のCAPTCHAはもはやフロントエンドのチャレンジにとどまりません。ウェブサイトはマウスの軌跡、タイプのリズム、ページ滞在時間、ブラウザの指紋を監視します。システムが「人間のように振る舞っていない」と判断すると、CAPTCHAの難易度は即座に上昇します—チェックボックスの単純な選択から、連続して10個の画像認識タスクを解くことまで。
-
時間の制限と文脈的な中断: CAPTCHAは通常、有効期限が設定されています。エージェントブラウザが複数ステップのタスク中にCAPTCHAに長時間とどまると、ログインセッションが期限切れ、製品が売り切れ、全体のタスクチェーンが崩壊する可能性があります。高速道路で突然橋が崩壊するようなものです。これにより、すべての自動化パイプラインが停止します。
言い換えれば、CAPTCHAを乗り越える能力がなければ、エージェントブラウザはウェブの「守られていない裏道」を移動するだけで、本格的な現実世界のウェブサイトの高速道路を真正にナビゲートすることはできません。これが、カプソルバーのようなCAPTCHA解決インフラストラクチャが存在する理由です。
1.2 カプソルバーがAIエージェントの道を切り開く方法
カプソルバーは一般的なユーザー向けのツールではなく、開発者のツールキットの中に隠された「CAPTCHAエンジン」です。そのコアは、自動化プログラムやAIエージェントがさまざまなタイプのCAPTCHAを処理するのを支援するために特別に設計されたAPIインターフェースを持つ知能型CAPTCHA解決プラットフォームです。
これは、疲れることなく、極めて高速に動作する24時間365日対応のCAPTCHA解決チームと考えることができます—ただし、その「チームメンバー」は高度なAIモデルだけでなく、高度に最適化された戦略アルゴリズムも含まれています。
その機能をよりよく理解するために、以下の比較表は同じCAPTCHAチャレンジに直面した際の従来のアプローチとカプソルバーの機能の違いを示しています:
| 比較次元 | ローカルOCR/単純モデル | 人間によるCAPTCHA解決プラットフォーム | カプソルバー |
|---|---|---|---|
| サポートされているCAPTCHAタイプ | 単純なテキストCAPTCHAのみ; 画像選択は主に効果がありません | 理論上すべてのタイプをサポートしていますが、遅く高価です | 主流のCAPTCHAタイプをカバー |
| 認識速度 | ミリ秒単位ですが、成功確率は低いです | 1回の試行で5〜15秒 | 1回の試行で1〜3秒 |
| 成功確率 | 低い(複雑なCAPTCHAではさらに悪い) | 相対的に高いですが、作業者の疲労やネットワーク遅延の影響を受けます | 高く安定しています |
| コスト構造 | 1回の開発コスト | タスク単位で支払いますが、労働コストが高いです | タスク単位で支払いますが、低価格で低限界コストです |
| 検出回避能力 | ほぼありません | 行動分析システムには対応できません | ブラウザ環境とリスクに合ったトークンや指示を返すことができます |
表1-1 従来のCAPTCHA解決方法とカプソルバーの機能の比較
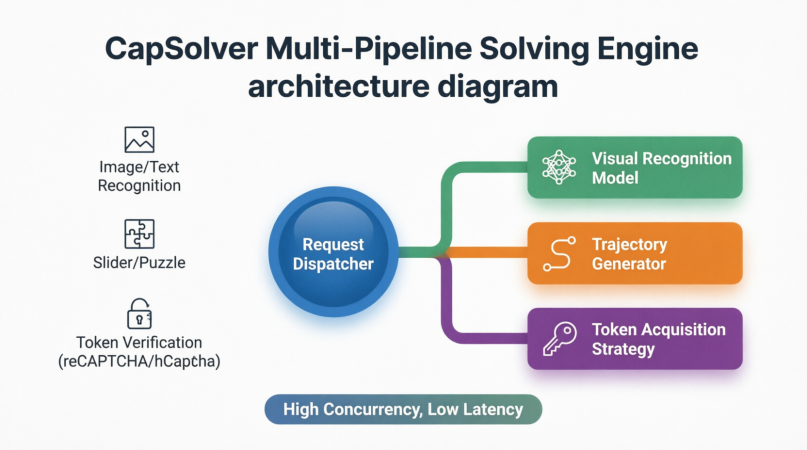
カプソルバーのコア運用原理は本質的に「AI対AI、戦略対戦略」です。さまざまなタイプのCAPTCHAに対して、専門的な解決パイプラインを組み込みます:
-
画像とテキスト認識CAPTCHA: 特許取得のビジョンモデルと膨大なトレーニングデータセットを組み合わせることで、カプソルバーは重く歪んだ、重なった、ノイズの多いテキストを正確に認識できます。
-
スライダーとパズルCAPTCHA: 空間の座標を直接出力する代わりに、環境分析に基づいてスムーズな移動軌跡を生成し、人間のタッチインタラクションの微細な手の震え、加速、減速パターンをシミュレートします。これらの行動パラメータにより、自動化プログラムは検証を通じてスライダーを自然にドラッグできます。
-
トークンベースの検証システム(reCAPTCHA v2/v3、Cloudflareなど): これらのCAPTCHAは明示的なユーザー入力を必要としません。代わりに、ブラウザの行動をバックグラウンドで評価し、ワンタイムトークンを返します。カプソルバーはブラウザの指紋、IPの評判、マウスの軌跡などの文脈データを組み合わせて、専用の解決インターフェースを通じて有効な検証トークンを取得します。エージェントブラウザはそのトークンをウェブページに挿入するだけで、検証を通過できます。
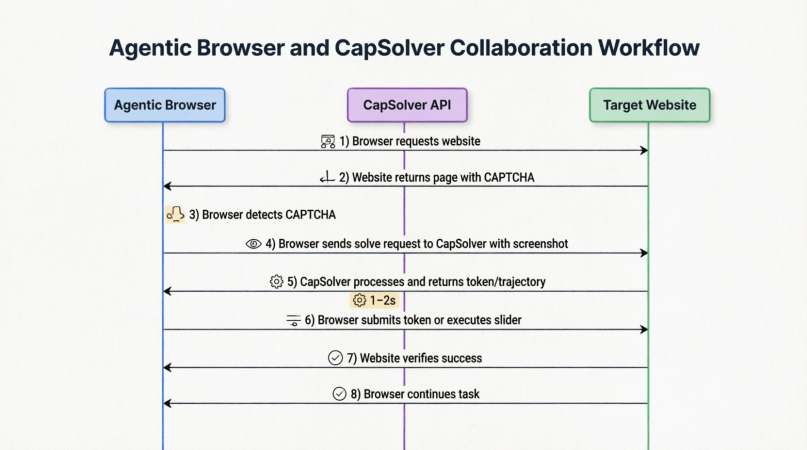
ではカプソルバーとエージェントブラウザは実際どのように協働しているのでしょうか?以下の図は、完全なプロセスを示しています:
ブラウザがウェブサイトにリクエストを送信し、CAPTCHAに遭遇し、スクリーンショットをキャプチャし、カプソルバーAPIを呼び出し、トークンや行動軌跡を受信し、検証を提出し、元のタスクを再開する—このすべてのワークフローは密接に統合されており、通常1〜2秒で完了します。
これは、エージェントブラウザにとってCAPTCHAがAI自身が「見たり」「推測したり」しなければならない問題ではなく、専門的なインフラストラクチャプロバイダーに標準化されたタスクとして委譲されるようになったことを意味します。ブラウザは挑戦をキャプチャし、文脈をパッケージ化し、送信し、そして「鍵」を待って、次のステップに進むだけです。
1.3 エージェントブラウザとカプソルバーの協働ワークフロー
では、エージェントブラウザのダイナミックな適応モジュールとカプソルバーを接続し、彼らがシームレスな「障害物を越えるパフォーマンス」でどのように協働しているかを見てみましょう。
エージェントブラウザがタスクを実行している間、環境認識レイヤーはウェブページを継続的に監視します。CAPTCHA要素が検出されると(例: reCAPTCHAのiframeを含むポップアップ)、アクション実行はすぐに停止し、専用のCAPTCHA処理サブプロセスが起動されます。
このプロセスは非常に高度で、一般的に以下のステップを含みます:
-
文脈収集: エージェントブラウザはCAPTCHA領域のスクリーンショットをキャプチャし、現在のURL、サイトキー、ブラウザビューポートの寸法、User-Agentなどの文脈情報を収集します。
-
タスク提出: スクリーンショットとパラメータはAPIを通じてカプソルバーにパッケージ化され、CAPTCHAのタイプが指定されます。
-
バックグラウンド解決: タスクを受け取ると、カプソルバーは対応する解決パイプラインにルーティングします。例えば、reCAPTCHA v2に遭遇した場合、専用の解決者を呼び出して有効な
g-recaptcha-responseトークンを返します。解決プロセスは通常1〜2秒で完了します。 -
指示の返還: エージェントブラウザは返された結果を受け取ります—これはトークン文字列やマウス軌跡の座標のセットかもしれません。
-
現場実行: エージェントブラウザはトークンを隠しフォームフィールドに挿入し、フォームを提出します。または、返された軌跡データに従って人間のようなスライダーの動きをシミュレートします。CAPTCHAレイヤーが消え、元のタスクフローがシームレスに再開されます。
-
状態検証: ブラウザはページが検証に成功したか、ターゲット要素が再び表示されているかを検証し、中断されたワークフローを再開します。
重要なのは、現代のCAPTCHAは多くの形式があり、複雑度も異なります。以下の図は主流のCAPTCHAタイプを分類し、それぞれの複雑度レベルを示しています:
エンドユーザーにとって、このプロセスは完全に透過的です。エージェントブラウザのタスクログでは、ユーザーは単純なメッセージのみを見ることになるでしょう:
“reCAPTCHA v2が検出されました。1.2秒で自動的に解決されました。”
これまでの自動化ワークフローを停止させる障害が、バックグラウンドで静かに解決されます。
これはAIエージェントの能力において重要な飛躍を意味します: エージェントはもはや、自動化をブロックするために設計された防御システムを恐れていません。CAPTCHA解決インフラが「目には見えないエンジン」として機能するため、エージェントブラウザは開かれたインターネット上でタスクを自律的に実行するための運用の自由を得ました。
このエンジンがなければ、知能エージェントに関するすべての約束は、最初のCAPTCHAポップアップで簡単に崩壊してしまうでしょう。
第2章: 今日、エージェントブラウザがどのように使われているのか?
前章でこの技術が遠いものに感じられたかもしれませんが、以下の例はあなたの視点を完全に変えるでしょう。エージェントブラウザは未来に浮かぶ抽象的な概念ではありません—急速に3つの主要な分野、個人の生産性、企業の自動化、データ収集に進出しています。それぞれの分野で、彼らは異なるレベルの実用的な問題を解決しています。
以下の図はエージェントブラウザの核心的な応用シナリオを要約しています:
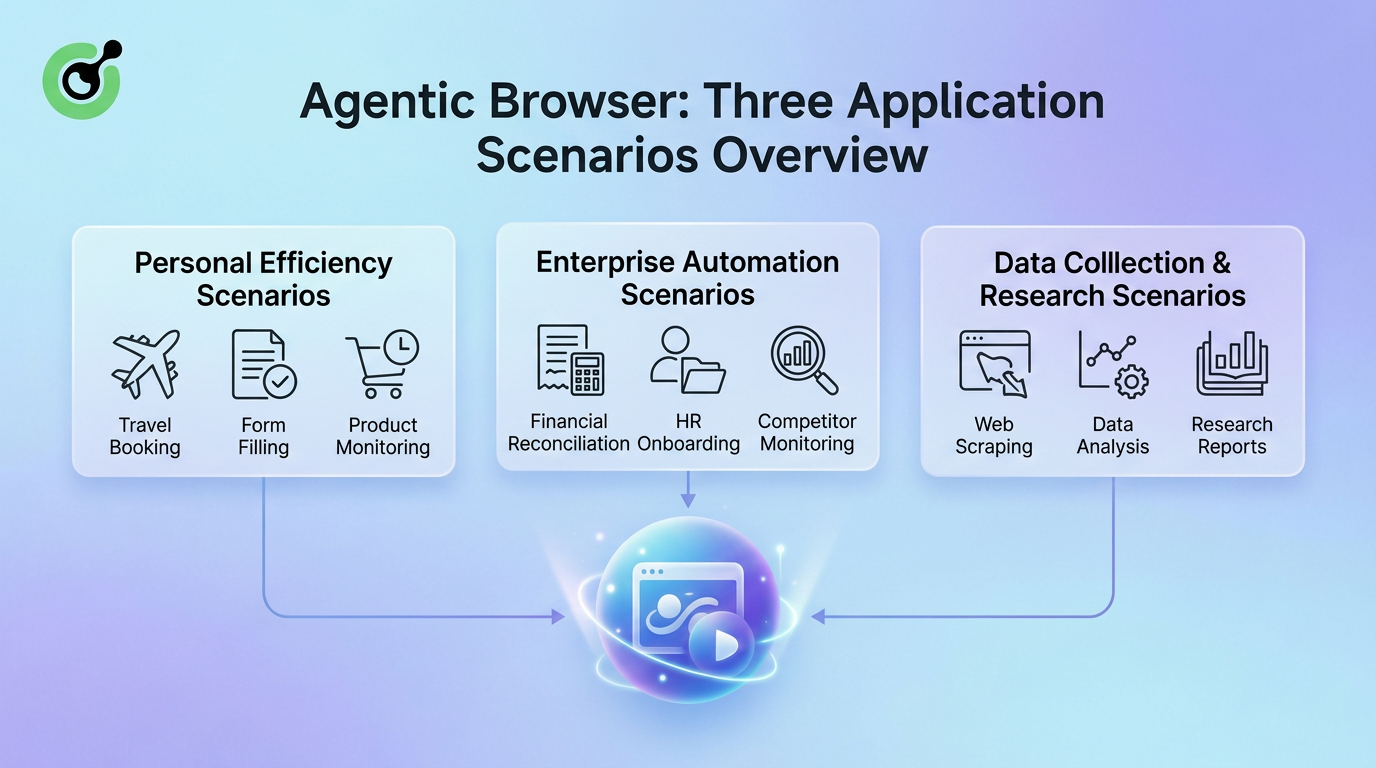
エージェントブラウザの応用は、個人ユーザーから大企業に至るまで、日常的なタスクから専門的な研究ワークフローに至るまで多岐にわたります。個人の生産性においては、旅行の予約、繰り返しのフォーム入力、製品価格の変動監視を手伝います。企業の自動化においては、財務の調整、従業員のオンボーディング、競合企業の追跡を担当します。データ収集と研究においては、疲れないクローラーと知的な分析アシスタントとして機能します。
次に、これらの3つのシナリオを詳細に検討し、エージェントブラウザが実際に「仕事を遂行する」方法を理解していきましょう。
| クロスプラットフォームデータの整理 | 1〜2時間(コピーペーストとフォーマット) | 5分(自動抽出とフォーマット) | マニュアルオペレーター → アナリスト |
表2-1 伝統的な個人作業とエージェンティックブラウザの効率比較
上記のように、エージェンティックブラウザは個人アシスタントとして効果的に機能します。ユーザーが「ワークフローのオペレーター」であることを解放し、「ゴールの設定者」と「結果のレビュー者」に変えるのです。
2.2 企業向けオートメーション:システム間のインテリジェントな調整
個人の生産性向上が「労力の削減」に焦点を当てているとすれば、エージェンティックブラウザの企業環境における価値は「接続」にあります。
大規模な組織は、APIを通じて簡単に統合できない多くの非統合されたレガシーシステム、SaaSプラットフォーム、サプライヤーポータルに依存しています。従業員は、繰り返しシステム間で情報を手動で移動する「人間の接着剤」としての役割を強いられています。
これはまさにエージェンティックブラウザが最も強力な利点を発揮する場面です。
一般的な企業向けユースケース
- 財務およびサプライチェーンの調整
エージェンティックブラウザは、銀行ポータルに自動ログインし、明細をダウンロードし、ERPシステムと比較し、差異レポートを作成し、通知メールの下書きも生成できます。
- フルエンドの従業員オンボーディングワークフロー
組織は事前にオンボーディングタスクパッケージを定義できます。エージェンティックブラウザは、HRシステム、ITシステム、メールリスト、アクセス制御システムでアカウントを自動的に作成し、欠落や遅延を防ぎます。
- 競合企業のモニタリングと市場情報収集
エージェンティックブラウザは、競合企業のウェブサイト、ECストア、ソーシャルメディアページを自動的に訪問し、重要な情報の変化を特定し、構造化されたデータベースに保存することで「市場レーダー」システムとして機能します。
エージェンティックブラウザが企業向けオートメーションにおいてどのようにユニークな位置を占めているかをよりよく説明するため、以下の表は手動操作と従来のAPI統合とを比較しています:
| 次元 | 手動操作 | API統合開発 | エージェンティックブラウザ |
|---|---|---|---|
| 対応可能なシステム | あらゆるシステム | APIが開いているシステムのみ | APIが開いていないレガシー内部システムを含むあらゆるウェブベースのシステム |
| 部署サイクル | 開発不要、しかし時間がかかる | 何週間から何カ月(開発リソースに依存) | 数時間から数日(タスク構成とテスト) |
| 非常に柔軟性がある | 高い(人間が動的に適応) | 低い(変更後にインターフェースの再構築が必要) | 高い(AIがページの変更に動的に適応) |
| CAPTCHA/ログイン処理 | 手動処理が必要 | 通常直接処理が難しい | 自動的に解決エンジンを呼び出し、シームレスに処理 |
| 拡張性 | 悪い | 非常に強い | 強い(並列タスク実行が可能) |
| 一般的な失敗シナリオ | 人間の疲労や見落とし | APIのレート制限やバージョンの不一致 | 非常に混沌としたページ状況では人間の確認が必要 |
表2-2 システム間オートメーションソリューションの比較
上記のように、エージェンティックブラウザはAPIを置き換えるためのものではありません。APIが利用不可または実装にコストがかかる状況において、軽量な統合層を提供します。
AIの柔軟性と適応性を活用することで、エージェンティックブラウザは従来のオートメーションアプローチによって残されたギャップを埋め、レガシーインフラストラクチャを再構築することなく、企業がインテリジェントなシステム間調整を実現できるようにします。
2.3 データ収集と研究:手動収集から知的抽出へ
データはデジタル時代の「オイル」とよく形容されますが、効率的にクリーンな公開ウェブデータを収集することは常に難しかったのです。
従来のウェブクローラーは固定されたパースルールに依存しています。ターゲットウェブサイトがレイアウトを再設計したり、クローリング防止措置を導入したりすると、クローラーは完全に機能しなくなります。学術研究者、市場調査会社、インベスティゲーティブジャーナリズムチームは、多数の異質なウェブページから特定の情報を抽出する必要があり、従来のアプローチは高コストで時間がかかることが一般的です。
エージェンティックブラウザはデータ収集にまったく新しいパラダイムを導入します:
「コードルールに基づく抽出」から「セマンティックな目的に基づく抽出」へのシフト。
そのワークフローは一般的に以下の通りです:
研究者は自然言語を使用して必要なデータの次元とサンプル範囲を説明します。例えば:
「上位100のEC商品ページから製品タイトル、価格、評価、レビュー数を抽出し、スポンサード製品を除外する。」
エージェンティックブラウザはウェブページを自律的にナビゲートし、環境認識を通じて関連情報ブロックを特定し、データを知的に抽出・構造化し、ページング、無限スクロール、ポップアップなどの複雑なインタラクションを処理します。
ターゲットウェブサイトがレイアウトを再設計すると、従来のクローラーはすぐに機能停止します。一方エージェンティックブラウザは視覚的に情報を再配置し、実行を継続します。
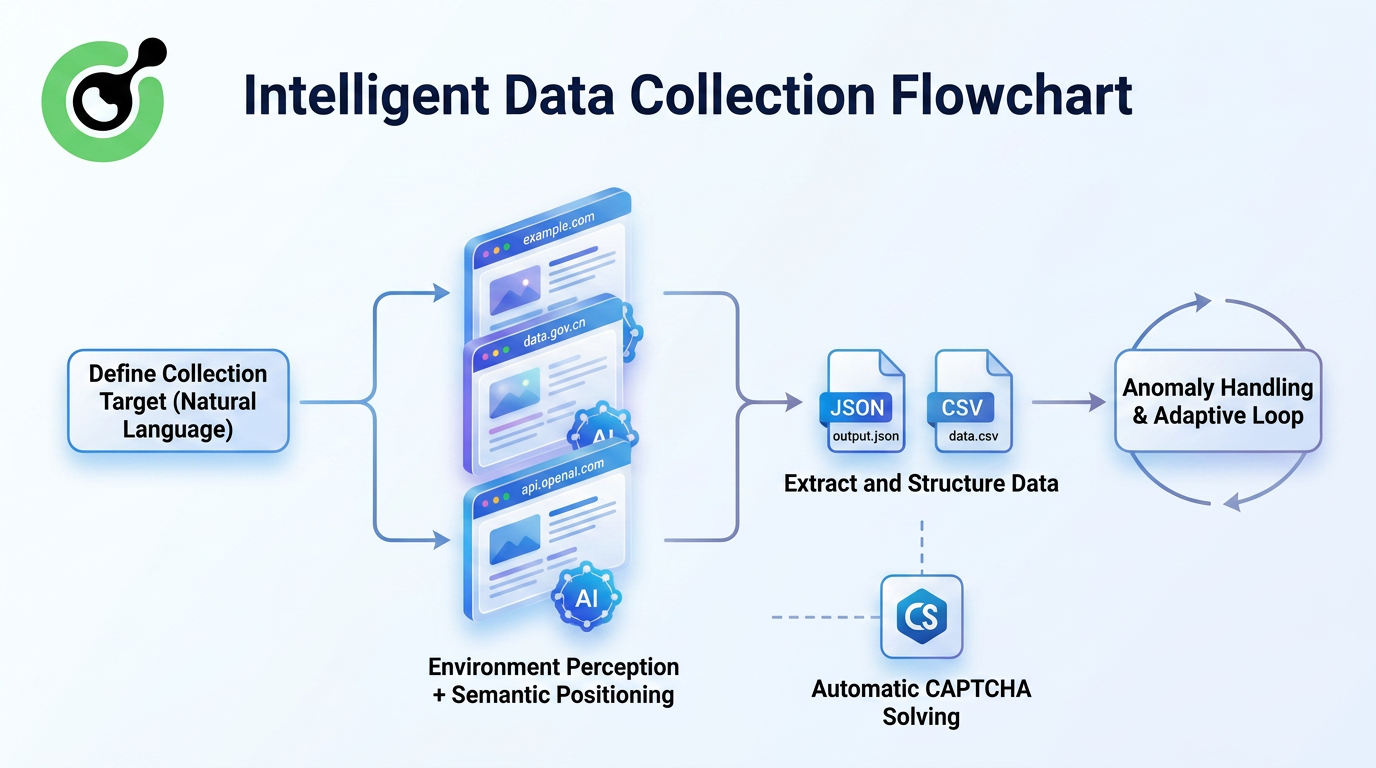
このアプローチにより、いくつかの根本的な改善がもたらされます:
- 解析ルールのメンテナンスの必要性なし
AIは「価格」がどのように見えるかをセマンティックに理解し、固定されたHTMLクラス名に依存しません。
- ウェブサイトの再設計に対するより高い耐性
レイアウトのわずかな変更がすぐに抽出パイプラインを破壊することはありません。
- 複雑なインタラクションの処理能力
ログインが必要なウェブサイトや無限スクロール、タブの切り替えが必要なウェブサイトでは、エージェンティックブラウザは実際のユーザーのようにインターフェースとインタラクションし、情報抽出を行います。
- 再現可能な研究ワークフロー
タスク構成は保存・共有可能であり、データ収集を標準化し、再現可能にします。
エージェンティックブラウザがデータ収集タスクにおいてどれだけの耐性の利点を持っているかをよりよく示すために、以下の図は複数回のウェブサイト再設計後の従来のクローラーとエージェンティックブラウザの比較を示しています:
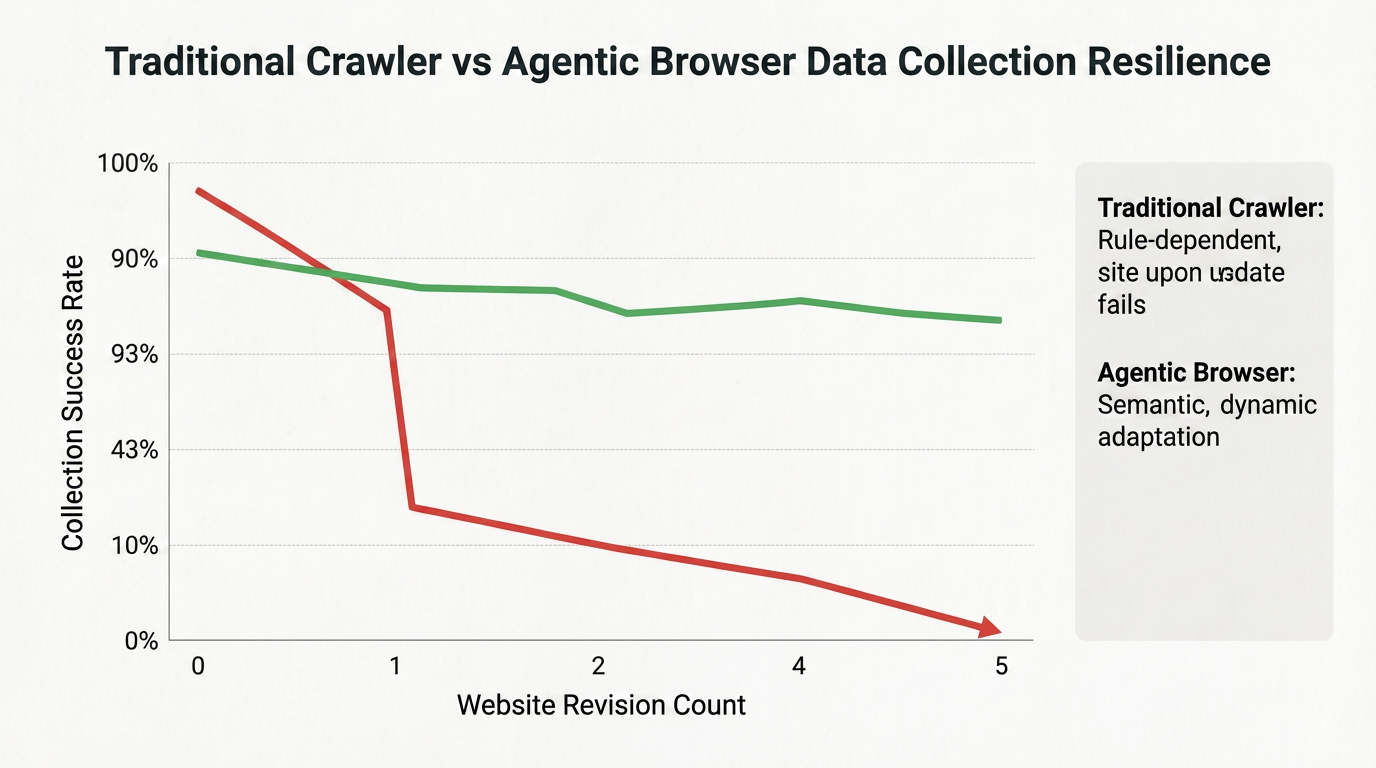
ウェブサイトの最初の再設計後、従来のクローラーは成功確率が劇的に低下します。一方エージェンティックブラウザは、視覚的なローカライズとセマンティック理解の能力により、複数回の再設計後でも比較的高い抽出成功確率を維持します。
この耐性により、長期的で大規模なデータ収集プロジェクトに最適です。
例えば、30カ国にまたがる200の政策ウェブサイトで特定の政策条項を比較する社会科学研究チームを想像してください。従来の方法では、研究補助員が何カ月もかけて手動で情報をコピーし整理する必要がありました。
今では、研究者はこれらのウェブサイトを自動的に巡回し、ターゲットキーワードを含む政策ページを特定し、関連する条項を抽出し、自動的に分類するタスクを構成できます。
研究者はその後、収集された結果をレビューし分析すればよく、人間の貴重な努力を「実際の研究」に集中させ、「繰り返しの手作業」から解放します。
結論
エージェンティックブラウザは、単なる製品ではなく、オンラインでの新しい哲学を表しています。そのコアロジックは、ブラウザが単にクリックを待つインターフェースではなく、あなたの意図を理解し、タスクを完了するための知的エージェントであるべきだということです。技術的な実装の観点から見ると、それは大規模言語モデルの推論能力に依存してタスクを計画し、マルチモーダルな認識でウェブページを理解し、実際のブラウザ環境で操作を実行し、CapSolverのようなインフラストラクチャを通じて、オートメーションの道の障害を除去します。これらの技術の融合は、30年にわたって使用されてきた「情報の窓」を、真の「アクションプラットフォーム」へとアップグレードしています。
Q&A
Q1: 一般的なAIモデルはCAPTCHAを独自に解くことができないのはなぜですか?
A1: 一般的なAIモデルは強力ですが、CAPTCHAは敵対的で頻繁に変更されるように設計されています。信頼性があり迅速に解くには、CAPTCHAの解決に特化したインフラストラクチャであるCapSolverのようなサービスが必要です。
Q2: CapSolverはエージェンティックブラウザにどのように役立ちますか?
A2: CapSolverはCAPTCHAのチャレンジを単純なAPI経由で処理する「目に見えないエンジン」として機能します。これにより、エージェンティックブラウザはセキュリティのハードルをシームレスに回避し、人間の介入なしにタスクを継続できます。
Q3: エージェンティックブラウザは人間の仕事に置き換えるのでしょうか?
A3: エージェンティックブラウザは「タスク」を置き換えるように設計されていますが、「仕事」を置き換えるようには設計されていません。繰り返しのデジタル労働を処理することで、人間がより上位の創造性や戦略的決定に焦点を当てられるようにします。
Q4: 今日からエージェンティックブラウザを使うことはできますか?
A4: すでにいくつかの実験的なブラウザや拡張機能が利用可能です。しかし、最高の体験を得るには、ウェブのセキュリティのハードルを処理する信頼性の高いCAPTCHA解決サービスであるCapSolverを統合することを確認してください。